
В этой статье будет рассказан опыт создания нейросети по распознаванию лиц, для сортировки всех фотографий из беседы ВК на поиск определённого человека. Без какого-либо опыта написания нейросетей и минимальными знаниями Python.
Введение
Есть у нас друг, которого зовут Сергей, который очень любит себя фотографировать в необычном образе и отправлять в беседу, а так же приправляет эти фотографии фирменными фразами. Так вот в один из вечеров в дискорде у нас появилась мысль — создать паблик в вк, куда мы могли бы постить Сергея с его цитатами. Первые 10 постов в отложку дались легко, но потом стало понятно, что перебирать руками все вложения в беседе — нет смысла. Так и было принято решение написать нейросеть для автоматизации этого процесса.
План
- Получить ссылки на фотографии из беседы
- Скачать фотографии
- Написание нейросети
1. Получение ссылок на фотографии
Так мы хотим получить все фотографии с беседы нам подходит метод messages.getHistoryAttachments, который возвращает материалы диалога или беседы.
С 15 февраля 2019 Вконтакте запретил доступ к messages, для приложений не прошедших модерацию. Из вариантов обхода могу предложить vkhost, который поможет получить токен от сторонних мессенджеров
С полученным токеном на vkhost можем, собирать нужный нам запрос к API, при помощи Postman. Можно конечно и без него всё заполнить ручками, но для наглядности будем использовать его
Заполняем параметры:
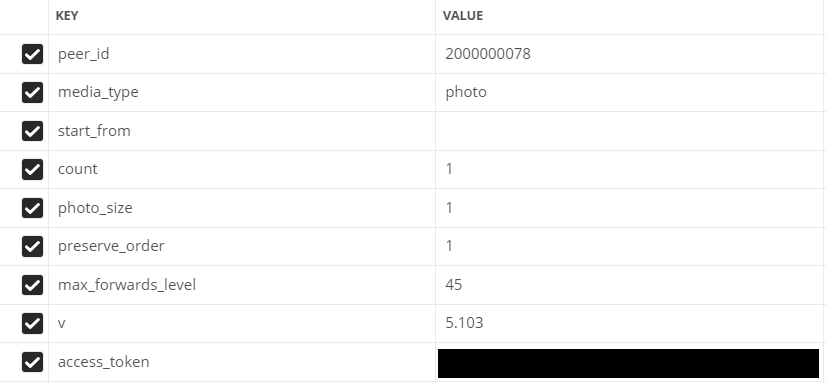
- peer_id — идентификатор назначения
Для беседы: 2000000000 + id беседы (можно увидеть в адресной строке).
Для пользователя: id пользователя. - media_type — тип материалов
В нашем случае photo
- start_from — смещение, для выборки нескольких элементов.
Пока что оставим пустым
- count — количество получаемых объектов
Максимум 200, столько и будем использовать
- photo_sizes — флаг для возвращение всех размеров в массиве
1 или 0. Мы используем 1
- preserve_order — флаг указывающий нужно ли возвращать вложения в оригинальном порядке
1 или 0. Мы используем 1
- v — версия vk api
1 или 0. Мы используем 1
Заполненные поля в Postman
Переходим к написанию кода
Для удобства весь код будет разбит на несколько раздельных скриптов
Будет использовать модуль json (для декодирования данных) и библиотеку requests (чтобы делать http запросы)
Листинг кода если в беседе/диалоге менее 200 фотографий
import json import requests val = 1 # Переменная для счётчика Fin = open("input.txt","a") # Создаём файл для записи ссылок # Отправляем GET запрос на API и записываем ответ в response response = requests.get("https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from=&count=10&photo_size=1&preserve_order=1&max_forwards_level=45&v=5.103&access_token=ВАШ_ТОКЕН") items = json.loads(response.text) # Считываем ответ от сервера в формате JSON # Так как по GET запросу сервер возвращает в каждом элементе массив с картинкой в разных размерах, будем перебирать всё циклом for item in items['response']['items']: # Перебираем массив items link = item['attachment']['photo']['sizes'][-1]['url'] # Записываем самый последний элемент, так как он самого максимального расширения print(val,':',link) # В консоли выводим лог по проделанной работе Fin.write(str(link)+"\n") # Записываем новую строку в файл val += 1 # Увеличиваем значение счётчика Если же фотографий более 200
import json import requests next = None # Переменная в которую будем записывать ключ смещения def newfunc(): val = 1 # Переменная для счётчика global next Fin = open("input.txt","a") # Создаём файл для записи ссылок # Отправляем GET запрос на API и записываем ответ в response response = requests.get(f"https://api.vk.com/method/messages.getHistoryAttachments?peer_id=2000000078&media_type=photo&start_from={next}&count=200&photo_size=1&preserve_order=1&max_forwards_level=44&v=5.103&access_token=ВАШ_ТОКЕН") items = json.loads(response.text) # Считываем ответ от сервера в формате JSON if items['response']['items'] != []: # Проверка наличия данных в массиве for item in items['response']['items']: # Перебираем массив items link = item['attachment']['photo']['sizes'][-1]['url'] # Записываем самый последний элемент, так как он самого максимального расширения print(val,':',link) # Лог перебора фотографий val += 1 # Увеличиваем значение счётчика Fin.write(str(link)+"\n") # Записываем новую строку в файл next = items['response']['next_from'] # Записываем ключ для получения следующих фотографий print('dd',items['response']['next_from']) newfunc() # Вызываем функцию else: # В случае отсутствия данных print("Получили все фото") newfunc()Ссылки получили пора качать
2. Скачивание изображений
Для скачивания фотографий используем библиотеку urllib
import urllib.request f = open('input.txt') # Наш файл с ссылками val = 1 # Переменная для счётчика for line in f: # Перебираем файл построчно line = line.rstrip('\n') # Скачиваем изображение в папку "img" urllib.request.urlretrieve(line, f"img/{val}.jpg") print(val,':','скачан') # В логи выводим сообщение о загрузке val += 1 # Увеличиваем счётчик print("Готово") Процесс загрузки всех изображений не самый быстрый, тем более если фотографий 8330. Место под это дело тоже требуется, если фотографий по количеству как у меня и более, рекомендую освободить под это 1,5 — 2 Гб

Черновая работа закончена, теперь можно приступать к самому интересному — написанию нейросети
3. Написание нейросети
Просмотрев много различных библиотек и вариантов, было решено использовать библиотеку
Face Recognition
Что умеет ?
Из документации рассмотрим самые основные возможности
Поиск лиц на фотографиях
Может найти любое количество лиц на фото, даже справляется с размытыми

Идентификация лиц на фотографии
Может распознать кому принадлежит лицо на фотографии

Для нас самый подходящим способом будет являться идентификация лиц
Подготовка
Из требований к библиотеке необходим Python 3.3+ или Python 2.7
По поводу библиотек — будет использоваться выше упомянутая Face Recognition и PIL для работы с изображениями.
Официально библиотека Face Recognition не поддерживается на Windows, но у меня всё заработало. С macOS и Linux всё работает стабильно.
Объяснение происходящего
Для начала нам необходимо задать классификатор для поиска человека, по которому уже будет происходить дальнейшая сверка фотографий.
Рекомендую выбрать максимально чёткую фотографию человека в анфас
При загрузке фотографии библиотека разбивает изображения на координаты черт лица человека (нос, глаза, рот и подбородок)

Ну, а дальше дело за малым, остаётся только применять подобный метод к фотографии на которую хотим сравнить с нашим классификатором. После чего даём нейросети сравнить черты лиц по координатам.
Ну и собственно сам код:
import face_recognition from PIL import Image # Библиотека для работы с изображениями find_face = face_recognition.load_image_file("face/sergey.jpg") # Загружаем изображение нужного человека face_encoding = face_recognition.face_encodings(find_face)[0] # Кодируем уникальные черты лица, для того чтобы сравнивать с другими i = 0 # Счётчик общего выполнения done = 0 # Счётчик совпадений numFiles = 8330 # Тут указываем кол-во фото while i != numFiles: i += 1 # Увеличиваем счётчик общего выполнения unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") # Загружаем скачанное изображение unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Кодируем уникальные черты лица pil_image = Image.fromarray(unknown_picture) # Записываем изображение в переменную # Проверяем нашла ли нейросеть лицо if len(unknown_face_encoding) > 0: # Если нашли лицо encoding = unknown_face_encoding[0] # Обращаемся к 0 элементу, чтобы сравнить results = face_recognition.compare_faces([face_encoding], encoding) # Сравниваем лица if results[0] == True: # Если нашли сходство done += 1 # Увеличиваем счётчик общего выполнения print(i,"-","Нашли нужного человека !") pil_image.save(f"done/{int(done)}.jpg") # Сохраняем фото с найденным человеком else: # Если не нашли сходство print(i,"-","Не нашли нужного человека!") else: # Если не нашли лицо print(i,"-","Лицо не найдено!") Также есть возможность прогонять всё по глубинному анализу на видеокарте, для этого надо добавить параметр model= «cnn» и изменить фрагмент кода для изображения с котором хотим искать нужного человека:
unknown_picture = face_recognition.load_image_file(f"img/{i}.jpg") # Загружаем скачанное изображение face_locations = face_recognition.face_locations(unknown_picture, model= "cnn") # Подключаем ускорение GPU unknown_face_encoding = face_recognition.face_encodings(unknown_picture) # Кодируем уникальные черты лица
Результат
Без GPU. По времени нейросеть перебрала и отсортировала 8330 фотографий за 1 час 40 минут и при этом нашла 142 фотографии из них 62 с изображением нужного человека. Конечно бывали ложные срабатывания, на мемы и других людей.
C GPU. Времени на обработку заняло гораздо больше, 17 часов и 22 минуты и нашла 230 фотографий из которых 99 нужный нам человек.
В заключение можно сказать, что работа проделана была не зря. Мы автоматизировали процесс сортировки 8330 фотографий, что гораздо лучше чем перебирать это самому
Также можете скачать весь исходный код с github
ссылка на оригинал статьи https://habr.com/ru/post/512002/
Добавить комментарий