Недавно мне пришлось столкнуться с необходимостью достать текст из офисных документов (docx, xlsx, rtf, doc, xls, odt и ods). Задача осложнялась требованием представить текст в формате xml без мусора с максимально удобной для дальнейшего парсинга структурой.
Решение использовать Interop сразу отпало по причине его громоздкости, во многом избыточности, а также необходимости устанавливать на сервер MS Office. В результате, решение было найдено и воплощено на внутреннем проекте. Однако, поиск оказался настолько сложен и не тривиален в силу отсутствия каких-либо общедоступных мануалов, что мной было принято решение написать в свободное от работы время библиотеку, которая решала бы указанную задачу, а также создать написать что-то вроде инструкции, чтобы разработчики прочитав ее смогли, хотя бы поверхностно, разобраться в вопросе.
Прежде, чем перейти к описанию найденного решения, предлагаю ознакомиться с некоторыми выводами, которые были сделаны в результате моих изысканий:
- Для платформы .Net не существует какого-либо готового решения для работы со всеми перечисленными форматами, что заставит нас местами кастылизовывать наш солюшн.
- Не пытайтесь в сети найти хороший мануал по работе с Microsoft OpenXML: чтобы разобраться с этой библиотекой придется изрядно покрасноглазить, покурить StackOverflow и поиграться с отладчиком.
- Да, мне все таки, удалось приручить дракона.
Сразу оговорюсь, что в настоящий момент библиотека еще не готова, но она активно пишется (на столько, на сколько это позволяет свободное время). Предполагается, что будут написаны отдельные посты для каждого формата и параллельно, вместе с их публикацией, будет обновляться репозиторий на гитхабе, откуда можно будет получить исходники.
Работа с xlsx и docx
.xlsx
Наверняка, раз вы читаете эту статью, то уже в курсе, что docx и xlsx фактически являются zip-архивами, в которых лежит множество разных xml. Если нет, то убедиться в этом не составит труда: меняем расширение файла на zip и открываем любым архиватором. Так, наши листы документа будут лежать по следующему пути: \xl\worksheets.
У меня уже есть подготовленный excel документ, и, если открыть какой-нибудь лист по указанному ранее пути, то мы увидим примерно следующее содержимое:

Обратите внимание на то, что в ячейках, которые содержат формулы, записаны формулы (внутри тега <f>) и результат (внутри тега <v>). Также, ячейки с повторяющимся содержимым отмечены как shared и содержат ссылку на строку в файле sharedStrings.xml, расположенного по пути \xl.
Пока просто имейте ввиду эти особенности: как обрабатывать их будет показано ниже.
Прежде, чем писать наши классы-конвертеры, создадим интерфейс IConvertable:
using System; using System.Collections.Generic; using System.IO; using System.Text; namespace ConverterToXml.Converters { interface IConvertable { string Convert(Stream stream); string ConvertByFile(String path); } }
Теперь все наши классы, должны будут реализовывать два метода: string Convert(Stream stream) для работы с потоком (может быть очень полезным, если необходимо получить какую-то информацию из файла без его сохранения на хосте), а также string ConvertByFile(String path) для конвертации непосредственно файла.
Создаем класс XlsxToXml, реализующий интерфейс IConvertable и подключаем через Nuget DocumentFormat.OpenXml (на момент написания, актуальной являлась версия 2.10.0).
Логику обработки документа поместим в отдельный приватный метод string SpreadsheetProcess(Stream memStream), который будет вызываться в string Convert(Stream stream).
public string Convert(Stream memStream) { return SpreadsheetProcess(memStream); }
Как видно, сама логика реализована в методе *string SpreadsheetProcess(Stream memStream)*:
string SpreadsheetProcess(Stream memStream) { using (SpreadsheetDocument doc = SpreadsheetDocument.Open(memStream, false)) { memStream.Position = 0; StringBuilder sb = new StringBuilder(1000); sb.Append("<?xml version=\"1.0\"?><documents><document>"); SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable; int sheetIndex = 0; foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts) { WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex); sheetIndex++; } sb.Append(@"</document></documents>"); return sb.ToString(); } }
Итак, в методе string SpreadsheetProcess(Stream memStream) происходит следующее:
-
В блоке
usingоткрываем документ excel из потока. За работу с xlsx в библиотеке DocumentFormat.OpenXml отвечает класс SpreadsheetDocument. -
Устанавливаем каретку в начало потока и создаем объект StringBuilder sb (сразу на 1000 символов. Используем StringBuilder вместо строк, чтобы несколько оптимизировать процесс и избежать порождения лишних сущностей в виде не нужных стрингов. Также, заранее задаем начальный размер стрингбилдера, чтобы немного сэкономить времени на инициализации и выделении памяти.
-
Выше я писал про shared ячейки (в которых хранятся повторяемые значения). Так вот, из объекта класса SpreadsheetDocument их можно получить так:
SharedStringTable sharedStringTable = doc.WorkbookPart.SharedStringTablePart.SharedStringTable. -
Далее создаем переменную, в которой будет храниться номер листа и запускаем цикл
foreach (WorksheetPart worksheetPart in doc.WorkbookPart.WorksheetParts) { WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex); sheetIndex++; }в котором выполняется обработка каждого листа с помощью вызываемого метода
WorkSheetProcess(sb, sharedStringTable, worksheetPart, doc, sheetIndex);:private void WorkSheetProcess(StringBuilder sb, SharedStringTable sharedStringTable, WorksheetPart worksheetPart, SpreadsheetDocument doc, int sheetIndex) { string sheetName = doc.WorkbookPart.Workbook.Descendants<Sheet>().ElementAt(sheetIndex).Name.ToString(); sb.Append($"<sheet name=\"{sheetName}\">"); foreach (SheetData sheetData in worksheetPart.Worksheet.Elements<SheetData>()) { if (sheetData.HasChildren) { foreach (Row row in sheetData.Elements<Row>()) { RowProcess(row, sb, sharedStringTable); } } } sb.Append($"</sheet>"); } -
Пожалуй, в данной функции больше всего вопросов вызывает строчка:
string sheetName = doc.WorkbookPart.Workbook.Descendants<Sheet>().ElementAt(sheetIndex).Name.ToString();
То, что таким образом мы получаем имя листа, думаю понятно. Но вот, чтобы добраться до нее придется воспользоваться отладчиком и методом научного тыка. Поэтому не стесняемся, ставим точку остановки, жмакаем shift+F9(или как там у вас), открываем переменнуюdoc(в которой лежит наш документ)->WorkbookPart->Workbook и вызываем метод Descendants(), который вернет коллекцию всех дочерних элементов типаSheet. Ну а дальше остается по индексу получить конкретный лист, вытащить его имя и преобразовать в строку (что и сделано в коде). Как это примерно выглядит показано на рисунке ниже:
-
Далее по коду в цикле
foreachполучаем данные из листа, которые представляют собой коллекцию строк. Если внутри объектаsheetDataесть какие-то элементы, то это строки, каждую из которых мы обработаем методомRowProcess:foreach (SheetData sheetData in worksheetPart.Worksheet.Elements<SheetData>()) { if (sheetData.HasChildren) { foreach (Row row in sheetData.Elements<Row>()) { RowProcess(row, sb, sharedStringTable); } } } -
В методе
void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable)происходит следующее:void RowProcess(Row row, StringBuilder sb, SharedStringTable sharedStringTable) { sb.Append("<row>"); foreach (Cell cell in row.Elements<Cell>()) { string cellValue = string.Empty; sb.Append("<cell>"); if (cell.CellFormula != null) { cellValue = cell.CellValue.InnerText; sb.Append(cellValue); sb.Append("</cell>"); continue; } cellValue = cell.InnerText; if (cell.DataType != null && cell.DataType == CellValues.SharedString) { sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText); } else { sb.Append(cellValue); } sb.Append("</cell>"); } sb.Append("</row>"); }В цикле
foreach (Cell cell in row.Elements<Cell>())проверяем каждую ячейку на предмет наличия в ней записанной формулы:if (cell.CellFormula != null) { cellValue = cell.CellValue.InnerText; sb.Append(cellValue); sb.Append("</cell>"); continue; }Если формула обнаружена, то получаем значение, вычисленное по формуле (
cellValue = cell.CellValue.InnerText;) и переходим к следующей ячейке.
Если ячейка не содержит формулы, то мы проверяем, является ли она shared: если является, то берем значение по индексу из ранее полученной коллекции с повторяющимися значениями:if (cell.DataType != null && cell.DataType == CellValues.SharedString) { sb.Append(sharedStringTable.ElementAt(Int32.Parse(cellValue)).InnerText); }В противном случае, мы просто получаем значение из ячейки.
.docx
Начнем с того, что парсинг документов word представляет из себя куда более не тривиальную задачу по сравнению с парсингом excel-файлов.
Так, разработчику предстоит решить проблему не только парсинга содержимого, но и сохранения структуры, что подразумевает, как минимум, сохранение абзацев, обработку списков и таблиц. Так как мои рабочие задачи не подразумевали обработку графики, сносок, оглавления и т.д., в данной статье они разобраны не будут, но, я не исключаю, что когда-нибудь мне придется столкнуться с такой задачей и, я обязательно обновлю и статью, и репозиторий.
Итак, для начала пара слов о внутреннем устройстве документа. Предлагаю снова проделать процедуру с переименованием расширения файла в zip и открыть его любым архиватором. Внутри мы увидим несколько папок. Открываем папку word и находим файл document. Да, внутри лежит еще куча файлов, но они, по большому счету, для решения нашей задачи не нужны. Однако, никто вам не запрещает в них поковыряться: вдруг вам потребуется вытащить какие-нибудь стили из документа.
Как мы видим, содержимое каждого абзаца находится внутри тега w:t, который лежит внутри w:r, который также находится внутри w:p. По большому счету, эта структура является ключевой для всех документов docx, независимо от их содержимого. Обратите внимание на списки: каждый элемент также находится внутри описанной структуры, но с добавлением тегов w:numPr, внутри которого определяется уровень вложенности списка (w:ilvl) и id списка, которому принадлежит данный элемент (w:numId).
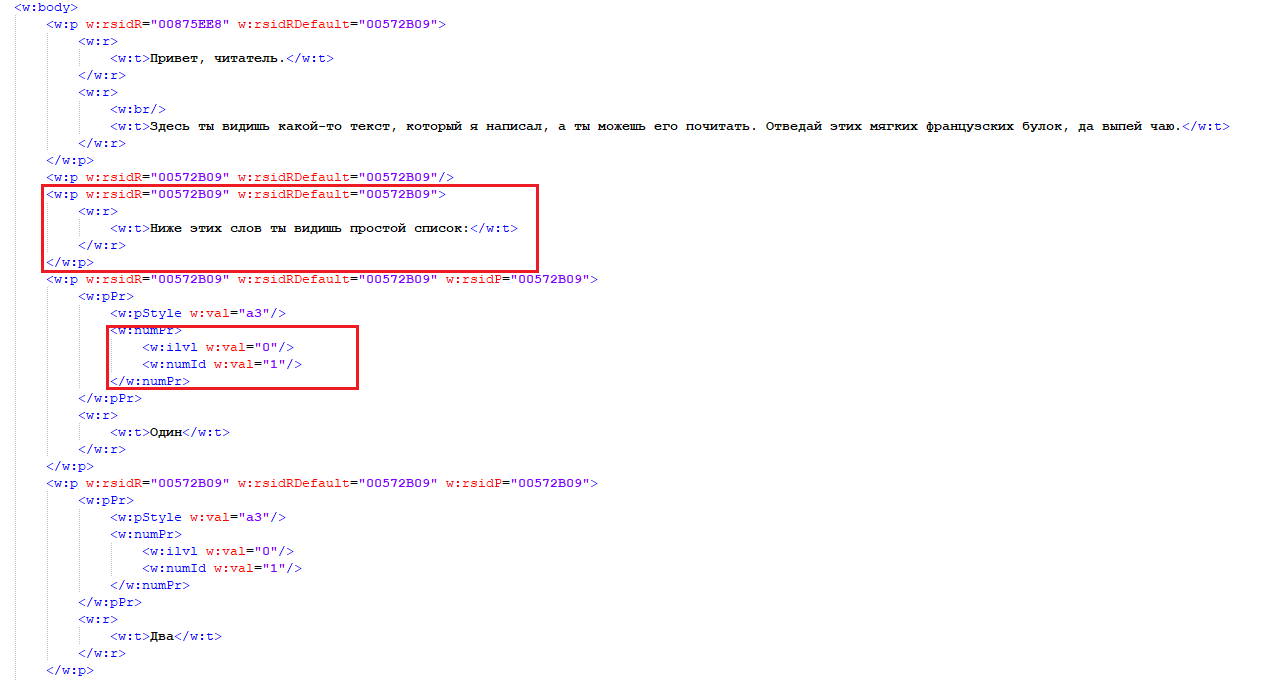
Также, хочу обратить внимание, что индексы элементов списка не хранятся в виде значения в данном файле, а, как мне кажется (во всяком случае, других версий я не нашел), формируются динамически, в зависимости от id списка, которому принадлежит элемент, уровня вложенности и порядкового номера элемента.
Аналогичная история со вложенными списками, которые отличаются от простых списков лишь тем, что у них не нулевой уровень вложенности:

Более того, данная структура сохраняется и для таблиц. Правда теперь она упакована в теги w:tr (строка) и w:tc(ячейка).

Прежде, чем начать кодить, хочу обратить внимание на один очень важный ньюанс (да-да, как в анекдоте про Петьку и Василия Ивановича). При разборе списков, особенно это касается вложенных, может возникнуть ситуация, когда пункты списка разделены какой-то вставкой текста, изображения или вообще чего угодно. Тогда возникает вопрос, когда же нам ставить закрывающий тег списка? Мое предложение попахивая костылезацией и велосипедостроением сводится к добавлению словаря, ключами которого будут выступать id списков, а значение будет соответствовать id параграфа (да, оказывается каждый параграф в документе имеет свой уникальный id), который одновременно является последним в каком-то списке. Пожалуй, написано довольно сложно, но, думаю, когда посмотрите на реализацию, станет несколько понятнее:
public string Convert(Stream memStream) { Dictionary<int, string> listEl = new Dictionary<int, string>(); string xml = string.Empty; memStream.Position = 0; using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false)) { StringBuilder sb = new StringBuilder(1000); sb.Append("<?xml version=\"1.0\"?><documents><document>"); Body docBody = doc.MainDocumentPart.Document.Body; CreateDictList(listEl, docBody); foreach (var element in docBody.ChildElements) { string type = element.GetType().ToString(); try { switch (type) { case "DocumentFormat.OpenXml.Wordprocessing.Paragraph": if (element.GetFirstChild<ParagraphProperties>() != null) { if (element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val != CurrentListID) { CurrentListID = element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val; sb.Append($"<li id=\"{CurrentListID}\">"); InList = true; ListParagraph(sb, (Paragraph)element); } else { ListParagraph(sb, (Paragraph)element); } if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value)) { sb.Append($"</li id=\"{element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val}\">"); } continue; } else { SimpleParagraph(sb, (Paragraph)element); continue; } case "DocumentFormat.OpenXml.Wordprocessing.Table": Table(sb, (Table)element); continue; } } catch (Exception e) { continue; } } sb.Append(@"</document></documents>"); xml = sb.ToString(); } return xml; }
-
Dictionary<int, string> listEl = new Dictionary<int, string>();— словарь в котором будет храниться информация о последних элементах каждого из списков. -
using (WordprocessingDocument doc = WordprocessingDocument.Open(memStream, false))— создаем объектdocкласса WordprocessingDocument, в котором находится содержимое нашего документа word, но уже в структурированном (на столько, на сколько это позволяет библиотека OpenXML) виде. -
StringBuilder sb = new StringBuilder(1000);— наша будущая строка с легко читаемым содержимым в формате xml. -
Body docBody = doc.MainDocumentPart.Document.Body;— получаем содержимое нашего документа, с которым мы дальше и будем работать -
Вызываем функцию
CreateDictList(listEl, docBody);, которая пробегается в цикле foreach по всем элементам документа, и ищет последний абзац для каждого списка:void CreateDictList(Dictionary<int, string> listEl, Body docBody) { foreach(var el in docBody.ChildElements) { if(el.GetFirstChild<ParagraphProperties>() != null) { int key = el.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val; listEl[key] = ((DocumentFormat.OpenXml.Wordprocessing.Paragraph)el).ParagraphId.Value; } } }GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val;— написание подобного рода страшных конструкций является отнюдь не результатом штудирования документации (можете перейти на сайт мелкомягких https://docs.microsoft.com/ru-ru/office/open-xml/open-xml-sdk и попытаться раскурить их мануал), а представляет собой порождение научного тыка в режиме дебага. Если есть люди, которые владеют методологией изучения подобных библиотек с аналогичной детализацией документации, буду рад, если поделитесь своим опытом) -
После того, как наш словарь создан, в цикле foreach перебираем все элементы в документе. На каждой итерации цикла выясняем к какому типу относится наш элемента: абзац или таблица. Если абзац, то мы должны произвести проверку, а не является ли наш абзац частью списка. И если он является элементом списка, то нужно выяснить в какой части списка находится данный абзац (начало, конец или середина) для того, чтобы корректно расставить открывающиеся и закрывающиеся теги для нашего списка. Помимо этого, также важно идентифицировать к какому именно списку относится наш элемент. В коде эта задача решается так:
string type = element.GetType().ToString(); try { switch (type) { case "DocumentFormat.OpenXml.Wordprocessing.Paragraph": if (element.GetFirstChild<ParagraphProperties>() != null) // список / не список { if (element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val != CurrentListID) { CurrentListID = element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val; sb.Append($"<li id=\"{CurrentListID}\">"); InList = true; ListParagraph(sb, (Paragraph)element); } else // текущий список { ListParagraph(sb, (Paragraph)element); } if (listEl.ContainsValue(((Paragraph)element).ParagraphId.Value)) { sb.Append($"</li id=\"{element.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val}\">"); } continue; } else // не список { SimpleParagraph(sb, (Paragraph)element); continue; } case "DocumentFormat.OpenXml.Wordprocessing.Table": Table(sb, (Table)element); continue; } }Блок
try-catchиспользуется в связи с тем, что существует вероятность наличия в документе какого-то элемента, который не предусмотрен в блокеswitch-case(в нашем случае, мы производим обработку только абзацев, списков и таблиц). Таким образом, если в документе есть что-то неопознанное и нами не предвиденное, то программа просто проигнорирует такой кейс. -
Если элемент является частью списка, то он обрабатывается с помощью метода
ListParagraph(sb, (Paragraph)element);:void ListParagraph(StringBuilder sb, Paragraph p) { // уровень списка var level = p.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingLevelReference>().Val; // id списка var id = p.GetFirstChild<ParagraphProperties>().GetFirstChild<NumberingProperties>().GetFirstChild<NumberingId>().Val; sb.Append($"<ul id=\"{id}\" level=\"{level}\"><p>{p.InnerText}</p></ul id=\"{id}\" level=\"{level}\">"); }По большому счету данный метод всего лишь упаковывает содержимое параграфа в теги
<ul>, дополняя его информацией об id списка и уровне вложенности. -
Если же, текущий элемент не является списком или таблицей, то он обрабатывается с помощью метода
SimpleParagraph(sb, (Paragraph)element);:void SimpleParagraph(StringBuilder sb, Paragraph p) { sb.Append($"<p>{p.InnerText}</p>"); }То есть, содержимое текста просто оборачивается в тег
<p> -
Таблица обрабатывается в методе
Table(sb, (Table)element);:void Table(StringBuilder sb, Table table) { sb.Append("<table>"); foreach (var row in table.Elements<TableRow>()) { sb.Append("<row>"); foreach (var cell in row.Elements<TableCell>()) { sb.Append($"<cell>{cell.InnerText}</cell>"); } sb.Append("</row>"); } sb.Append("</table>");}Обработка такого элемента вполне тривиальна: считываем строки, разбиваем на ячейки, из ячеек берем значения, оборачиваем в теги
<cell>, которые запаковываем в в теги<row>и все это помещаем внутрь<table>.
На этом, поставленную задачу предлагаю считать решенной для документов формата docx и xlsx.
Исходный код можно посмотреть в репозитории по ссылке
Статья о конвертации rtf
ссылка на оригинал статьи https://habr.com/ru/post/491090/
Добавить комментарий