
Подход DevOps качественно изменил процесс разработки. Если раньше программисты только писали код и прогоняли тесты, то теперь они участвуют и в развертывании проектов на продакшен. Звучит так, будто сисадмины решили переложить свои заботы на плечи разработчиков, не так ли? Но не все так просто.
Выяснить это решил Барух Садогурский (jbaruch) из JFrog. Под катом вы найдете расшифровку его доклада, где Барух на примерах покажет, действительно ли DevOps помогает деплоить код чаще и улучшать его качество. Трудно передать харизму спикера текстом, поэтому в статье будут мемы из презентации.
Далее повествование от лица спикера.
Видеозапись доклада можно найти по ссылке.
Что скрывается под диаграммой процессов в DevOps?
Этот доклад я называю срывом покровов, и мы разберемся, является ли DevOps заговором сисадминов против разработчиков.
На самом деле, проблема в том, что никто не знает, что такое DevOps. Теоретически для этого существует ответ, который заключается в этой диаграмме:

Начнем с того, что DevOps — это некая методология, которая содержит следующие шаги: мы написали, построили, потестили, зарелизили, задеплоили, прооперировали в продакшене и отмониторили, а затем по новой. Что-то эта диаграмма нам напоминает…

Agile она нам напоминает. Только Agile находится лишь на той половине, где разработка:
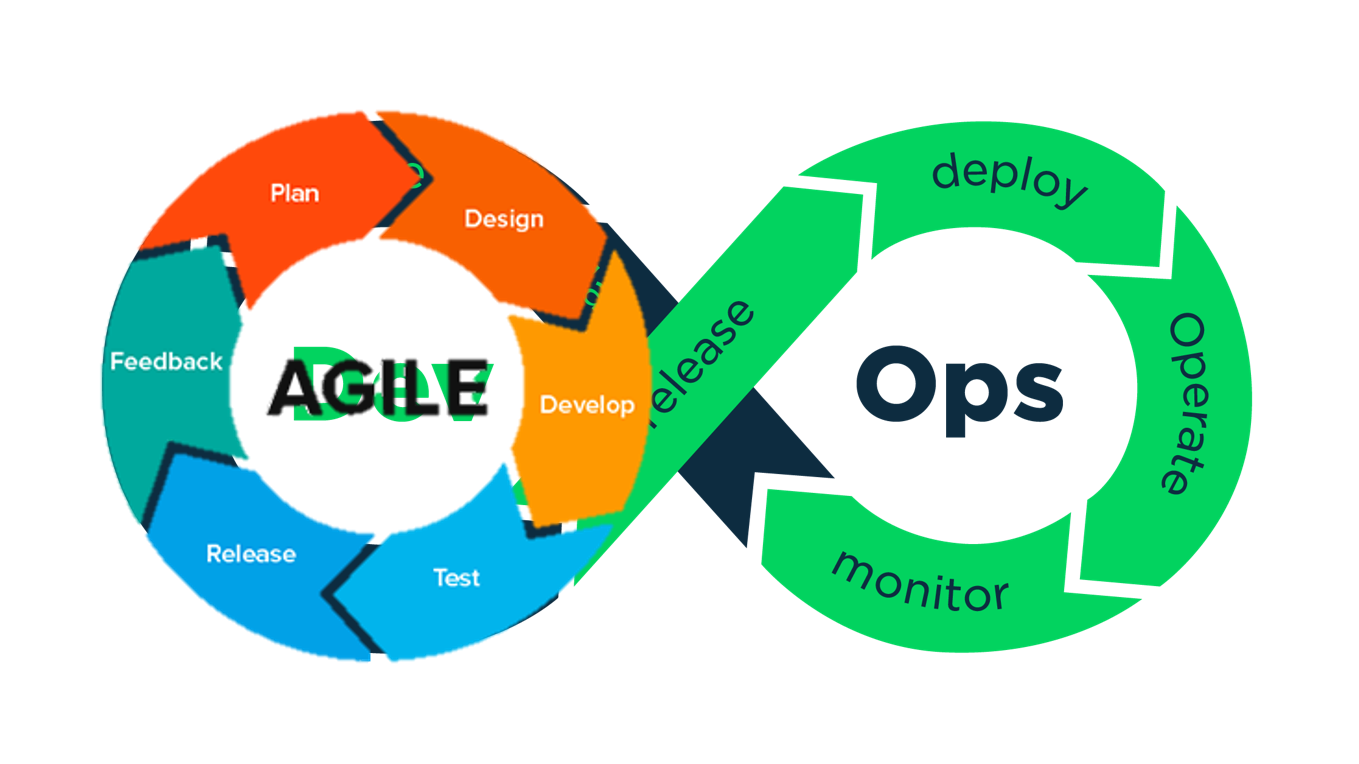
Ребята сильно не парились: взяли диаграмму Agile и прицепили к ней кучу всякой сисадминской фигни — deploy, монитор и т.п. На самом деле, это все то же самое, и сейчас я расскажу об этом.
Почему я буду срывать покровы? Хоть я в душе и джавист, но моя компания занимается DevOps, я занимаюсь DevOps, и поэтому я смотрю на DevOps глазами разработчика. И далее я докажу, что DevOps придуман сисадминами.
Кто стоит у истоков DevOps?
Главная книжка по DevOps — «The Phoenix Project». Это такой роман, где главный герой с помощью DevOps побеждает. Сначала у них все очень просто — плохо, затем он придумывает DevOps, и у них становится все хорошо.
На обложке книги есть главные герои. Давайте рассмотрим их внимательнее:

Кого нет на обложке, но в самой книге они на задних ролях? Разработчиков! Вся книжка про то, как Ops-сисадмины придумали DevOps и с помощью него победили.
Второе доказательство: книжка «Руководство по DevOps» (DevOps Handbook). Давайте посмотрим, кто ее написал:
- Джен Ким (Gene Kim). Он написал «The Phoenix Project», то есть с ним все понятно.
- Патрик Дебуа (Patrick Debois). Он был Systems Architect, то есть сисадмином.
- Джез Хамбл (Jez Humble). Работал Deputy Director of Delivery Architecture, то есть сисадмином.
- Джон Уиллис (John Willis). Был VP of Services из компании Opscode, а Opscode — это инструмент для сисадминов.
То есть «Руководство по DevOps» придумано сисадминами.
Может, у нас более продвинутые люди? Уж они-то знают, зачем нужен DevOps и кто такие DevOps-специалисты. Открываем статью на Хабре и видим высказывание Кирилла Сергеева:
Настал тот день, когда разработчики и системные инженеры заинтересовались работой друг друга.
Хм, то есть Кирилл утверждает, что разработчики заинтересовались сисадминством? Интересно! Как вы думаете, кем работает этот Кирилл Сергеев? DevOps Engineer в компании EPAM! Ах вон оно что, теперь понятно, это сисадмины хотят, чтобы разработчики заинтересовались сисадминством, чтобы свалить на них часть своей работы!
Спустимся и посмотрим комментарии к этой статье:
Я три года работал системным администратором Linux в одной конторе, а в этом году стал DevOps-инженером в другой. Если честно, я так и не понял, что такое DevOps — перечень моих задач особо не изменился (добавился Jenkins разве что), но зарплата выросла существенно. А ещё я теперь могу громко орать, что я не сисадмин какой-то, а модный и востребованный «DevOps-специалист». Вот что такое DevOps в моем случае.
Есть еще русскоязычный чат по DevOps в Telegram:
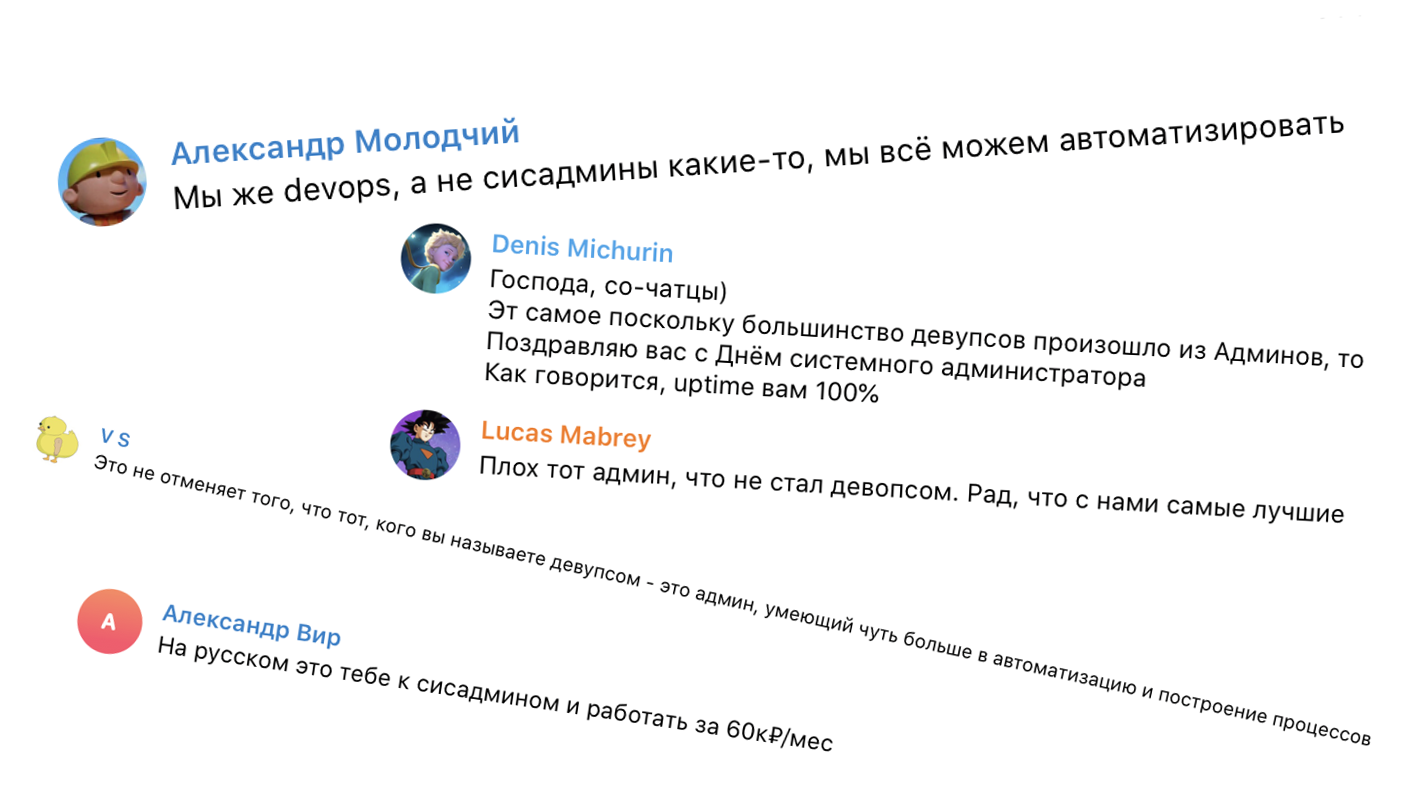
Вот что мы знаем: DevOps — это как сисадмины, только умеют в автоматизацию и знают английский.
Откуда же взялся этот ребрендинг? Откуда появились “DevOps-инженеры”?
Как вы и могли догадаться, это маркетинговый трюк рекрутеров. Им надо нанимать сисадминов, но сисадмины больше не хотят называться сисадминами! Поэтому рекрутеры придумали новую должность: “DevOps-инженер”.
LinkedIn выдает около 15 тыс. результатов по запросу DevOps в США. Если вы думаете, что в Питере не так, то нет — около 1300 открытых вакансий DevOps-инженеров на HeadHunter по состоянию на октябрь 2019 года.
Вот откуда ноги-то растут! Ну ладно, может быть всё не так плохо, и этим «ДевОпс-инженерам» всё-таки есть дело до задач, целей и головных болей разработчиков? Еще есть такой отчет под названием Accelerate: State of DevOps. Любой DevOps-специалист начнет вам рассказывать, как там все правильно. Пока давайте немного про версию 2018 года, а о выпуске 2019 года чуть позже.
Что измеряет State of DevOps? То, как мы деплоим код, куда код девается после того, как мы его написали, какие outages у серверов, лежат ли сервера, degraded service. То есть всё-всё-всё про DevOps. Главное измерение — это new work, то есть сколько мы тратим, создавая новые фичи. Как же он измеряется?

Никаких outages, degradation, server migrations! То есть все метрики в State of DevOps — это метрики сисадминов, и к нам, разработчикам, не имеют никакого отношения, потому что у нас есть три вида работы: фигачим новые фичи, фиксим баги или делаем рефакторинг. Ну то есть суммируя: DevOps — это в лучшем случае ребрендиг сисадминства, а, может быть, даже и попытка сисадминов переложить часть своей работы на разработчиков!
На этом, господа присяжные, я считаю доказанным, что DevOps — это заговор сисадминов против разработчиков. Но я-то разработчик, и что для меня этот new work, что для меня является сделанной работой? Где я провожу эту границу между Dev и Ops в DevOps?
Перейдем к докладу «The world needs full stack craftsmen», с которым Антон Кекс выступал на JPoint 2019. Если в двух словах, то доклад про Software Craftsmanship. Антон рассказывал о том, что значит быть full stack разработчиком, но затем он говорит что-то в духе:

Дальше он говорил про deployment, потому что иначе злой админ позвонит вам в середине ночи. Но у нас же DevOps! Разработчики же деплоят! То есть в докладе еще одно доказательство, что в теме про Software Craftsmanship никаким DevOps и не пахнет. Мы должны сделать так, чтобы системные администраторы не звонили ночью, и заботиться о том, чтобы код был в продакшене.
Далее Антон рассматривал Manifest of Software Craftsmanship:
As aspiring Software Craftsmen we are raising the bar of professional software development by practicing it and helping others learn the craft. Through this work we have come to value:
Not only working software, but also well-crafted software
Not only responding to change, but also steadily adding value
Not only individuals and interactions, but also a community of professionals
Not only customer collaboration, but also productive partnerships
That is, in pursuit of the items on the left we have found the items on the right to be indispensable.
Что-нибудь про DevOps, production, delivery? Ничего.
Что же считается хорошей разработкой по Software Craftsmanship?
- Мы поняли, что надо сделать;
- Наш код максимально читабелен, прост, понятен и удобен;
- Наш код легко, удобно и понятно деплоить;
- Нефункциональные требования выполнены;
- У нас не накопилось никакого долга (и даже уменьшилось);
- У нас проходят все тесты;
- QA посмотрел, и вопросов не имеет;
- Лид посмотрел, и ему понравилось;
- Product owner посмотрел, и ему понравилось;
- Клиент посмотрел, и ему понравилось.
Как меняются требования к качеству кода?
Антон в докладе привел картинку, где тестеры ругаются с разработчиками:
Да нет у нас никакого конфликта и быть не может, ведь важно качество кода. Мы лучшие друзья с тестерами из QA, потому что они помогают писать качественный код. Но что такое качество?
Я, конечно, разработчик, но это хозяйство трогал давно, в 2010 году. Рассмотрим мобильное приложение какого-нибудь банка. Какие требования предъявлялись к нему в 2010 году? Да чтобы оно было, потому что его еще не существовало. Если бы оно было, представьте, что оно закрылось на всю ночь на maintenance. Ни у кого не возникло бы вопросов; спасибо и на том, что по SMS можно деньги перевести. А в 2019 году? Мы просто меняем банк, если не нравится мобильное приложение. Требования к качеству совершенно изменились, в том числе и к постоянной работе сервиса в продакшене. Это одна проблема, по которой качество стало измеряться по-другому.
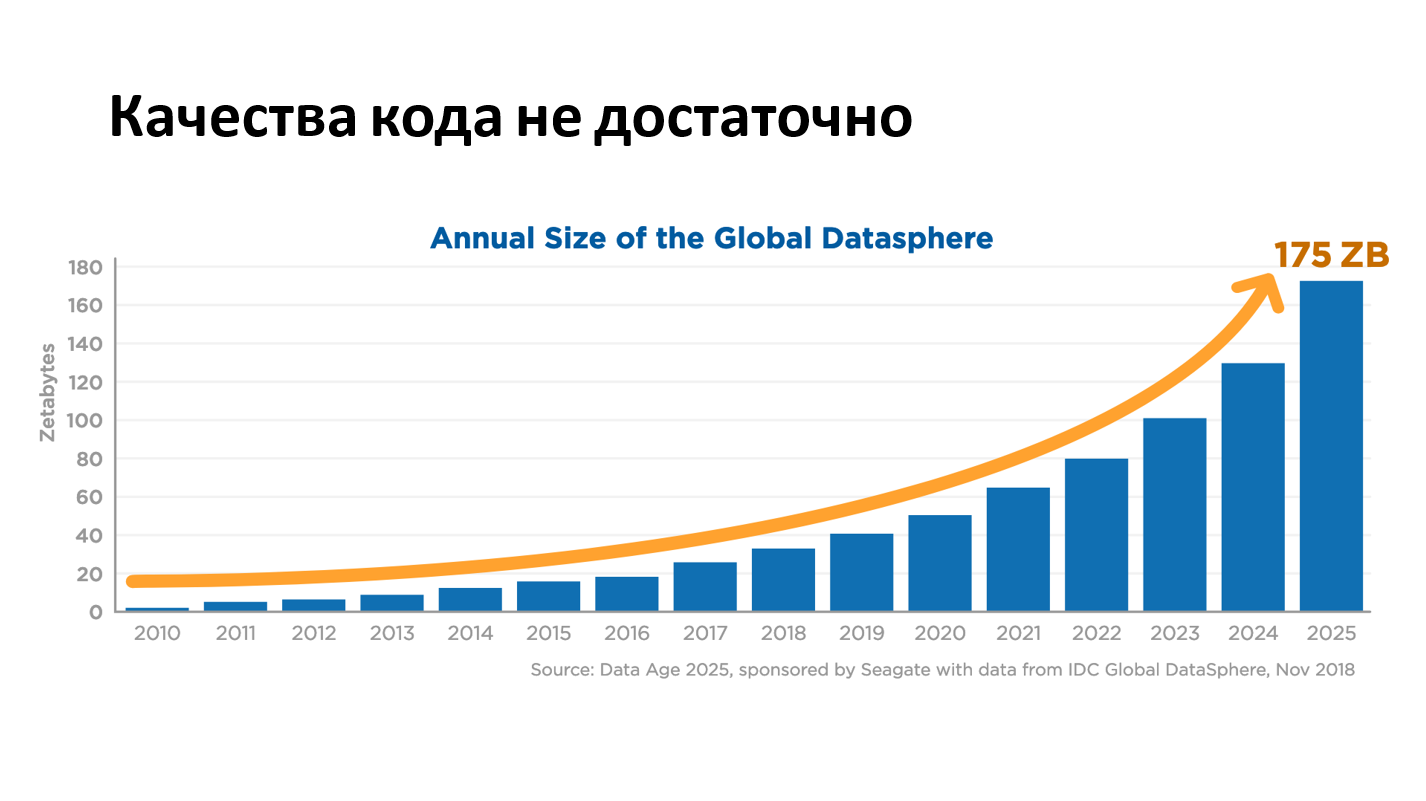
Другая проблема — увеличение количества данных. Конечно, приведенное мной исследование сделано при участии Seagate, а им нужно продавать диски, но данных на самом деле много, и тогда отваливается понятие staging.
Идея staging в том, что он похож на продакшн, только его можно ломать. Но если у вас петабайты в продакшене, то вам никто не даст деньги на такой же staging, поэтому его не существует. Сначала мы паникуем, а затем мы начинаем тестировать в продакшене.

Мое любимое — blast radius reduction. Говоря проще, мы деплоим такого качества код, что впечатление будто мы бросаем бомбу; там такие баги, что все умирают, и желательно, чтобы радиус был поменьше. Но ведь разработчикам есть дело до качества, а теперь единственная возможность проверить код — это швырнуть что-нибудь в продакшн и смотреть на радиус поражения. И внезапно продакшн врывается к нам в жизнь. Оказывается, нам пора на дежурство!

Мы можем сказать, что у нас все работает, только когда посидим на дежурстве и посмотрим на радиус поражения, когда что-то вбросили. И теперь в TODO-список по хорошей разработке прибавляется еще один пункт:
-
SRE посмотрел, и ему понравилось.
Ведь он с нами на дежурстве сидит. Понятие SRE, или Site Reliability Engineering, придумали в Google (видимо, чтобы удобнее было гуглить):
SRE is what you get when you treat operations as if it’s a software problem.
SRE — это про то, чем на самом деле занимается DevOps. Есть и другое определение: SRE имплементирует DevOps, то есть это подход, который автоматизирует дела, связанные с Ops, и рассматривает их, будто это софт.
Какие новые требования предъявляют к разработчику, когда появляется SRE:
- Мы понимаем, что наш код будет раскатан в проде.
- Сборка нашего кода проверяема и быстра. Быстра, потому что у нас лежат сегменты, есть жертвы в радиусе поражения, и надо срочно выкатывать новую версию. Поэтому сборка должна быть и повторяема.
- Наш код масштабируем, и состояние ему не помеха. Предположим, у нас «Черная пятница», к нам пришли пользователи, и нужно в 10 раз больше «железа».
- Наш код быстро поднимается и умирает.
- Наш код отчитывается о своем состоянии. У нас нет зомби-серверов, которые теоретически работают, пока на нас не наорут в Twitter.
- Наш код умеет в feature flags. Код должен уметь переключаться на старую версию, если вы, например, завалили западное побережье Америки.
- Наш код обратно и вперед совместим (на случай роллбэка). Если мы все завалили, нам нужно срочно откатывать, а если новая версия микросервиса несовместима со старой, то уже ничего не сможем откатить.
- Наш код логирует поток событий. Ведь заходить каждый раз на сервер и делать поиск по файлам логов не очень продуктивно, когда у вас радиус поражения и все лежит.
- К нашему коду можно подключить мониторинг и трейсинг.
- Наш код экономен.
Внезапно это все становится заботой разработчика, потому что, кроме него, никто этого сделать не сможет. Эти требования относятся к коду, поэтому сисадмины нам не помогут.
Какую пользу разработчик принесет бизнесу, если разберется с DevOps?

Это счет AWS. Хотелось бы, чтобы он был поменьше, потому что бизнес хочет сэкономить деньги. Причем здесь разработчики, когда это забота Ops-ов в компании? Но на самом деле экономия зависит от разработчиков.
На Kafka Summit SF 2019 Удай Сагар Ширамшетти (Uday Sagar Shiramshetty) из SignalFX рассказывал про то, как они сократили на 50 % счет в Cloudia благодаря правильному внедрению Kafka. Это очень круто, ведь бизнес экономит средства, хотя, казалось бы, разработчиков это не должно касаться.

Когда мы пишем экономный код, мы помогаем бизнесу и помогаем себе. Но еще нам нужны довольные клиенты, несмотря на blast radius.

Перейдем к отчету 2019 года Accelerate State of DevOps от DORA:

И тут мы понимаем, что бизнес — это про нас. Мы видим, что те, кто понимают в DevOps, деплоят в 208 раз быстрее, чем люди без знаний о нем.
Как обеспечивается информационная безопасность в компании? Мы нанимаем Chief Information Security Officer, который ходит по офису, всем нудит, а его все тряпками гоняют. Зато, когда утекает миллион записей клиентов, его можно уволить, ведь он был нанят, чтобы подобное предотвратить! Но есть способ лучше.
Кто сдавал на права, тот помнит про тормозной путь. Тормозной путь состоит из двух разных частей: осознания и торможения. Мы хотим сократить тормозной путь. Чтобы уменьшить время торможения, мы меняем резину и колодки из разных сплавов. Для сокращения времени осознания мы заменяем людей автопилотом.
В security все точно так же. Когда есть дыры в безопасности, происходит три совершенно разных процесса:
- Найти проблему.
- Придумать, как обезвредить.
- Задеплоить фикс в продакшен.
Каждая из этих историй влияет на защищенность продукта. Найти проблему и придумать ее решение можно по-разному, зато мы прекрасно знаем, как залить в продакшн. Вы помните, что если мы начинаем писать код, который нравится и SRE, то и деплоим в 208 раз быстрее. Вы можете сказать, что достаточно знать проблему заранее, и будет время задеплоить фикс, пока ее найдет кто-то другой. Однако существуют проблемы, которые найти заранее невозможно.
Возьмем уязвимости Spectre и Meltdown, которые наделали шума в январе 2018 года. Больше всего паниковали из-за Meltdown, потому что там были три строчки Java-скрипта, которые выдирали пароли из памяти. Но паника была скоротечная, потому что через неделю прилетели апдейты на все наши ОС, кроме Windows XP.
Со Spectre все намного хуже, потому что от него защититься невозможно. Он пытается угадать спекулятивные решения, которые принимает процессор на основании паттернов программирования. То есть если вы используете design patterns, то ваш код более подвергнут атакам класса Spectre. Защититься невозможно, потому что никто не будет знать, что атака в принципе происходит. И тогда единственный способ бороться — деплоить чаще.
И несмотря на то, что DevOps — это заговор сисадминов против разработчиков, DevOps — это история про эволюционный отбор. Те, кто деплоит чаще, остаются на рынке, а остальные, видимо, идут просить деньги у государства.
DevOps — это всего лишь средство для достижения целей:
- качество;
- экономия;
- новые фичи;
- безопасность.
Поэтому как бы мы не любили DevOps, добро пожаловать в DevOps.

DevOps и разработчики — друзья навек?
Есть и хорошая новость. Сисадмины тоже начинают понимать, что им нужно договариваться с разработчиками. И даже отчет Accelerate: State of DevOps, который я приводил в качестве доказательства, что разработчики не имеют отношения к DevOps, начинает меняться. В 2019 году для создания этого отчета было опрошено больше разработчиков (30 %), чем DevOps-специалистов и SRE (26 %). И внезапно Software Development становится частью Performance Metrics:

Разработчики, которые хотят принимать участие в DevOps, могут посетить сайт The Twelve-Factor App. Он содержит требования к приложению, которым будет доволен SRE. Они схожи с теми требованиями, которые мы разобрали ранее. Однако сайт уже устарел, и этих требований стало больше.
Вернемся к тому, что такое SRE: это подход к вопросам системного администрирования, как будто это софтверная проблема. Что любят разработчики больше всего? Софтверные проблемы!
И внезапно DevOps из заговора сисадминов против разработчиков превращается в подарок сисадминов разработчикам. Сисадмины пришли со своим администрированием Linux и сказали: сделайте нам жизнь более легкой, как ваша, чтобы вы могли поклацать по клавиатуре, и внезапно все серверы заработали. Все, что для этого нужно — нормальные задачи и инструменты.
Наше эволюционное давление по Дарвину порождает новые живые виды, и DevOps как раз об этом. У нас есть теперь инженеры и разработчики, которые волшебным прикасанием к коду внезапно решают проблемы не только разработки, но и системного администрирования.
Поэтому, как завещал кот Леопольд, давайте жить дружно. Хоть DevOps и родился в мозгах у сисадминов, бизнесу DevOps понравился, потому что можно деплоить чаще. И это хорошо: это и качество, и экономия, и конкурентное преимущество, и безопасность. На самом деле, все не так страшно, теперь все — код, а код мы любим. А от нас, разработчиков, требуется соблюдать паттерны и практики, а это все мы умеем.
Итак, Барух показал, что DevOps необходим разработчикам. Но как убедить компанию внедрить DevOps в рабочий процесс, если вы обычный программист? Об этом Барух расскажет на конференции DevOops 2020 Moscow, которая пройдет 29-30 апреля.
ссылка на оригинал статьи https://habr.com/ru/company/jugru/blog/489488/
Добавить комментарий