Введение
Анализ актуальной в настоящее время темы искусственного интеллекта и его применения в области юриспруденции мы начали с обзора инструментов синтаксического и семантического анализа текстов, которые применяются при разработке LegalTech-решений.
В комментариях к предыдущей статье красной нитью проходил очень непростой вопрос: а почему бы не извлекать из текста все имеющиеся в нем смыслы? В чем здесь сложность? Такой вопрос — крайне показателен, поэтому мы решили уделить ему более пристальное внимание и дать максимально развернутый ответ.
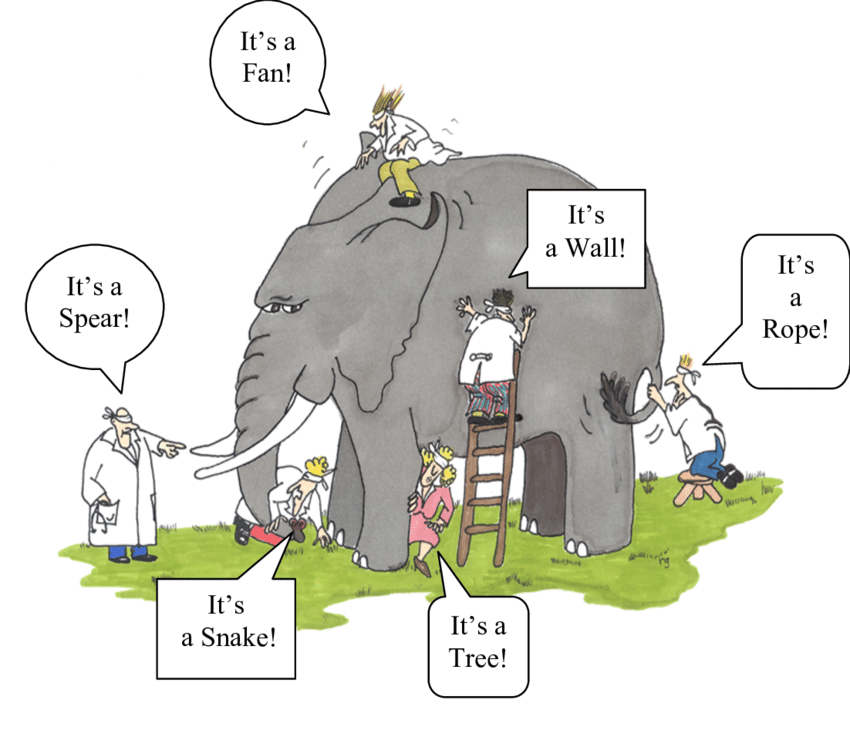
Итак, сегодня мы постараемся ответить на ряд, казалось бы, простых вопросов:
- Как найти в тексте «все смыслы»? В чем различия в восприятии текста между экспертом в предметной области (юристом) и неспециалистом (разработчиком)?
- Как эти различия влияют на разработку соответствующих IT-решений?
1. Legal AI: миф или реальность
В тексте нашей первой статьи мы определили основные задачи, которые необходимо решить на пути к созданию Legal Artificial Intelligence (далее по тексту — «Legal AI»). В качестве одной из ключевых и первостепенных задач мы выделили необходимость обучения машины смысловому понимаю документов на уровне, сравнимым с восприятием профессионального юриста, а равно — создание инструментов процессинга сложных юридических текстов на русском языке.
Мы детально исследовали на практике некоторые из доступных лингвистических инструментов обработки текста, но результаты и выводы, к которым мы пришли, получили неоднозначную оценку и вызвали дискуссию в профессиональном сообществе. Мы получили множество вопросов от специалистов, связанных с практической реализуемостью данных задач и перспектив применения технологий в этом направлении. Среди вопросов и комментариев, на наш взгляд, прослеживается некий пессимизм, отсутствие веры в технологии и их практическую применимость для решения поставленных задач, а также тезис о том, что Legal AI создать невозможно в силу различных причин и наличия трудных «нерешаемых» задач.

Мы не согласны с данной позицией. Текущего уровня развития технологий вполне достаточно, чтобы создать полноценный юридический искусственный интеллект, что и будет сделано в обозримом будущем. Фундаментальные теоретические разработки продвинулись достаточно далеко, чтобы можно было перейти к их практической реализации. Очевидно, что частные проблемы и трудности в данной сфере, тормозящие темпы развития таких продуктов, действительно, существуют. Но данные проблемы решаемы, однако пути решения требуют кропотливой и долгой пошаговой работы, которой многие опасаются.
Многие представители сферы LegalTech, сталкиваясь с трудностями и ограничениями технологий, отказываются от первоначальных концепций и создают довольно успешные пользовательские продукты с ограниченным функционалом. Например, известный сервис DoNotPay, чат-бот, позволяющий обрабатывать однотипные юридические запросы граждан по решению бытовых споров и конфликтов: оспаривать штрафы за неправильную парковку, готовить иски и претензии о компенсации за задержку авиарейсов и поездов, а также требования о страховых выплатах. Данный продукт, безусловно, является в некоторой степени прорывным, но он не решил главную задачу — создание полноценного «автоматизированного юриста», не привязанного к выборке типовых успешных кейсов. Этот недостаток ограничивает в том числе и перспективы развития сервиса. Руководствуясь количественным подходом, разработчики продукта расширяют набор типовых ситуаций, которые могут быть обработаны ботом, но все это упирается в обозначенное ограничение, а значит настанет момент, когда придется либо вернуться к нерешенным проблемам, либо остановить развитие продукта.
1.1. Что такое Legal AI?
Говоря о Legal AI, мы не занимаемся подменой понятий и не пытаемся поставить знак равно между искусственным интеллектом и машинными обучением / нейронными сетями. Для нас принципиально важной является именно автоматизация творческих задач, которые традиционно нельзя решить без участия человека-эксперта.
Поэтому инструменты Legal AI нацелены на замену человека, а не на оптимизацию решения отдельных задач в его деятельности. Глобальная функциональная задача и цель Legal AI — трансформация юридической функции и создание полноценного цифрового эксперта, который способен анализировать данные и генерировать выводы на основе юридической логики, заменив тем самым команду высокоспециализированных юристов. При успешной реализации данных задач общество получит инструмент, способный отвечать на сложные вопросы предметной области, например, «Кто может подписать договор?» или «Какая ответственность может наступить в случае превышения полномочий?».
Помимо этого, Legal AI является инструментом, выходящим за рамки привычного понимания классической юриспруденции, а перспективы его практического применения не ограничиваются анализом рисков и обработкой типичных юридических документов (договоров, исковых заявлений и др.). Любой письменный документ содержит в себе юридически значимые сущности, которые могут быть связаны с теми или иными правовыми последствиями для организации или третьих лиц. Например, с момента поступления и регистрации письма, содержащего обращение гражданина или организации в любой государственный орган, начинает течь срок, предусмотренный законом или иным нормативным актом для его рассмотрения.
Таким образом, область Legal AI охватывается весь документооборот в деятельности любой компании или государственного органа. Один из многочисленных примеров — закупочные процедуры по выбору поставщика товаров/услуг/работ. Каждая из стадий закупочной процедуры (публикация сведений и конкурсной документации, получение заявок, принятие решений, публикация итогов и взаимодействие с участниками конкурсного отбора) предполагает характерные для нее документы, действия и связи между субъектами, которые можно формализовать в виде конечного набора правил, требований и, как следствие, — можно автоматизировать с помощью Legal AI.
Мы считаем, что создание и практическое применение Legal AI в обозначенных областях возможно, но только при полном осознании глубины существующих проблем и правильном подходе к созданию продукта, основанном на необходимости тесного взаимодействия со специалистами предметной области и создания онтологий и графов знаний, воспроизводящих логику юриста-профессионала.
2. Новый подход к созданию продукта
2.1. Построение диалога между экспертами
Взаимодействие команды и правильный подход к созданию конечного продукта является важнейшей составляющей успеха. Мы неоднократно отмечали в качестве оптимального подхода для создания LegalTech-продуктов необходимость тесного взаимодействия:
- юристов, являющихся носителями глубоких экспертных знаний в предметной области;
- лингвистов, разрабатывающих методики и инструменты процессинга текста;
- разработчиков, осуществляющих практическое воплощение продукта.
Однако построение такого взаимодействия сопряжено с рядом сложностей, одной из которых является проблема в коммуникации между разработчиками и юристами, что в результате может привести к несогласованности командной работы и недостижению необходимого результата.
Юрист и разработчик говорят на разных языках и чаще всего не понимают друг друга, поскольку это классическое столкновение противоположных форматов мышления. Мышление разработчика основано на применении дискретной логики, которая проявляется в том числе в подходе, при котором все процессы могут быть алгоритмизированы тем или иным образом. Мышление юриста базируется на противоположных категориях, а именно — высокой степени абстракции, применении неалгоритмизируемых подходов при решении задач. Оба формата мышления заслуживают внимания и являются эффективными в своих областях знаний. Но при столкновении данных форматов в процессе создания LegalTech-решений возникают противоречия еще на первоначальных этапах реализации проекта. Традиционно любой подобный проект начинается с постановки цели, разработки концепции и подготовки ТЗ.
Если цель понимается разработчиком и юристом, как правило, одинаково, то уже при выработке концепции и методологии ее достижения зачастую начинаются существенные противоречия, не позволяющие перейти к написанию ТЗ.
Когда мы говорим о создании продуктов для юридической сферы на основе инновационных технологий, для преодоления таких противоречий необходимо находить баланс и выстраивать эффективную коммуникацию между представителями данных профессий. Для этого необходимо, чтобы и разработчики, и юристы не ограничивались собственными областями знаний, а стремились к пониманию особенностей деятельности друг друга и к поиску оптимальных решений существующих проблем для достижения общей цели. Юристы должны стремиться к пониманию логики разработчиков и принципов работы существующих технологий, а разработчики — к понимаю базовых категорий юриспруденции, ее основ и принципов. При этом, на наш взгляд, большее влияние на сегодняшний день должны оказывать именно юристы, являющиеся носителями экспертных знаний предметной области разрабатываемых продуктов.
Эффективная коммуникация и взаимопонимание будут способствовать осознанию глубины существующих проблем в области LegalTech, которые могут быть решены при помощи метода first principles.

Такой подход — один из лучших способов деконструкции сложных проблем и раскрытия нестандартных возможностей. Его смысл заключается в том, чтобы разбить сложные проблемы на базовые элементы и затем реконструировать их снизу вверх. Это один из лучших способов продвинуться от предсказуемых исходных данных к нелинейным результатам. Такой метод использовался философом Аристотелем, а теперь используется Илоном Маском и Чарльзом Мангером. Он позволяет преодолеть ложные убеждения и неэффективные аналогии, увидев возможности, которые все упускают. «В каждом систематическом изыскании (греч. Methodos), где существуют первые принципы, или причины, или элементы, знание и наука являются результатом познания этих принципов; мы считаем, что познали что-то, только узнав о первичных причинах, первичных первых принципах, вплоть до элементов», — писал Аристотель.
Данный метод отлично подходит и для решения задачи в сфере Legal AI, а именно — необходимо планомерно и пошагово реализовать продукт, продвигаясь от решения простых вопросов к сложным путем тесного взаимодействия между всеми участниками процесса разработки: юристами, разработчиками и лингвистами.
2.2. Структура знаний и восприятие данных
Еще одним аргументом в подтверждение нашего подхода служат различия в восприятии данных специалистом соответствующей предметной области знаний и тем, кто с особенностями данной сферы не знаком. Применительно к юриспруденции данные различия проявляются весьма наглядно.
Например, услышав термин «компания», не погруженный в юриспруденцию человек, вероятно, представит некоторую организацию, которая продает товар, выполняет работы или оказывает услуги.
Юрист, услышав данный термин, подсознательно выстроит для себя следующую картину:
- есть некоторое юридическое лицо, которое функционирует в определенной области, является коммерческим образованием корпоративного типа;
- такое юридическое лицо равно имеет акционеров (участников), органы управления (как минимум общее собрание и единоличный исполнительный орган), которые осуществляют собственные полномочия в соответствии с законодательством и уставом;
- помимо этого компания имеет фирменное наименование, юридический адрес, уставный капитал и др.
Данный список можно продолжать достаточно долго, но и приведенных примеров достаточно для понимания различий в глубине восприятия окружающего мира специалистами различных областей знаний. Применительно к сфере LegalTech, в которой в рамках общего проекта по созданию юридических программных продуктов взаимодействуют юристы и разработчики, различия в понимании предметной области проявляются не только в глубине восприятия, но и во взглядах на одну и ту же проблему. Юристы стремятся понять сложность задачи с точки зрения соответствующей области знаний, а разработчики стремятся понять, каким образом можно описать программный продукт, решающий данную задачу. Такие различия имеют в том числе научное обоснование.
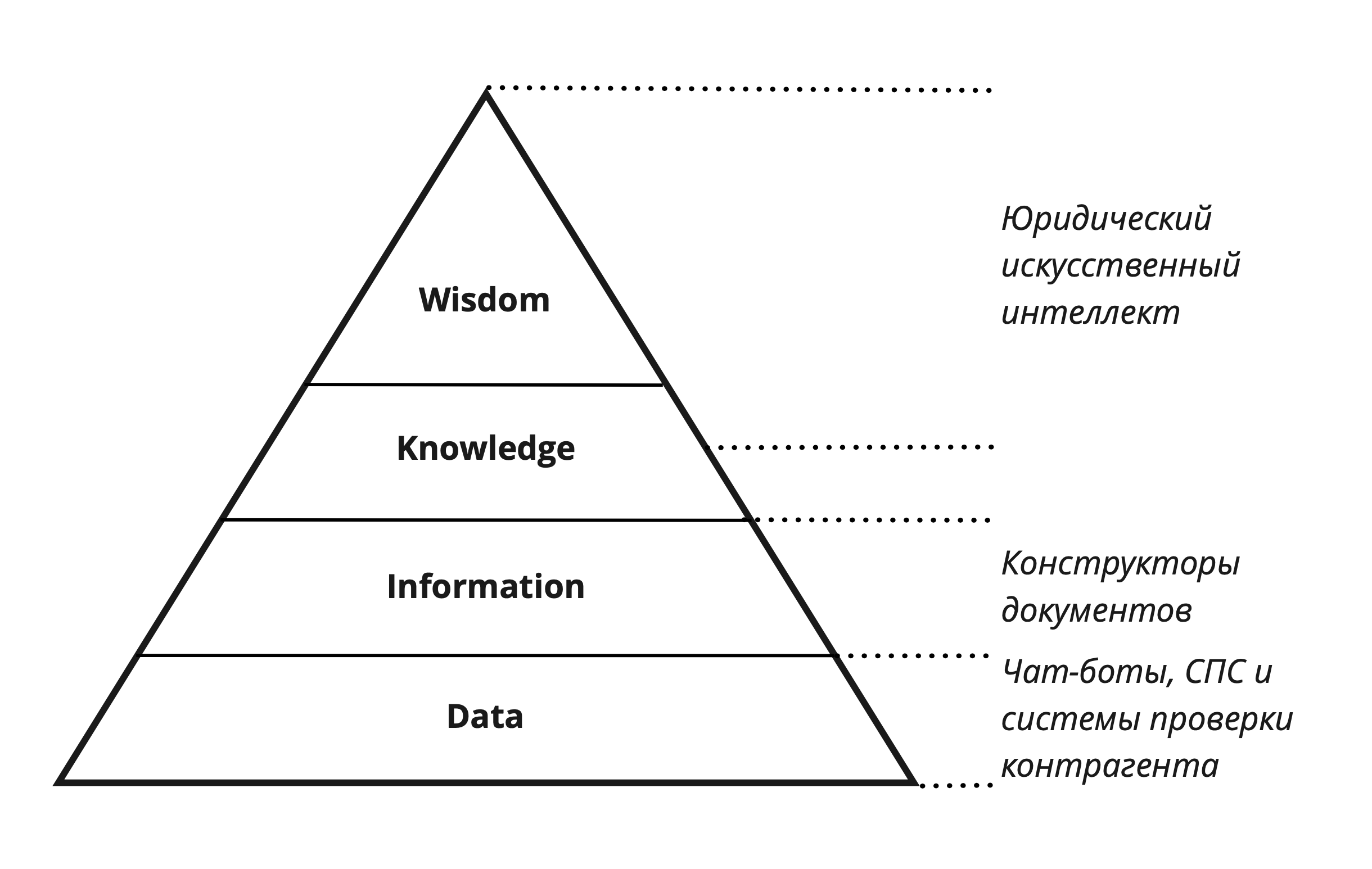
Традиционно в теориях системного анализа информации существующие данные разделяют на иерархию уровней, каждый из которых своими свойствами существенно отличается от предыдущего. Наиболее распространенной моделью является DIKW (англ. data, information, knowledge, wisdom — данные, информация, знания, мудрость), предложенная в 1989 г. Расселом Акоффом (так называемая пирамида Акоффа).

В рамках данной иерархии выделяются:
- data (неструктурированные, разрозненные данные);
- information (структурированные данные, информация);
- knowledge (знания);
- wisdom (мудрость).
Перемещение между данными уровнями представляет собой процесс накопления знаний — обрабатывая больший объем данных и информации, субъект получает знания и понимание в рамках соответствующей предметной области. Чем больше знаний, тем на более высокой ступени пирамиды находится субъект. Приведем простой пример перемещения между иерархией знаний внутри профессионального сообщества юристов:
- стажер и помощник юриста, как правило, работают с информацией на уровнях data и information, обеспечивая ее поиск и первичную обработку;
- юрист работает на уровне knowledge, обладая устойчивыми и системными знаниями предметной области, сформированным на основе длительной работы с информацией;
- старший юрист и выше работают на уровне wisdom, обладая накопленным опытом, мудростью и способностью видеть закономерности и взаимосвязи в мельчайших деталях.
Пирамида может быть представлена и в обратной последовательности — от мудрости к неструктурированным данным. Тогда становится очевидной иная закономерность — чем больше опыта и профессиональной мудрости у субъекта, тем меньше данных и информации ему необходимо для анализа ситуации и предоставления вывода. Например, при разработке стратегии защиты интересов клиента в ходе судебного разбирательства старший юрист, как правило, безошибочно определит процессуальную категорию спора и проработает вопросы, которые входят в предмет доказывания по данному делу с учетом процессуального законодательства и сложившейся практики рассмотрения судом аналогичных разбирательств, соберет необходимую доказательную базу, что в совокупности позволит эффективно достичь судебного решения в свою пользу. Менее опытный и квалифицированный специалист, вероятно, либо не выполнит необходимые мероприятия в полном объеме, либо выполнит лишние действия, не влияющие на решение судьи и конечный результат.
Другая не менее важная закономерность взаимосвязанных уровней заключается в том, что не специалист предметной области не сможет подняться выше уровня data (неструктурированные данные). Это вызвано в первую очередь тем, что для классификации данных и выделения из всего массива отдельной, значимой для дела информации требуются специальные познания. Мы уже отмечали ранее, что одна из значимых компетенций юриста — это умение видеть в письменных документах именно существенные юридические факты для поиска возможных решений.
Решить данную задачу лицу, далекому от юриспруденции, с высокой долей вероятности не удастся. Во многом именно в этом и заключается роль юриста. Данные тезисы в том числе ставят под сомнение практическую эффективность существующих на отечественном рынке платформ-агрегаторов общедоступной правовой информации (Спарк, Контр.Фокус и др.), которые позиционируются в качестве инновационных LegalTech-решений. Как мы видим, данные продукты по-прежнему работают только на уровне неструктурированных данных, предоставляя пользователю всю найденную информацию, прямо или косвенно связанную с запросом, и не осуществляют ее обработку под призмой юридических знаний, оставляя задачу интерпретации этих данных человеку.
Приведем в качестве примера историю, основанную на реальных событиях. В нашей практике состоялся диалог с одной уважаемой компанией-разработчиком, представители которой занимаются разработками в сфере LegalTech. В ходе беседы представители компании поделились с нами планами по автоматизации проверки полномочий подписанта сделки. Отметим, что мы также с удивлением для себя обнаружили, что в отделе, который занимается разработками LegalTech, нет юристов, они привлекаются «по необходимости». Логика представителей компании-разработчика была следующей:
- проверка полномочий не является сложной задачей, чтобы понять ее специфику достаточно однократно обсудить вопросы с юристом (составить алгоритм, список вопросов и др.);
- суть проверки полномочий руководителя компании сводится по большей части к верификации его ФИО с данными из ЕГРЮЛ.
Однако любой юрист с данной логикой не согласится. На основании записи в ЕГРЮЛ мы не можем с полной уверенностью говорить о безусловном праве лица действовать от имени компании во всех случаях. Проверка полномочий руководителя хоть и не является трудной задачей, но требует, как минимум, комплексной проверки юридической связи между организацией и ее руководителем, а именно:
- проверки факта избрания руководителя высшим органом управления, срока полномочий и действительности такого решения;
- проверка факта вступления в должность руководителя юридического лица на основании приказа, совпадение всех идентификационных данных (ФИО, паспортные данные и др.) в каждом из документов;
- проверка полномочий руководителя на совершение юридически значимых действий (заключение сделок, выдача доверенности и др.) от имени организации на предмет наличия ограничений в уставе (например, для крупных сделок, сделок с заинтересованностью) и др.
Можем ли мы на примере данного сравнения говорить о корректности предложенного алгоритма проверки полномочий руководителя — вопрос риторический. К сожалению, в IT-сообществе распространен подход, когда реализация продукта начинается без привлечения экспертов из предметной области, либо с их привлечением на этапах тестирования.
Этой традиции уже не один десяток лет, и примеры мы можем найти даже в прошлом столетии. Так, в 1986 г. был проведен эксперимент по разбору британского закона о гражданстве (The British Nationality Act) с применением логики языка Prolog. Суть эксперимента заключалась в попытке разложить текст данного закона на структурные единицы (смысловые триплеты), что и было в итоге сделано. Работы проводились без привлечения юристов, но в итоге эксперимент был признан успешным, несмотря на множественные недостатки и ограничения данной системы.
«Our representation of the British Nationality Act was undertaken with no legal expert assistance. Our model of the Act expresses the layman’s reading of the provisions. This in itself renders our British Nationality Act program of limited practical value. We could not use it in its present form for solving problems of British citizenship in actual legal practice».
Вместе с тем практической ценности для юриспруденции данный эксперимент не принес, что было признано самими разработчиками, поскольку без участия специалистов в области права невозможно воспроизвести смысловую структуру нормативного акта. Это во многом обусловлено особенностями юридического языка и терминологии, которая очень часто включает в себя неочевидные с позиции обыденного толкования значения.
В качестве примера можно привести следующий фрагмент из оригинальной статьи:
«A complication that we anticipated was the presence of vagueness. The act contains such vague phrases as “being a good character,” “having reasonable excuse,” and “having sufficient knowledge of English.”»
В данной ситуации авторы с позиции бытовой логики утверждают, что ряд терминов имеют размытое значение, основываясь, в первую очередь, на том, что нет какой-то одной статьи в законе, которая давала бы полную и точную дефиницию. Для практикующего юриста эта ситуация выглядит по-другому: рассматриваемые термины являются обширными, но не размытыми; по каждому из них накоплено несколько сотен лет судебной практики, где на многочисленных кейсах разбираются все возможные детали и нюансы.
В итоге эксперимент трансформации The British Nationality Act на язык Prolog был проведен ради самого процесса: была подтверждена возможность структурирования нормативных актов на языках формальной логики, но практическая значимость результата оказалась нулевой.
Таким образом, мы приходим к выводу, что при разработке решений в области LegalTech без ведущего участия профессиональных юристов обойтись невозможно. В противном случае нивелируется значимость и ценность таких решений для аудитории. Именно поэтому существующий сегодня фокус на работу с data (machine learning / deep learning) не позволяет продвинуться вперед и решать задачи, в которых требуется настоящая экспертиза на основе знаний и опыта конкретной предметной области.
В итоге мы пришли к выводу, что разработка Legal AI может быть выполнена только в результате создания независимого семантического блока, включающего в себя:
- структурированные модели юридических знаний (графы знаний и онтологии), воспроизводящие юридическую картину мира;
- набор методов и инструментов лингвистического анализа для процессинга текстов на естественном языке;
- элементы машинного обучения.
Данные инструменты в совокупности позволят создать качественно новые продукты в области LegalTech и перейти на следующие уровни работы в системе знаний (knowledge и wisdom).
2.2.1. Новый подход к формированию проектных команд
Разработка решений в области Legal AI требует применения нового подхода к формированию бюджета проекта. По нашей практике, что в структуре расходов основной статьей (70-80%) является стоимость работы профессионалов предметной области (высоко специализированных юристов), обладающих глубокими знаниями и опытом на уровнях knowledge и wisdom, а также способных строить юридические онтологии, воспроизводя собственное экспертное видение юриспруденции.
Остальные 20-30% расходов приходятся на оплату услуг разработчиков, обучение нейронных сетей, оборудование и др. Обобщая изложенное, можно отметить, что наиболее дорогостоящими задачами являются строительство графа знаний предметной области и подготовка обучающего дата-сета, поскольку они требуют участия высокоспециализированных представителей предметной области. Задачи по непосредственной разработке программного продукта менее затратны, однако с практической точки зрения разработка Legal AI не может быть осуществлена без решения обозначенных задач.
2.3. Неалгоритмизируемые процессы в LegalTech
Система знаний о какой-либо отдельно взятой предметной области может быть представлена в виде пирамиды из четырех уровней (data>information>knowledge>wisdom), которая отражает как статическую глубину профессиональных познаний конкретного субъекта, так и динамический процесс накопления знаний. Основой и базисом всех знаний служат неструктурированные данные (data), из числа которых может быть выделена существенная информация (information). По мере накопления информации и ее обработки субъект формирует устойчивые знания предметной области, которые в последующем под призмой накопленного опыта трансформируются в мудрость (wisdom) и позволяют эффективнее работать с данными и информацией (knowledge).
Для достижения устойчивых знаний и мудрости требуется обширный опыт и глубокие экспертные познания в соответствующей области, поэтому данные уровни остаются недостижимыми для людей, не являющихся экспертами конкретной сферы. Применительно к сфере LegalTech это объясняет невозможность самостоятельного понимания IT-специалистами всех особенностей и деталей юриспруденции, поскольку они не владеют системными знаниями права и опытом их практического применения.
В юриспруденции (как в любой системе научных знаний) многие элементы взаимосвязаны и имеют между собой причинно-следственную связь. Однако данная предметная область имеет и собственные особенности, благодаря которым такая связь может быть прямой (очевидной), косвенной (неочевидной) или отсутствовать вовсе. В связи с этим с точки зрения возможности алгоритмизации существует множество сложных областей и процессов, которые не поддаются программированию с помощью традиционных методов, применяемых в различных сферах. Подобные особенности существуют не только в юриспруденции.

Наиболее наглядным примером служат эксперименты инженеров по созданию системы автопилота для легковых автомобилей, которая будет пригодна для автоматизированного управления транспортным средством в городской среде без участия человека. Сегодня во всем мире в данном направлении достигнуты большие успехи, однако на первоначальных этапах разработчики столкнулись со следующей проблемой. Изначальным подходом по алгоритмизации порядка управления автомобилем служила идеальная модель вождения, сформированная на основе всех правил дорожного движения. В результате система управляла автомобилем только в строгом в соответствии с правилами. На этапах тестирования такая модель показала свои существенные недостатки, которые связаны с тем, что помимо правил дорожного движения существуют отдельные неформализованные правила и законы вождения, а также общепринятые алгоритмы поведения водителей в нестандартных ситуациях, оцифровать которые было невозможно.
Например, водитель, приближаясь к пешеходному переходу и видя стоящего у него человека, на основе системы невербальной коммуникации способен понять и с точностью предугадать дальнейшие действия пешехода, а именно — намерен ли он переходить улицу или просто стоит у перехода без желания продолжать движение. Система автопилота оказалась неспособна определять действия пешехода, стоящего возле нерегулируемого перехода, и, подчиняясь правилам дорожного движения, останавливалась и ждала пока пешеход не перейдет улицу. Если пешеход не намерен переходить улицу, автопилот не поедет дальше, пока человек не уйдет. Другой пример — сложный нерегулируемый перекресток. В стандартной ситуации водители пользуются жестами, с помощью которых могут разъехаться, не создавая заторы и аварийные ситуации. Для системы автопилота, действующей на основе правил дорожного движения, такие невербальные методы были недоступны. И, наконец, третий пример — слепая зона, расположенная после поворота, которая не видна водителю перед маневром. Человек при управлении автомобилем в таких ситуациях действует на основе интуиции и когнитивного восприятия, предугадывая риск наличия или отсутствия пешехода на дороге после поворота, но у системы автопилота интуиции нет, поэтому такая ситуация на практике несет в себе определенные риски.
Описанные примеры и существующие неформальные правила и законы вождения, включающие в себя невербальную коммуникацию водителей, интуитивные действия и др. служат примером неалгоритмизируемой области, которая вырабатывается на основе длительной практики по управлению транспортным средством и с точки зрения пирамиды знаний находится на верхних уровнях (knowledge и wisdom). Правила дорожного движения, в свою очередь, являются примером алгоритмизируемой области, которая располагается на нижних уровнях пирамиды (data и information). Аналогичные области существуют и в сфере юриспруденции, поэтому принятый у многих LegalTech-разработчиков подход, что все процессы в данной сфере могут быть алгоритмизированы традиционными методами, является заблуждением.
Кроме того, формат пирамиды и представления знаний позволяет наглядно определить место Legal AI в системе программных инструментов автоматизации юридической функции. Критерием разграничения инструментов выступает уровень в системе знаний, на котором функционирует тот или иной продукт, а именно:
- юридические чат-боты, справочно-правовые системы (Консультант Плюс, Гарант, Кодекс и др.) и системы проверки контрагента (Спарк, Контур.Фокус и др.) функционируют на уровне неструктурированных данных, обеспечивая поиск и аккумуляцию необходимых сведений;
- конструкторы правовых документов (Freshdoc, Easylaw, Doczilla и др.) функционируют на уровне информации, обеспечивая систематизацию необходимых данных, генерацию документов по шаблону;
- Legal AI, функционирующий на уровнях wisdom и knowledge, обеспечивает экспертную аналитику данных с точки зрения знаний предметной области.
2.4. Agile в LegalTech
Другой немаловажной проблемой является активная популяризация в IT-среде принципов и подходов Agile, которые в области LegalTech, по нашему мнению, создают очень большие сложности. Гибкая методология разработки (англ. Agile software development) — обобщающий термин для целого ряда подходов и практик, основанных на ценностях Манифеста гибкой разработки программного обеспечения и 12 принципах, лежащих в его основе, а именно:
- удовлетворение клиента за счёт ранней и бесперебойной поставки программного обеспечения;
- приветствие изменений требований даже в конце разработки (это может повысить конкурентоспособность полученного продукта);
- частая поставка рабочего программного обеспечения (каждый месяц или неделю, или ещё чаще);
- тесное и ежедневное общение заказчика с разработчиками на протяжении всего проекта;
- проектом занимаются мотивированные личности, которые обеспечены нужными условиями работы, поддержкой и доверием;
- рекомендуемый метод передачи информации — личный разговор (лицом к лицу);
- работающее программное обеспечение — лучший измеритель прогресса;
- спонсоры, разработчики и пользователи должны иметь возможность поддерживать постоянный темп на неопределённый срок;
- постоянное внимание улучшению технического мастерства и удобному дизайну;
- простота — искусство не делать лишней работы;
- лучшие технические требования, дизайн и архитектура получаются у самоорганизованной команды;
- постоянная адаптация к изменяющимся обстоятельствам: команда должна систематически анализировать возможные способы улучшения эффективности и соответственно корректировать стиль своей работы.
Применяется Agile как эффективная практика организации труда небольших групп (которые делают однородную творческую работу) в объединении с управлением ими комбинированным (либеральным и демократическим) методом.
Суть Agile заключается в том, что применяется итеративный подход при работе над проектом. Команда сконцентрирована на решении отдельных малых пользовательских кейсов в течение всего процесса, требования к конечному продукту формируются в динамике (по сути в процессе разработки). Такой подход в итоге приводит к тому, что на первых этапах создается не сильно функциональный продукт, к которому в последующей перспективе интегрируются новые возможности. Данный подход имеет определенные преимущества, но в то же время имеет и существенные недостатки. К числу преимуществ традиционно относят увеличение скорости реализации проекта при сокращении ресурсов. Критика Agile сводится к тому, что при нем часто пренебрегают созданием плана («дорожной карты») развития продукта, равно как и управлением требованиями, в процессе которого и формируется такая «карта».
Гибкий подход к управлению требованиями не подразумевает далеко идущих планов (по сути, управления требованиями в данной методологии просто не существует ), а подразумевает возможность заказчика вдруг и неожиданно в конце каждой итерации выставлять новые требования, часто противоречащие архитектуре уже созданного и поставляемого продукта. Такое иногда приводит к катастрофическим проблемам с массовым рефакторингом и переделками практически на каждой очередной итерации. Кроме того, считается, что работа в Agile мотивирует разработчиков решать все поступившие задачи простейшим и быстрейшим возможным способом, при этом зачастую не обращая внимания на правильность решения с точки зрения требований (подход — «работает, и ладно», при этом не учитывается, что может перестать работать при малейшем изменении или же дать тяжёлые к воспроизводству дефекты после реального внедрения). Это приводит к снижению качества продукта и накоплению дефектов. Принципы Agile применимы при создании продуктов, ориентированных на массовую аудиторию, которые не предполагают глубокое внедрение в какую-либо предметную область, например, различные развлекательные сервисы, социальные сети и др.

В случае с LegalTech эта шутка имеет большую долю истины. Как мы говорили ранее, успеха можно добиться только при неуклонном следовании first principles, когда еще до перехода к работе программистов мы от и до понимаем, какие задачи необходимо решить, как их решить, и какой результат должен быть в конце. Только при полном понимании всех деталей и требований к продукту мы можем перейти к его практической реализации. В противном случае велик риск упустить важные детали в алгоритме работы продукта, что в конечном итоге приводит к его невостребованности и неприменимости (пациент не проснется).
3. Графовые системы и онтологии
3.1. Концептуальное понимание картины мира
В юридической сфере помимо описанных факторов большую роль играет глубины понимания отдельных смыслов, концептов. Русский язык, особенно с учетом профессиональной лексики, таит в себе опасную иллюзию, которая заключается в следующем. Мы все говорим на одном языке, и кажется, что мы говорим об одном и том же, но на самом деле мы укладываем наши концепты в слова. В процессе сжатия концепта в слово происходит его критическая деградация, которая становится обратимой только внутри профессионального сообщества. Иными словами, два юриста с легкостью поймут друг друга, но юрист и разработчик — нет. Данные идеи подтверждаются теорией И.А. Мельчука «Смысл — текст».
Теория «Смысл ⇔ Текст» (ТСТ, или теория лингвистических моделей «Смысл ⇔ Текст», как её называют полностью) создана И.А. Мельчуком в середине 1960-х г. при активном участии ряда других лингвистов — прежде всего А.К. Жолковского, а также Ю.Д. Апресяна. По замыслу её создателей, ТСТ является универсальной концепцией, которая может быть применима к любому языку. На практике основным объектом для неё служил русский язык, а в 1980-е годы и в последующем теория разрабатывалась применительно к данным английского и французского языков. Теория «Смысл ⇔ Текст» представляет собой описание естественного языка, понимаемого как устройство («система правил»), обеспечивающее человеку переход от смысла к тексту («говорение», или построение текста) и от текста к смыслу («понимание», или интерпретация текста). При этом приоритет в исследовании языка отдаётся переходу от смысла к тексту: считается, что описание процесса интерпретации текста может быть получено на основе описания процесса построения текста. Теория постулирует многоуровневую модель языка, то есть такую, в которой построение текста на основе заданного смысла происходит не непосредственно, а с помощью серии переходов от одного уровня представления к другому. Помимо двух «крайних» уровней — фонологического (уровня текста) и семантического (уровня смысла), выделяются поверхностно-морфологический, глубинно-морфологический, поверхностно-синтаксический и глубинно-синтаксический уровни. Каждый уровень характеризуется набором собственных единиц и правил представления, а также набором правил перехода от данного уровня представления к соседним. На каждом уровне мы имеем дело с особыми представлениями текста — например, глубинно-морфологическим, поверхностно-синтаксическим и т.п.
Основной идеей данной теории является то, что одну и ту же мысль можно выразить с использованием различных синтаксических и лексических конструкций. Поэтому переводить текст в смысл в буквальном толковании невозможно, поскольку при выражении смысла устным и (или) письменным языком автор закладывает в него скрытые, понятные ему и лицам с аналогичными знаниями и мышлением смыслы. Применительно к юридическому языку это демонстрируется на примере, который мы приводили выше (о различном понимании термина «компания» юристом и лицом без соответствующих знаний). Данная теория в полной мере подтверждает вывод о том, что юрист и программист, обсуждая проекты в области LegalTech, говорят на разных языках и очень часто не понимают друг друга, что в итоге порождает конфликты и проблемы. Однако взаимодействие этих специалистов является ключом к успеху при создании Legal AI, поэтому важно стремиться к плодотворному и взаимному сотрудничеству.
3.2. Юридические концепты
По итогам рассмотрения предыдущих вопросов мы пришли к выводу о сложности юридической области знаний и различной глубине понимания окружающего мира юристами и специалистами иных предметных областей. Данная проблема находит свое практическое выражение даже в повседневной работе юриста.

Многие граждане и представители бизнеса нередко считают, что привлекать профессиональных юристов для сопровождения обычных и повседневных процедур, будь то оформление поставки партии товара или подписание очередного типового договора, не имеет смысла. К тому же с развитием LegalTech общественности становится доступно все больше различных электронных сервисов проверки контрагентов (Спарк, Контр.Фокус), онлайн-конструкторов договоров (Freshdoc, типовые формы в справочно-правовых системах «Консультант», «Гарант» и др.), позиционирующихся в качестве инновационных продуктов, способных заменить юриста в несложных, на первый взгляд, операциях (подробнее о существующем рынке LegalTech в России и сущности предлагаемых продуктов мы говорили в предыдущей статье). Однако это очень большое заблуждение, которое нередко приводит к фатальным последствиям.
Для иллюстрации рассмотрим, что представляет собой проверка полномочий руководителя в обыденном понимании и в понимании юриста.
Предположим, что нам необходимо подписать с контрагентом договор о поставке товара. Контрагентом выступает организация, от имени которой действует генеральный директор. В подавляющем большинстве случаев лица без юридических знаний сводят проверку полномочий к поиску контрагента в ЕГРЮЛ и верификации представителя компании со строкой «Лица, действующие от имени организации без доверенности». Если данные совпадают, значит договор можно подписывать. Однако это не всегда так. С точки зрения юриста процедура проверки полномочий включает в себя анализ множества неочевидных и непонятных для обычного человека категорий, имеющих значение не только для подтверждения факта наличия полномочий у лица заключить сделку в данный момент времени, но и для обеспечения исполнения данной сделки и предупреждения оспаривания договора и признания его недействительным в последующем, что способно повлечь неблагоприятные последствия для всех сторон правоотношений. При ответе на вопрос о наличии у лица (руководителя) полномочий подписать договор от имени организации юрист анализирует не только наличие статуса руководителя у лица на момент заключения сделки, но и проверку следующих факторов:
- право лица заключить сделку с конкретным объектом договора;
- наличие прав на соответствующий объект (право собственности на вещь, действительность права при заключении сделки с имущественными правами и др.);
- отсутствие признаков оспоримости сделки (непротиворечие сделки закону и иным нормативным актам, соответствие подписантов критериям полной дееспособности, вопросы аффилированности и взаимосвязанности, отсутствие признаков обмана, заблуждения, кабальности и др.).

Данный список может быть продолжен и далее, однако и приведенного выше достаточно для понимания, что проверка полномочий руководителя на заключение сделки существенно выходит за рамки поиска нужной фамилии в ЕГРЮЛ. Если ретранслировать данную ситуацию на тему Legal AI и автоматизацию проверки полномочий руководителя с помощью программных решений, мы сталкиваемся с необходимостью полного отражения данного концепта и фрагмента юридических знаний в данной области на языке формальной логики. И для начала нам необходимо понять сущность алгоритма проверки полномочий, а именно: сколько шагов и какие действия необходимо выполнить, какие концепты и данные задействованы и др. Только при условии решения данной задачи можно говорить о создании инструмента интеллектуальной проверки полномочий, которая по существу анализирует обстоятельства, не ограничиваясь обращением к ЕГРЮЛ. Если попытаться представить данный процесс в формате графа, он будет включать в себя сотни/тысячи нодов.
Другой пример — процесс подготовки проекта договора (например, договора поставки). Многие исходят из того, что для оформления большинства отношений, в том числе в предпринимательской сфере, не требуется участие юриста и достаточно использовать типовые шаблоны или конструкторы договоров, в которые необходимо внести недостающие сведения: фамилии, наименования, реквизиты, название объекта и др., и договор можно отправлять на подписание.

Однако с точки зрения юриста данный процесс должен выглядеть совершенно иначе. Руководствуясь методом first principles, юрист должен ответить на следующие вопросы:
- в какой юрисдикции заключается договор и какому праву он подчинен;
- кем являются стороны договора с точки зрения их правового статуса (граждане, предприниматели, организации или публично-правовые образования, вопросы специальной правоспособности и др.);
- кем являются подписанты договора (представители по доверенности, законные представители, «органические» представители в виде единоличного исполнительного органа и др.);
- как подтверждается право собственности продавца на товар (наличие соответствующих документов и др.) и так далее.

Кроме того, юрист стремится индивидуализировать текст договора под обстоятельства клиента, формулируя условия, исходя из интересов и рисков стороны. Именно поэтому один и тот же договор поставки может быть подготовлен и на 5, и на 60 страниц. Безусловно, многие юристы пренебрегают этим и сознательно в ряде случаев не следуют описанному алгоритму.
Поэтому распространенная и в целом приемлемая практика — это, когда многие важные этапы опускаются в целях оптимизации всего процесса (для простых и незначительных сделок, где риски минимальны и ими можно пренебречь). Другой случай — юристы ленятся и либо сознательно пропускают данные проверки, либо осуществляют их поверхностно и сугубо формально. ФНС России неоднократно разъясняла правила должной осмотрительности при выборе контрагента и критерии оценки его добросовестности. Однако далеко не многие юристы руководствуются данными рекомендациями при сопровождении сделок и проверке полномочий ее подписантов, что является неприемлемой, но, к сожалению, распространенной практикой.
Данные примеры наглядно иллюстрируют различное понимание стандартных в деловой практике процедур с точки зрения юридической логики и логики специалистов других областей знаний. Многие, сталкиваясь с необходимостью подготовить проект договора или проверить полномочия подписанта сделки, на подсознательном уровне полагают, что это предельно простые задачи, требующие не более 1-2 часов времени. Однако это далеко не так. Осознание глубины проблемы и отказ от подобных убеждений — первый шаг на пути к созданию Legal AI.
Третий пример, иллюстрирующий глубину и концептуальность понимания юристами внешних обстоятельств (событий и действий как разновидностей юридических фактов), — это вопросы юридической ответственности. Юридическая ответственность представляет собой меры государственного принуждения, применяемые к лицу за совершение противоправного деяния. Наиболее сложным видом ответственности является ответственность лиц, входящих в состав органов управления организации. В зону риска попадают контролирующие лица, которые в силу своего служебного положения (осуществление полномочий члена совета директоров, единоличного исполнительного органа) в ходе хозяйственной деятельности организации принимают решения и заключают сделки, которые имеют определенную степень предпринимательского риска. В силу данного факта такие лица должны действовать добросовестно и разумно, поскольку от их решений зависит будущее финансовое положение компании. За нарушение данных требований они могут быть привлечены как к имущественной ответственности за действия, которые повлекли за собой неплатежеспособность или убытки компании, так и к дисциплинарной (при исполнении обязанностей на основе трудового договора), административной и уголовной ответственности при наличии в их действиях составов административного правонарушения или преступления.
Приведем пример наступления неблагоприятных последствий при недобросовестных действиях контролирующих лиц. Генеральный директор регулярно заключал договоры поставки в пользу компании партий товаров, стоимость которых в 1,5 раза превышала рыночную стоимость аналогичных товаров у других поставщиков. Увеличенные расходы на закупку товаров генеральный директор объяснял бенефициарам компании высокой надежностью поставщика и наличием устойчивых и длительных партнерских отношений с ним, за счет чего условия поставки могли включать в себя и рассрочку оплаты, и доставку товаров на отдаленные производственные объекты и др. Однако фактически генерального директора и учредителя поставщика связывали личные приятельские отношения, благодаря которым поставщик получал необоснованную прибыль за счет превышения цены по сравнению с рыночной на протяжении нескольких лет. Полученная в результате сверхприбыль в последующем была выведена в форме дивидендов и неформально распределена поровну между генеральным директором покупателя и учредителем поставщика, а компания-покупатель на протяжении многих лет несла убытки в связи с переплатой за товар. Как только данные факты стали известны участникам компании-покупателя, генеральный директор был привлечен к дисциплинарной ответственности в виде увольнения на основании п. 9 ст. 81 ТК РФ (принятие необоснованного решения руководителем организации, повлекшего за собой нарушение сохранности имущества, неправомерное его использование или иной ущерб имуществу организации). Однако убытки компании в последующей перспективе повлекли за собой существенное ухудшение платежеспособности, что в результате привело к невозможности исполнения обязательств перед иными контрагентами и работниками предприятия. В результате было инициировано дело о банкротстве, в рамках которого действия бывшего генерального директора привлекли внимание конкурсного управляющего. В отношение генерального директора было возбуждено уголовное дело, по итогам расследования которого виновные лица были привлечены к уголовной ответственности за совершение преступлений, предусмотренных ст. 160 (присвоение вверенного виновному имущества) и ст. 204 (коммерческий подкуп) УК РФ. Помимо этого, в рамках уголовного дела к генеральному директору был предъявлен гражданский иск о возмещении убытков юридическому лицу в размере необоснованной переплаты по поставкам.
С точки зрения генерального директора данная схема выглядела соответствующей закону, поскольку в его понимании закупка товаров по завышенной цене у проверенного поставщика была платой за надежность контрагента, а получаемое скрытое вознаграждение — благодарностью поставщика за долгосрочное сотрудничество. Однако для юриста такие риски являются прогнозируемыми еще задолго до их реализации. Понимая и оценивая риски, юрист подходит к анализу каждого принимаемого решения, будь то заключение сделки или проверка контрагента, с точки зрения возможных неблагоприятных последствий в виде мер юридической ответственности, поскольку понимает механизмы реализации таких рисков и специфику коммерческих взаимоотношений. Закупка товара по завышенной цене сама по себе влечет множество вопросов и несет в себе значительное число рисков в виде ответственности для контролирующих лиц. То есть в юридической парадигме любое действие прямо или опосредованно влечет за собой определенные правовые последствия. Одно действие может стать основанием для привлечения к различным видам ответственности. Благодаря понимаю таких взаимосвязей и закономерностей профессиональный юрист оценивает ситуации и осуществляет собственную экспертизу.

Именно такое понимание функциональных задач мы вкладываем в Legal AI. Настоящим технологическим прорывом в области LegalTech станет создание инструмента, позволяющего оценивать юридические факты с точки зрения профессиональной логики, видеть взаимосвязи и закономерности, очевидные для юриста, но скрытые для обывателя. Это станет большим шагом в сторону автоматизации юридической функции, что при существующих продуктах на рынке LegalTech пока остается невозможным.
3.3. Онтологии и графы знаний
В процессе разработки программных решений для автоматизации юридической деятельности на основе искусственного интеллекта важным этапом, обеспечивающим возможность достижения успешного результата, является создание унифицированной базы знаний, отражающей особенности юридической картины мира.

Вопросы о необходимости структурирования и систематизации знаний в различных предметных областях не являются новыми. Еще в начале 2000-х годов в Европе начались разработки первых онтологий, а также были выработаны единые стандарты их построения. В России единый подход не выработан, поэтому развитие онтологических систем знаний происходит менее активно.
Онтология является унифицированной и структурированной базой знаний необходимой предметной области, представляющей собой объективное семантическое отражение картины мира в структурированном формате. Онтология включает в себя набор связанных между собой терминов, иерархически записанных в формате классов, подклассов различного уровня и связей (Relationships) между ними, что позволяет соотносить имеющиеся данные между собой с точки зрения экспертной логики. Среди способов систематизации знаний онтология является гораздо более продвинутой моделью, чем таксономия. Таксономией является любая структура знаний в виде иерархически соотносящихся сущностей. От онтологии ее отличает наличие связей между структурными единицами только 1 типа — родительский или дочерний элемент («subclass of»). Онтология, в отличие от таксономии, обладает большим количеством связей между всеми структурными единицами, представляя собой способ формализации знаний, абстрактных или специфических, реализованный на основе формального описания объектов, фактов и отношений между ними. Например, если в таксономии класс «Акционерное общество» может иметь только дочернюю связь с классом «Юридическое лицо» (акционерное общество является разновидностью юридического лица), то в онтологии «Акционерное общество» будет иметь сотни и тысячи связей, отражающих взаимосвязь акционерного общества с субъектами, объектами права и др. Данное ключевое отличие говорит о том, что таксономии не позволяют отвечать на юридические вопросы в силу отсутствия в их составе важных элементов в виде связей.
В формате онтологии крайне сложно выражать такие важные для юриспруденции конструкции как время (процессуальные сроки, сроки исполнения обязательств и др.) и модальность. В случае со временем мы вынуждены иметь дело с громоздкими конструкциями (например, как на изображении ниже), с которыми сложно работать на практике. В случаях с модальностью на языке OWL к настоящему времени не решена проблема выражения таких состояний, как отрицание, сомнение, различного рода субъективные факторы и оценочные категории.

Идеальной моделью представления знаний какой-либо предметной области является граф знаний. Граф структурно включает в себя графовые хранилища семантических метаданных и онтологий, которые в данном случае выступают в роли полуструктурированной модели предметной области, являясь ядром графа знаний. В результате такого способа обеспечивается возможность решения интеллектуальных задач с помощью постоянной циркуляции данных за счет применения методов машинного обучения. Говоря о соотношении графа знаний и онтологии, необходимо отметить, что онтология выступает в качестве способа формализации знаний в формате графа. Как верно отмечал Д. Муромцев, для графов знаний онтология — это семантическая основа представления данных, базирующаяся на логике и включающая терминологический словарь и набор утверждений о моделируемых объектах. В результате граф может иметь в себе в качестве семантической основы множество онтологий, обеспечивая комплексную концептуализацию всех знаний предметной области.
Онтологии и графы, создаваемые для Legal AI, должны иметь в совокупности сотни и тысячи классов и связей для решения даже простых юридических задач. При этом решающее значение имеет именно количество связей, отражающих отношения между классами. Для приблизительной оценки необходимого количества связей в нашей практике мы ориентируемся на полный граф (где каждая пара различных вершин смежна) и в результате получаем, что необходимое количество связей на порядок превышает количество необходимых классов:
Оптимальное количество связей ≈ n*(n-1)/2,
где n — количество задействованных классов, вершин.
Обращаясь к зарубежному опыту, нам удалось найти глубоко детализированные онтологии, применяемые в медицине (онтология геномов и др.), финансовой сфере и др. В области права существуют такие онтологии, как FOLaw, FBO, LKIF, Legal Rule ML и др. В России таких примеров найти не удалось, не говоря даже конкретно о юридических онтологиях. Исследование вопросов, связанных с онтологиями, обзор существующих зарубежных наработок в области юридических онтологий и их значение мы отдельно рассмотрим в следующей статье, но некоторые особенности, необходимые для понимания глубины проблемы, будут описаны далее.
Одним из наиболее впечатляющих примеров существующих онтологий является FIBO (Financial Industry Business Ontology), разрабатываемая в настоящее время международным сообществом под управлением консорциума OMG, который занимается объектно-ориентированными технологиями и стандартами. Стандарты FIBO применяются многими налоговыми органами различных государств в том числе в рамках автоматического обмена информацией (сведения о бенефициарах и др.).
Онтология FIBO имеет своей целью воспроизвести структуру отношений между участниками финансового рынка по поводу различных финансовых инструментов. Многими специалистами данной области FIBO рассматривается в качестве бизнес-онтологии, тем самым позиционируется ее широкая и универсальная сфера применения. Среди мнений встречаются также позиции о том, что бизнес-сфера включает в себя (поглощает) и сферу права, а также что унификация знаний в области финансов является основой для построения общих юридических концептов. Мы считаем, что обе позиции являются заблуждением, в подтверждение чего далее данная онтология FIBO будет рассмотрена более подробно.
В онтологии FIBO содержится семантически связанные понятия финансовой отрасли с описанием их смысла и практики использования специалистами. В частности, в FIBO описаны такие базовые понятия, как юридические лица, рыночные данные и финансовые процессы, структура и договорные обязательства, различные финансовых инструментов и др. Классы и подклассы онтологии FIBO представлены двумя способами: формальным описанием понятий и их взаимосвязей на языке OWL, а также их описанием на естественном языке с использованием толковых словарей финансовой отрасли. Предполагается, что онтология FIBO должна стать общим языком для финансовой индустрии, поддерживающим автоматизацию бизнес-процессов. Она предназначена для использования разработчиками, бизнес-аналитиками и другими участниками сферы финансов. Бизнес-термины и определения, описанные в FIBO, могут быть использованы в качестве эталонной модели, с которой финансовые организации могут связывать свои собственные (локальные) модели. Появляется возможность создавать логические модели данных, которые получают из FIBO свою формальную семантику.

В действительности FIBO является не одной онтологией, а набором большого количества онтологий, которые разделены по модулям и подмодулям. Модули (подмодули) включают наборы совместно используемых онтологий. Между собой онтологии FIBO связаны отношением «использует» – одна онтология может использовать, расширять и уточнять понятия, описанные в другой онтологии (или наборе онтологий). FIBO на очень глубоком уровне детализирует финансовые инструменты и термины, актуальные для финансовой отрасли. Но финансовая отрасль во многом пересекается с юриспруденцией: финансовые сделки являются разновидностями частно-правовых договоров (обязательств), а финансовые инструменты — объектами гражданского оборота (ценные бумаги и др.). Поэтому данная онтология содержит в том числе правовые категории, необходимые в той или иной мере для финансовой экспертизы, однако уровень их детализации является невысоким, что не позволяет применять FIBO для целей юриспруденции.

Для понимания различного уровня детализации сферы финансов и права приведем несколько фрагментов онтологии FIBO.

На данном фрагменте отражены документы, используемые в сфере финансов (порядка 57 категорий).

На данном — известные FIBO источники права (порядка 6 категорий).
Вследствие различия глубины проработки вопросов финансов и права онтология FIBO малоприменима для решения задач в сфере Legal AI. Кроме того, существуют и другие объективные причины, ограничивающие возможность применения онтологии FIBO для целей отечественного юридического искусственного интеллекта.
3.3.1. Успешный опыт построения индустриальных графов знаний
Ранее мы приводили в качестве примера успешной и глубоко детализированной онтологии разработку онтологии генов в рамках исследований в области молекулярной биологии. Для ее создания были вложены значительные финансовые ресурсы, и в результате научное сообщество получило функциональный инструмент для дальнейших исследований.
Данная онтология воспроизводит концепцию генома, включающую в себя как функциональное описание генов (функция и роль того или иного гена), так и их структурное описание (химический состав гена). Такая структурированная модель знаний позволяет, во-первых, интегрировать знания из различных баз данных в едином формате, во-вторых, генерировать выводы о функциональности вновь открытых генов и получать представление о сохранении и дивергенции биологических подсистем. Онтология генов имеет свойство универсальности. Существующие в молекулярной биологии элементы одинаковы и равным образом признаются учеными вне зависимости от территории, страны и др. Отличается лишь их индивидуальный набор у каждого представителя того или иного вида организмов. Данные особенности предметной области позволяют практически применять подобную базу знаний во всем мире.
В области юриспруденции создать общеприменимую модель знаний невозможно.
Первая причина — фундаментальное различие правовых систем. В теории права принято выделять 5 правовых систем: континентальную (например, Германия, Франция, Россия и др.), англо-американскую (США, Великобритания, Канада, Австралия), социалистическую (Китай, КНДР, Куба и др.), а также религиозную (основана на имплементации в право религиозных канонов и их законодательное развитие) и традиционную (основана на обычаях и общинных правилах поведения). Каждая из правовых систем имеет фундаментальные отличия в принципах построения права и законодательном регулировании общественных отношений. Крупнейшими в мире по числу представителей являются континентальная (романо-германская система) и англо-американская (система общего права) правовые семьи.

Однако даже внутри одной правовой системы существуют множественные ветви, характеризующиеся наличием индивидуальных особенностей, поскольку право в каждом государстве формируется под воздействием множества факторов (экономических, исторических, социальных, географических и др.). Например, Россия и Германия относятся к одной правовой семье, однако их законодательство разительно отличается, хотя и существуют отдельные схожие институты.
Так, в гражданском праве и России, и ФРГ в качестве отдельного вида договора о передаче имущества в собственность является договор купли-продажи недвижимости как соглашение продавца и покупателя, по которому продавец обязуется передать в собственность покупателя недвижимую вещь, а покупатель — принять и оплатить ее стоимость. Однако есть существенное отличие в понимании сущности данных отношений и в правовых последствиях их реализации. В России договор купли-продажи недвижимости является обязательственной сделкой, которая создает взаимные обязательства между двумя сторонами. Право собственности на недвижимость переходит к покупателю после государственной регистрации такого перехода. Если договор купли-продажи признается недействительным, то в качестве последствий применяется двусторонняя реституция (взаимный возврат всего полученного каждой из сторон). В ФРГ договор купли-продажи включает в себя две сделки: обязательственную и вещную. По обязательственной сделке создаются взаимные обязательства, а по вещной — переходит право собственности на вещь. В результате право собственности переходит к покупателю с момента заключения вещной (распорядительной) сделки. При этом в силу принципа абстракции если обязательственная сделка признается недействительной, то это не влияет на действительность сделки вещной, и право собственности за покупателем сохраняется.
Вторая причина — фундаментальные различия в языках. Всего в мире насчитывается более 7 тыс. языков, из которых только 40 являются самыми распространенными для 2/3 населения Земли. Безусловно, английский язык является наиболее распространенным в том числе как государственный язык, на котором составляются источники права в различных странах. Практически любой текст можно перевести с одного языка на другой. Однако не любой текст в результате такого перевода сохранит 100% своего смыслового содержания и будет тождественным. Данная особенность крайне актуальна и для юридических текстов, которые имеют собственную специфику в виде терминологии, уникальных значений и др.
Приведенные причины позволяют прийти к выводу о невозможности создания общеприменимой структурированной базы знаний в области права и необходимости ее самостоятельной разработки в отдельной стране с учетом ее государственного языка и права. Право государств отличается настолько фундаментально (даже внутри одной правовой семьи), что применение зарубежных разработок для решения задач LegalTech в России становится невозможным. Равным образом невозможно использование существующей онтологии FIBO, поскольку она создана на английском языке представителями англо-американской правовой семьи. Это требует выработки самостоятельного подхода и создания уникальной онтологии, воспроизводящей право РФ.
3.3.2. Количество классов и связей в практических онтологиях
Онтология представляет собой структурированную модель представления системы знаний какой-либо предметной области на основе описания объектов (классов), их свойств и взаимосвязей с другими объектами. Построение такой модели позволяет систематизировать знания в едином формате и использовать их в том числе для генерации выводов. Однако функциональное назначение онтологий существенно шире.
В мировой практике существует множество примеров онтологий, которые создаются для различных целей (например, упомянутые нами FIBO в финансовой области, онтология геномов в молекулярной биологии и др.). Существующие на текущий момент онтологии преимущественно создаются и применяются для обмена данными между различными субъектами, используя такую модель представления данных в качестве мета-языка, упрощающего и ускоряющего взаимообмен информацией. Однако для обеспечения такого функционала онтологии создаются с упором на универсальность и возможность многократного применения (свойство «reusable»). Это влечет за собой необходимость построения онтологий с высокой степенью абстракции, которая проявляется в максимальном обобщении и сокращении количества классов. В результате такие онтологии обеспечивают возможность обмена данными, но становятся непригодными для использования в качестве базы знаний в виду неглубокой детализации.
Другая проблема в сфере существующих онтологий заключается в том, что во многом представленные экземпляры являются не онтологиями, а таксономиями. Многим покажется, что создание юридической онтологии превратится в длительную и трудоемкую задачу, выполнить которую вручную не представляется возможным. Сторонники такого подхода предлагают воспользоваться альтернативным методом — автогенерацией онтологий. Автогенерация онтологий представляет собой процесс автоматического формирования онтологии предметной области на основе обучающей выборки документов. Этот процесс состоит из нескольких этапов, на каждом из которых происходит извлечение из текста фактов или их пост-обработка для формирования какой-то части онтологии, будь то термины или объекты, концепты или же отношения между ними. Однако данный метод для юридической онтологии не применим. Основными его недостатками являются крайне скудный набор извлекаемых связей (is-a, subclass of), которых для полноценного описания юридической картины мира в формате структурированной базы знаний явно недостаточно.
Другой проблемой является отсутствие достаточной обучающей выборки документов. В результате мы получаем разрозненные и бессистемные классы, объединенные связями одного порядка, что на практике не позволит решить поставленные задачи.
В качестве примера можно привести фрагмент из разработанной нами онтологии:
- данный фрагмент описывает процедуры подачи и принятия искового заявления к производству, описанные в статьях 125-129 Арбитражного процессуального кодекса РФ, всего ~4 страницы текста;
- функциональное предназначение — подготовка ответов на 2 вопроса: «Соответствует ли поданное исковое заявление установленным требованиям?» и «К какой категории спора относится данное исковое заявление?»;
- суммарно этот фрагмент онтологии содержит ~645 классов (без учета связей), меньшее количество классов не позволяет отвечать на поставленные вопросы.
При создании онтологий для целей Legal AI мы исходим из необходимости включения такого количества классов, которого будет достаточно для отражения системы юридических знаний в полной мере. При таком подходе свойство «reusable» применительно к онтологии не имеет значения, поскольку она направлена на решение иных задач. Необходимое количество классов зависит от глубины детализации вопросов, ответы на которые могут быть получены с помощью онтологии, а также от уровня представления знаний.
Другой пример, иллюстрирующий необходимость наличия большого количества связей и классов, — due diligence.

Due diligence — процедура составления объективного представления об объекте и субъектах правоотношений, включающая в себя оценку правовых и финансовых рисков, независимую оценку объекта (вещи, имущественные права и др.), всестороннее исследование деятельности компании, комплексную проверку её финансового состояния и положения на рынке.
Такая услуга оказывается опытными юристами-консультантами перед покупкой бизнеса, осуществлением сделок слияния и поглощения (M&A), подписанием сложных контрактов, соглашений о сотрудничестве и включает в себя полномасштабное и всестороннее исследование компании.
Обращаясь к рассмотренной ранее модели представления знаний в форме пирамиды, необходимое количество классов онтологии может быть выражено следующим образом:
- для ответа на вопрос: «Кто является директором компании?» — требуется в среднем до 30 классов (уровень data);
- для ответа на вопрос: «Какие полномочия есть у директора согласно уставу?» — требуется в среднем до 100-150 классов (уровень information);
- для ответа на вопрос: «Имеются ли у директора полномочия на подписание конкретной сделки?» — требуются в среднем сотни — тысячи классов (уровень knowledge);
- для проведения полномасштабного due diligence требуются десятки тысяч классов (уровень wisdom).
Такое количество необходимых классов для проведения due diligence обусловлено сложностью процедуры. Например, для классической услуги по проведению due diligence в отношение компании перед ее приобретением юристу необходимо:
- определить схему владения и систему управления компанией;
- проанализировать хозяйственную деятельность организации и оценить ее эффективность с точки зрения прибыли и наличия или отсутствия признаков банкротства;
- проанализировать структуру активов компании и права на них (недвижимое имущество, движимое имущество, объекты интеллектуальной собственности, иные имущественные права);
- оценить соответствие деятельности компании трудовому, антимонопольному, налоговому, административному законодательству;
- проанализировать судебные разбирательства, в которых компания принимала участие или участвует в настоящий момент и др.
Это лишь часть направлений, которые необходимо проанализировать юристу при выявлении рисков и подготовке заключения.
В зависимости от сложности и глубины практических вопросов, ответы на которые должны быть получены с помощью онтологии, зависит необходимая глубина ее детализации. Чем выше сложность вопросов, тем больше требуется классов для ответа на них. При этом необходимо учитывать, что рост количества связей между классами экспоненциален росту количества классов онтологии.
Для сравнения в настоящий момент онтология FIBO, охватывающая только область финансовых взаимоотношений, включает в себя 3099 классов.
4. Заключительные положения
Изложенные в настоящей статье рассуждения и выводы относительно возможности практической реализации и методологии разработки решений Legal AI были выработаны нами в течение нескольких лет исследований и практической деятельности. Не остается сомнений в том, что развитие искусственного интеллекта в настоящий момент является одним из приоритетных направлений деятельности мировых технологических лидеров в том числе на государственном уровне.
6 июля 2020 года Президент РФ утвердил Поручение Правительству РФ с учетом ранее данных поручений принять исчерпывающие меры по утверждению отдельного федерального проекта «Искусственный интеллект», обеспечив необходимое финансирование, в том числе из предусмотренных на реализацию национальной программы «Цифровая экономика Российской Федерации» средств федерального бюджета. Данный факт свидетельствует о выделении технологий искусственного интеллекта в самостоятельную ветвь национального проекта.
Мы, являясь компанией, которая занимается развитием технологий искусственного интеллекта в области юриспруденции, считаем, что такое решение является стратегически правильным. В долгосрочной перспективе оно будет способствовать комплексному развитию всего направления в том числе при помощи государственной поддержки различных проектов, а не только отдельных субтехнологий. Поскольку изучению вопросов развития Legal AI мы уделяем большое количество времени, у нас сформировано представление о том, какие меры будут способствовать наиболее эффективному и быстрому развитию рынка технологий искусственного интеллекта.
Важно отметить, что в общественном сознании устойчиво мнение о том, что отечественные достижения в области цифровых технологий и, в частности, в сфере искусственного интеллекта, отстают от результатов зарубежных стран (США, Китая и др.).
Однако это не так, и существующий разрыв может быть сокращен в краткосрочной перспективе. На российском рынке сложилась уникальная ситуация, при которой созданы все необходимые условия для появления в самом ближайшем будущем прорывных отечественных решений.
Во-первых, в России существует прочная научная и практическая основа в области искусственного интеллекта. При этом многие материалы и публикации по теме находятся в открытом доступе, а в профессиональном сообществе активно осуществляется обмен опытом, достижениями и концептами. Это позволяет наглядно видеть существующие тренды (в том числе зарубежные) в области искусственного интеллекта, понимать вектор развития и оценивать практические достижения в данной сфере.
Во-вторых, в последние годы активно развивается рынок труда и появляются специалисты в области искусственного интеллекта, машинного обучения и нейронных сетей, что позволяет создавать сильные и профессиональные команды разработчиков. Кроме того, благодаря процессам глобализации существует возможность привлекать в команды зарубежных специалистов, обладающих богатым практическим опытом и необходимыми теоретическими знаниями.
В-третьих, весомым преимуществом для отечественного рынка программных решений на основе технологий искусственного интеллекта является уникальность русского языка. Это не позволяет зарубежным IT-компаниям, являющимся лидерами в области цифровых технологий, создавать решения для отечественного рынка и конкурировать с российскими разработчиками, уступающим им по масштабам и финансовым возможностям. В совокупности данные факторы создают все условия для самостоятельного развития технологий искусственного интеллекта в России силами отечественных разработчиков, которые при правильном подходе имеют все шансы на успех.

P.S.
Дополнительные материалы:
- Искусственный интеллект в области юриспруденции — Статья 1;
- Д. Муромцев, А. Романов, Д. Волчек. Индустриальные графы знаний — интеллектуальное ядро цифровой экономики (2019);
- Dessimoz С., Škunca N. (2017) The Gene Ontology Handbook. Methods in Molecular Biology (ISBN 978-1-4939-3741-7);
- Перечень поручений Президента РФ по итогам совещания по вопросу развития информационно-коммуникационных технологий и связи;
- Интервью с основателем сomma.ai о проблемах создания беспилотных авто.
ссылка на оригинал статьи https://habr.com/ru/post/511004/
Добавить комментарий