У нас в компании мы активно работаем над автореферированием документов, в эту статью не стал включать все подробности и код, но описал основные подходы и результаты на примере нейтрального датасета: 30 000 футбольных спортивных новостных статей, собранных с информационного портала «Спорт-Экспресс».
Итак, суммаризацию можно определить, как автоматическое создание краткого содержания (заголовка, резюме, аннотации) исходного текста. Существует 2 существенно отличающихся подхода к этой задаче: экстрактивный и абстрактивный.
Экстрактивная суммаризация
Экстрактивный подход заключается в извлечении из исходного текста наиболее «значимых» информационных блоков. В качестве блока могут выступать отдельные абзацы, предложения или ключевые слова.

Методы данного подхода характеризует наличие оценочной функции важности информационного блока. Ранжируя эти блоки по степени важности и выбирая ранее заданное их число, мы формируем итоговое резюме текста.
Перейдем же к описанию некоторых экстрактивных подходов.
Экстрактивная суммаризация на основе вхождения общих слов
Данный алгоритм очень прост как для понимания, так и дальнейшей реализации. Здесь мы работаем только с исходным текстом, и по большому счету у нас отсутствует потребность в обучении какой-либо модели извлечения. В моем случае извлекаемые информационные блоки будут представлять собой определенные предложения текста.
Итак, на первом шаге разбиваем входной текст на предложения и каждое предложение разбиваем на токены (отдельные слова), проводим для них лемматизацию (приведение слова к «канонической» форме). Этот шаг необходим для того, чтобы алгоритм объединял одинаковые по смыслу слова, но отличающиеся по словоформам.
Затем задаем функцию схожести для каждой пары предложений. Она будет рассчитываться как отношение числа общих слов, встречающихся в обоих предложениях, к их суммарной длине. В результате мы получим коэффициенты схожести для каждой пары предложений.
Предварительно отсеяв предложения, которые не имеют общих слов с другими, построим граф, где вершинами являются сами предложения, ребра между которыми показывают наличие в них общих слов.
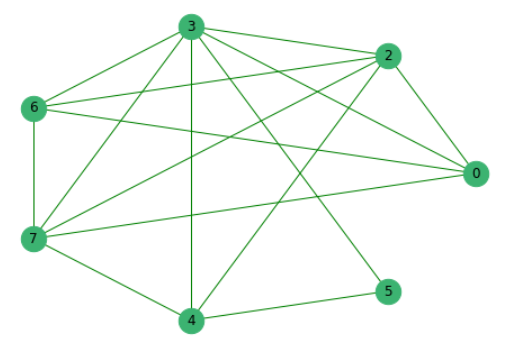
Далее ранжируем все предложения по их значимости.

Выбирая несколько предложений с наибольшими коэффициентами и далее сортируя их по номеру появления в тексте, получаем итоговое резюме.
Экстрактивная суммаризация на основе обученных векторных представлений
При построении следующего алгоритма уже использовались ранее собранные данные полных текстов новостей.
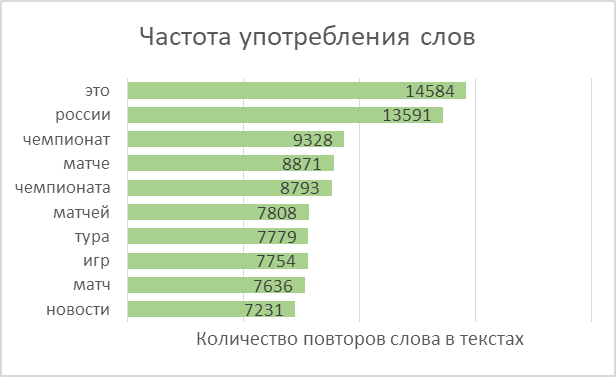
Слова во всех текстах разбиваем на токены и объединяем в список. Всего в текстах оказалось 2 270 778 слов, среди которых уникальных — 114 247.
С помощью популярной модели Word2Vec для каждого уникального слова найдем его векторное представление. Модель присваивает каждому слову случайные вектора и далее на каждом шаге обучения, «изучая контекст», корректирует их значения. Размерность вектора, которая способна «запомнить» особенность слова можно задать любую. Исходя из объема имеющегося датасета, будем брать векторы, состоящие из 100 чисел. Также отмечу, что Word2Vec является дообучаемой моделью, что позволяет подать на вход новые данные и на их основе скорректировать уже имеющиеся векторные представления слов.
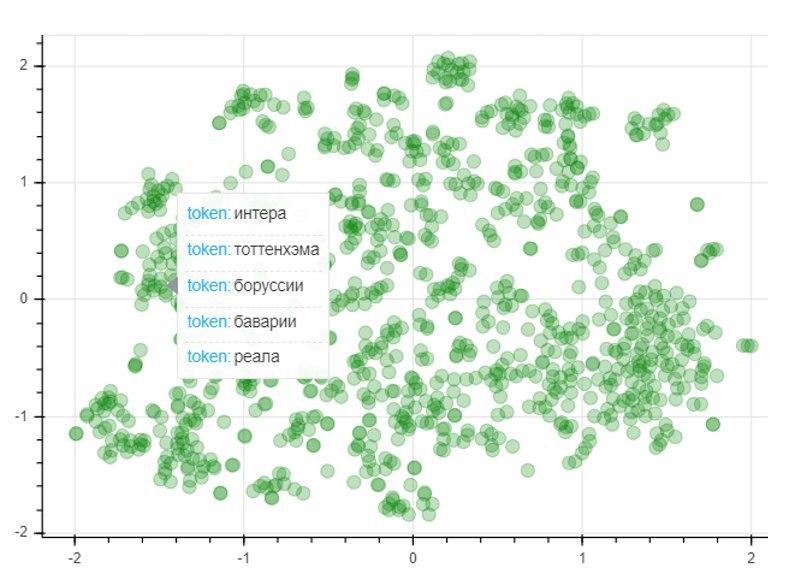
Для оценки качества модели применим метод понижения размерности T-SNE, который итеративно построит отображение векторов для 1000 самых употребляемых слов в двумерное пространство. Полученный график представляет собой расположение точек, каждая из которых соответствует определенному слову таким образом, что схожие по смыслу слова располагаются близко друг к другу, а различные наоборот. Так в левой части графика располагаются названия футбольных клубов, а точки в левом нижнем углу представляют собой имена и фамилии футболистов и тренеров:
После получения обученных векторных представлений слов можно переходить к самому алгоритму. Как и в предыдущем случае, на входе у нас текст, который мы разбиваем на предложения. Токенизируя каждое предложение, составляем для них векторные представления. Для этого берем отношение суммы векторов для каждого слова в предложении к длине самого предложения. Здесь нам помогают ранее обученные векторы слов. При отсутствии слова в словаре к текущему вектору предложения прибавляется нулевой вектор. Тем самым мы нивелируем влияние появления нового слова, отсутствующего в словаре, на общий вектор предложения.
Далее составляем матрицу схожести предложений, которая использует формулу косинусного сходства для каждой пары предложений.
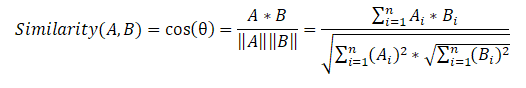
На последнем этапе на основе матрицы схожести также создаем граф и выполняем ранжирование предложений по значимости. Как и в предыдущем алгоритме, получаем список отсортированных предложений по их значимости в тексте.

В конце изображу схематично и еще раз опишу основные этапы реализации алгоритма (для первого экстрактивного алгоритма последовательность действий абсолютно такая же, за исключением того, что нам не нужно находить векторные представления слов, а функция сходства для каждой пары предложений вычисляется на основе появления в них общих слов):

- Разбиение входного текста на отдельные предложения и их обработка.
- Поиск векторного представления для каждого предложения.
- Вычисление и сохранение в матрице подобия сходства между векторами предложений.
- Преобразование полученной матрицы в граф с предложениями в виде вершин и оценками подобия в виде ребер для вычисления ранга предложений.
- Выбор предложений с наивысшей оценкой для итогового резюме.
Сравнение экстрактивных алгоритмов
С помощью микрофреймворка Flask (инструмент для создания минималистичных веб-приложений) был разработан тестовый веб-сервис для наглядного сравнения результатов вывода экстрактивных моделей на примере множества исходных новостных текстов. Мною проанализировано краткое содержание, генерируемое обеими моделями (извлекалось 2 наиболее значимых предложения) для 100 различных спортивных новостных статей.

По результатам сравнения результатов определения обеими моделями наиболее релевантных предложений могу предложить следующие рекомендации по использованию алгоритмов:
- Первая модель больше подходит для формирования заголовков или различного рода вступлений. На рассмотренных статьях выделялись именно те предложения, которые могли бы привлечь внимание потенциального читателя новости. Поэтому использование данной модели оправдано при формировании заголовка спортивной статьи, блога или иной новости.
- Вторая модель качественнее отражала основную суть полного текста. За счет обученных векторов, которые учитывали похожесть слов даже если они отличаются в написании, этот алгоритм хорошо подходит для формирования аннотации, содержащей основные мысли исходного текста. Обучая модель на других данных, которые связаны с интересующей предметной областью, можно получить качественный результат передачи основного смысла новости, документа или другого текста.
Абстрактивная суммаризация
Абстрактивный подход существенно отличается от своего предшественника и заключается в генерации краткого содержания с порождением нового текста, содержательно обобщающего первичный документ.
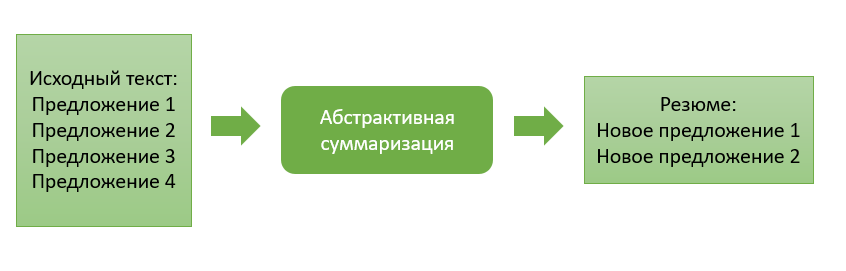
Основная идея данного подхода состоит в том, что модель способна генерировать абсолютно уникальное резюме, которое может содержать слова, отсутствующие в исходном тексте. Вывод модели представляет собой некоторый пересказ текста, который более близок к ручному составлению краткого содержания текста людьми.
Этап обучения
Я не буду подробно останавливаться на математических обоснованиях работы алгоритма, все известные мне модели основаны на архитектуре «кодера-декодера», которая в свою очередь построена с помощью рекуррентных слоев LSTM (о принципе работе которых можно почитать здесь). Кратко опишу шаги для декодирования тестовой последовательности.
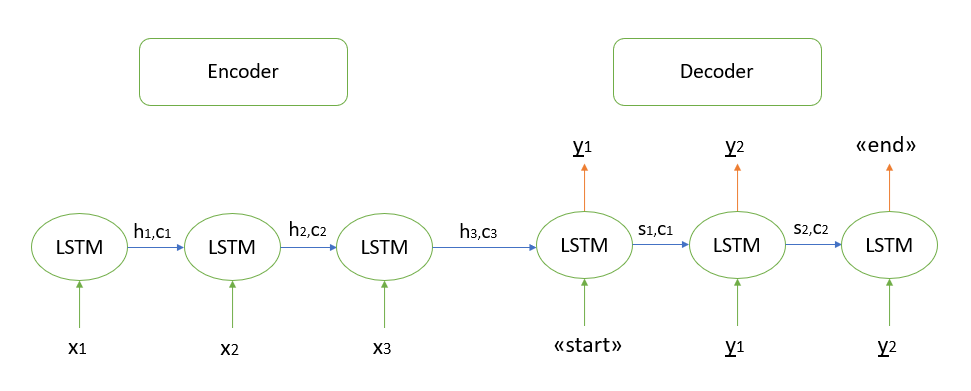
- Кодируем всю входную последовательность и инициализируем декодер внутренними состояниями кодера
- Передаем токен «start» в качестве входных данных для декодера
- Запускаем декодер с внутренними состояниями кодера на один временной шаг, в результате получаем вероятность следующего слова (слово с максимальной вероятностью)
- Передаем выбранное слово в качестве входных данных для декодера на следующем временном шаге и обновляем внутренние состояния
- Повторяем шаги 3 и 4, пока не сгенерируем токен «end»
Подробно с архитектурой «кодера-декодера» можно ознакомиться здесь.
Реализация абстрактивной суммаризации
Для построения более сложной абстрактивной модели извлечения краткого содержания потребуются как полные тексты новостей, так и их заголовки. В качестве резюме будет выступать именно заголовок новости, так как модель «плохо запоминает» длинные текстовые последовательностями.
При чистке данных используем перевод в нижний регистр и отбрасывание не русскоязычных символов. Лемматизация слов, удаление предлогов, частиц и других неинформативных частей речи окажет отрицательное воздействие на конечный вывод модели, так как потеряется взаимосвязь между словами в предложении.
Далее тексты и их заголовки разбиваем на обучающую и тестовую выборки в отношении 9 к 1, после чего преобразуем их в векторы (случайным образом).
На следующем шаге создаем саму модель, которая будет считывать переданные ей векторы слов и осуществлять их обработку с помощью 3 рекуррентных слоев LSTM кодера и 1 слоя декодера.
После инициализации модели обучаем ее с применением кросс-энтропийной функции потерь, которая показывает расхождения между реальным целевым заголовком и тем, который предсказывает наша модель.

Наконец, выводим результат модели для тренировочного множества. Как можно заметить в примерах, исходные тексты и резюме содержат неточности из-за отбрасывания перед построением модели редко встречающихся слов (отбрасываем для того, чтобы «упростить обучение»).

Вывод модели на данном этапе оставляет желать лучшего. Модель «успешно запоминает» некоторые названия клубов и фамилии футболистов, но сам контекст практически не уловила.
Несмотря на более современный подход к извлечению резюме, пока данный алгоритм сильно уступает созданным ранее экстрактивным моделям. Тем не менее, для того, чтобы улучшить качество модели, можно обучать модель на более объемном датасете, но, на мой взгляд, для получения действительного хорошего вывода модели необходимо изменить или, возможно, полностью сменить саму архитектуру используемых нейросетей.
Так какой же подход лучше?
Подытоживая данную статью, перечислю основные плюсы и минусы рассмотренных подходов извлечения краткого содержания:
1. Экстрактивный подход:
Преимущества:
- Интуитивно понятна суть алгоритма
- Относительная простота реализации
Недостатки:
- Качество содержания во многих случаях может быть хуже, чем написанное вручную человеком
2. Абстрактивный подход:
Преимущества:
- Качественно реализованный алгоритм способен выдать результат наиболее близкий к ручному составлению резюме
Недостатки:
- Сложности при восприятии основных теоретических идей алгоритма
- Большие трудозатраты при реализации алгоритма
Однозначного ответа на вопрос, какой же подход лучше сформирует итоговое резюме, не существует. Всё зависит от конкретной задачи и целей пользователя. К примеру, экстрактивный алгоритм скорее всего лучше подойдет для формирования содержания многостраничных документов, где извлечение релевантных предложений действительно сможет корректно передать идею объемного текста.
На мой взгляд, будущее все-таки за абстрактивными алгоритмами. Несмотря на то, что на данных момент они развиты слабо и на определенном уровне качества вывода могут использоваться только для генерации небольших резюме (1-2 предложения), стоит ждать прорыв именно от нейросетевых методов. В перспективе они способны формировать содержание для абсолютно любых по размеру текстов и, что самое главное, само содержание будет максимально соответствовать ручному составлению резюме экспертом в той или иной области.
Векленко Влад, системный аналитик,
Консорциум «Кодекс»
ссылка на оригинал статьи https://habr.com/ru/post/514540/
Добавить комментарий