Продолжаю серию рассказов о OpenSource разработке In2sql, которая визуализирует объекты SQL для выгрузки данных в Excel. ( по сути это серия статей — документация к разработке )
В предыдущих частях
В предыдущих частях
В данной части поговорим о том, как создается список объектов, которые выводятся в навигационное дерево.
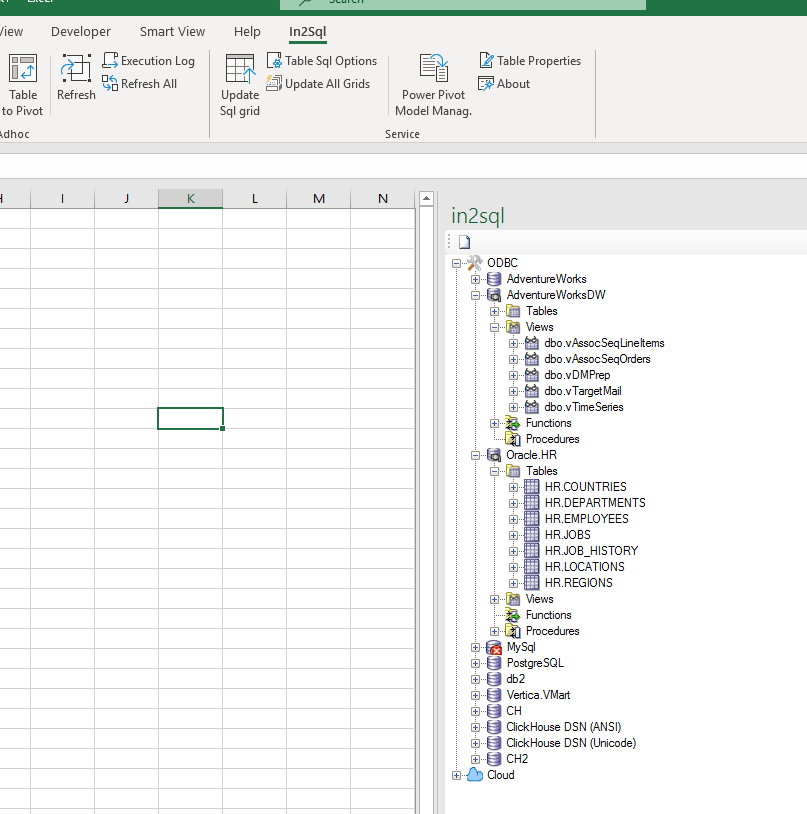
Стандартно, выделяем 4 типа основных объектов
- Таблицы
- Представления
- Функции
- Процедуры.
Так же каждая БД имеет свои объекты для хранения сущностей — например
- MS SQL — хранит данные в sys.schemas, где они разделены по типам (type = ‘V’ — View,type = ‘U’ — таблицы)
- Oracle — здесь все достаточно просто — есть объекты user_views и user_tables, которые хранят описание соответствующих настроек пользователя
- Vertica — v_catalog.views и v_catalog.tables
- PostegreSQL — pg_catalog.pg_views и pg_catalog.pg_tables
- MySQL — information_schema.views и information_schema.tables
- DB2 — все данные хранятся в SYSIBM.tables, где table_type = ‘VIEW’ — это представления, а table_type = ‘BASE TABLE’ — это таблицы.
- ClickHouse все объекты лежат в system.tables, разделение на таблицы и view происходит по полю engine = ‘View’
Этим многообразием управляет класс in2SqlLibrary, в котором происходит
- определение типа ODBC подключения, на основании имени файла драйвера (getDBType)
- раздача таблиц (getSqlTables) и представлений (getSqlViews) по соответсвующим типам.
Для того что бы ускорить загрузку excel плагина (addin ) к этим данным происходит обращение в момент раскрытия ветки соответствующего артефакта. (об этом расскажу в другой статье)
ссылка на оригинал статьи https://habr.com/ru/post/511166/
Добавить комментарий