В этом смысле опыт Леона Файера, которым он делился на DevOpsConf, не то чтобы прямо уникален, но помноженный на стаж и количество различных ролей, которые он за 20 лет успел на себя примерить, очень полезен. Под катом хронология событий за 90 дней и много баек, над которыми приятно посмеяться, когда они происходят с кем-то другим, но с которыми не так уж весело сталкиваться лично.
Леон очень колоритно рассказывает по-русски, поэтому если у вас есть 35-40 минут, то рекомендую смотреть видео. Текстовая версия для экономии времени ниже.
Первая версия доклада была хорошо структурированным описанием работы с людьми и процессами, содержащим полезные рекомендации. Но она не передавала всех сюрпризов, которые встречались по пути. Поэтому я поменял формат и изложил проблемы, которые в новой компании выскакивали передо мной, как черт из табакерки, и методы их решения в хронологическом порядке.
За месяц до
Как и многие хорошие истории, эта началась с алкоголя. Мы сидели со знакомыми в баре, и как полагается в среде айтишников, каждый плакался о своих проблемах. Один из них только что сменил работу и рассказывал о своих проблемах и с технологиями, и с людьми, и с командой. Чем дольше я слушал, тем больше понимал, что ему надо просто нанять меня, потому что именно такие проблемы я решал последние 15 лет. Я так ему и сказал, и на следующий день мы встретились уже в рабочей обстановке. Компания называлась Teaching Strategies.
Teaching Strategies лидирует на рынке учебных программ для детей совсем раннего возраста — от рождения до трех лет. Традиционной «бумажной» компании уже лет 40, а цифровой SaaS-версии платформы 10. Относительно недавно начался процесс адаптации цифровой технологии в стандарты компании. «Новая» версия запустилась в 2017 г. и была почти как старая, только работала хуже.
Самое интересное, что трафик у этой компании очень прогнозируемый — изо дня в день, из года в год можно очень четко спрогнозировать, сколько людей придут и когда. Например, между 13 и 15 часами дня все дети в детских садиках идут спать, а учителя начинают вводить информацию. И так происходит каждый день, кроме выходных, потому что в выходные почти никто не работает.
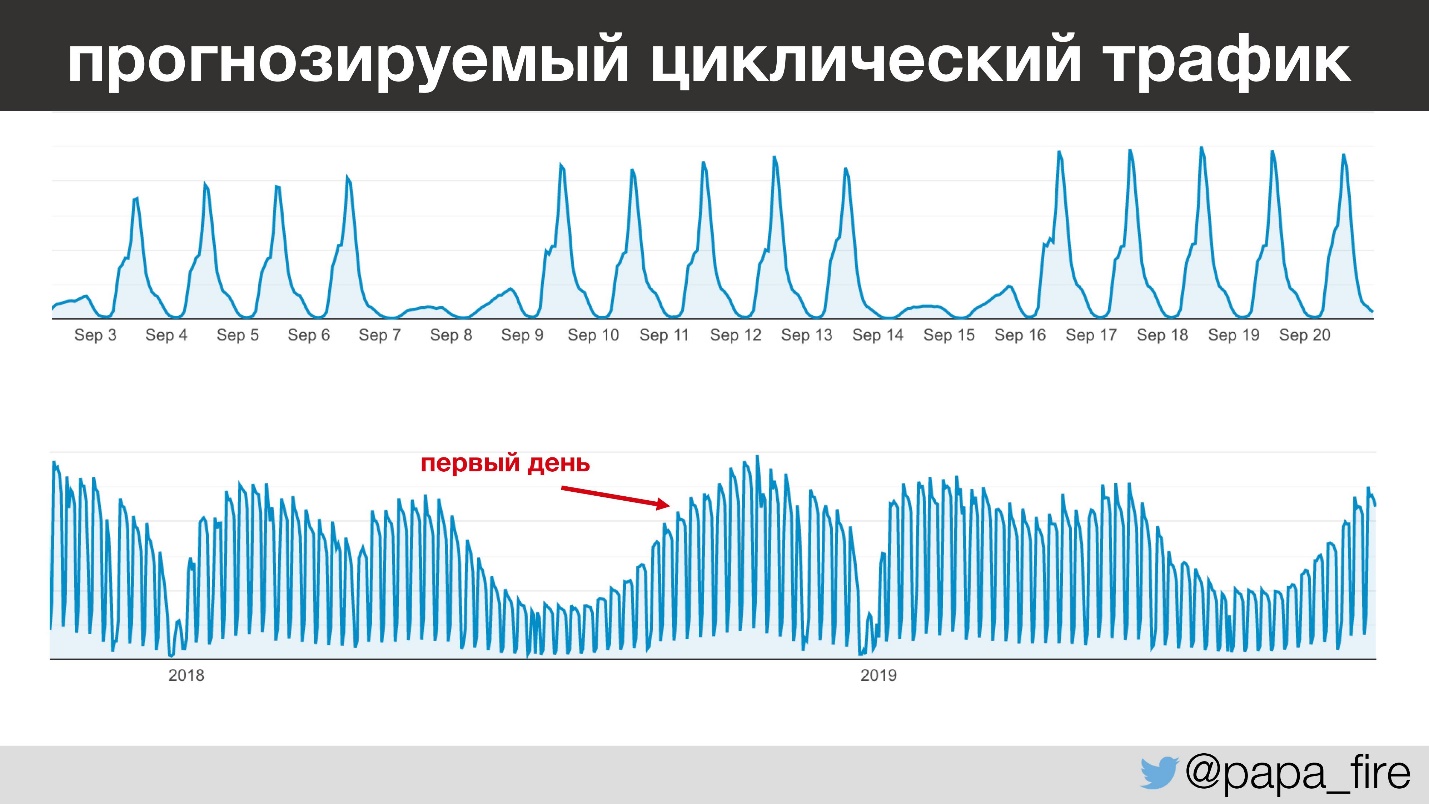
Забегая немного вперед замечу, я начал свою работу в период самого большого годового трафика, что интересно по разным причинам.
Платформа, которой было как будто всего 2 года, имела своеобразный стек: ColdFusion & SQL Server 2008 года. ColdFusion, если не знаете, а скорее всего не знаете, — это такой enterprise PHP, который вышел в середине 90-х, и с тех пор я про него даже не слышал. Также там были: Ruby, MySQL, PostgreSQL, Java, Go, Python. Но основной монолит работал на ColdFusion и SQL Server.
Проблемы
Чем больше я говорил с сотрудниками компании о работе и о том, какие проблемы встречаются, тем больше понимал, что проблемы носят не только технический характер. Ладно, технология старая — и не на таком работали, но были проблемы с командой и с процессами, и компания это начинала понимать.
Традиционно технари у них сидели в углу и занимались какой-то своей работой. Но все больше и больше бизнеса начало проходить именно через цифровую версию. Поэтому в компании за последний год до начала моей работы появились новые: совет директоров, CTO, CPO и QA-директор. То есть компания начала вкладываться в технологическую сферу.
Следы тяжелого наследия были не только в системах. В компании были legacy-процессы, legacy-люди, legacy-культура. Все это надо было менять. Я подумал, что скучно точно не будет, и решил попробовать.
За два дня до
За два дня до начала новой работы я приехал в офис, заполнил последние бумаги, познакомился с командой и обнаружил, что команда в это время борется с проблемой. Она заключалась в том, что среднее время загрузки страниц подскочило до 4 с, то есть в 2 раза.
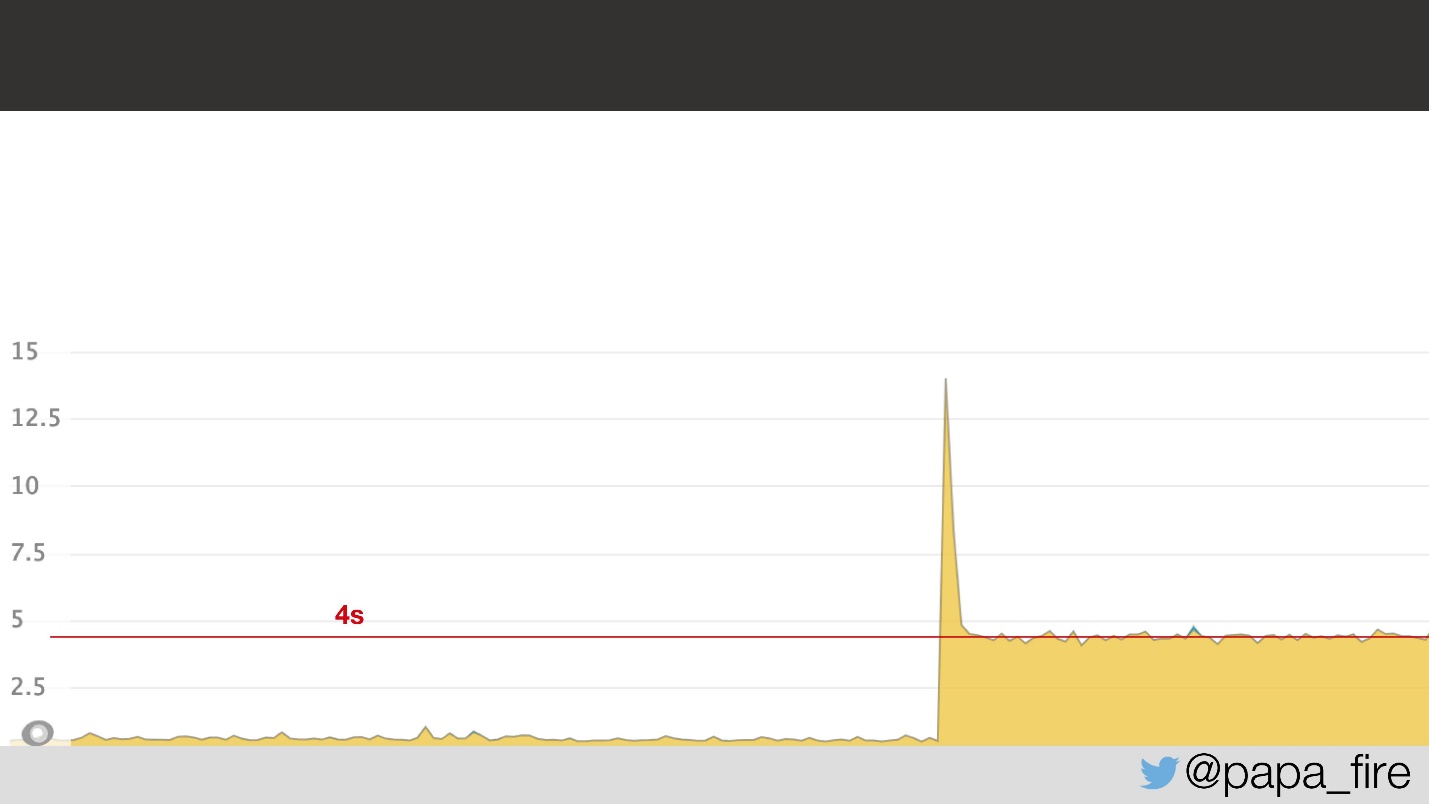
Судя по графику, явно что-то случилось, причем непонятно что. Оказалось, что проблема была в network latency в дата-центре: 5 мс latency в дата-центе преобразовались в 2 с для пользователей. Почему так произошло, я не знал, но во всяком случае стало известно, что проблема в дата-центре.
День первый
Прошло два дня, и в свой первый рабочий день я обнаружил, что проблема никуда не делась.
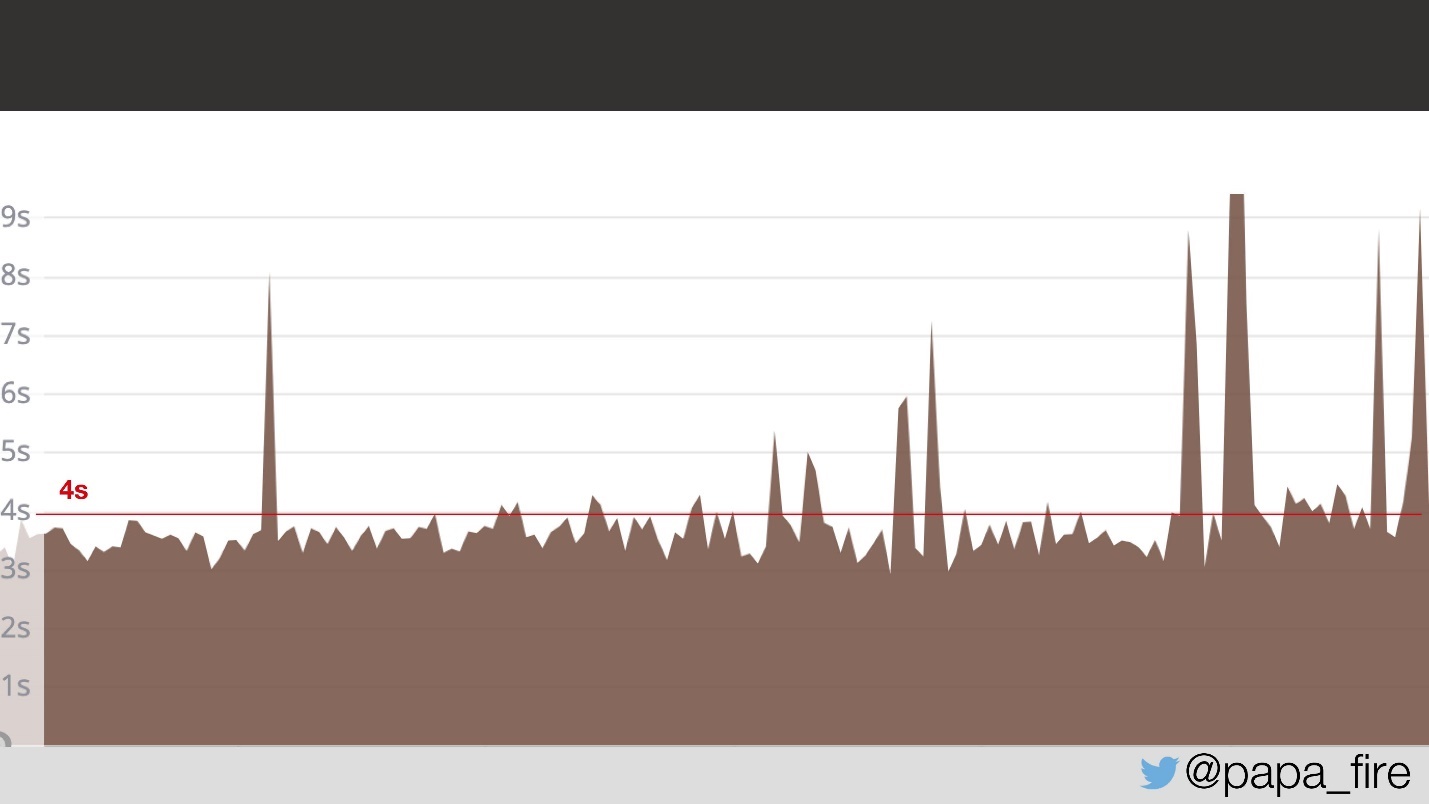
Два дня у пользователей страницы грузились в среднем по 4 с. Спрашиваю, нашли ли, в чем проблема.
— Да, мы открыли тикет.
— И?
— Ну, они нам пока еще не ответили.
Тут я понял, что все, о чем мне до этого рассказывали, это только маленький кончик айсберга, с которым надо бороться.
Есть хорошая цитата, которая очень подходит к этому случаю:
«Иногда для изменения технологии нужно менять организацию».
Но так как я начал работу в самое загруженное время года, надо было смотреть на оба варианта решения проблемы: и быстрое, и в дальнесрочной перспективе. И начинать с того, что критично прямо сейчас.
День третий
Итак, загрузка длится 4 секунды, а с 13 до 15 самые большие пики.
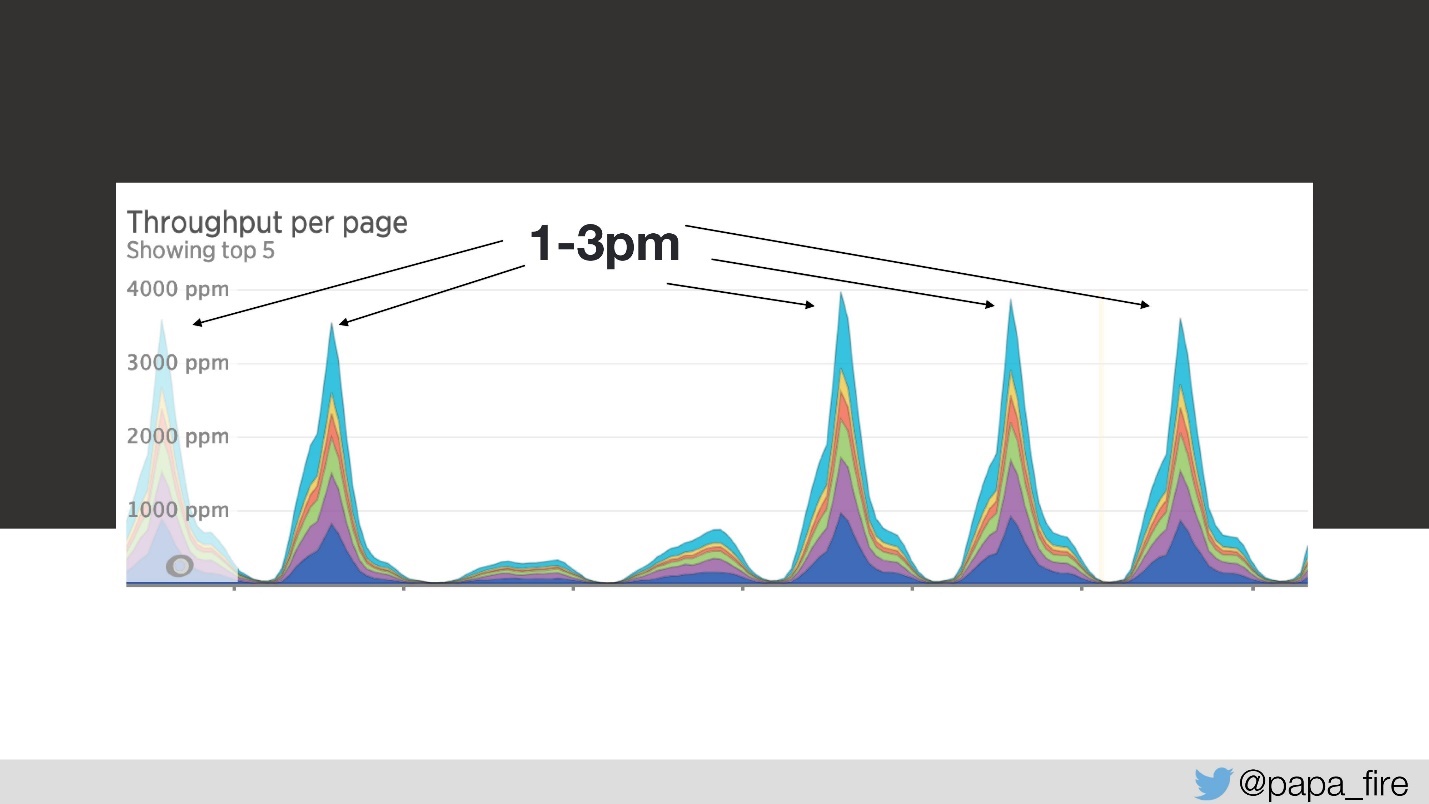
На третий день в этот отрезок времени скорость загрузки выглядела так:
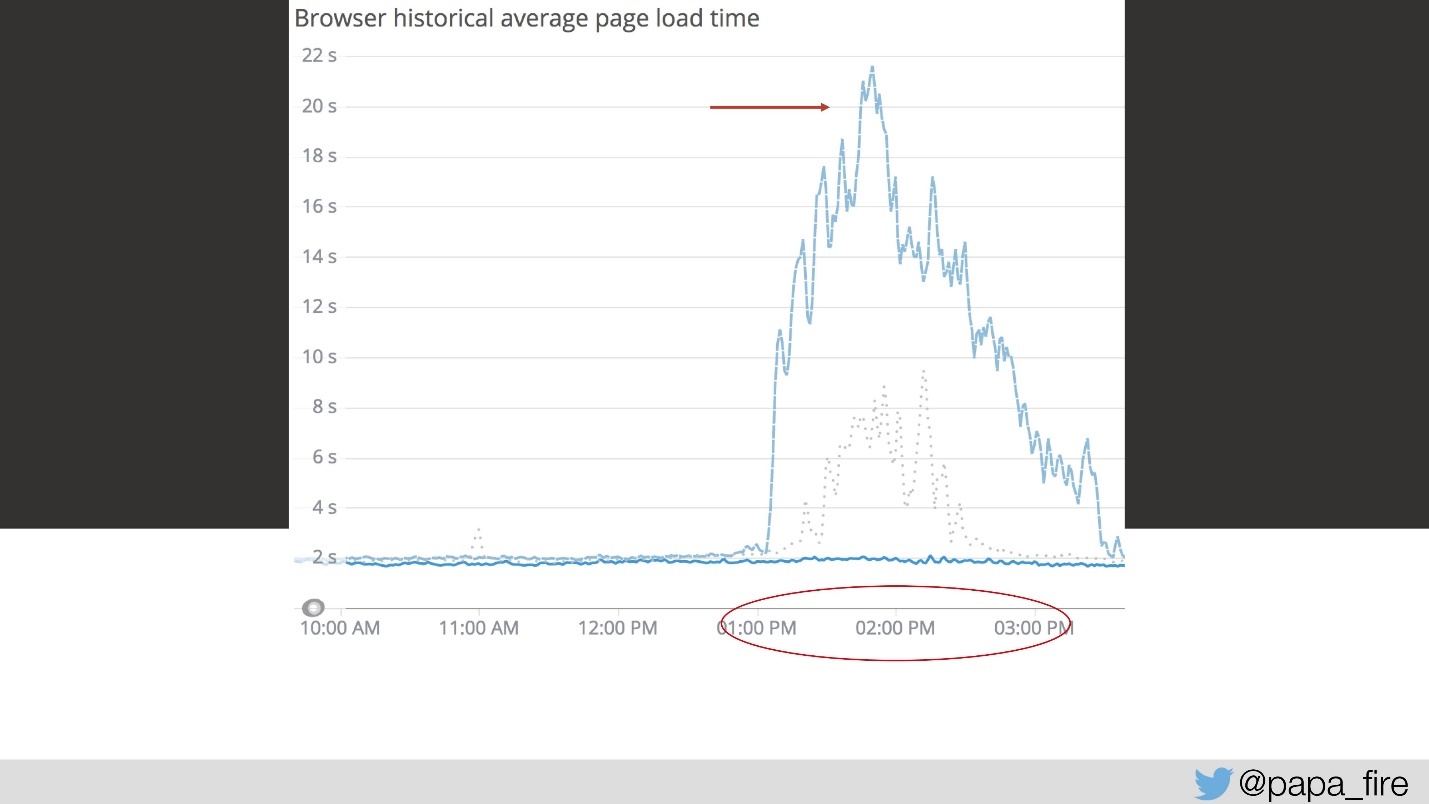
С моей точки зрения вообще ничего не работало. С точки зрения всех остальных работало немного медленнее, чем обычно. Но просто так так не бывает — это серьезная проблема.
Я пытался убедить команду, на что мне отвечали, что просто нужно больше серверов. Это, конечно, решение проблемы, но далеко не всегда единственное и самое эффективное. Я спросил, почему не хватает серверов, какой объем трафика. Я экстраполировал данные и получил, что у нас примерно 150 запросов в секунду, что в принципе укладывается в разумные пределы.
Но надо не забывать, что перед тем, как получить правильный ответ, надо задать правильный вопрос. Мой следующий вопрос был: сколько у нас frontend-серверов. Ответ меня «немного озадачил» — у нас было 17 frontend-серверов!
— Стесняюсь спросить, 150 разделить на 17, получится примерно 8? Хотите сказать, что каждый сервер пропускает 8 запросов в секунду, и если завтра будет 160 запросов в секунду, нам нужно будет еще 2 сервера?
Конечно, нам не нужны были дополнительные серверы. Решение находилось в самом коде, причем на поверхности:
var currentClass = classes.getCurrentClass(); return currentClass; Была функция getCurrentClass(), потому что все на сайте работает в контексте класса — правильно. И на одну эту функцию на каждой странице приходилось 200+ запросов.
Решение таким образом было очень простым, даже не надо было ничего переписывать: просто не запрашивать одну и ту же информацию повторно.
if ( !isDefined("REQUEST.currentClass") ) { var classes = new api.private.classes.base(); REQUEST.currentClass = classes.getCurrentClass(); } return REQUEST.currentClass;Я очень обрадовался, потому что решил, что всего на третий день нашел главную проблему. Как я был наивен, это была лишь одна из очень многих проблем.
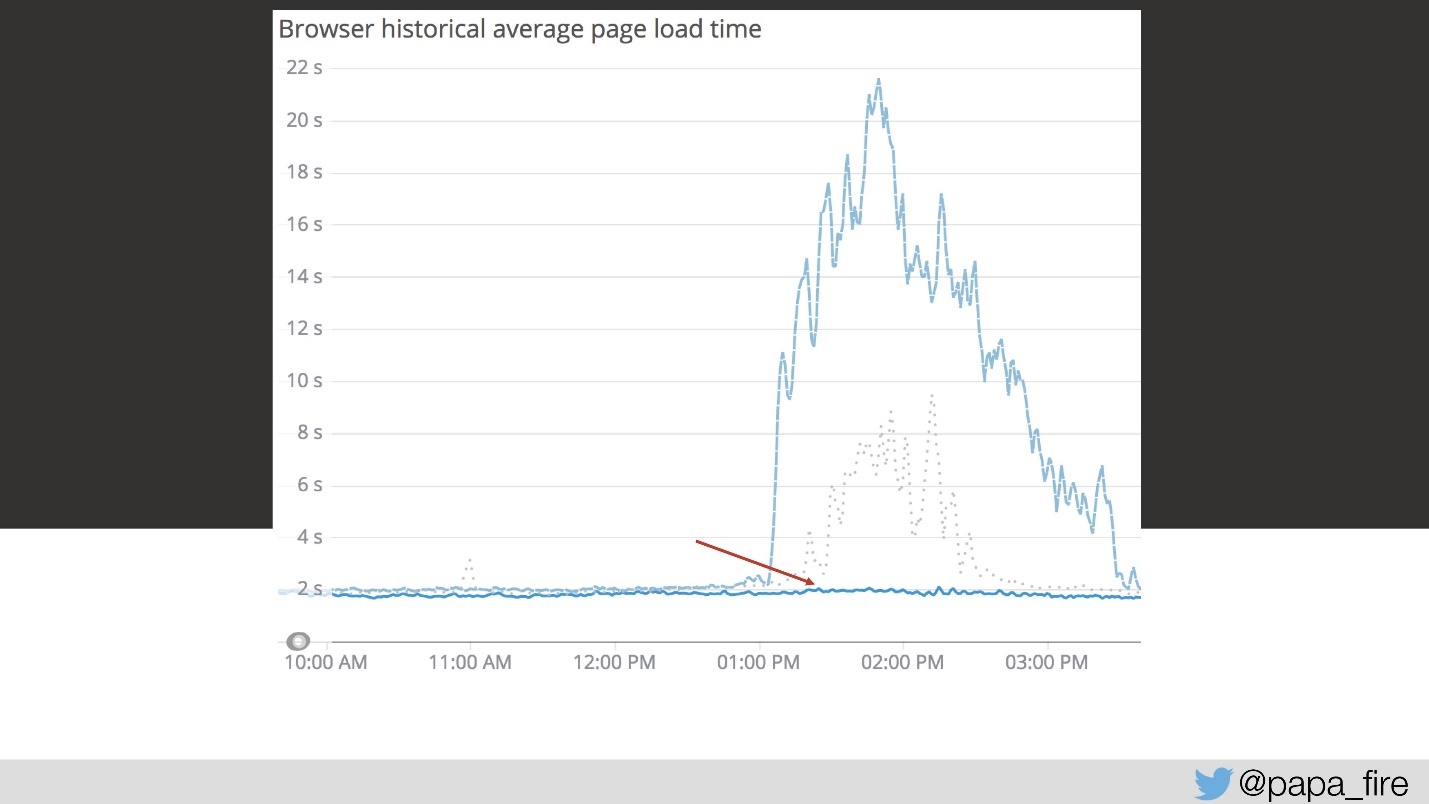
Но решение этой первой проблемы опустило график гораздо ниже.
В то же время мы занимались другими оптимизациями. На виду было много всего, что можно починить. Например, в тот же третий день я обнаружил, что в системе все-таки был кэш (сначала я подумал, что все запросы идут сразу из базы данных). Когда я думаю о кэше, представляю стандартные Redis или Memcached. Но так думал только я, потому что для кэширования в той системе использовались MongoDB и SQL Server — тот же, из которого только что прочитали данные.
День десятый
Первую неделю я разбирался с проблемами, которые нужно было решать прямо сейчас. Где-то на второй неделе я первый раз пришел на стендап пообщаться с командой, посмотреть, что происходит и как идет весь процесс.
Опять обнаружилось интересное. Команда состояла из: 18 разработчиков; 8 тестировщиков; 3 менеджеров; 2 архитекторов. И все они участвовали в общих ритуалах, то есть больше 30 человек приходили на стендап каждое утро и рассказывали, что они делали. Понятно, что встреча занимала не 5 и не 15 минут. Никто никого не слушал, потому что все работают на разных системах. В таком виде 2-3 тикета за час на grooming session уже были хорошим результатом.
Первое, что мы сделали, — это разделили команду на несколько по линии продуктов. Для разных секций и систем мы выделили отдельные команды, которые включали разработчиков, тестировщиков, продакт-менеджеров, бизнес-аналитиков.
В результате получили:
- Сокращение стендапов и митингов.
- Предметное знание продукта.
- Чувство собственности. Когда раньше люди все время ратировались по системам, они знали, что работать с их багами скорее всего придется кому-то еще, но не им самим.
- Сотрудничество между группами. Можно не говорить, что QA с программистами до этого не сильно общались, продакт делал свое собственное дело и т.д. Теперь у них появилась общая точка ответственности.
В основном мы фокусировались на эффективности, производительности и качестве — именно эти проблемы мы пытались решить трансформацией команды.
День одиннадцатый
В процессе изменения структуры команды я обнаружил, как подсчитывают StoryPoints. 1 SP был равен одному дню, а каждый тикет у них содержал SP и на разработку, и на QA, то есть как минимум 2 SP.
Как я это обнаружил?
Нашли баг: в одном из отчетов, где вводится дата начала и конца периода, за который нужен отчет, не учитывается последний день. То есть где-то в запросе стояло не <=, а просто <. Мне сказали, что это три Story Points, то есть 3 дня.
После этого мы:
- Пересмотрели систему оценки Story Points. Теперь исправление мелких багов, которые можно быстро пропустить через систему, быстрее доходит до пользователя.
- Начали объединять связанные тикеты для разработки и тестирования. Раньше каждый тикет, каждый баг был замкнутой экосистемой, непривязанной ни к чему другому. Изменение трёх кнопок на одной странице могло быть тремя разными тикетами с тремя разными QA-процессами вместо одного автоматического теста на странице.
- Стали работать с разработчиками над подходом к оценке трудозотрат. Три дня, чтобы поменять одну кнопку — это не смешно.
День двадцатый
Где-то к середине первого месяца ситуация чуть-чуть стабилизировалась, я разобрался с тем, что в основном происходит, и уже начал смотреть в будущее и думать и долгосрочных решениях.
Долгосрочные цели:
- Управляемая платформа. Сотни запросов на каждой странице — это несерьезно.
- Предсказуемые тенденции. Были периодические пики трафика, которые на первый взгляд не коррелировали с другими метриками — нужно было понять, почему такое случается и научиться предсказывать.
- Расширение платформы. Бизнес постоянно растет, приходит все больше пользователей, увеличивается трафик.
В прошлом часто говорили: «Давайте все перепишем на [язык/фреймворк], все станет работать лучше!»
В большинстве случаев это не срабатывает, хорошо, если переписанное вообще будет работать. Поэтому нам нужно было создать roadmap — конкретную стратегию, иллюстрирующую шаг за шагом, как будут достигнуты бизнес-цели (что мы будем делать и для чего), которая:
- отражает миссию и цели проекта;
- приоритезирует основные цели;
- содержит график их достижения.
До этого никто не разговаривал с командой о том, для какой цели делаются любые изменения. Для этого нужны правильные показатели успеха. Первый раз в истории компании мы поставили KPI для технической группы, причем эти показатели привязали к организационным.
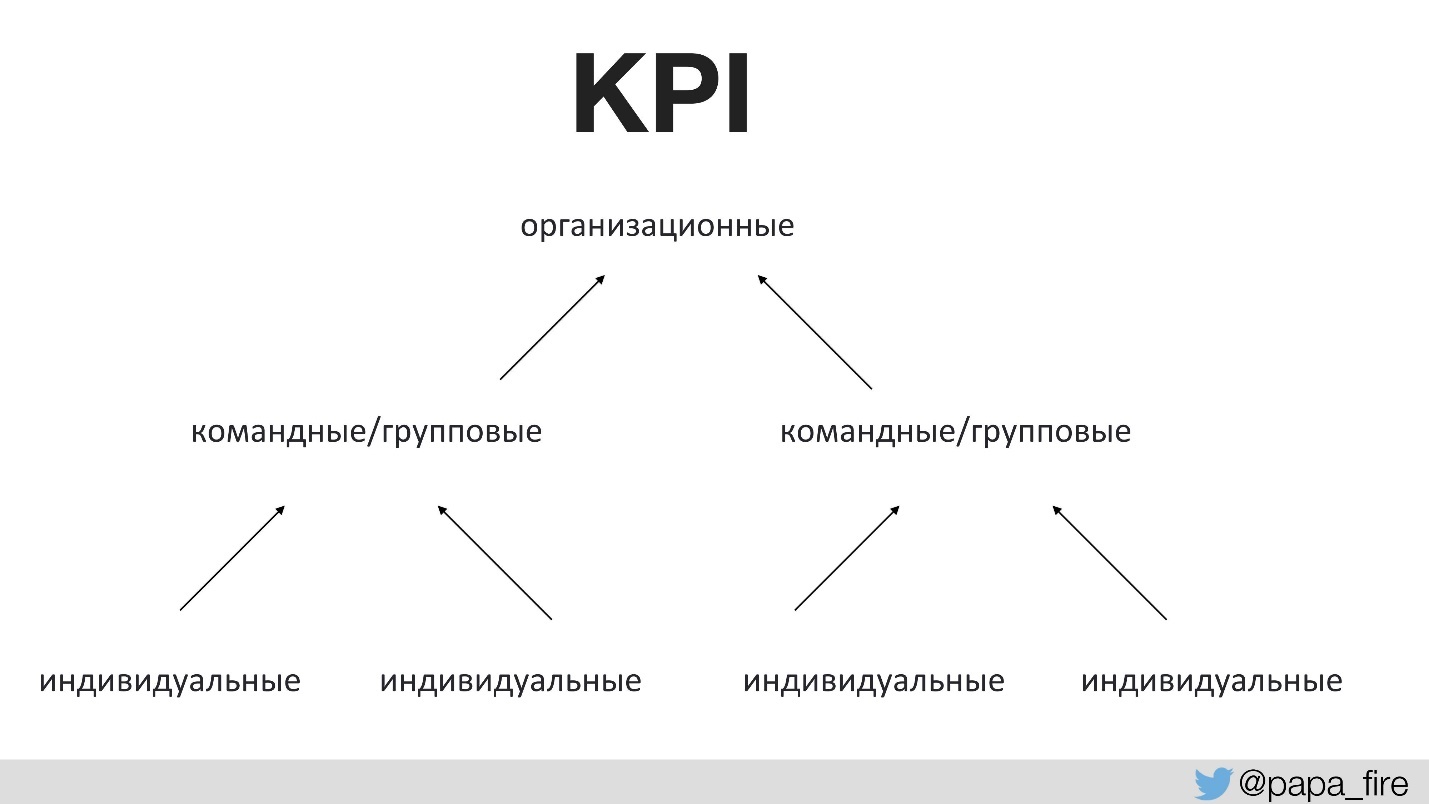
То есть организационные KPI поддерживаются командами, а командные KPI поддерживаются уже индивидуальными. В противном случае, если технологические KPI не сходятся с организационными, то каждый тянет одеяло на себя.
Например, один из организационных KPI — это увеличение доли рынка посредством новых продуктов.
Чем можно поддержать цель иметь больше новых продуктов?
- Во-первых, мы хотим тратить больше времени на разработку новых продуктов вместо того, чтобы чинить дефекты. Это логичное решение, которое легко измеряется.
- Во-вторых, мы хотим поддерживать увеличение объема транзакций, потому что чем больше доля на рынке, тем больше пользователей и, соответственно, тем больше трафика.
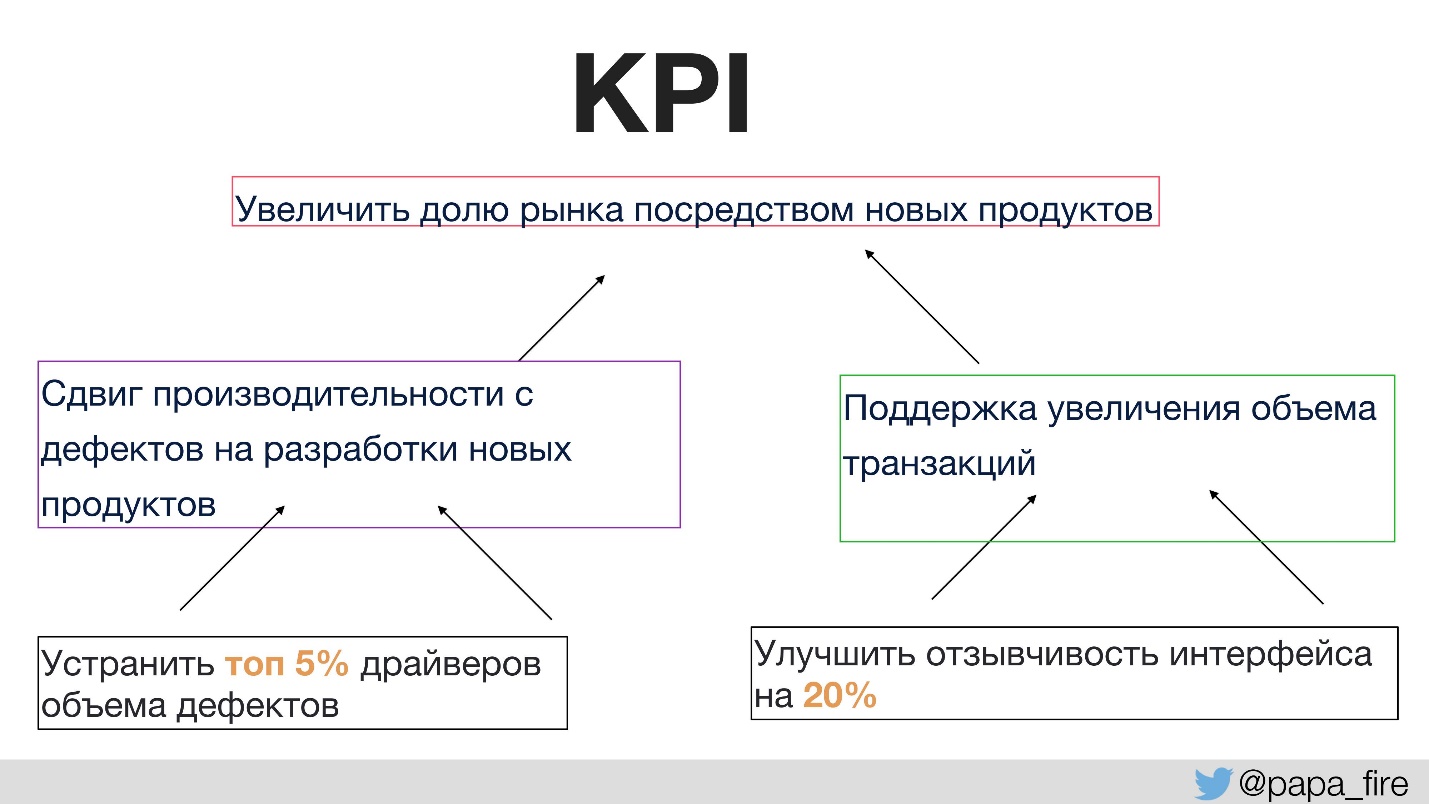
Тогда индивидуальные KPI, которые могут исполняться внутри группы будут, например, будут в том месте, откуда идут основные дефекты. Если сфокусироваться именно на этой секции, можно сделать так, что дефектов станет гораздо меньше, и тогда увеличится время на разработку новых продуктов и опять же на поддержку организационных KPI.
Таким образом каждое решение, в том числе переписать код, должно поддерживать конкретные цели, которые компания перед нами поставила (рост организации, новые функции, набор персонала).
Во время этого процесса выявилась интересная вещь, которая стала новостью не только для технарей, но вообще в компании: все тикеты должны быть ориентированы как минимум на один KPI. То есть если продакт говорит, что хочет сделать новую фичу, первый вопрос должен быть задан: «Какой KPI эта фича поддерживает?» Если никакой, то извините — кажется, это ненужная фича.
День тридцатый
В конце месяца я обнаружил еще один нюанс, что никто из моей Ops-команды никогда не видел контракты, которые мы заключаем с клиентами. Вы можете спросить, зачем видеть контакты.
- Во-первых, потому что в контрактах прописаны SLA.
- Во-вторых, SLA все разные. Каждый клиент приходил со своими требованиях, а отдел продаж подписывал не глядя.
Еще интересный нюанс — в контракте с одним из самых больших клиентов написано, что все версии софта, которые поддерживает платформа, должны быть n-1, то есть не самая последняя версия, а предпоследняя.
Понятно, как мы были далеки от n-1, если платформа была на ColdFusion и SQL Server 2008 года, который в июле перестали поддерживать вообще.
День сорок пятый
Где-то к середине второго месяца у меня освободилось достаточно времени, чтобы сесть и сделать valuestreammapping полностью на весь процесс. Это необходимые шаги, которые нужно предпринять, от создания продукта до доставки его потребителю, причем расписать их нужно максимально подробно.
Разбиваешь процесс на маленькие куски и смотришь, что занимает слишком много времени, что можно оптимизировать, улучшить и т.д. Например, сколько времени занимает запрос от продукта, проход через grooming, когда он дойдет до тикета, который разработчик может взять, QA и т.д. Так подробно смотришь на каждый отдельный шаг и думаешь, что можно оптимизировать.
Когда я это делал, в глаза бросились две вещи:
- высокий процент возврата тикетов из QA обратно разработчикам;
- pull request review занимали слишком много времени.
Проблема была в том, что это были выводы вроде: кажется, много времени занимает, но мы не уверены, сколько именно.
«Нельзя улучшить то, что нельзя измерить».
Как обосновать, насколько проблема серьезная? Из-за неё тратятся дни или часы?
Чтобы это измерить, добавили пару шагов в Jira-процесс: «ready for dev» и «ready for QA», чтобы измерять, сколько времени каждый тикет ждет и сколько раз возвращается на определенный шаг.
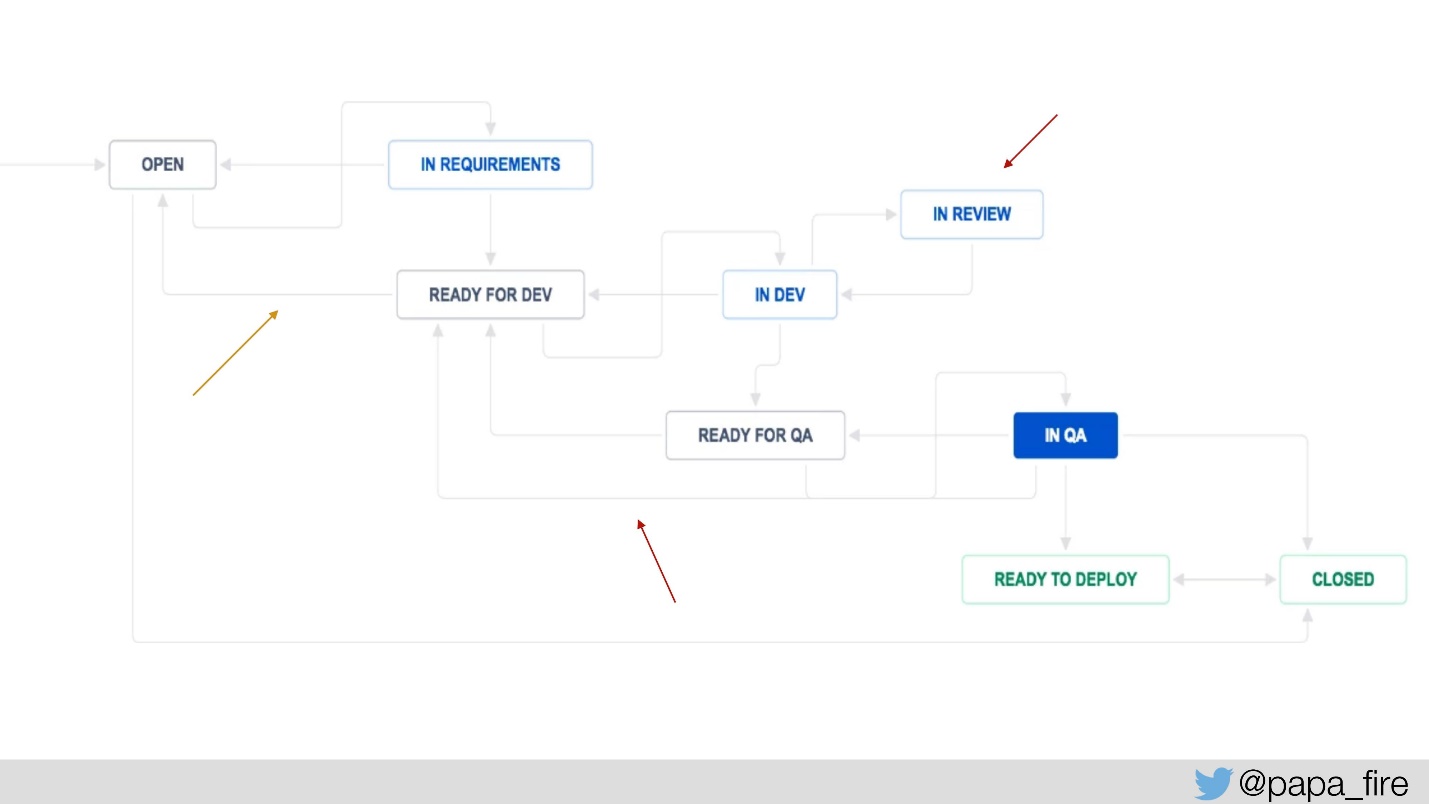
Также мы добавили «in review», чтобы знать, сколько в среднем тикеты находятся на review, и от этого уже танцевать. Системные метрики у нас были, теперь мы добавили новые метрики, и стали измерять:
- Эффективность процесса: производительность и запланировано/доставлено.
- Качество процесса: количество дефектов, дефекты от QA.
Это действительно помогает понимать, что проходит хорошо, а что плохо.
День пятидесятый
Это все, конечно, хорошо и интересно, но ближе к концу второго месяца случилось то, что в принципе, было предсказуемо, хотя я и не ожидал такого масштаба. Люди начали уходить, потому что поменялась верхушка. В руководство пришли новые люди, которые начали все менять, и старые увольнялись. А обычно в компании, которой несколько лет, все друзья и все друг друга знают.
Это было ожидаемо, но неожиданным был масштаб увольнений. Например, в одну неделю два тимлида одновременно подали заявление на увольнение по собственному желанию. Поэтому мне пришлось не то, что забыть о других проблемах, но сфокусироваться на создании коллектива. Это долгая и труднорешаемая проблема, но ей надо было заниматься, потому что хотелось сохранить людей, которые остались (или большинство из них). Надо было как-то реагировать на то, что люди ушли, чтобы поддерживать мораль в команде.
В теории это хорошо: приходит новый человек, у которого есть полный карт-бланш, который может оценить навыки команды и заменить кадры. На самом деле нельзя просто так привести новых людей по очень многим причинам. Всегда нужен баланс.
- Старого и нового. Нужно сохранить старых людей, которые могут поменяться и поддерживать миссию. Но в то же время нужно привнести новую кровь, об этом мы поговорим чуть позже.
- Опыта. Я много говорил с хорошими джуниорами, которые горели и хотели к нам на работу. Но я не мог их взять, потому что было недостаточно сеньоров, которые бы поддерживали джуниоров и были для них менторами. Надо было сначала набрать верхушку и только потом молодежь.
- Кнута и пряника.
У меня нет хорошего ответа на вопрос, какой баланс правильный, как его поддерживать, сколько людей оставлять и насколько давить. Это чисто индивидуальный процесс.
День пятьдесят первый
Я стал присматриваться к команде, чтобы понять, кто у меня есть, и в очередной раз вспомнил:
«Большинство проблем — это проблемы с людьми».
Я обнаружил, что в команде, как таковой — и у разработчиков, и у Ops — есть три большие проблемы:
- Удовлетворенность текущим положением вещей.
- Отсутствие ответственности — потому что никто никогда не приводил результаты работы исполнителей к влиянию на бизнес.
- Боязнь перемен.

Перемены всегда выводят из зоны комфорта, и чем младше люди, тем больше они не любят перемены, потому что они не понимают, зачем, и не понимают, как. Самый частый ответ, который я слышал: «Мы так никогда не делали». Причем доходило до полнейшего абсурда — малейшие изменения не проходили без того, чтобы кто-то не возмутился. Причем неважно, насколько изменения касались именно их работы, люди говорили: «Нет, зачем? Это не сработает».
Но нельзя стать лучше, ничего не меняя.
У меня был абсолютно абсурдный разговор с сотрудником, я рассказывал ему свои идеи по оптимизации, на что он мне сказал:
— А, это ты не видел, что у нас было в прошлом году!
— Ну и что?
— Сейчас гораздо лучше, чем было.
— Так что, не может быть еще лучше?
— А зачем?
Хороший вопрос — зачем? Как будто, если сейчас лучше, чем было, значит, всё достаточно хорошо. Это приводит к отсутствию ответственности, что в принципе абсолютно нормально. Как я сказал, техгруппа была немного в стороне. В компании считали, что они должны быть, но никто никогда не устанавливал стандарты. В техподдержке никогда не видели SLA, поэтому для группы было вполне «приемлемо» (и это меня поразило больше всего):
- 12 секунд загрузка;
- 5-10 минут downtime каждый релиз;
- устранение критических неполадок занимает дни и недели;
- отсутствие дежурных 24х7 / on-call.
Никто никогда не пытался спросить, почему бы нам не сделать это лучше, и никто никогда не понимал, что так не должно быть.
Как бонус, была еще одна проблема: отсутствие опыта. Сеньоры ушли, а оставшаяся молодая команда выросла при прежнем режиме и была им отравлена.
Ко всему этому люди еще и боялись потерпеть неудачу, показаться некомпетентными. Это выражается в том, что они, во-первых, ни при каких обстоятельствах не просили помощи. Сколько раз мы разговаривали в группе и индивидуально, и я говорил: «Задайте вопрос, если не знаете, как что-то сделать». Я уверен в себе и знаю, что могу решить любую проблему, но это займет время. Поэтому если можно спросить кого-то, кто знает, как ее решить за 10 минут, я спрошу. Чем меньше у тебя опыта, тем больше ты боишься спрашивать, потому что думаешь, что тебя посчитают некомпетентным.
Эта боязнь задать вопрос проявляется в интересных формах. Например, спрашиваешь: «Как дела с этой задачей?» —«Осталось на пару часов, уже заканчиваю». На следующий день снова спрашиваешь, получаешь ответ, что все хорошо, но возникла одна проблемка, до конца дня точно будет готово. Проходит еще день, и пока не прижмешь к стенке и не заставишь с кем-то поговорить, так всё и продолжается. Человеку хочется решить задачу самому, он считает, что если сам не решит, это будет большой неудачей.
Именно поэтому разработчики завышали оценки. Это был тот еще анекдот, когда обсуждали определенную задачу, мне выдали такую цифру, что я очень удивился. На что мне сказали, что в estimates разработчик включает и время, которое тикет будет возвращаться из QA, потому что они найдут там ошибки, и время, которое займет PR, и время пока люди, которые должны его просмотреть, будут заняты — то есть все, что только возможно.
Во-вторых, люди, которые бояться показаться некомпетентным, излишне анализируют. Когда говоришь, что конкретно нужно сделать, начинается: «Нет, а что, если мы здесь подумаем?» В этом смысле наша компания не уникальна, это стандартная проблема молодежи.
В ответ я ввел следующие практики:
- Правило 30 минут. Если за полчаса вы не можете решить проблему, попросите кого-нибудь помочь. Это работает с переменным успехом, потому что народ все равно не просит, но хотя бы процесс начался.
- Исключить все, кроме сути, в оценке срока выполнения задачи, то есть считать только то, сколько времени займет написание кода.
- Непрерывное обучение для тех, кто излишне анализирует. Это просто постоянная работа с людьми.
День шестидесятый
Пока я всем этим занимался, пришло время разобраться с бюджетом. Конечно, я нашел много интересного в том, куда мы тратили деньги. Например, у нас была целая стойка в отдельном дата-центре, на которой стоял один FTP-сервер, который использовался одним клиентом. Оказалось, что «… мы переезжали, а он так и остался, мы его не поменяли». Это было 2 года назад.
Особый интересе представлял счет за услуги облака. Я уверен, что основная причина большого счета за облачные услуги — это разработчики, у которых первый раз в жизни есть неограниченный доступ к серверам. Им не нужно просить: «Дайте мне, пожалуйста, тестовый сервер», — они могут сами взять. Плюс к этому разработчики всегда хотят построить такую крутую систему, чтобы Facebook с Netflix обзавидовались.
Но у разработчиков нет опыта закупки серверов и навыка определения нужного размера серверов, потому что им это раньше не было нужно. И обычно они не вполне понимают разницу между scalability и performance.
Результаты инвентаризации:
- Вышли из одного дата-центра.
- Расторгли договор с 3 лог-сервисами. Потому что у нас их было 5 — каждый разработчик, который начинал с чем-то играться, брал новый.
- Выключили 7 AWS-систем. Опять же, умершие проекты никто не останавливал, они все так и продолжали работать.
- Уменьшили расходы на софт в 6 раз.
День семдесят пятый
Время шло, и через два с половиной месяца я должен был встретиться с с советом директоров. Наш совет директоров не лучше и не хуже других, он как все советы директоров хочет знать всё. Люди вкладывают деньги и хотят понимать, насколько то, что мы делаем, укладывается в поставленные KPI.
Совет директоров получает много информации каждый месяц: количество пользователей, их рост, какими сервисами они пользуются и как, производительность и продуктивность, наконец, среднюю скорость загрузки страницы.
Проблема только в том, что я считаю, что средняя величина — это чистое зло. Но совету директоров это объяснить очень трудно. Они привыкли оперировать агрегированными числами, а не, например, разбросом времени загрузки в секунду.
В связи с этим были интересные моменты. Например, я сказал, что нужно разделить трафик между отдельными веб-серверами в зависимости от типа контента.

То есть ColdFusion проходит через через Jetty и nginx и запускал страницы. А картинки, JS и CSS идут через отдельный nginx со своими конфигурациями. Это довольно стандартная практика, о которой я писал еще пару лет назад. В результате картинки загружаются гораздо быстрее, и … средняя скорость загрузки увеличилась на 200 мс.
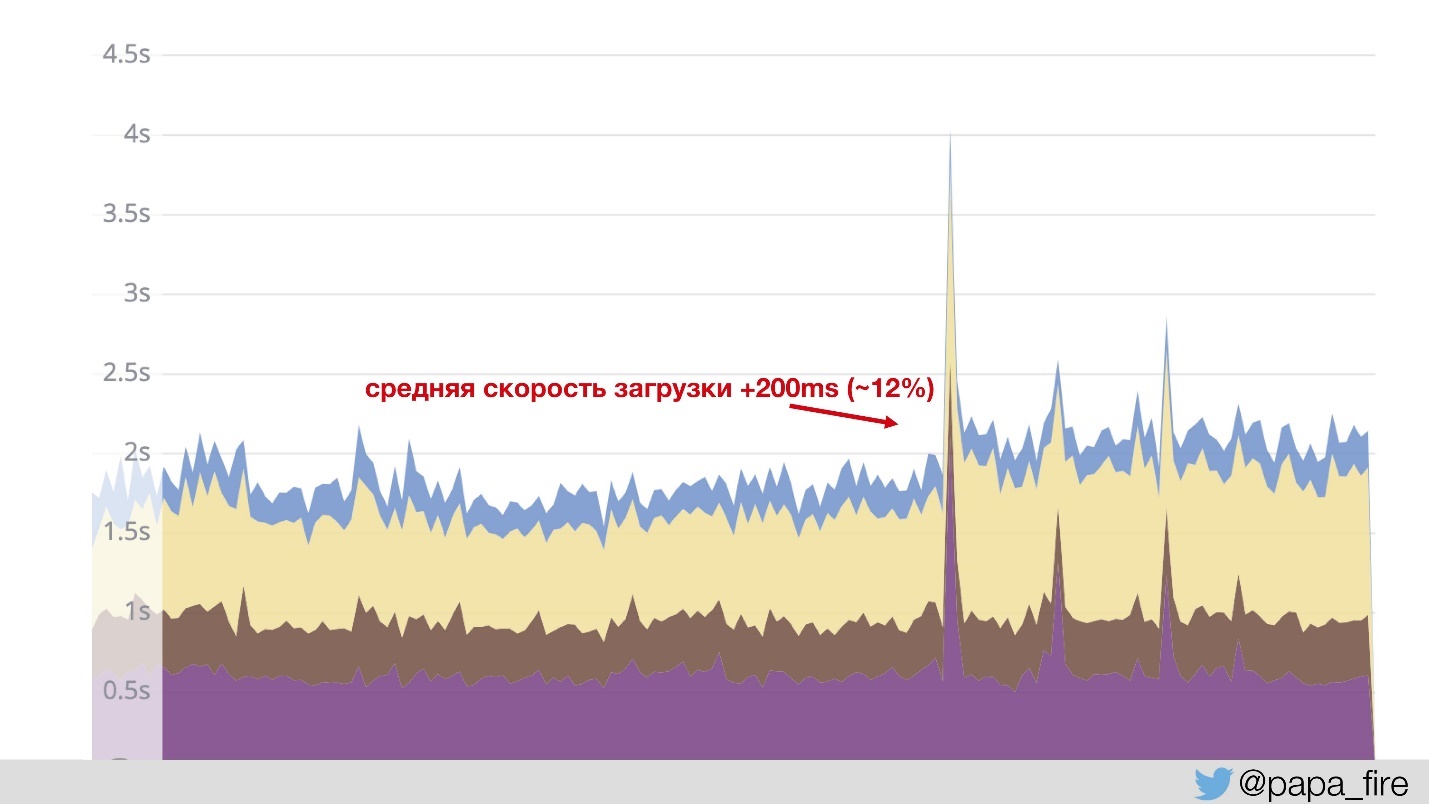
Это произошло потому, что график строится на основе данных, которые идут с Jetty. То есть быстрый контент в расчет не попадает — средняя величина подскочила. Нам это было понятно, мы посмеялись, но как объяснить совету директоров, почему мы что-то сделали и стало хуже на 12%?
День восемдесят пятый
Под конец третьего месяца я понял, что на одну вещь я совсем не рассчитывал — это время. На все, о чем я рассказывал, требуется время.

Это мой настоящий календарь на неделю — просто рабочая неделя, не очень нагруженная. Времени на всё не хватает. Поэтому опять-таки нужно набирать людей, которые помогут справиться с проблемами.
Заключение
Это совсем не всё. В этом рассказе я еще даже не дошел до того, как мы работали с продуктом и пытались настроиться на общую волну, или как интегрировали техподдержку, или как решали другие технические проблемы. Например, я совершенно случайно узнал, что на самых больших таблицах в базе данных мы не пользуемся SEQUENCE. У нас есть самописная функция nextID, и используется она не в транзакции.
Был еще миллион подобных вещей, о которых можно долго говорить. Но самое важное, о чем еще стоит сказать, — это культура.

Именно культура или её отсутствие ведет ко всем остальным проблемам. Мы пытаемся построить культуру, где люди:
- не боятся неудач;
- учатся на ошибках;
- сотрудничают с другими командами;
- проявляют инициативу;
- берут ответственность на себя;
- приветствуют результат как цель;
- празднуют успех.
С этим все остальное придет.
Леон Файер в twitter, facebook и на medium.
В отношении legacy есть две стратегии: всеми силами избегать работы с ним, или отважно преодолевать сопутствующие трудности. Мы c DevOpsConf идем по второму пути, меняя процессы и подходы. Присоединяйтесь к нам в youtube, рассылке и телеграме, и будем вместе внедрять культуру DevOps.
ссылка на оригинал статьи https://habr.com/ru/company/oleg-bunin/blog/480626/
Добавить комментарий