На сегодняшний день существуют готовые (проприетарные) решения для мониторинга IP(TS)-потоков, например VB и iQ, они обладают достаточно богатым набором функций и обычно подобные решения имеются у крупных операторов, имеющих дело с ТВ-сервисами. В этой статье описывается решение на базе open source проекта TSDuck, предназначенное для минимального контроля IP(TS)-потоков по счётчику CC(continuity counter) и битрейту. Возможный вариант применения — контроль потери пакетов или потока целиком через арендованный L2-канал (который нет возможности нормально мониторить, например путём считывания счётчиков потерь в очередях).
Очень кратко о TSDuck
TSDuck это open source (лицензия 2-Clause BSD) ПО (набор консольных утилит и библиотека для разработки своих утилит или плагинов) для манипуляций с TS-потоками. В качестве входа умеет работать с IP (multicast/unicast), http, hls, dvb-тюнерами, dektec dvb-asi демодулятором, имеется внутренний генератор TS-потока и чтение из файлов. В качестве выхода может быть запись в файл, IP (multicast/unicast), hls, dektec dvb-asi и HiDes модуляторы, плееры (mplayer, vlc, xine) и drop. Между входом и выходом можно включить различные процессоры трафика, например перемаппинг PID-ов, делать скремблирование/дескремблирование, анализ CC-счётчиков, подсчёт битрейта и прочие типовые для TS-потоков операции.
В данной статье в качестве входа будут IP-потоки (multicast), использованы процессоры bitrate_monitor (из названия понятно что это такое) и continuity (анализ CC-счётчиков). Без особых проблем можно заменить IP multicast на другой тип входа, поддерживаемый TSDuck.
Имеются официальные сборки/пакеты TSDuck для большинства актуальных ОС. Для Debian их нет, но удалось без проблем собрать под debian 8 и debian 10.
Далее используется версия TSDuck 3.19-1520, в качестве ОС используется Linux (для подготовки решения использовался debian 10, для реального использования — CentOS 7)
Подготовка TSDuck и ОС
Прежде чем мониторить реальные потоки нужно убедиться что TSDuck корректно работает и не происходят дропы на уровне сетевой карты или ОС(сокета). Это требуется для того, чтобы потом не гадать где произошли дропы — на сети или «внутри сервера». Проверять дропы на уровне сетевой карты можно командой ethtool -S ethX, тюнинг делается той же ethtool (обычно, нужно увеличивать RX-буфер (-G) и иногда отключать некоторые offloads (-K)). В качестве общей рекомендации можно посоветовать использовать отдельный порт для приёма анализируемого трафика, если имеется такая возможность, это минимизирует ложные срабатывания связанные с тем, что дроп случился кокрентно на порту анализатора из-за наличия другого трафика. Если такой возможности нет (используется мини-компьютер/NUC с одним портом), то очень желательно настроить приоритезацию анализируемого трафика по отношению к остальному на устройстве, в который подключается анализатор. Относительно виртуальных сред, здесь нужно быть осторожным и уметь находить дропы пакета начиная от физического порта и заканчивая приложением внутри виртуальной машины.
Генерация и приём потока внутри хоста
В качестве первого шага подготовки TSDuck будем генеририровать и принимать трафик внутри одного хоста с использованием netns.
Готовим окружение:
ip netns add P #создаём netns P, в нём будет происходить анализ трафика ip link add type veth #создаём veth-пару - veth0 оставляем в netns по умолчанию (в этот интерфейс будет генерироваться трафик) ip link set dev veth1 netns P #veth1 - помещаем в netns P (на этом интерфейсе будет приём трафика) ip netns exec P ifconfig veth1 192.0.2.1/30 up #поднимаем IP на veth1, не имеет значения какой именно ip netns exec P ip ro add default via 192.0.2.2 #настраиваем маршрут по умолчанию внутри nents P sysctl net.ipv6.conf.veth0.disable_ipv6=1 #отключаем IPv6 на veth0 - это делается для того, чтобы в счётчик TX не попадал посторонний мусор ifconfig veth0 up #поднимаем интерфейс veth0 ip route add 239.0.0.1 dev veth0 #создаём маршрут, чтобы ОС направляла трафик к 239.0.0.1 в сторону veth0
Окружение готово. Запускаем анализатор трафика:
ip netns exec P tsp --realtime -t \ -I ip 239.0.0.1:1234 \ -P continuity \ -P bitrate_monitor -p 1 -t 1 \ -O drop
где «-p 1 -t 1» означает что нужно расчитывать битрейт каждую секунду и выводить информацию о битрейте каждую секунду
Запускаем генератор трафика со скорость 10Мбит/с:
tsp -I craft \ -P regulate -b 10000000 \ -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
где «-p 7 -e» означает, что нужно паковать по 7 TS-пакетов в 1 IP-пакет и делать это жёстко (-e), т.е. всегда дожидаться 7 TS-пакетов от последнего процессора перед отправкой формированием IP-пакета.
Анализатор начинает выводить ожидаемые сообщения:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s * 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s * 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/s
Теперь добавляем немного дропов:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROP
и появляются сообщения тип таких:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets * 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets
что является ожидаемым. Отключаем потерю пакетов (ip netns exec P iptables -F) и пробуем увеличить битрейт генератора до 100Мбит/с. Анализатор рапортует кучу CC-ошибок и около 75 Мбит/с вместо 100. Пытаемся разобраться кто виноват — не успевает генератор или же проблема не в нём, для этого запускаем генерацию фиксированного количества пакетов (700000 TS-пакетов = 100000 IP-пакетов):
# ifconfig veth0 | grep TX TX packets 151825460 bytes 205725459268 (191.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234 * count: PID 0 (0x0000): 700,000 packets # ifconfig veth0 | grep TX TX packets 151925460 bytes 205861259268 (191.7 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Как видно, было сгенерировано ровно 100000 IP-пакетов (151925460-151825460). Значит разбираемся что происходит с анализатором, для этого сверяем со счётчиком RX на veth1, он строго равен счётчику TX на veth0, далее смотрим что происходит на уровне сокета:
# ip netns exec P cat /proc/net/udp sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops 133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355
Здесь видно количество дропов = 24355. В TS-пакетах это 170485 или 24.36% от 700000, таким образом видим что те самые 25% потерянного битрейта это дропы в udp-сокете. Дропы в UDP-сокете обычно возникают из-за нехватки буфера, смотрим чему равен размер буфера сокета по умолчанию и максимальный размер буфера сокета:
# sysctl net.core.rmem_default net.core.rmem_default = 212992 # sysctl net.core.rmem_max net.core.rmem_max = 212992
Таким образом, если приложения не запрашивают размер буфера явно, сокеты создаются с буфером размером 208 Кб, но если запросят больше, то всё равно не получат запрашиваемое. Поскольку в tsp для IP-входа можно задать размер буфера (—buffer-size), то размер сокета по умолчанию трогать не будем, а лишь зададим максимальный размер буфера сокета и укажим размер буфера явно через аргументы tsp:
sysctl net.core.rmem_max=8388608 ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O drop
С таким тюнингом буфера сокета теперь рапортуемый битрейт составляет примерно 100Мбит/с, CC-ошибок нет.
По потреблению CPU самим приложением tsp. Относительно одного ядра i5-4260U CPU @ 1.40GHz для анализа потока 10Мбит/с потребуется 3-4% CPU, 100 Мбит/с — 25%, 200Мбит/с — 46%. При задании % потери пакетов, нагрузка на CPU практически не увеличивается (но может уменьшаться).
На более производительном железе удавалось без проблем генерировать и анализировать потоки более 1Гб/с.
Тестирование на реальных сетевых картах
После тестирования на veth-паре нужно взять два хоста или два порта одного хоста, соединить порты между собой, на одном запустить генератор, на втором анализатор. Тут неожиданностей не случилось, но на самом деле всё зависит от железа, чем слабее, тем интереснее здесь будет.
Использование получаемых данных системой мониторинга (Zabbix)
У tsp нет какого-либо machine-readable API типа SNMP или подобного. Сообщения CC нужно агрегировать хотя бы по 1 секунде (при высоком проценте потери пакетов, их может быть сотни/тысяч/десятки тысяч в секунду, зависит от битрейта).
Таким образом, чтобы сохранять и информацию и нарисовать графики по CC-ошибкам и битрейту и сделать какие-то аварии дальше могут быть следующие варианты:
- Распарсить и сагрегировать (по CC) вывод tsp, т.е. преобразовать его в нужную форму.
- Допилить сам tsp и/или процессорные плагины bitrate_monitor и continuity, чтобы результат выдавался в machine-readable форме, пригодной для системы мониторинга.
- Написать своё приложение поверх библиотеки tsduck.
Очевидно, что с точки трудозатрат вариант 1 самый простой, особенно учитывая то, что сам tsduck написан на низкоуровневом (по современным меркам) языке (C++)
Простенький прототип парсера+агрегатора на bash показал, что на потоке 10Мбит/с и 50% потери пакетов (наихудший вариант), процесс bash потреблял в 3-4 раза больше CPU, чем сам процесс tsp. Такой вариант развития событий неприемлем. Собственно кусок этого прототипа ниже
#!/usr/bin/env bash missingPackets=0 ccErrorSeconds=0 regexMissPackets='^\*\ (.+) - continuity:.*missing ([0-9]+) packets$' missingPacketsTime="" ip netns exec P tsp --realtime -t -I ip -b 8388608 "239.0.0.1:1234" -O drop -P bitrate_monitor -p 1 -t 1 -P continuity 2>&1 | \ while read i do #line example:* 2019/12/28 23:41:14 - continuity: packet index: 6,078, PID: 0x0100, missing 5 packets #line example 2: * 2019/12/28 23:55:11 - bitrate_monitor: 2019/12/28 23:55:11, TS bitrate: 4,272,864 bits/s if [[ "$i" == *continuity:* ]] then if [[ "$i" =~ $regexMissPackets ]] then missingPacketsTimeNew="${BASH_REMATCH[1]}" #timestamp (seconds) if [[ "$missingPacketsTime" != "$missingPacketsTimeNew" ]] #new second with CC error then ((ccErrorSeconds += 1)) fi missingPacketsTime=$missingPacketsTimeNew packets=${BASH_REMATCH[2]} #TS missing packets ((missingPackets += packets)) fi elif [[ "$i" == *bitrate_monitor:* ]] then : #... fi done
Кроме того, что это работает недопустимо медленно, в bash отсутствуют нормальные нити, bash jobs являются самостоятельными процессами и пришлось делать запись раз в секунду значения missingPackets на сайд-эффекте (при получении сообщения о битрейте, которые приходят каждую секунду). В итоге, bash был оставлен в покое и было решено написать обёртку (парсер+агрегатор) на golang. Потребление CPU аналогичного кода на golang в 4-5 раз меньше, чем самого процесса tsp. Ускорение обёртки за счёт замены bash на golang получилось примерно в 16 раз и в целом результат приемлимый (оверхед по CPU на 25% в наихудшем случае). Исходный файл на golang находится здесь.
Запуск обёртки
Для запуска обёртки сделан простейший шаблон сервиса для systemd (здесь). Предполагается, что сама обёртка скомпилирована в бинарный файл (go build tsduck-stat.go), размещённый в /opt/tsduck-stat/. Предполагается что используется golang с поддержкой monotonic clock (>=1.9).
Чтобы создать экземпляр сервиса нужно выполнить команду systemctl enable tsduck-stat@239.0.0.1:1234, затем запустить с помощью systemctl start tsduck-stat@239.0.0.1:1234.
Discovery из Zabbix
Чтобы zabbix мог делать дискавери запущенных сервисов, сделан генератор списка групп (discovery.sh), в формате необходимом для Zabbix discovery, предполагается что он размёщен там же — в /opt/tsduck-stat. Чтобы запускать discovery через zabbix-agent, нужно добавить .conf-файл в директорию с конфигурациями zabbix-agent’а для добавления user-параметра.
Шаблон Zabbix
Созданный шаблон (tsduck_stat_template.xml) содержит правило автообнаружения, прототипы элементов данных, графиков и триггеров.
Краткий чеклист (ну а вдруг кто-то решит воспользоваться)
- Убедиться что tsp не дропает пакеты в «идеальных» условиях (генератор и анализатор подключены напрямую), если есть дропы см. п.2 или текст статьи по этому поводу.
- Сделать тюнинг максимального буфера сокета (net.core.rmem_max=8388608).
- Скомпилировать tsduck-stat.go (go build tsduck-stat.go).
- Положить шаблон сервиса в /lib/systemd/system.
- Запустить сервисы с помощью systemctl, проверить что начали появляться счётчиками (grep «» /dev/shm/tsduck-stat/*). Количество сервисов по количеству мультикаст-потоков. Тут может потребоваться создать маршрут до мультикаст-группы, возможно, отключить rp_filter или создать маршрут до source ip.
- Запустить discovery.sh, убедиться что он генерирует json.
- Подложить конфиг zabbix-агента, перезапустить zabbix-агент.
- Загрузить шаблон в zabbix, применить его к хосту, на котором осуществляется мониторинг и установлен zabbix-agent, подожать около 5 минут, посмотреть что появились новые элементы данных, графики и триггеры.
Результат
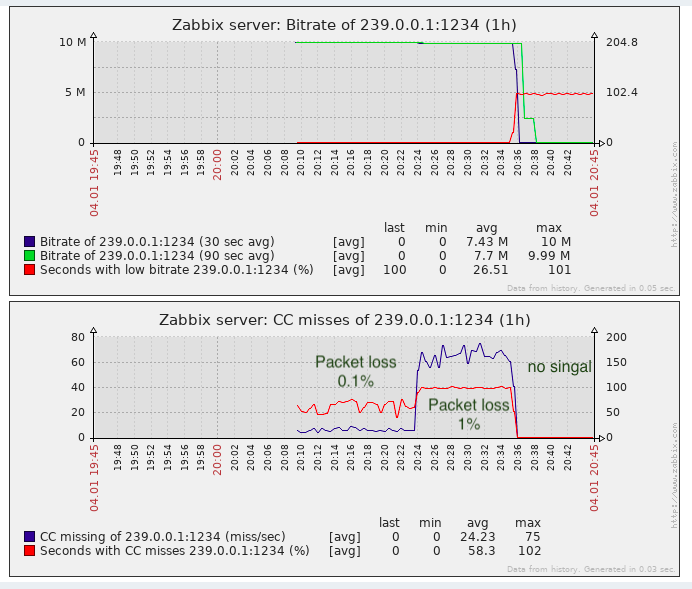
Для задачи выявления потери пакетов почти достаточно, по крайней это лучше чем отсутствие мониторинга.
В самом деле, CC-«потери» могут возникать при склейке видеофрагментов (насколько мне известно, так делаются вставки на местных телецентрах в РФ, т.е. без пересчёта CC-счётчика), это нужно помнить. В проприетарных решениях эта проблема частично обходится детектированием меток SCTE-35 меток (если они добавляются генератором потока).
С точки зрения мониторинга качества транспорта, не хватает мониторинга jitter (IAT), т.к. ТВ-оборудование (будь то модуляторы или конечные устройства) имеет требования к этому параметру и не всегда можно раздувать jitbuffer до бесконечности. А jitter может поплыть когда на транзите используется оборудование с большими буферами и не настроен или недосточно хорошо настроен QoS для передачи подобного realtime-трафика.
ссылка на оригинал статьи https://habr.com/ru/post/482736/
Добавить комментарий