Привет, Хабр! В этой статье я покажу как сделать частотный анализ современного русского интернет-языка и воспользуюсь им для расшифровки текста. Кому интересно, добро пожаловать под кат!

Частотный анализ русского интернет-языка
В качестве источника, откуда можно взять много текста с современным интернет-языком, была взята социальная сеть Вконтакте, а если быть точнее, то это комментарии к публикациям в различных сообществах данной сети. В качестве сообщества я выбрал реальный футбол. Для парсинга комментариев я воспользовался API Вконтакте:
def get_all_post_id(): sleep(1) offset = 0 arr_posts_id = [] while True: sleep(1) r = requests.get('https://api.vk.com/method/wall.get', params={'owner_id': group_id, 'count': 100, 'offset': offset, 'access_token': token, 'v': version}) for i in range(100): post_id = r.json()['response']['items'][i]['id'] arr_posts_id.append(post_id) if offset > 20000: break offset += 100 return arr_posts_id def get_all_comments(arr_posts_id): offset = 0 for post_id in arr_posts_id: r = requests.get('https://api.vk.com/method/wall.getComments', params={'owner_id': group_id, 'post_id': post_id, 'count': 100, 'offset': offset, 'access_token': token, 'v': version}) for i in range(100): try: write_txt('comments.txt', r.json() ['response']['items'][i]['text']) except IndexError: pass
В результате было получено около 200MB текста. Теперь считаем, какой символ сколько раз встречается:
f = open('comments.txt') counter = Counter(f.read().lower()) def count_letters(): count = 0 for i in range(len(arr_letters)): count += counter[arr_letters[i]] return count def frequency(count): arr_my_frequency = [] for i in range(len(arr_letters)): frequency = counter[arr_letters[i]] / count * 100 arr_my_frequency.append(frequency) return arr_my_frequency
Полученные результаты можно сравнить с результатами из Википедии и отобразить в виде:
1) сравнительной диаграммы
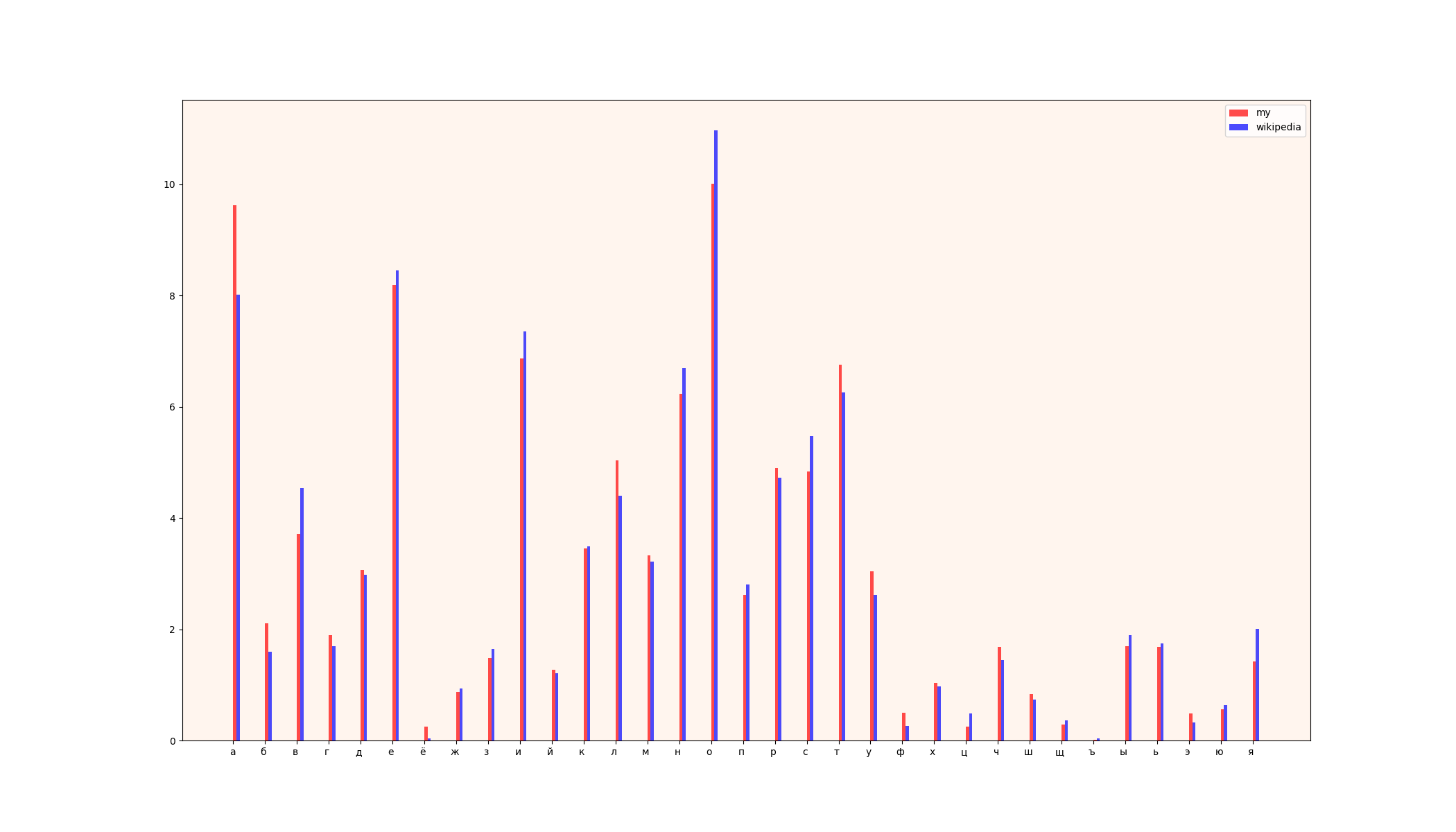
2) таблицы(слева — данные википедии, справа — мои данные)
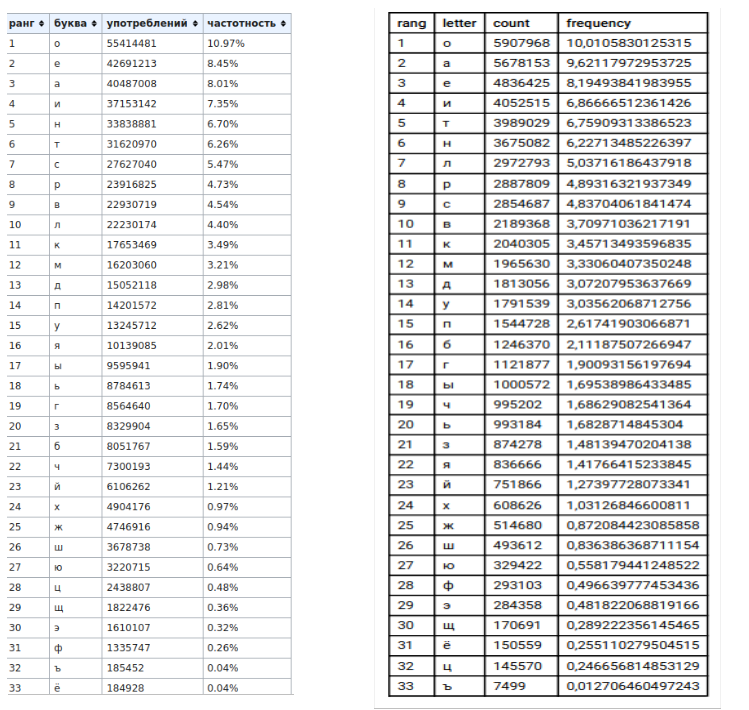
Проанализировав данные, можно сделать вывод, что частота встречаемости символов в процентном соотношении в двух источниках практически одинакова, за исключением таких букв как «а» и «о».
Шифрование и дешифрование текста
Далее я выбрал из того же сообщества более развёрнутый комментарий, который найти было не так уж и легко, так как в основном комментарии состоят из 2-4 слов:

дружа слово почти не считается, вар извинилась за неправильное решение, и этого достаточно чтобы сделать вывод и усомниться во многих их решениях, вар вместо того чтобы исключать ошибки делает их, это абсолютно не нормально, народ не такой уже и тупой, не по радио же слушаем транслы а в живую смотрим, по этому я больше чем уверен если бы не было столько пенок для мю они бы подавно в топ не попали, аналогично касается ман с, хотя играют местами захватывающе и красиво
После этого необходимо зашифровать полученный текст с помощью какого-нибудь симметричного алгоритма шифрования. Первое, что приходит на ум — это шифр цезаря, сущность которого заключается в том, чтобы изменить символ на другой с определенным шагом:
def caesar_cipher(): file = open("text.txt") text_for_encrypt = file.read().lower().replace(',', '') letters = 'абвгдеёжзийклмнопрстуфхцчшщъыьэюя' arr = [] step = 3 for i in text_for_encrypt: if i == ' ': arr.append(' ') else: arr.append(letters[(letters.find(i) + step) % 33]) text_for_decrypt = ''.join(arr) return text_for_decrypt
жуцйг фосес тсъхл рз фълхгзхфв егу лкелрлогфя кг рзтугелоярсз узызрлз л ахсёс жсфхгхсърс ъхсдю фжзогхя еюесж л цфспрлхяфв ес прсёлш лш узызрлвш егу епзфхс хсёс ъхсдю лфнобъгхя сылднл жзогзх лш ахс гдфсобхрс рз рсупгоярс ргусж рз хгнсм цйз л хцтсм рз тс угжлс йз фоцыгзп хугрфою г е йлецб фпсхулп тс ахспц в дсояыз ъзп цезузр зфол дю рз дюос фхсоянс тзрсн жов пб срл дю тсжгерс е хст рз тстгол гргосёлърс нгфгзхфв пгр ф шсхв лёугбх пзфхгпл кгшегхюегбьз л нугфлес
Затем осталось расшифровать текст с помощью частотного анализа:
def decrypt_text(text_for_decrypt, arr_decrypt_letters): arr_encrypt_text = [] arr_encrypt_letters = [' ', 'о', 'а', 'е', 'и', 'т', 'н', 'л', 'р', 'с', 'в', 'к', 'м', 'д', 'у', 'п', 'б', 'г', 'ы', 'ч', 'ь', 'з', 'я', 'й', 'х', 'ж', 'ш', 'ю', 'ф', 'э', 'щ', 'ё', 'ц', 'ъ'] dictionary = dict(zip(arr_decrypt_letters, arr_encrypt_letters)) for i in text_for_decrypt: arr_encrypt_text.append(dictionary.get(i)) text_for_decrypt = ''.join(arr_encrypt_text) print(text_for_decrypt)
двужа лросо мопти не лпитаетлб сав ишсиниралг ша немвасиргное вейение и ютохо долтатопно птоыч лдератг счсод и улокнитглб со кнохиз из вейенибз сав скелто тохо птоыч ильряпатг ойиыьи дерает из юто аылорятно не новкаргно навод не таьоф уже и тумоф не мо вадио же лруйаек тванлрч а с жисуя лкотвик мо ютоку б ыоргйе пек усевен елри ыч не ычро лторгьо меноь дрб кя они ыч модасно с том не момари анарохипно ьалаетлб кан л зотб ихваят келтаки шазсатчсаяэе и ьвалисо
Заключение
Если посмотреть на расшифрованный текст, то можно догадаться, где наш алгоритм ошибся: дерает → делает, вадио → радио, тохо → того, навод → народ. Таким образом, можно расшифровать весь текст, по крайне мере, уловить смысл текста. Также хочу отметить, что данный метод будет эффективный в расшифровке только длинных текстов, которые были зашифрованы симметричными методами шифрования. Полный код доступен на Github .
ссылка на оригинал статьи https://habr.com/ru/post/513926/
Добавить комментарий