
Сегодня мы без привязки к конкретным моделям сетевого оборудования расскажем, как принцип «от автоматизации к автономности» воплощается в новых возможностях продукта FabricInsight. Ведь за последнее время не только состав его изменился, но и появились многочисленные новые сценарии, позволяющие определить текущее состояние сети и предсказать возможные проблемы в ней.
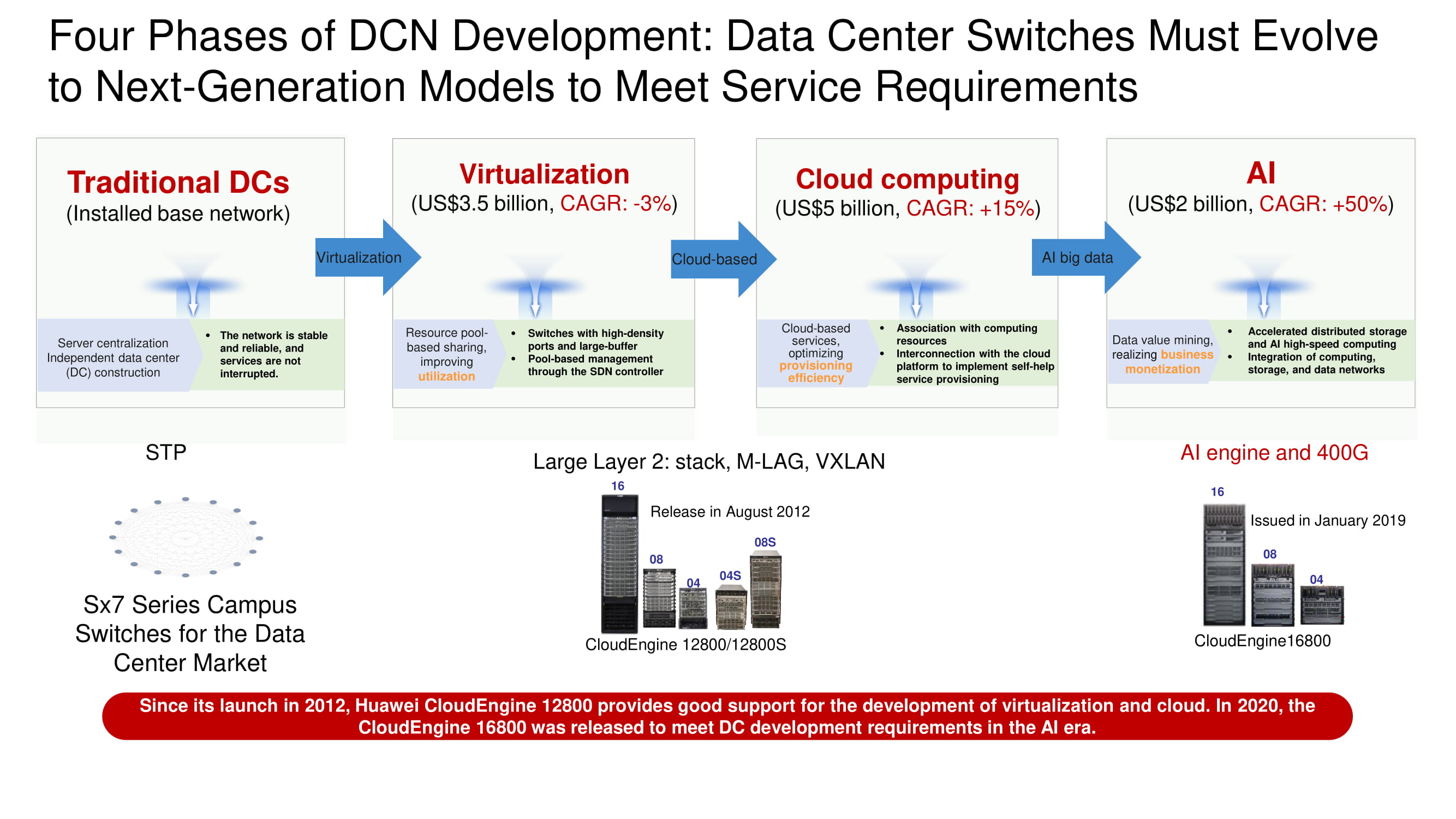
Четыре этапа развития ЦОДа
Определяя вектор развития сетей центров обработки данных, нетрудно заметить, как традиционные архитектуры ЦОДов постепенно пали под натиском систем виртуализации, затем пережили массовую миграцию ресурсов и сервисов в облака, а теперь вплотную подошли к широкому внедрению систем искусственного интеллекта и скоростных интерфейсов 400 Гбит/с. Возможности ИИ необходимы для построения сетей «Ethernet без потерь» и создания приложений, полностью невосприимчивых к задержкам.
Ещё одна сфера применения ИИ — анализ и мониторинг работы ЦОДа. Нам предстоит перейти от идеологии, подразумевающей функционально ограниченный мониторинг состояния неких «чёрных ящиков», к концепции полностью прозрачных сетей, о которых известно всё.

В качестве основных инфраструктурных сетевых единиц для построения сетей ЦОД Huawei предлагает сейчас линейку четырёх-, восьми- и шестнадцатислотовых коммутаторов CloudEngine 16800 с аплинками 400 Гбит/с; их выпуск намечен на текущий год. Также среди новинок отметим построенные на нашей собственной элементной базе ToR-свитчи CloudEngine 6881 и 6863 с интерфейсами 10 и 25 Гбит/с соответственно.

На иллюстрации показаны модели коммутаторов из линейки CloudEngine 16800 с классической ортогональной архитектурой, которые оснащены системой охлаждения front-to-back, а также совместимые с ними линейные карты, снабжённые интерфейсами 10, 40 и 100 Гбит/с.
Из важных базовых функций CloudEngine 16800 выделим его умение работать с NSH (Network Service Header), что позволяет реализовать в ЦОДе распределённую по нескольким свитчам микросегментацию (изоляцию на уровне виртуальных машин), обеспечить широкие возможности телеметрии и проводить анализ трафика на границе сети (edge intelligence) с применением технологий искусственного интеллекта на базе AI-чипов Huawei.
По-настоящему революционной станет модель V1R19C10. Именно в ней должны быть реализованы многие давно ожидаемые функции, в том числе EVPN Multihoming без «перемычки» в виде M-LAG (Multi-Switch Link Aggregation) на основании первого и четвертого типов маршрутов в EVPN-роутинге VXLAN.
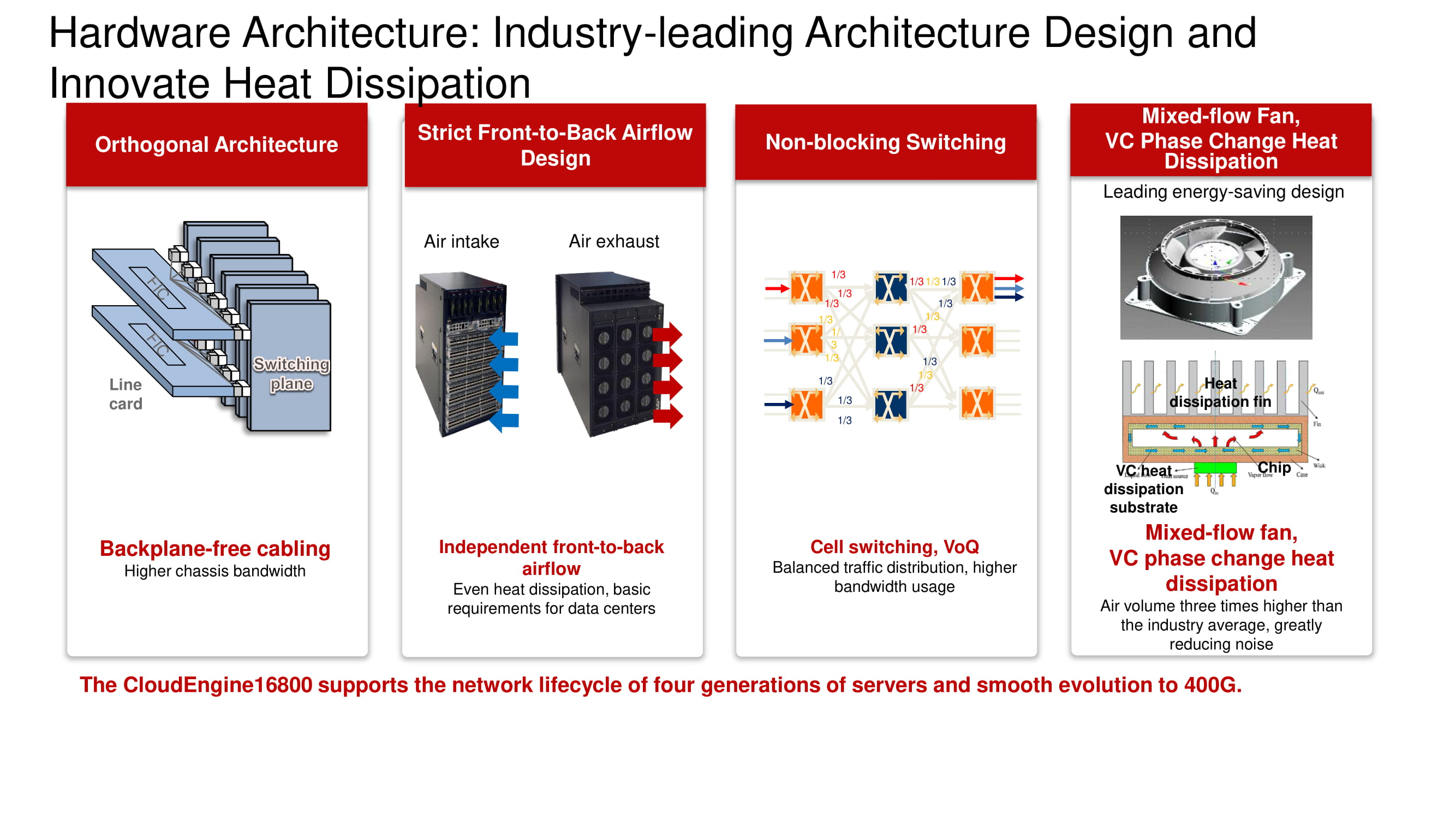
Знакомая архитектура и новые возможности
На схеме видна привычная ортогональная архитектура трёхуровневой «фабрики» Non-blocking Switching. К её первоочередным достоинствам стоит отнести оптимальное расположение плат «фабрики», линейных карт, коннекторов и системы обдува, основанной на вентиляторах с переменной скоростью вращения.
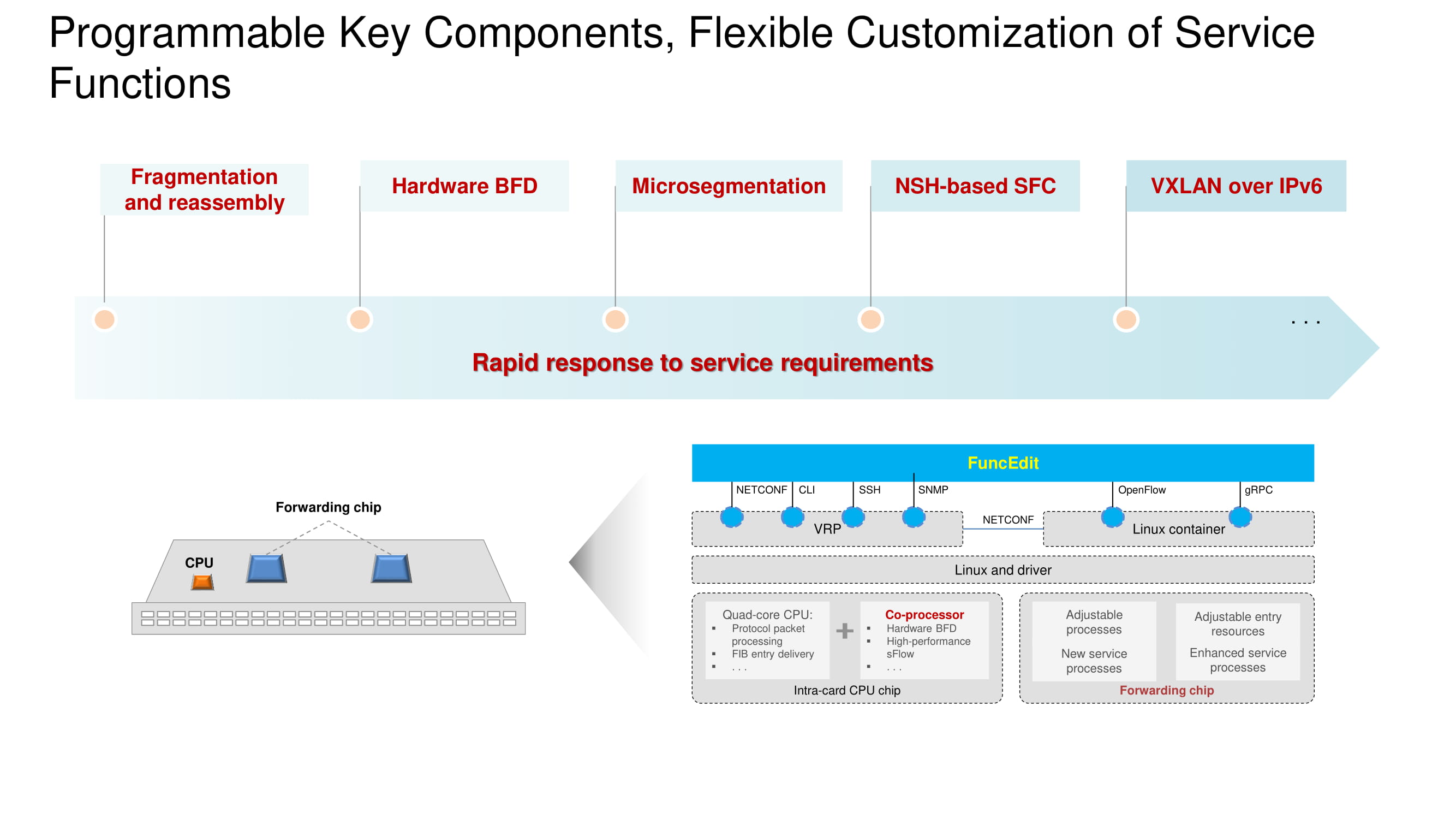
Важно, что на новых моделях коммутаторов аппаратно реализован протокол BFD (Bidirectional Forwarding Detection) и есть возможность настройки VXLAN в адресном пространстве IPv6. Базовая архитектура осталась прежней и строится на процессоре, сопроцессоре и forwarding chip. Функциональность каждого из узлов представлена на схеме. Главное же изменение 2020 года — переход на собственные чипы Huawei во флагманских коммутаторах, полноценно конкурирующие с аналогами от Broadcom.
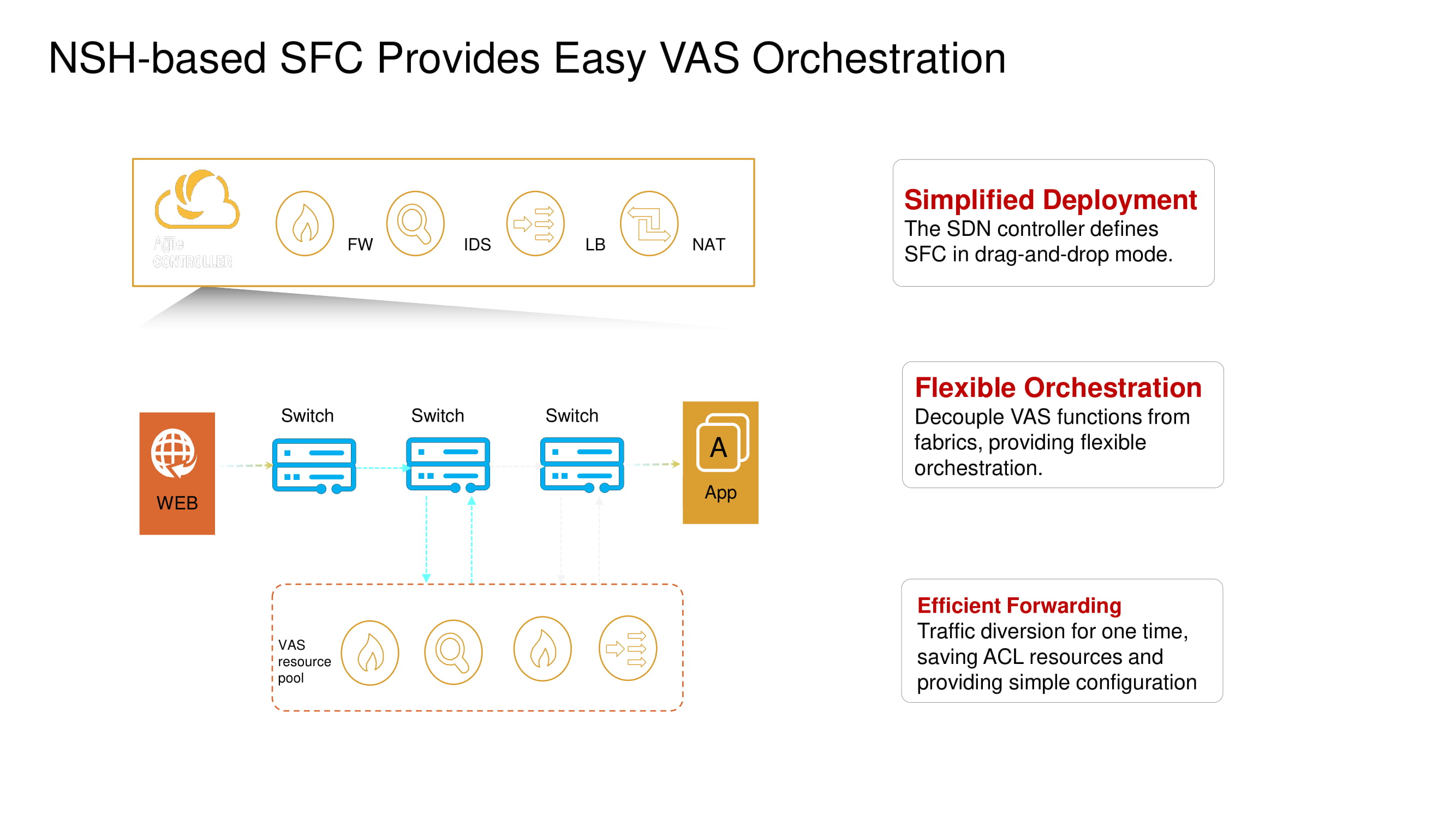
Поддержка операций с Network Service Header позволяет новым коммутаторам менять дефолтные маршруты пакетов VXLAN и подключать такие сервисы, как межсетевые экраны (FW), системы обнаружения вторжений (IDS), балансировщики нагрузки (SLB) и NAT.
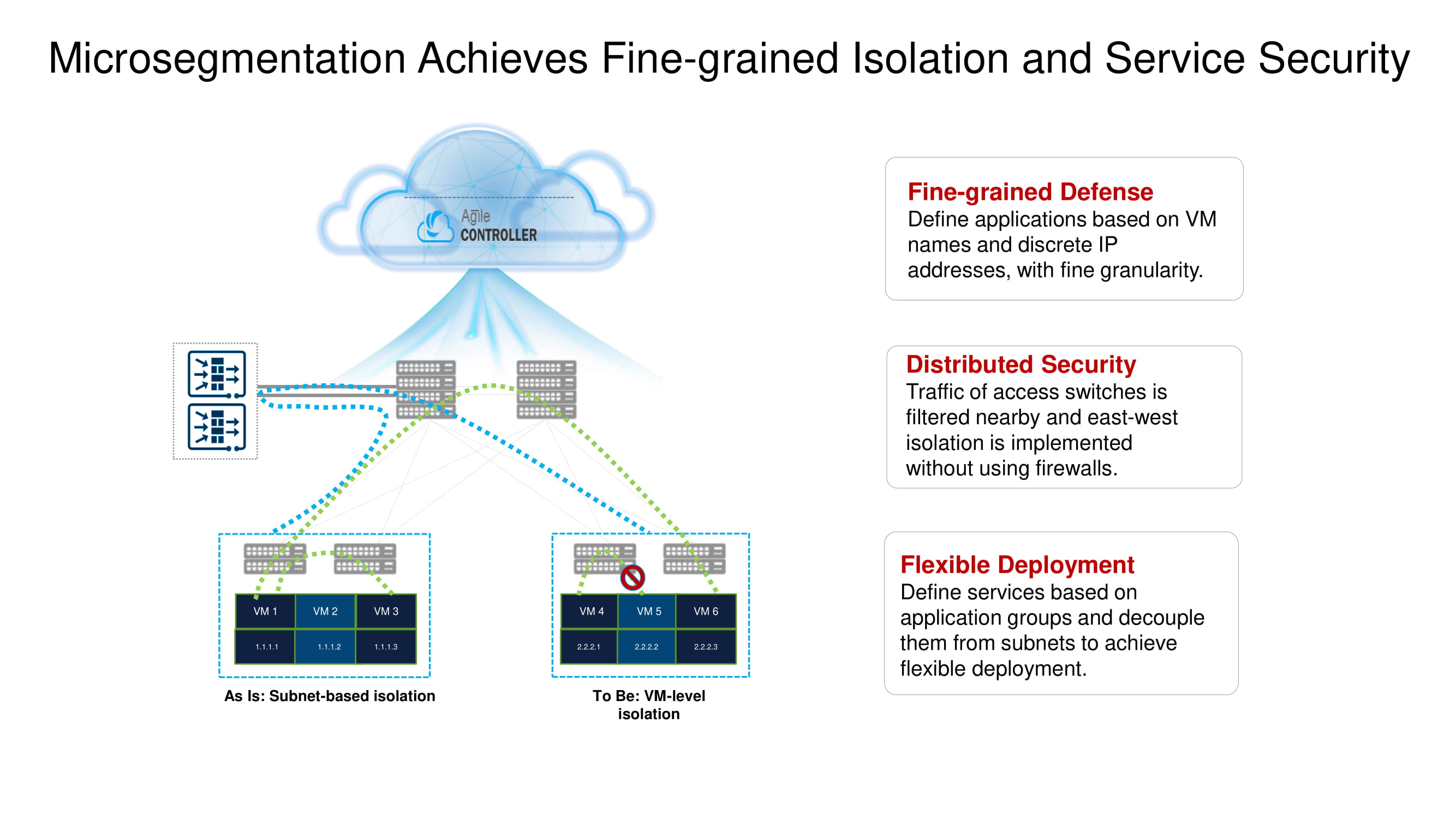
Вернёмся ненадолго к ранее упомянутой разделённой микросегментации. Новые ToR-коммутаторы Huawei с помощью всё тех же NSH позволяют изолировать рабочие нагрузки на уровне имён виртуальных машин. Эти машины можно дополнительно группировать на уровне подсетей, на основании номеров портов, вышестоящих протоколов и пр., таким образом формируя группы приложений.
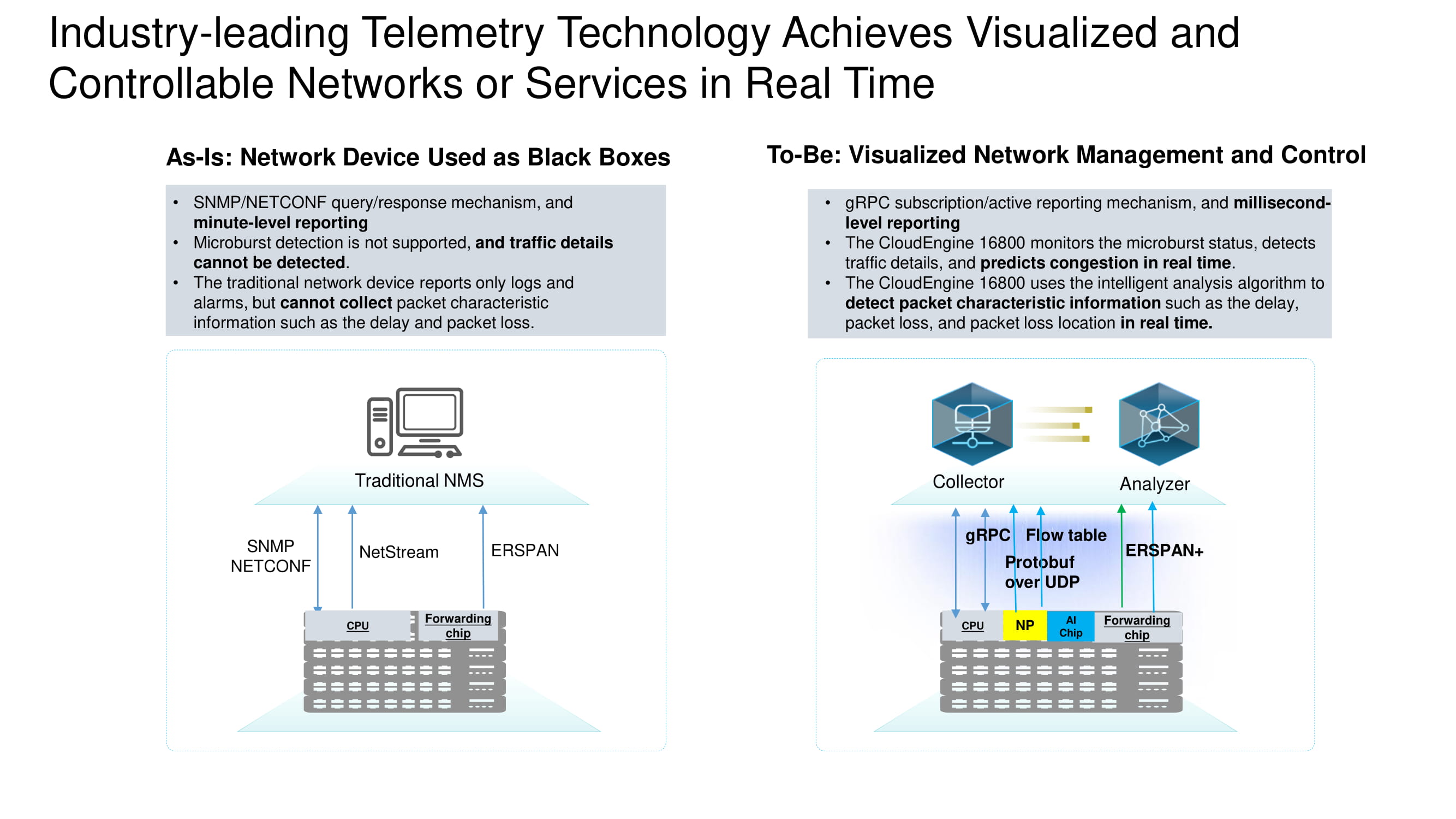
Полный спектр телеметрических данных
Информация с устройств собирается в реальном времени с использованием нескольких основных протоколов. Задачей ERSPAN+ является сбор TCP-заголовков для последующего детального анализа TCP-потоков в ЦОДе. Дополнительные данные добываются с помощью протокола gRPC и таблицы переадресации (Flow table). Всё это собирается с Protobuf over UDP.
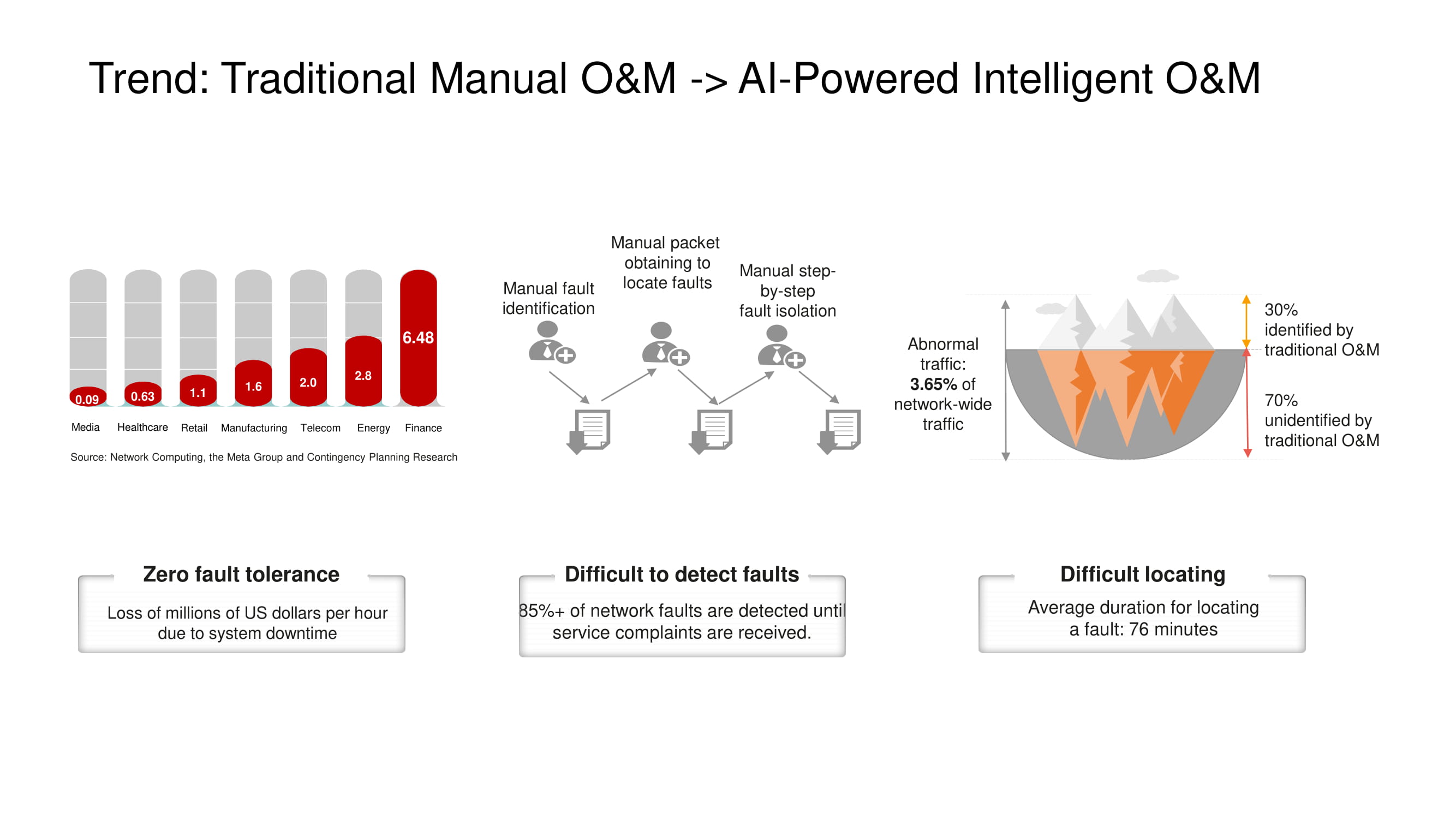
Основное направление развития средств O&M в Huawei — переход от ручного или полуавтоматического контроля сети к полностью автоматическому, основанному на технологиях искусственного интеллекта. Всеохватная система телеметрии достаточно крупной площадки производит огромные объёмы данных, анализ которых в сжатые сроки возможен только с применением ИИ. Особенно это важно в тех ЦОДах, где сбои и простои просто недопустимы.
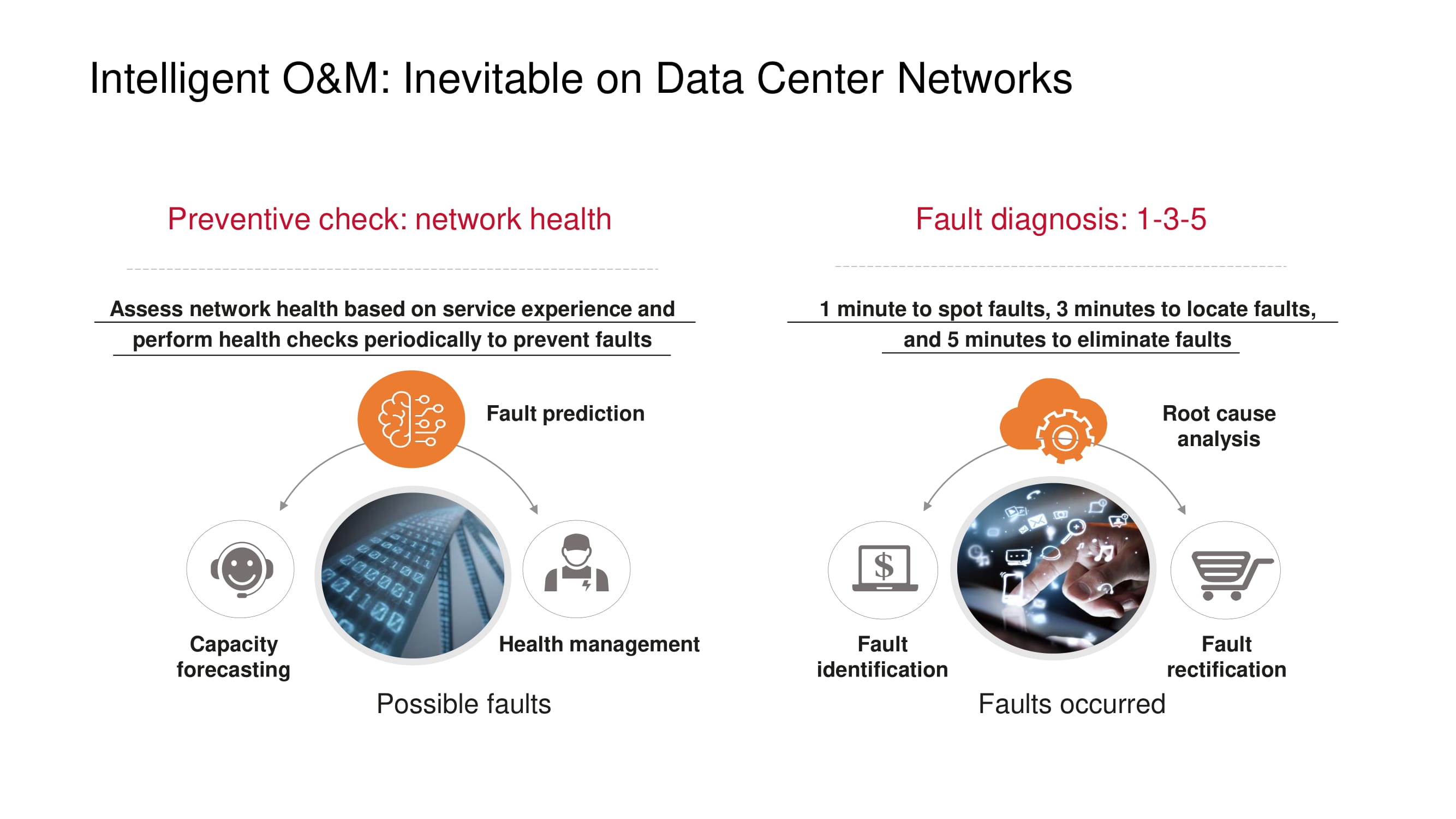
К превентивным мерам, призванным не допустить возникновения неполадок в работе сети, прежде всего стоит отнести мониторинг «здоровья» сети: контроль загрузки каналов, выявление причин потери пакетов (допустим, поиск корреляции с временем суток или периодами работы какого-либо приложения), обнаружение «узких» мест (capacity forecasting) и пр.
Если неполадки всё же наблюдаются, минимизировать время диагностики и восстановления помогает выдвинутый Huawei принцип 1-3-5: минута на поиск, три минуты на локализацию, пять минут на ликвидацию проблемы. Для того чтобы укладываться в эти рамки, продукты Huawei поддерживают постоянно расширяющийся список типовых неисправностей, которые определяются автоматически.

Модель V100R019C10 для небольших ЦОДов
Одним из главных нововведений в V100R019C10 стала поддержка визуализации на основе телеметрических данных во всех типах сценариев. По сути, речь идёт о наглядном отображении любых изменений в сети. Кроме того, устройство теперь умеет определять более 75 первопричин возникновения тех или иных проблем и помогает наметить действия для их устранения (запуск скриптов и пр.).
Важной новостью стало появление версии Standalone, включающей в себя как iMaster NCE, так и FabricInsight и предназначенной главным образом для дата-центров небольшого размера, не требующих нескольких серверов для управления сетью.
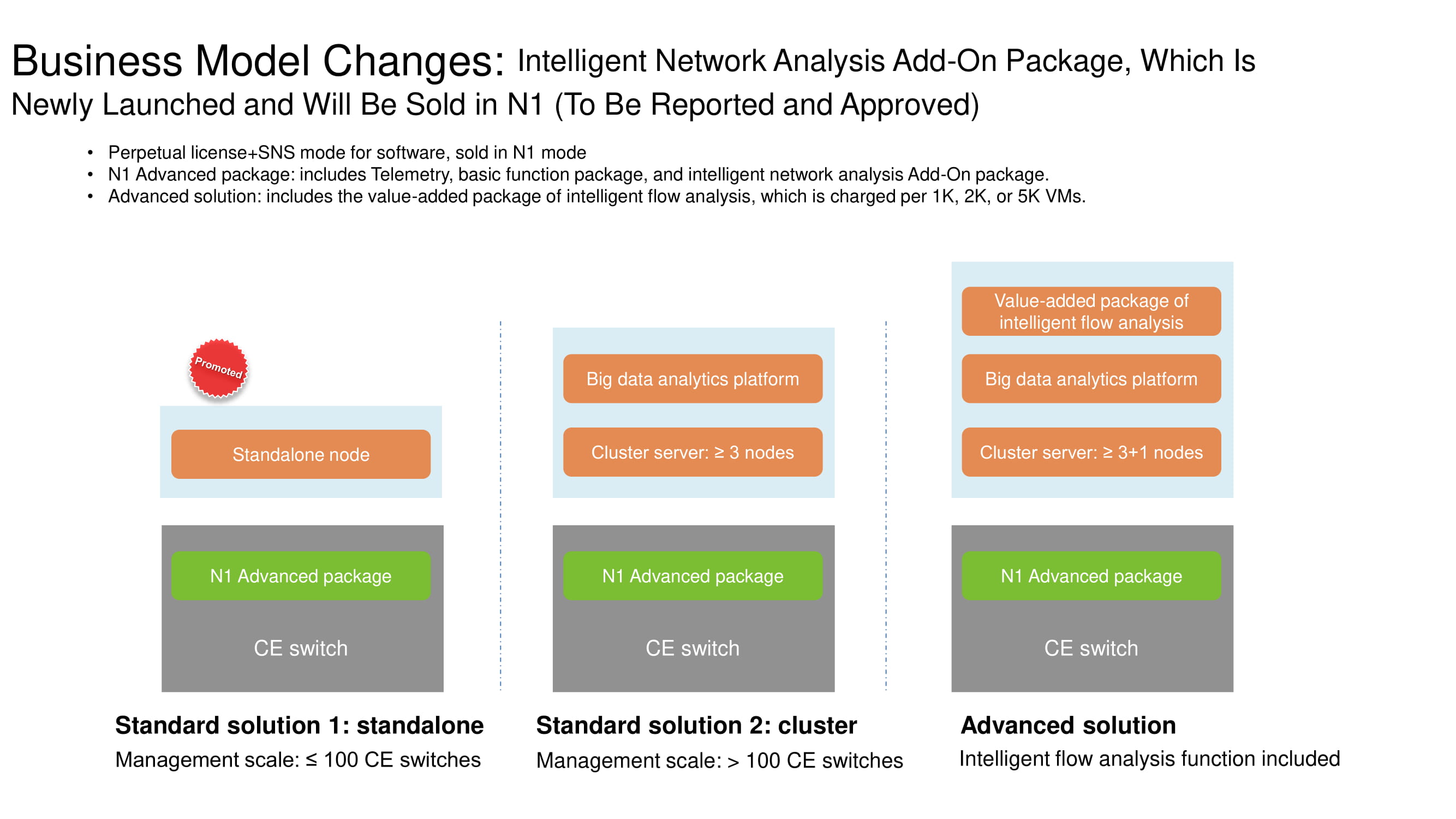
Изменения в системе лицензирования
Для лучшего понимания функциональных особенностей FabricInsight следует пояснить, какие изменения произошли в бизнес-модели распространения сетевых продуктов Huawei. Если количество коммутаторов не достигает сотни, такой вариант классифицируется как standalone edition и подразумевает наличие лицензии N1. Кластер из трёх и более серверов уже поставляется в комплекте с платформой аналитики больших данных. Решение Advanced solution, включающее в себя несколько сотен свитчей, рекомендуется использовать совместно с инструментарием для анализа сетевых потоков. Все три варианта допускают использование возможностей FabricInsight при наличии лицензии N1.
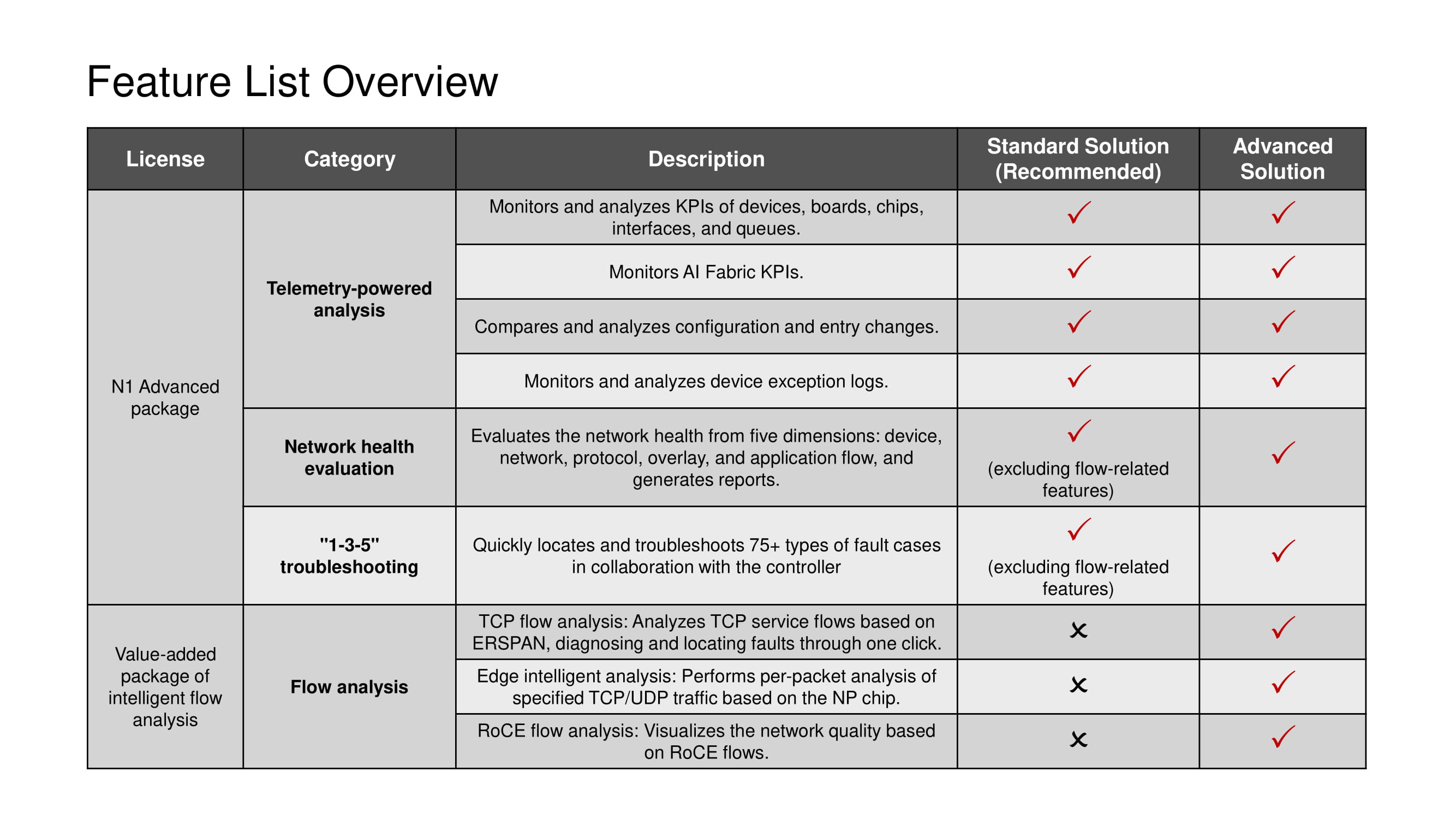
Любая лицензия подразумевает применение всего набора телеметрических инструментов и сценариев 1-3-5, за исключением средств анализа TCP-потоков, доступных только в Advanced solution.
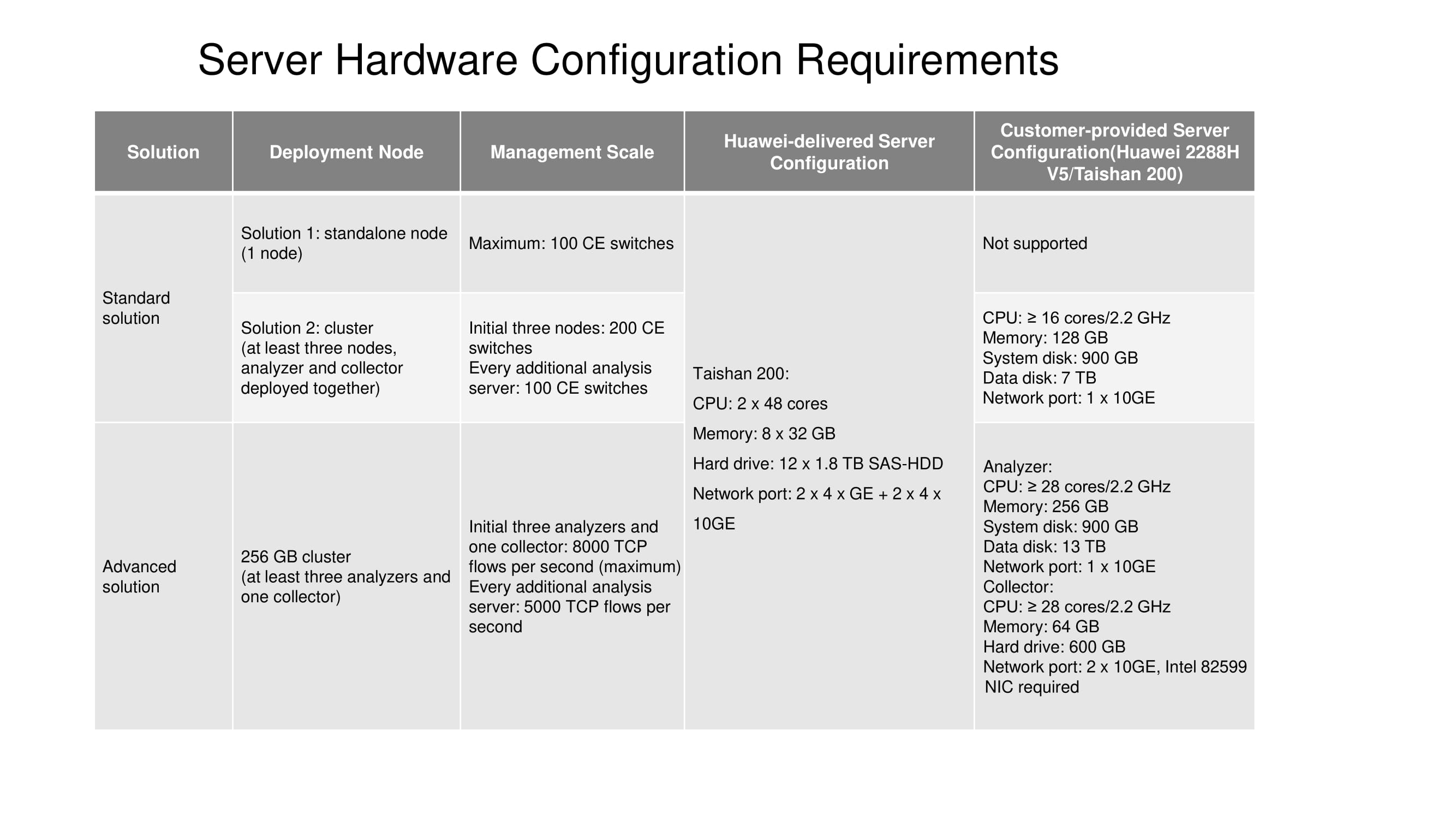
Осталось рассказать о конфигурациях серверов, предназначенных для решений Standard и Advanced solution. На сегодняшний день standalone node (один узел) доступен только на сервере Taishan 200. Для работы кластера из трёх узлов необходимо 16 или более вычислительных ядер, 128 Гбайт оперативной памяти и т. д. (см. схему). Объём дата-диска напрямую зависит от того, как долго должна храниться статистика.

KPI-мониторинг
Чуть подробнее остановимся на KPI-мониторинге. Для его применения достаточно задать временной интервал и конкретные пороговые значения, достижение которых будет проверяться на основании полученных телеметрических данных. Доступно много типов метрик, среди которых:
- использование ЦПУ и памяти;
- использование FIB / MAC;
- использование троичной ассоциативной памяти (TCAM) чипа;
- параметры портов;
- размер буфера для очереди;
- разные метрики AI Fabric;
- уровень сигнала, температура и другие параметры работы оптического модуля;
- потеря пакетов.
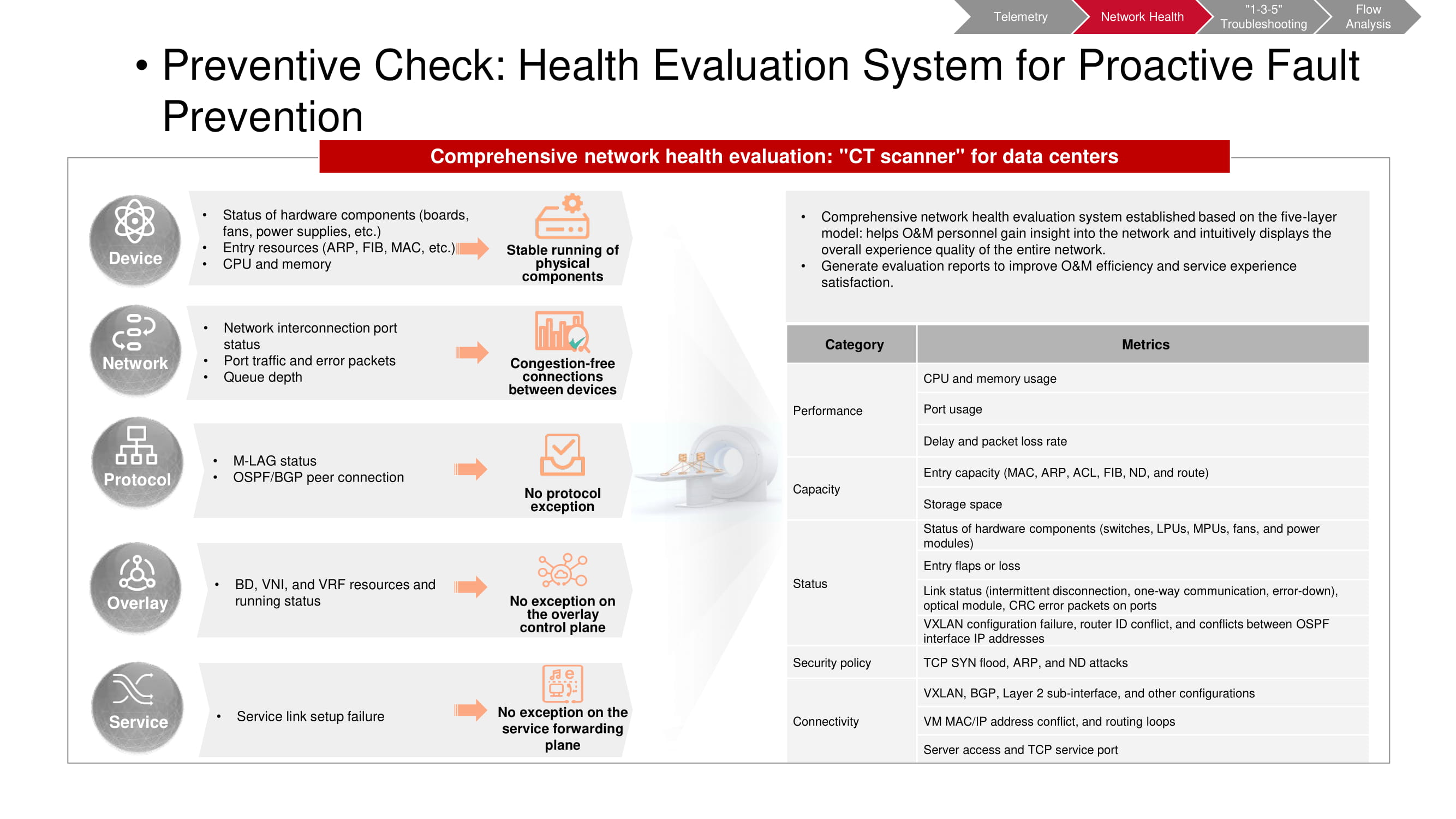
Предварительная проверка
Инструмент предварительной проверки также оперирует данными, получаемыми с помощью телеметрии. CT scanner позволяет понять, происходили ли в сети те или иные нежелательные события. Часть метрик совпадает с метриками KPI-мониторинга «фабрики» (главным образом касающиеся ёмкости и производительности). Остальные основываются на результатах анализа верхнего уровня (VXLAN, BGP и др.) и анализа конфигурации. После запуска CT scanner собирает необходимые сведения и формирует исчерпывающий отчёт о состоянии сети.
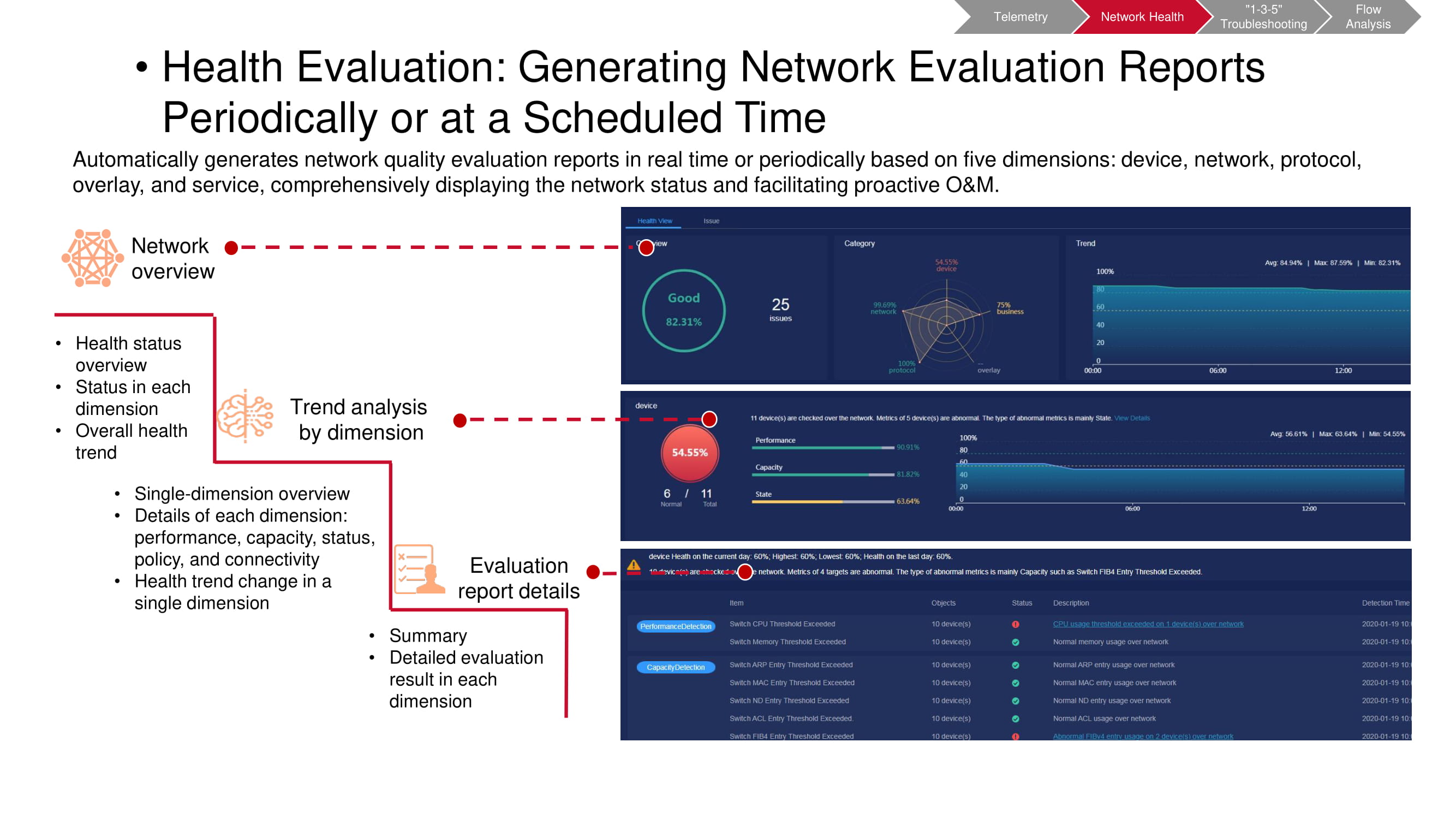
Выполнять подобные проверки необходимо регулярно, заранее определив интервалы времени между ними. Так легче вовремя заметить возникающие в сети тренды, включающие как периодические, так и непериодические изменения. Это позволяет гораздо полнее и оперативнее понимать, что именно происходит. Притом какой-либо параметр, представляющий особый интерес, можно выбрать для более детального мониторинга.
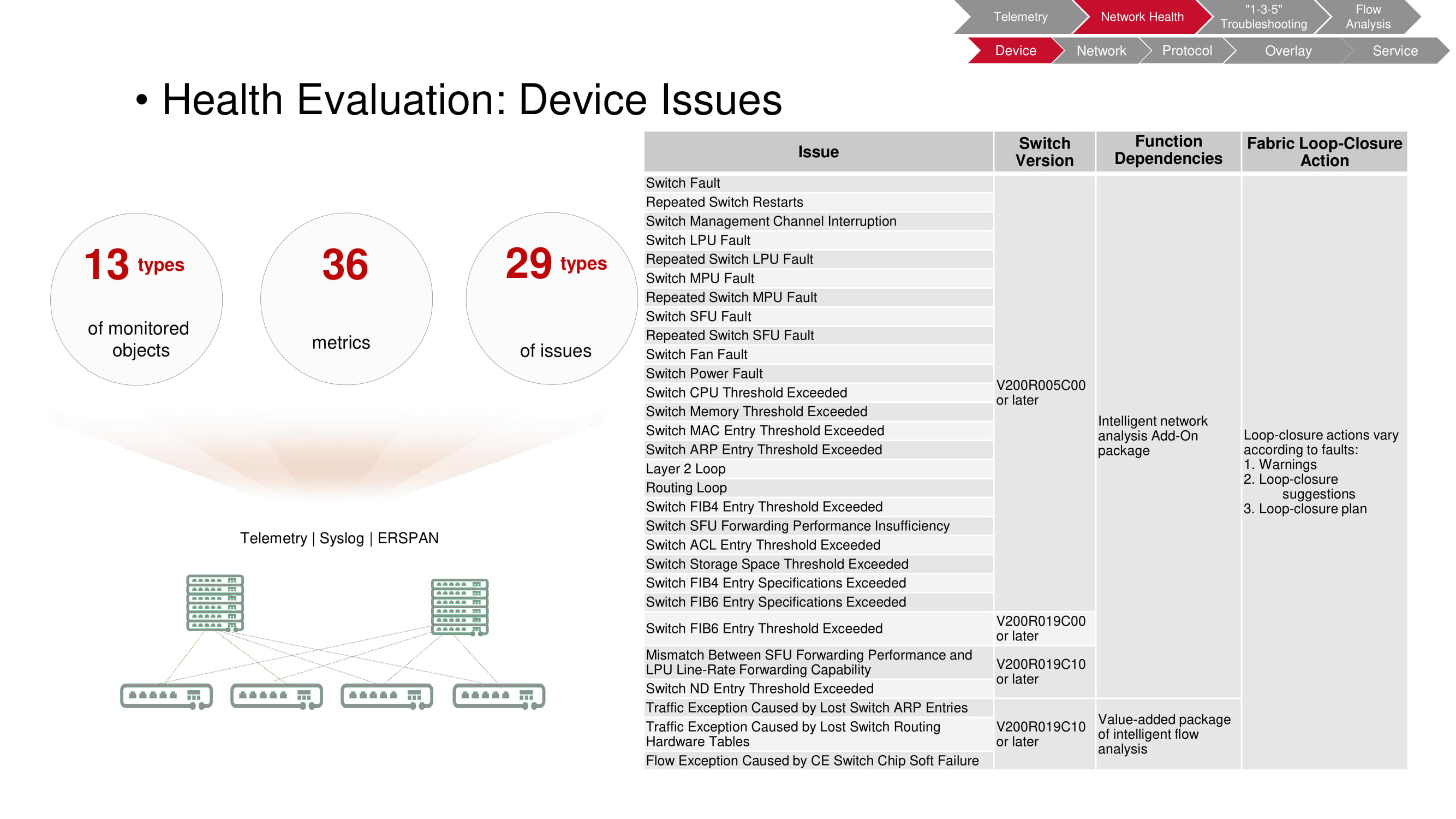
Неполадки устройств
Мониторинг позволяет выявлять самые разнообразные проблемы, возникающие на уровне устройств. В рассматриваемом случае объектом проверки является свитч, 36 регистрируемых параметров работы которого дают возможность обнаруживать 29 типов неисправностей.
В таблице на схеме перечислены виды неисправностей; модели коммутаторов, позволяющих FabricInsight обнаружить проблему; используемые FabricInsight функции; автоматические действия, предпринимаемые при обнаружении неполадок (предупреждения, рекомендации, запуск скрипта).
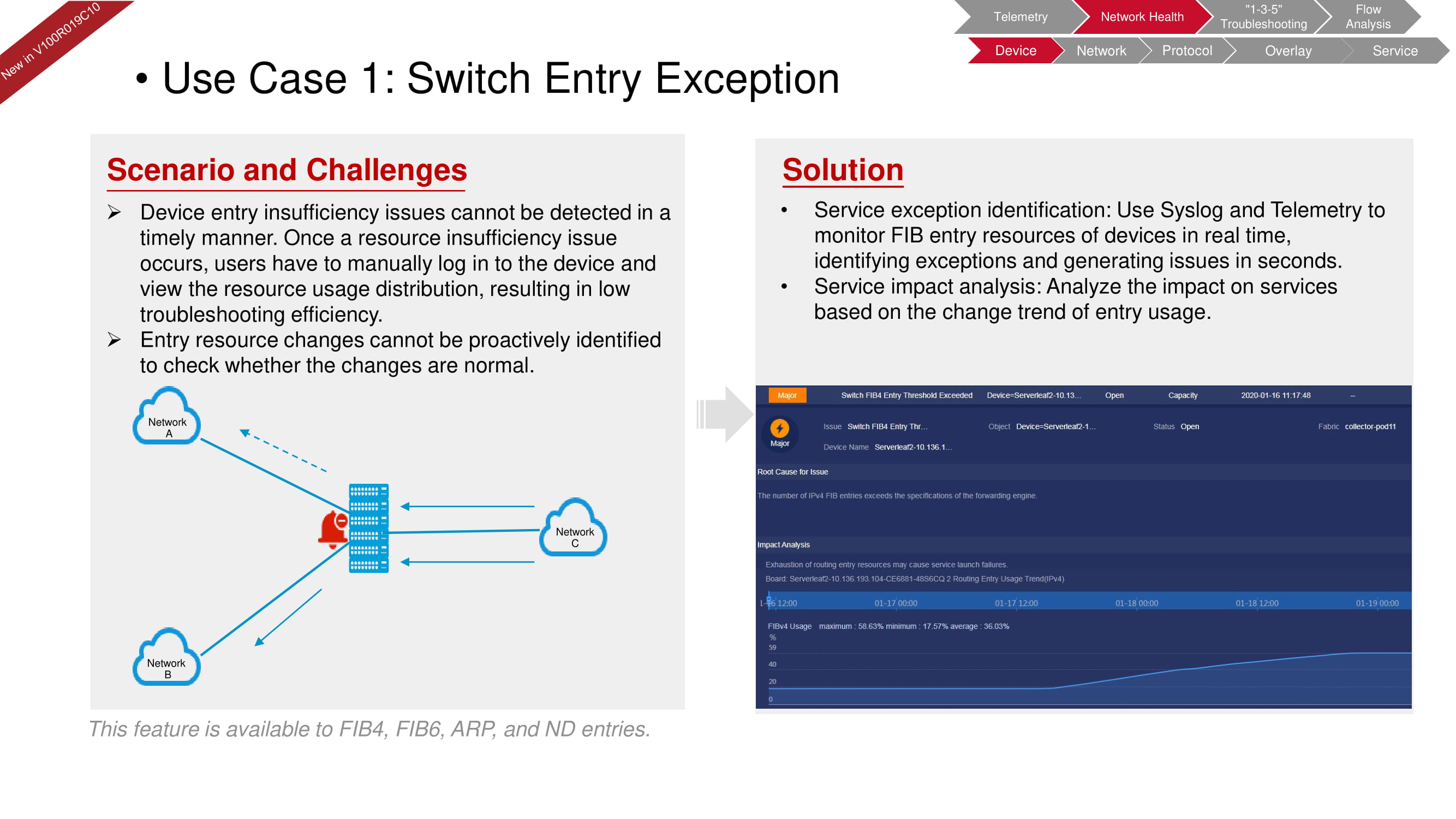
Допустим, у устройства зафиксирована нехватка ресурсов, ведущая к падению уровня сервиса. Данные из системного журнала, объединённые с данными телеметрии FIB-ресурсов, позволяют оперативно оценить ситуацию в режиме ручной проверки.
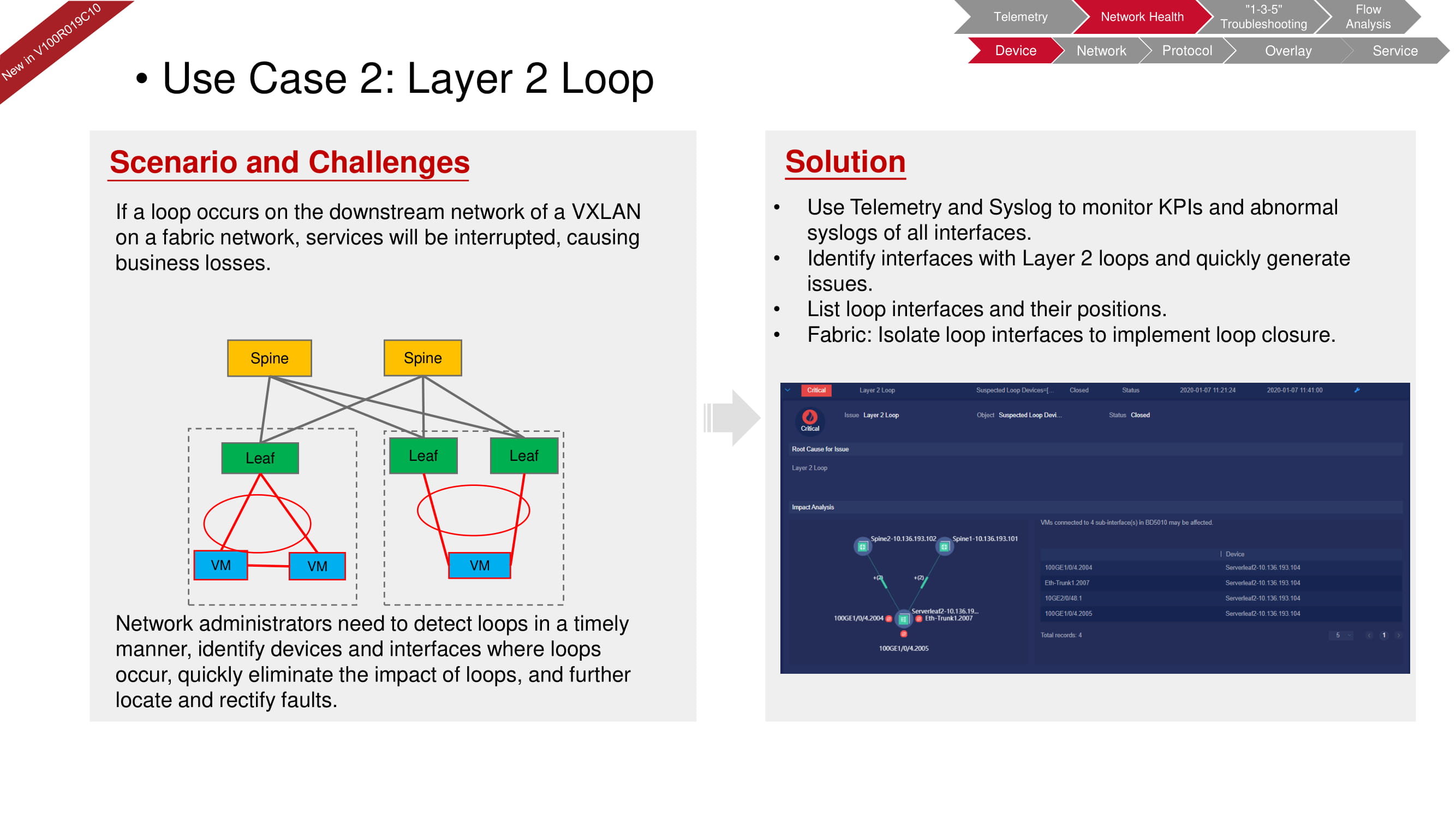
Возникновение петли на уровне оборудования просто невозможно, так как устройство не позволит внести подобную ошибку в конфигурацию. Однако петля может возникнуть, например, на втором уровне (на уровне виртуальной машины) из-за неправильно настроенного программного свитча, как на представленной выше схеме. С помощью FabricInsight можно не только обнаружить неполадку, но и изолировать нужный участок сети, чтобы исключить его влияние на функционирование всей «фабрики».

Неполадки сети
Посредством FabricInsight с опорой на 18 доступных для анализа метрик удаётся выявлять 10 типов сетевых неполадок. На схеме приведён их полный перечень, а также — как и в случае с неполадками устройств — модели коммутаторов, позволяющих FabricInsight обнаружить проблему, используемые функции и доступные автоматические действия.

Допустим, деградация или неисправность оптического модуля приводит к ухудшению его работы: линк становится нестабильным. Такие ситуации возникают нерегулярно, и их трудно воспроизвести. Из-за этого обнаружение проблемы может занять много времени. Средства FabricInsight дают возможность сразу заметить падение уровня сигнала или изменение напряжения на модуле.
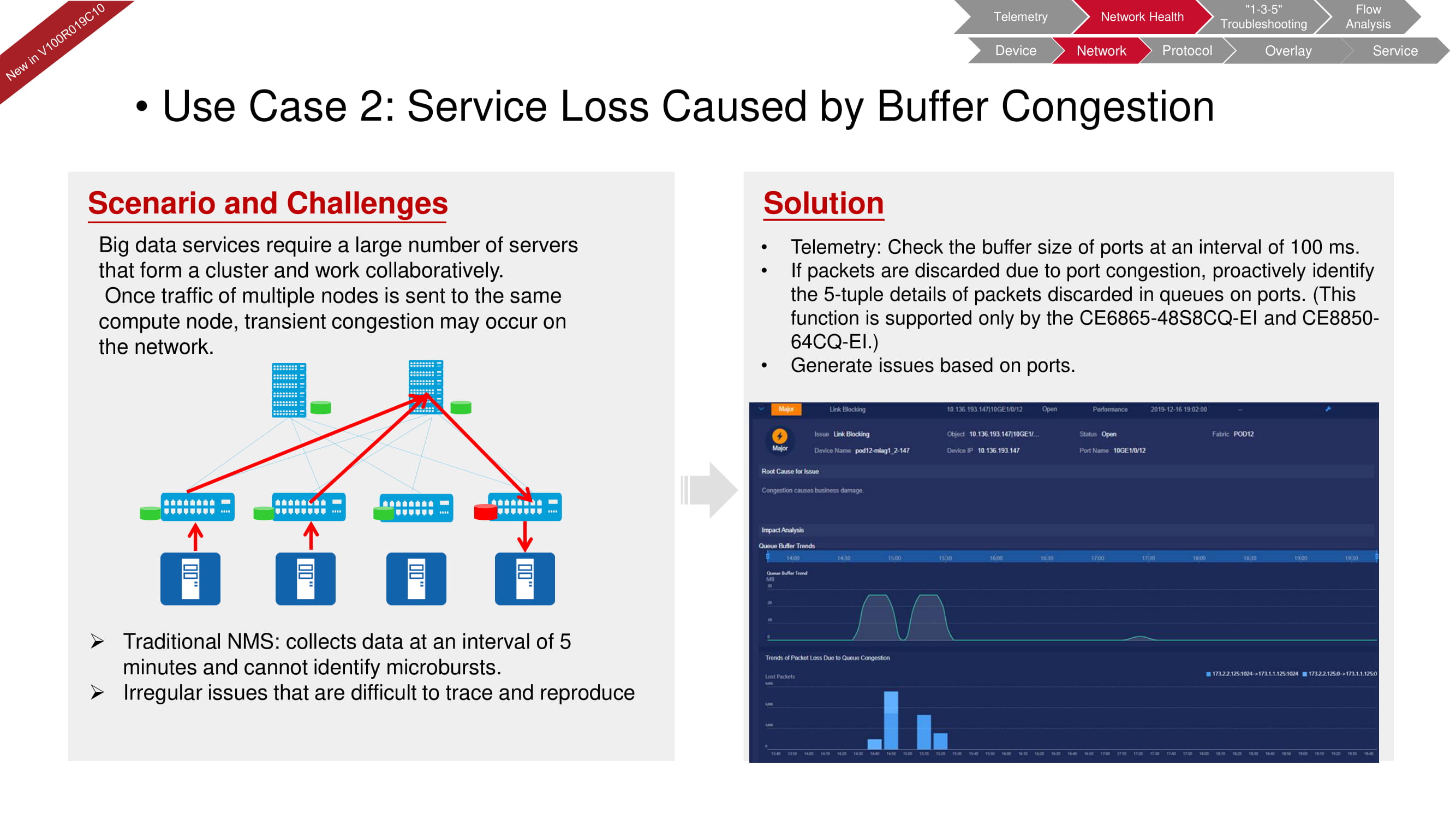
Средствами сетевой диагностики FabricInsight можно своевременно выявить и проблемы с буфером, часто возникающие в системах с большим количеством серверов, которые отведены под обработку big data. Традиционная NMS (Network Management System) проверяет связанные с буфером параметры каждые пять минут. Возможности телеметрии FabricInsight позволяют уменьшить эти интервалы вплоть до 100 мс и выявить даже самые короткие микроинциденты.

Неполадки на уровне протоколов
Здесь FabricInsight умеет определять шесть типов неполадок, включая конфликт двух мастер-свитчей в M-LAG; проблемы взаимодействия соседних коммутаторов и пр. Эта функциональность доступна при использовании коммутаторов V200R005C00 и более новых.

Рассмотрим конфликт мастер-свитчей. При всех достоинствах технологии M-LAG в случае обрыва линка и неисправности одноранговой сети в системе появляются два мастер-свитча. FabricInsight умеет проактивно реагировать на подобную ситуацию благодаря постоянному контролю состояния peer-линка и DFS.

Неполадки оверлейной сети
Семь типов неполадок оверлейной сети могут быть выявлены благодаря контролю десяти различных метрик. FabricInsight умеет проверять статус лицензии VXLAN, находить ошибки в конфигурациях, определять падение sub-интерфейса и т. д. Опции реагирования аналогичны описанным ранее.

Неполадки сервисов
Для выявления шести типов неполадок на уровне сервисов используется контроль семи метрик. Обнаружению поддаются конфликты IP-адресов, проблемы с установлением соединения, флуд-атака TCP SYN и др. Обратим внимание на то, что для поддержки этих возможностей FabricInsight может понадобиться наличие анализатора TCP-потоков.
При более широком взгляде на вопросы поиска неполадок видно, что FabricInsight — это не просто средство сбора данных с устройства, но и расширяемая библиотека сценариев, нацеленных на решение проблем самых разных типов.

От автоматизации к автономности
В качестве резюме скажем, что в основе идеологии Intent-Driven Network лежит трёхступенчатая модель реагирования, которая включает в себя сбор информации, её анализ с привлечением средств ИИ и предложения по изменению состояния сети, в том числе в автоматическом режиме.
***
Напоминаем о том, что наши эксперты регулярно проводят вебинары по продуктам Huawei и по технологиям, которые в них используются. Список вебинаров на ближайшие недели доступен по ссылке.
ссылка на оригинал статьи https://habr.com/ru/company/huawei/blog/510890/
Добавить комментарий