
Задержка выключения pod’а в Kubernetes
Это третья часть нашего пути (прим. пер. — ссылка на первую статью) к достижению нулевого времени простоя при обновлении Kubernetes-кластера. Во второй части мы сокращали время простоя, которое возникло из-за принудительного завершения работающих в pod’ах приложений, завершая их корректно при помощи lifecycle hooks. Однако, мы так же узнали, что pod может продолжать принимать трафик после того, как приложение в нем начало завершение работы. То есть клиент может получить ошибку, потому что его запрос будет направлен на pod, который больше не может обслуживать трафик. В идеале, мы бы хотели, чтобы pod’ы перестали принимать трафик сразу после начала выселения. Чтобы уменьшить риск простоя, нам сначала нужно понять, почему это происходит.
Большая часть информации в этом посте была взята из книги Марко Лукши “Kubernetes in Action”. Вы можете найти выдержку из соответствующего раздела здесь. В дополнение к материалу, описанному здесь, в книге представлен превосходный обзор лучших практик для запуска приложений в Kubernetes, и мы настоятельно рекомендуем прочитать его.
Процесс выключения pod’а
В предыдущем посте мы описали lifecycle выселения pod’а. Как вы помните, первый этап в процессе выселения — это удаление pod’а, которое запускает цепь событий, приводящую к удалению pod’а из системы. Однако, мы не говорили о том, как pod перестает быть endpoint для Service и прекращает принимать трафик.
Так что вызывает удаление pod’а из Service? Мы поймем это, если подробнее рассмотрим процесс удаления pod’а из кластера.
Когда pod удаляется из кластера при помощи API, все что происходит — это его маркировка на сервере с метаданными как подлежащий удалению. Он посылает уведомление об удалении pod’а всем соответствующим подсистемам, которые затем обрабатывают его:
kubeletзапускает процесс удаления, описанный в предыдущем посте.- Демон
kube-proxyудалит IP pod’а изiptablesсо всех нод. - Endpoints controller удалит pod из списка валидных endpoints, в том числе удаляя pod из
Service
Вам не нужно детально знать каждую систему. Главный момент здесь в том, что задействовано несколько систем на разных нодах, причем процесс удаления происходит на них параллельно. Поэтому велика вероятность, что pod запустит хук preStop и получит сигнал TERM намного раньше, чем pod удалится из всех активных списков. Поэтому pod продолжит получать трафик даже после того, как запущен процесс выключения.
Смягчение проблемы
На первый взгляд можно решить, что нам нужно реализовать подход, когда pod не выключается до тех пор, пока не будет исключен из всех списков во всех соответствующих подсистемах. Однако, на практике это сложно сделать из-за распределенной природы Kuberenetes. Что случится, если с одной из нод будет потеряна связь? Будете ли вы бесконечно ждать применения изменений? Что, если нода снова станет online? Что, если у вас есть тысячи нод? Десятки тысяч?
К сожалению, здесь нет идеального решения, при котором время простоя было бы сведено полностью к 0. Что мы можем сделать, так это ввести задержку в процесс выключения, чтобы охватить 99% проблемных случаев. Для этого мы введем sleep в хук preStop, который задержит процесс выключения. Давайте посмотрим как это работает на примере.
Нам понадобится обновить наш конфиг, что бы внести в него задержку как часть хука preStop. В “Kubernetes in Action”, Lukša рекомендует 5-10 секунд, поэтому здесь мы возьмем 5 секунд:
lifecycle: preStop: exec: command: [ "sh", "-c", # Introduce a delay to the shutdown sequence to wait for the # pod eviction event to propagate. Then, gracefully shutdown # nginx. "sleep 5 && /usr/sbin/nginx -s quit", ]
Теперь давайте посмотрим как будет проходить процесс выключения на нашем примере. Как и в предыдущем посте, мы запустим kubectl drain, который выселит pod’ы с ноды. Мы отправим event, который уведомит об удалении pod’а kubelet и Endpoint Controller (который управляет Service endpoints) одновременно. Здесь, мы предполагаем, что хук preStop запустится прежде чем контроллер удалит pod.
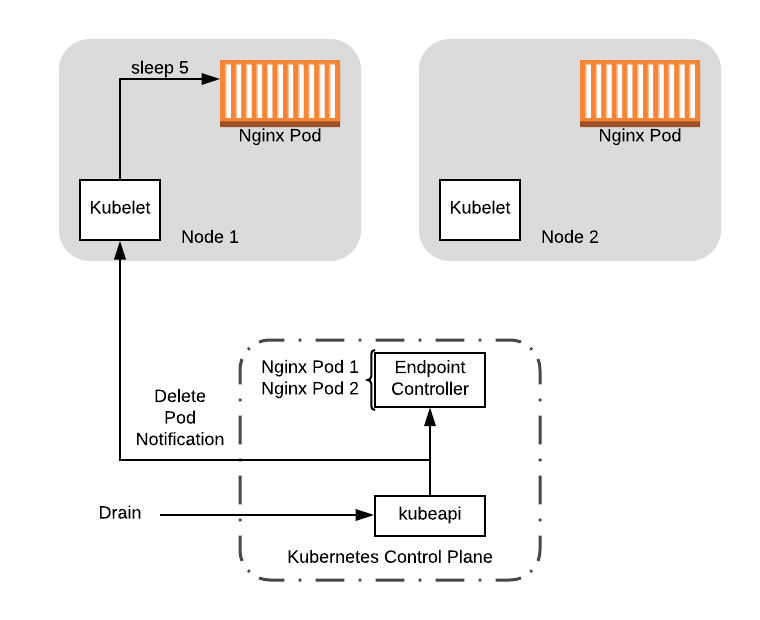
Drain node удалит pod, который в свою очередь отправит event об удалении
С момента когда хук preStop запускается, начинается задержка для процесса выключения на пять секунд. В течение этого времени Endpoint Controller удалит pod:

Pod удаляется контроллером, пока длится задержка процесса выключения
Обратите внимание, что во время задержки pod продолжает работать и, если он примет подключение, то сможет его обработать. К тому же, если какой-либо клиент попытается подключится к pod’у, когда тот удален из контроллера, их не направят на отключенный pod. Согласно данному сценарию, при условии, что контроллер обрабатывает event в течение времени задержки, у нас не будет простоя.
В итоге, что бы завершить картину, хук preStop завершает выполнение sleep и выключает pod с Nginx, удаляя pod с ноды:


С этого момента можно безопасно делать любые обновления на Node 1, включая перезагрузку ноды для загрузки новой версии ядра. Мы также можем отключить ноду, если мы уже запустили новую, на которой могут размещаться рабочие приложения.
Пересоздание pod’ов
Если вы зашли настолько далеко, вам должно быть интересно, как мы пересоздаем pod’ы, которые изначально были распределены на ноду. Теперь мы знаем как корректно завершать работу pod’ов, но, что если очень важно вернуться к первоначальному количеству запущенных pod’ов? В этом месте Deployment вступает в игру.
Ресурс Deployment называется controller, и он выполняет работу по поддержанию заданного желаемого состояния кластера. Если вы вспомните наш resource config, мы не задавали создание pod’а напрямую. Вместо этого мы использовали Deployment чтобы автоматически управлять pod’ами, предоставляя шаблон для создания pod’ов. Вот данный раздел с шаблоном в нашей конфигурации:
template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.15 ports: - containerPort: 80
Здесь определяется, что pod’ы в нашем Deployment должны создаваться с лейблом app: nginx и в pod’е будет запущен один контейнер с образом nginx:1.15, прокидывается 80 порт.
В дополнение к шаблону pod’а, мы также задаем spec в ресурсе Deployment, который определяет количество реплик, которые он должен поддерживать:
spec: replicas: 2
Это говорит контроллеру о том, что он должен пытаться поддерживать 2 pod’а запущенными в кластере. Каждый раз, когда количество запущенных pod’ов уменьшается, контроллер автоматически создает новый, чтобы заменить удаленный pod. Поэтому, в нашем случае, когда мы выселяем pod’ы с ноды при помощи drain, Deployment контроллер автоматически пересоздает его на одной из других доступных нод.
Обобщим
В целом, с обоснованной задержкой в хуке preStop и корректным завершением, мы можем выключать наши pod’ы корректно на одной ноде. И с ресурсом Deployment мы можем автоматически пересоздавать выключенные pod’ы. Но что если мы хотим заменить все ноды в кластере одновременно?
Если мы просто сделаем drain на нодах, это может привести к простою, так как балансировщик нагрузки может не иметь ни одного доступного pod’а. Хуже того, для stateful-системы, мы можем разрушить кворум, что приведет к увеличению времени простоя, так как появляются новые pod’ы и им приходится проводить выборы лидера, ожидая пока кворум нод будет достигнут.
Если вместо этого мы попробуем выполнить drain на каждой ноде по очереди, то можем получить новые pod’ы, запущенные на старых нодах. Появляется риск возникновения ситуации, когда в итоге все реплики pod’а будут запущены на одной из старых нод, и, когда мы выполним на ней drain, то потеряем все реплики нашего pod’а.
Чтобы справиться с этой ситуацией, Kubernetes предлагает функцию PodDisruptionBudgets, которая показывает допустимое количество pod, которые могут быть выключены в конкретный момент времени. В следующей и финальной части нашей серии мы расскажем, как мы можем использовать данную функцию для управления одновременным количеством процессов drain, несмотря на наш прямолинейный подход по вызову drain для всех нод параллельно.
Чтобы получить полностью внедренную и протестированную версию обновлений кластера Kubernetes для нулевого временем простоя на AWS и других ресурсах, посетите Gruntwork.io.
Также читайте другие статьи в нашем блоге:
- Zero Downtime Deployment и базы данных
- Kubernetes: почему так важно настроить управление ресурсами системы?
- Cборка динамических модулей для Nginx
- Бэкапы Stateful в Kubernetes
- Резервное копирование большого количества разнородных web-проектов
- Telegram-бот для Redmine. Как упростить жизнь себе и людям
ссылка на оригинал статьи https://habr.com/ru/company/nixys/blog/490380/
Добавить комментарий