Установите лимит использования ресурсов. С помощью простой математики можно рассчитать, сколько копий приложения вы сможете запустить – если одной копии нужен 1 ГБ RAM, то имея 10 ГБ памяти, можно запустить 10 копий. За этим не нужно будет следить, потому что я знаю, что ядро системы просто станет исполнять обусловленный контракт. Этот контракт, или соглашение между вами и системой, очень важен, потому что при его наличии все инструменты работают намного лучше. Таким образом мы привносим в систему дисциплину исполнения.
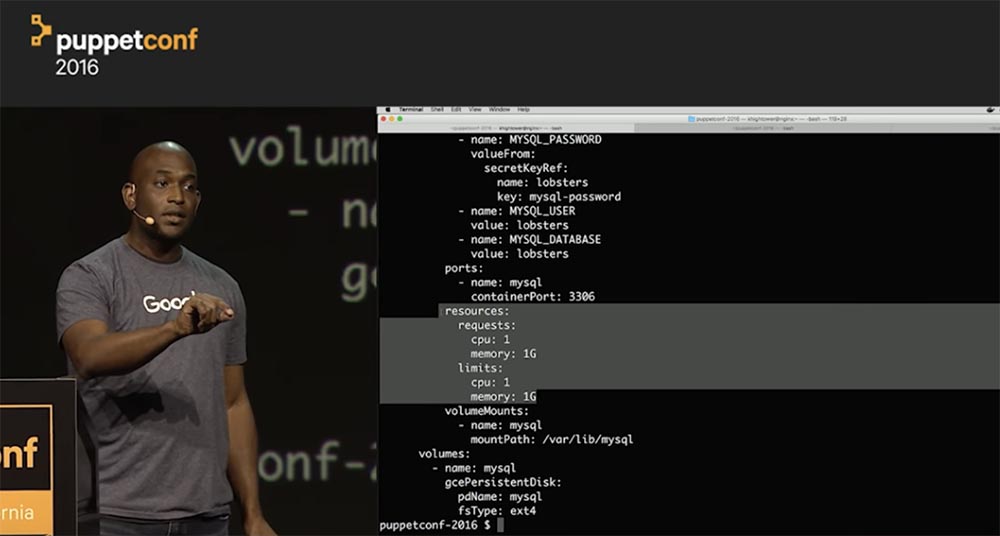
Так вот, планировщик запустит это только в том случае, если на каждую из реплик достанется по 1 Гб свободной памяти. Если же памяти не хватает, процесс не запустится. Итак, я ввожу команду kubectl create, и после ее выполнения будет создан контейнер mysql.
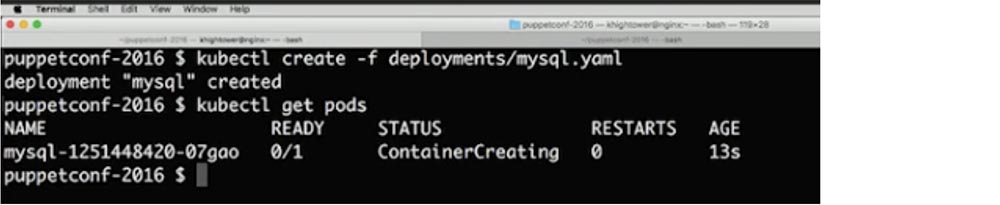
Здесь имеется один нюанс, связанный со stateful-системами – у вас есть несколько вариантов выбора. Я выделил фрагмент кода, в котором указал, что хочу использовать PersistentDisk моего облачного провайдера.
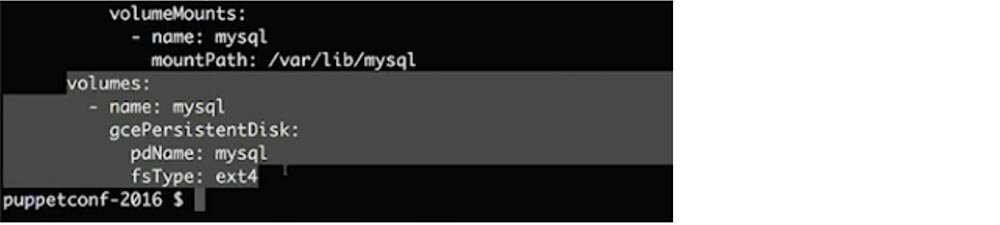
Это может быть NFS, ISCSI или любой другой протокол, который обеспечивает сетевой block-level доступ к устройствам хранения данных. Я делаю это для того, чтобы отсоединить свое хранилище от машин. Если одна из машин выйдет из строя, я смогу воссоздать процесс на другой машине, используя это же хранилище данных. Если вы монтирует хранилище с хоста, на котором происходит сбой, вы просто потеряете свои данные и должны будете все заново восстановить из резервной копии.
Поэтому наша цель заключается том, чтобы хранилище работало быстрее по мере того, как наши сети становятся все быстрее. Речь идет не о миграции, а о возможности быстро смонтировать и размонтировать хранилище вне машины. Это вполне можно проделать. Посмотрим, как дела с нашим подом – он все еще создается, и сейчас я хочу создать для него services, чтобы наш под могли найти другие приложения.
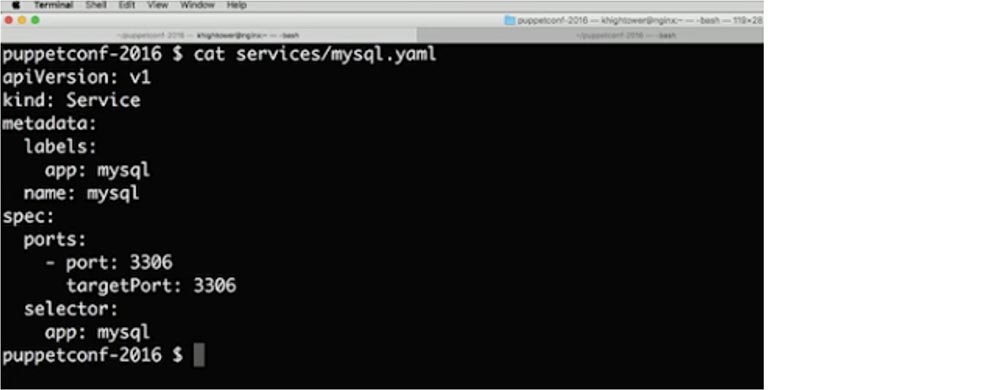
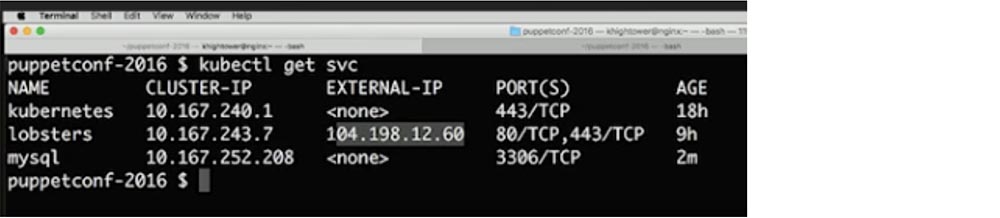
Как только я создаю этот сервис, Kubernetes сформирует запись DNS, так что вы можете просто вызвать mysql и автоматически обнаружить, что этот контейнер запущен. Давайте продолжим и введем команду $ kubectl create –f services/mysql.yaml. Как видите, контейнер все еще создается. Кстати, вы можете пересмотреть это демонстрационное видео на моем сайте. Вы видите, как выглядит service для приложения mysql – здесь содержатся IP-адреса кластера, внешние IP-адреса, номера портов и сетевые протоколы.
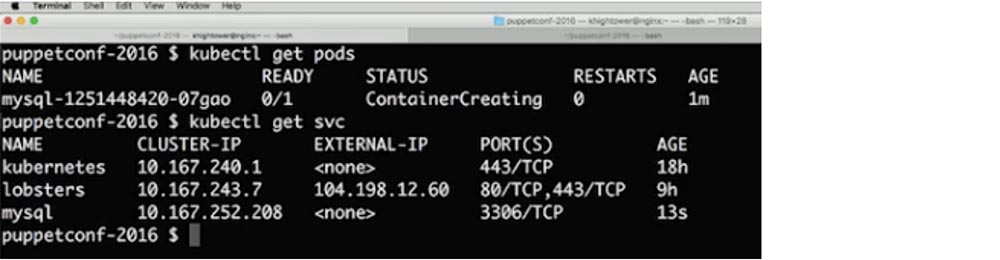
Давайте посмотрим, что происходит с этим конкретным контейнером. Как видите, он работает.

Итак, в данный момент я верю, что приложение mysql действительно работает. Следующее, что нам нужно – это web-приложение. Поэтому давайте развернем такое приложение под названием «lobsters», я взял его на GitHub, это клон Hacker News. Он представляет собой проект Ruby-on-Rails, я просто создал контейнер на основе приведенных здесь данных и базовой конфигурации.
Если вы не в курсе: материалы Hacker News сделают вас супер популярным на любой хакерской конференции. Просто прочитайте, о чем здесь написано, и вы сможете обсуждать все популярные темы из мира компьютерных технологий. Так что если хотите произвести на окружающих впечатление – читайте новости этого портала.
Итак, я хочу создать клон этой штуки и выложить его в интернете, чтобы зарабатывать деньги. Конечно, это не настоящий бизнес-проект, а всего лишь демонстрация возможностей.
Сейчас я развертываю приложение под названием Lobsters. Из своего secret я беру URL базы данных, для чего использую команду $ kubectl get secrets. В secret также имеется имя пользователя и пароль.
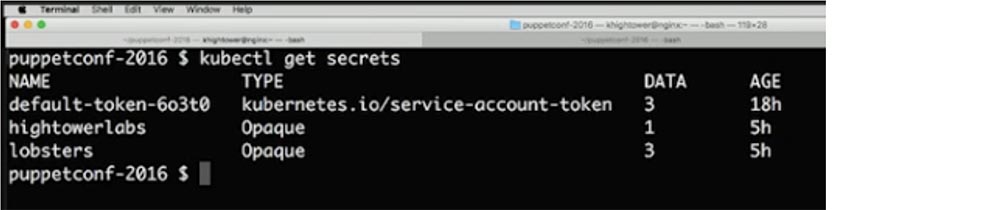
Далее я хочу создать контейнер, который будет общаться с моим приложением, для чего использую команду $ kubectl create –f deployments/lobsters.yaml. Как видите, приложение запущено.
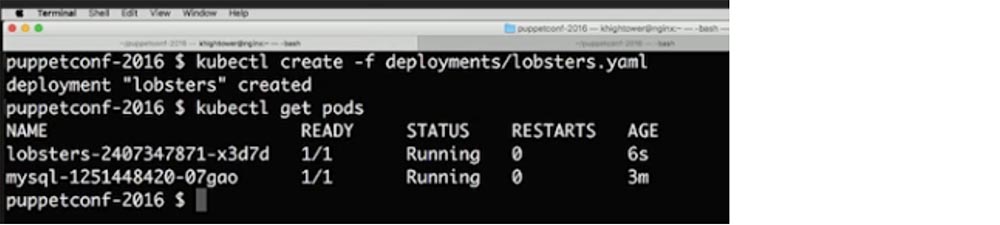
Кроме того, у нас имеется IP-адрес. Я ввожу команду $ kubectl get svc и задействую глобальный балансировщик нагрузки, который указывает на страницу с внешним IP-адресом 101.198.12.60.
Перейдем в браузер и попробуем ввести этот адрес через HTTP. Ага, ошибка ожидания миграции! Это же Ruby-on-Rails, так что я ждал чего-то такого.
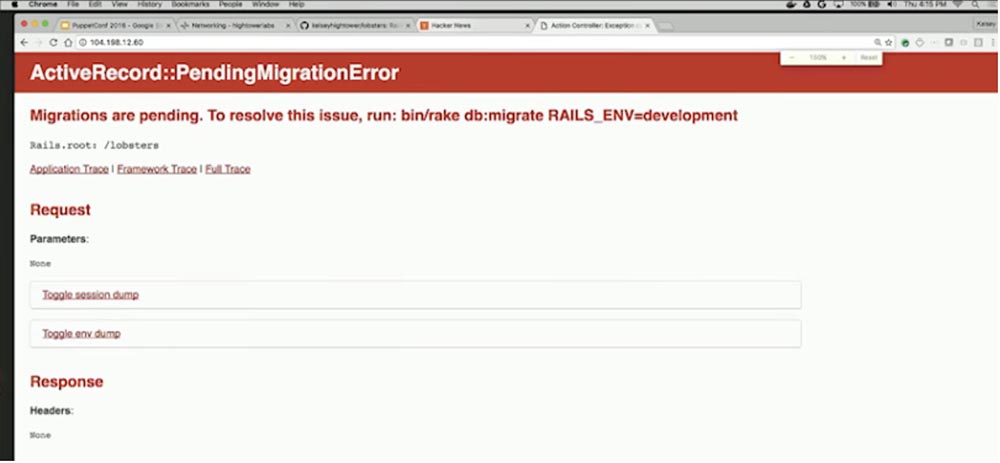
Итак, нам нужен перенос базы данных. Нам нужно единожды запустить этот процесс, и все. Однако мы хотим проделать это таким же образом – никакой авторизации на сервере, никаких особых серверов типа Jump box, мы хотим обратиться к планировщику и сказать: «Эй, запусти эту задачу один раз и после выполнения просто убей процесс!». То есть я хочу запустить всего одну команду и выйти. Поэтому для выполнения пакетной обработки с помощью команды $ cat jobs/lobsters-db-schema-load.yaml я создаю объект Jobs, который реализует такую схему.
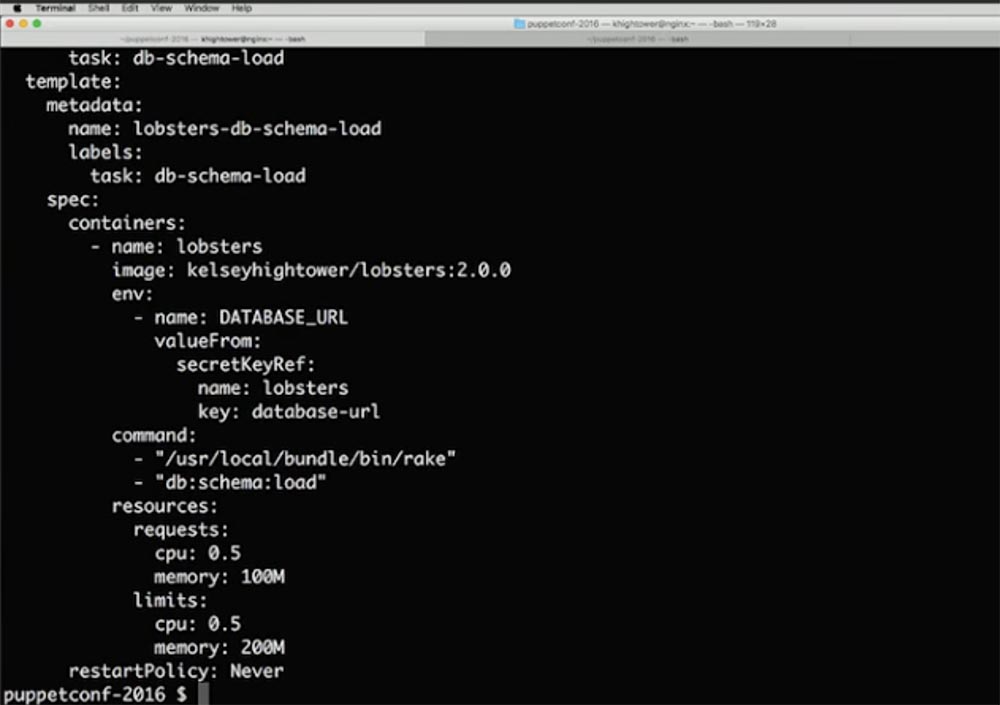
Командный флаг rake «db:schema:load» отправляется прямо на сайт GitHub и говорит: «возьмите код image: kelseyhightower/lobsters:2.0.0 и запустите эту команду 1 раз». Строка restartPolicy:never в конце кода указывает Kubernetis, что он должен запустить это всего один раз и никогда не повторять. Я также ограничиваю ресурсы процессора и памяти, то есть указываю параметры подходящей машины, на которой это можно запустить и выполнить, после чего перенос базы данных будет завершен. Так я «выставляю на рельсы» все объекты Jobs, которые должны запускаться в системе, используя команду $ kubectl create –f jobs/lobsters-db-schema-load.yaml.
Вы видите, что соответствующий job создан, после чего я набираю команду $ watch kubectl get jobs.

Итак, контейнер был притянут к машине, планировщик сработал, rake task создана. Вернемся и обновим страницу с ошибкой базы данных. Как видите, теперь наша схема удачно реализована.
Далее мне нужно залогиниться. Я использую команду $ kubectl create –f jobs/lobsters-db-seed.yaml. Вы видите, что планировщик еще загружает контейнер, и спустя несколько секунд работа закончена. Для запуска миграции мы используем тот же уровень кода, что и раньше. Я авторизуюсь на данной странице, и все, что нужно сейчас проделать – это получить контент. Контент необходим, если мы хотим «поднять» немного денег. Вот так выглядит growth hacking, или «взламывание роста» – вы идете на чужой сайт, утаскиваете оттуда контент и выкладываете его на собственном сайте, который внешне похож на оригинал.
Но нам нужен не просто контент, а хороший контент. Было бы обидно пускать все на самотек, поэтому я вручную заимствую несколько новостей. Можно было скопировать контент автоматически, но это не законно. Так что я выбираю новость, копирую адрес ссылки, устанавливаю тег «test», отмечаю чекбокс «Я являюсь автором истории, расположенной по данному URL» и жму кнопку Submit. Смотрите, как прекрасно выглядит украденная новость!
Теперь настало время масштабировать приложение. Для этого просто нужно изменить определение того, что мы делаем – вместо 1 реплики перейти, например, к 10. Затем я снова запускаю блок команд.

Kubernetes принимает эту информацию, совершает действие, и теперь у нас в поде работает 10 копий приложения Lobsters. Причем этот процесс автоматически добавляется в балансировщик нагрузки благодаря работе Services.
Посмотрим, что происходит в бэкенде. Для этого я использую команду $ kubectl get svc, получаю краткое состояние и прошу его описать командой $ kubectl describe svc. Kubernetes автоматически определяет все наши конечные точки endpoints и размещает их за балансировщиком нагрузки.
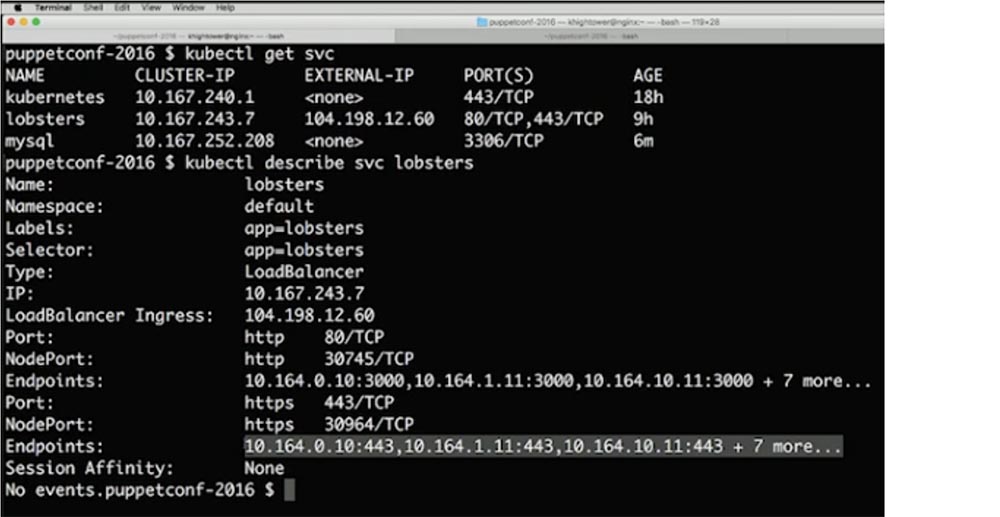
При этом все, что бесполезно, удаляется, а все, что необходимо, автоматически добавляется. Нам не нужно создавать эту штуку снова и снова, все полностью интегрировано в платформу.
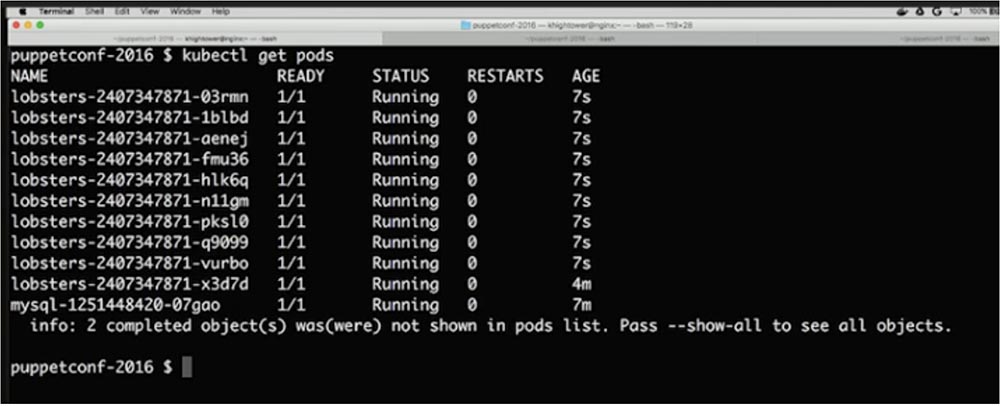
Следующий важный вопрос – как производить обновление и как получать логи. Если помните, я отнял у вас SSH-доступ, поэтому вам нужна централизация журналов с помощью чего-то вроде Log Stash или внутренний логгинг Google Cloud. Но если вы просто хотите просмотреть логи ad hoc, помните, что у вас нет доступа к машинам. Однако вы можете использовать API, чтобы захватывать логи при помощи имен контейнеров. Для этого нужно ввести команду $ kubectl logs lobsters-240734871-03rmn –f, где 03rmn – имя конкретной копии приложения lobsters-240734871в контейнере. Так можно просмотреть лог каждого контейнера с репликой, чтобы при необходимости устранить неполадки.
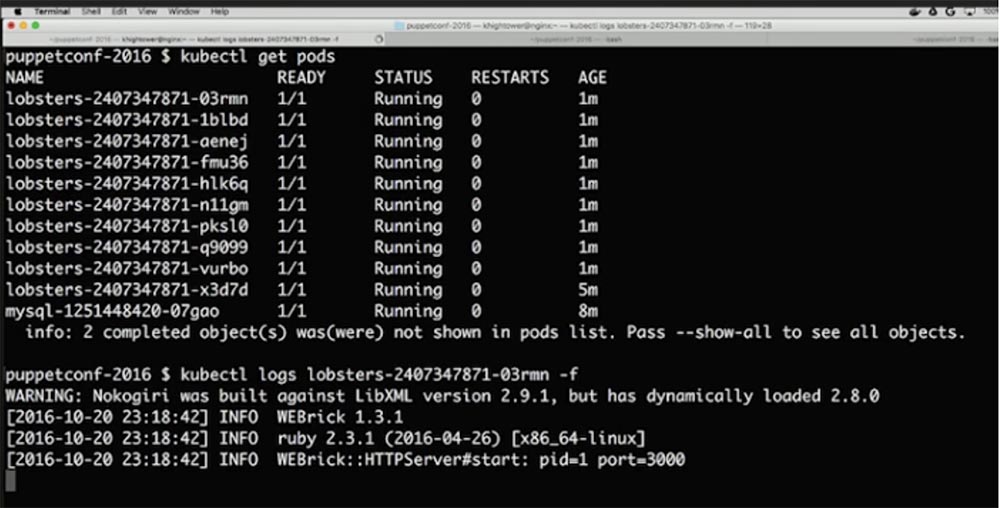
Просмотрим наш контент с помощью команды $ kubectl get pods, как видите, все работает. Следующая важная вещь, которую нужно проделать — это нанять маркетолога. Он смотрит на эту страничку и говорит: «Делайте что хотите, но уберите с сайта эти белые места!».
Все, что нужно для этого сделать — создать новый контейнер вдобавок к уже созданному и настроить CSS для того, что мы хотим раскрутить. Напомню – речь не идет об узлах, ноды нам не важны, потому что сама система обеспечит именно то, что мы хотим.
Продолжение будет совсем скоро…
Немного рекламы 🙂
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
ссылка на оригинал статьи https://habr.com/ru/company/ua-hosting/blog/504358/
Добавить комментарий