Часть 1. Начало
1.1 Введение и постановка задачи
В компании МТС мы централизованно занимаемся контролем качества сетей передачи данных или, проще – транспортной сети (не путать с логистической транспортной сетью), далее по тексту – ТС. И, в рамках нашей деятельности, нам постоянно приходиться решать две основные задачи:
- Обнаружена деградация клиентских (по отношению к ТС) сервисов – нужно определить путь их проключения через ТС, и выяснить, является ли причиной деградации сервисов какой-либо участок ТС. Далее, будем называть это Прямой задачей.
- Обнаружена деградация качества транспортного канала или последовательности каналов – нужно определить, какие сервисы зависят от данного канала/каналов, чтобы определить влияние. Далее, будем называть это Обратной задачей.
Под сервисами ТС понимается любое проключение клиентского оборудования. Это могут базовые станции (БС), В2В клиенты (использующие ТС МТС для организации доступа в сеть Интернет и/или наложенных сетей VPN), клиенты фиксированного доступа (т.н. ШПД), и т.д. и т.п.
В нашем распоряжении – две централизованные информационные системы:
| Система Performance Monitoring | Данные о параметрах и топологии сети |
|---|---|
 |
 |
| Метрики, КПЭ ТС | Параметры конфигурации, L2/L3 каналы |
Любая транспортная сеть по своей сути является ориентированным графом , в котором каждое ребро имеет неотрицательную пропускную способность. Потому с самого начала поиск решения указанных задач выполнялся в рамках теории графов.
Сначала вопрос сопоставления показателей качества ТС и сервисов – с топологией ТС решался путем буквального объединения и представления данных топологии и качества в виде сетевого графа.
Просмотр сформированного по данным топологии и производительности графа был реализован на open source ПО Gephi. Это позволило решить задачу автоматического представления топологии, без ручной работы по её актуализации. Выглядит это так:
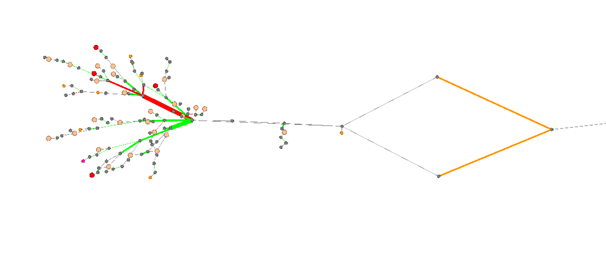
Здесь, узлы – это, собственно узлы ТС (маршрутизаторы, коммутаторы) и базовые, рёбра – каналы ТС. Цветовая маркировка, соответственно, обозначает наличие деградаций качества и статусы обработки этих деградаций.
Казалось бы – вполне наглядно и можно работать, но:
- Прямую задачу (от сервиса – к пути сервиса) можно решить достаточно точно только при условии, что сама топология ТС достаточно простая – дерево или просто последовательное соединение, без каких-либо колец и альтернативных маршрутов.
- Обратную задачу можно решить при аналогичном условии, но при этом на уровне агрегации и ядра сети решить эту задачу невозможно в принципе, т.к. данные сегменты управляются протоколами динамической маршрутизации и имеют множество потенциальных альтернативных маршрутов.
Также, надо иметь ввиду, что в общем случае топология сети гораздо сложнее (выше приведенный фрагмент обведён красным):

И это не самый маленький сегмент — есть гораздо больше и сложнее по топологии:

Итак, данный вариант подходил для медитативного разбора отдельных случаев, но никак не для поточной работы и, тем более, не для автоматизации решения прямой и обратной.
Часть 2. Автоматизация v1.0
Напоминаю, какие задачи мы решали:
- Определение пути проключения сервиса через ТС — Прямая задача.
- Определение зависимых сервисов от канала ТС — Обратная задача.
2.1. Транспортные сервисы для Базовых Станций (БС)
Обобщенно, организация транспорта от центрального узла (контроллера/шлюза) до БС выглядит так:

На сегментах агрегации и ядра ТС проключения выполняются через транспортные сервисы MPLS сети: L2/L3 VPN, VLL. На сегментах доступа проключения выполняются, как правило, через выделенные VLAN-ы.
Напоминаю, что у нас есть БД где лежит вся актуальная (в пределах определенного срока) параметрия и топология ТС.
2.2. Решение для коммутируемого сегмента (доступ)
Берем данные о VLAN логического интерфейса БС, и пошагово “идём” по связям, порты которых содержат этот Vlan ID, пока не дойдем до граничного маршрутизатора (МВН).

Для решения такой простой постановки задачи в итоге пришлось:
- Написать алгоритм пошаговой трассировки “распространения” VlanID от БС по каналам сети агрегации
- Учесть имеющиеся пробелы в данных. Особенно это касалось стыков между узлами на площадках.
- Фактически написать SPF алгоритм для того чтобы отбросить в конце тупиковые ветки, которые не ведут к МВН маршрутизатору.
Алгоритм получился из одного основного процесса и семи подпроцессов. На его реализацию и отладку было потрачено недели 3-4 чистого рабочего времени.
Кроме того, особое удовольствие нам доставили…
2.2.1. SQL JOIN
В силу своей структуры реляционная модель для прохода по графу требует явного рекурсивного подхода с операциями соединения на каждом уровне, при это осуществляется многократный проход по одному набору записей. Что в свою очередь влечет за собой ухудшение производительности системы, особенно на больших наборах данных.
По понятным причинам не могу здесь приводить содержимое запросов к БД, но оцените – каждый “уступ” в тексте запроса – это подключение очередной таблицы, которая нужна для, в данном случае, получения в унифицированном виде соответствия Порт — VlanID:

А этот запрос – для получения, в унифицированном виде кросс-коннектов VlanID внутри коммутатора:

Учитывая, что кол-во портов составляло несколько десятков тысяч, а VLAN – в 10 раз больше – ворочалось всё это очень нехотя. А такие запросы нужно было сделать для каждого узла и VlanID. И “выгрузить всё сразу и вычислить” – нельзя, т.к. это последовательное вычисление пути c с пошаговыми операциями, которые зависят от результатов предыдущего шага.
2.3. Определение пути сервиса в маршрутизируемых сегментах
Здесь мы начали с одного вендора МВН, система управления которого предоставляла данные о текущем и резервном LSP через сегмент MPLS. Зная Access интерфейс, который стыковался с доступом (L2 Vlan) можно было найти LSP а затем – через серию запросов к NBI системы, получить путь LSP, состоящий из маршрутизаторов и линков между ними.

- Аналогично коммутируемому сегменту, описание выгрузки пути LSP MPLS сервиса вылилось в алгоритм с уже 17-ю подпрограммами.
- Решение работало только на сегментах, которые обслуживались данным вендором
- Нужно было решать определение стыков между сервисами MPLS (например, в центре сегмента был общий VPLS сервис, а от него расходились или EPIPE либо L3VPN)
Мы проработали вопрос и для других вендоров МВН, где систем управления не было, или они не предоставляли данных о текущем прохождении LSP в принципе. Решение для нескольких мы нашли, но – кол-во LSP, проходящее через маршрутизатор – это уже не кол-во VanID, которое прописано на коммутаторе. Затягивая такой объем данных “по запросу” (ведь нам нужна оперативная информация) — есть риск положить железо.
Кроме этого, возникали дополнительные вопросы:
- Сеть МВН в общем случае – мультивендорная, и на одном сегменте встречаются маршрутизаторы разных производителей, управляемых разными СУ. Т.е. – у нас будут данные только о куске пути MPLS сервиса.
- СУ вендора, которая могла предоставлять данные об основном и резервном LSP, на деле прописывала и первый и второй по одному и тому же пути. Это мы видели очень часто. А нам бы хотелось знать про потенциальные пути обхода при анализе ограничений на сети.
2.4. Где и как хранить результаты. Как запрашивать данные
Полученные данные о путях проключения сервисов надо куда-то записать, чтобы потом обращаться к ним при решении наших Прямой и Обратной задач.
Вариант с хранением в реляционной БД сразу исключили: с таким трудом агрегировать данные из множества источников чтобы потом в итоге рассовать по очередным наборам таблиц? Это не наш метод. Тем более – помним про многоэтажные джойны и их производительность.
Данные должны содержать информацию о структуре сервиса и зависимостях его составляющих: линках, узлах, портах и т.п.
В качестве тестового решения был выбран формат XML и Native-XML БД – Exist.
Каждый сервис в результате записывался в БД в формате (подробности опущены для компактности записи):
<services> <service> <id>,<description> Описание сервиса (например, наименование БС) <source> Интерфейс условной точки А <target> Интерфейс условной точки Z <<segment>> Сегменты L2/L3 <topology> Информация о пути через сегмент (узлы, порты/интерфейсы, соединения) <<joints>> Стыки между сегментами (узлы, порты/интерфейсы, соединения) </service> </services>Запрос данных по прямой и обратной задачам выполнялся по протоколу XPath:

Всё. Теперь система заработала – на запрос с наименованием БС возвращается топология проключения её через транспортную сеть, на запрос с наименованием узла и порта ТС возвращается список БС, которые от него зависят по подключению. Поэтому, выводы мы сделали следующие…
2.5.

Вместо заголовка о выводах по части 2
2.5.1. Для коммутируемого сегмента (сети на L2 коммутаторах Ethernet)
- Обязательно нужны полные данные о топологии и соответствии Port – VlanID. Если на каком-то линке нет данных о VlanID – алгоритм останавливается, путь не найден
- Многоэтажные непроизводительные запросы к реляционной БД. При появлении нового вендора со своей спецификой параметрии – добавление запросов на всех этапах работы
2.5.2. Для маршрутизируемого сегмента
- Ограничено возможностями СУ МВН по предоставлению данных о топологии LSP MPLS сервисов.
- Запросы конфигурации непосредственно с МВН – потенциально опасны, т.к. счёт обслуживаемых LSP идет на тысячи.
- Резервные LSP часто прописываются системой по тому же маршруту что и основные – нет информации о потенциальных альтернативных путях (в том числе и помимо тех, которые “держит” система).
2.5.3. Общее
- Чтобы решить, по сути, задачу в сетевом графе, мы постоянно собираем данные из табличных источников, чтобы представить их в виде графа ( визуально – в голове, или в памяти программы), реализовать алгоритм, а потом – разобрать обратно.
- Алгоритмизация решений и их реализация традиционными методами требует значительных трудозатрат. На реализацию данного этапа у нас ушло в целом 3-4 месяца.
- Масштабирование очень затруднено, т.к. любое изменение, в виде появления нового вендора либо MPLS сервиса ведёт за собой внесение изменений в структуру запросов к БД и в сам программный код.
- Приходится писать Дейкстра – подобные алгоритмы, а не использовать готовые инструменты.
2.6. Чего всё-таки хотим
- Чтобы данные о сетевом графе ТС и хранились, и обрабатывались как сетевой граф, т.е. – набор узлов и зависимостей.
- Чтобы использовались уже готовые алгоритмы работы с графами
- Чтобы модель данных была универсальной, а не вендорно-зависимой
- Чтобы трассировка была возможна и на неполных данных (например, частичное отсутствие данных о VlanID)
После того как мы провели оценку возможных вариантов реализации наших хотелок — определились с классом систем, которые бы всё это обеспечили “из коробки” – это т.н. графовые базы данных.
Хоть и читается последнее предложение как нечто линейное и простое, учитывая что ранее с таким классом БД никому из нас (и наших айтишников, как потом выяснилось – тоже) сталкиваться не приходилось — к решению пришли в некоторой степени случайно: подобные базы данных упоминались (но не разбирались) в обзорном курсе по Big Data. В частности, там упоминался продукт Neo4j. Мало того, что он, судя по описанию, удовлетворял всем нашим требованиям, у него ещё есть полностью бесплатная функциональная community-версия. Т.е. – не 30-дневный триал, не обрезанный основной функционал, а полностью рабочий продукт, который можно не спеша изучить. Не последнюю (если не основную) роль в выборе сыграла широкая поддержка графовых алгоритмов.
Часть 3. Пример реализации прямой задачи в Neo4j
Чтобы не затягивать линейное повествование о том, как реализуется модель ТС в графовой БД Neo4j — сразу покажем конечный результат на примере.
3.1. Трассировка пути проключения интерфейса Iub для БС 3G

Путь проключения сервиса проходит по двум сегментам – маршрутизируемому МВН, и коммутируемому РРЛ (радиорелейные станции работают как Ethernet-коммутаторы). Путь через РРЛ сегмент определяется также, как было описано в части 2 – по прохождению VlanID интерфейса БС по сегменту РРЛ до граничного маршрутизатора МВН. Сегмент МВН соединяет граничный (с сегментом РРЛ) маршрутизатор — с маршрутизатором к которому подключен контроллер БС (RNC).
Изначально, из параметрии Iub, мы знаем точно — какой МВН является шлюзом для БС (граничный МВН), и каким контроллером обслуживается БС.
Исходя из этих начальных условий, построим 2 запроса к БД для каждого из сегментов. Все запросы к БД строятся на языке Cypher. Чтобы сейчас не отвлекаться на его описание, воспринимайте его просто как “SQL для графов”.
3.1.1. Сегмент РРЛ. Путь по VlanID
Cypher-запрос трассировки пути сервиса по имеющимся данным о VlanID и топологии L2:
| Фрагмент Cypher-запроса (конструкция WITH – передача результатов одного этапа запроса на следующий (конвейеризация обработки) ) |
Промежуточные результаты запроса (визуальное представление в консоли Neo4j – “Neo4j Browser”) |
|---|---|
Получение узлов БС и МВН между которыми будет проводиться поиск пути сервиса Iub
|
 |
Получение узлов Vlan БС интерфейса Iub
|
 |
Выбираем узлы ТС на той же площадке с БС, на портах которых прописан VlanID Iub БС
|
 |
по алгоритму Дейкстра находим кратчайший путь от VlanID ТС узла площадки БС до граничного МВН
|
 |
Из цепочки Vlan получаем список узлов, портов, и связей между портами, который, в итоге, и будет являться путём проключения сервиса Iub от БС до граничного маршрутизатора
Результат: |
|

|
|
Как видно, путь получен, даже несмотря на частичный недостаток данных. В данном случае – отсутствует информация о стыке порта БС с портом радиорелейной станции.
3.1.2. Сегмент РРЛ. Путь по L2 топологии
Допустим, попытка в п. 3.1.1. не удалась по причине полного или частичного отсутствия данных о параметрии VlanID. Другими словами – подобная непрерывная цепочка, доходящая до узла МВН не выстраивается:
Тогда можно попробовать определить проключение сервиса как кратчайший путь до МВН по топологии L2:
Результат: |

|
Как видно, получен такой же результат. Здесь недостаток информации о стыке БС с РРС восполнен прохождением связи через объект (узел) площадки, на которой они находятся. Разумеется, точность такого метода будет меньше, т.к. в общем случае Vlan может быть прописан не по кратчайшему пути, предполагаемому алгоритмом Дейкстра. Зато запрос состоит из всего двух операций.
3.1.3 Сегмент МВН. Трассировка пути от граничного МВН до контроллера
Здесь так же используем алгоритм Дейкстра.
Один путь с минимальной стоимостью
|
 |
Топ-2 пути с минимальной стоимостью (основной + альтернатива)
|
 |
Топ-3 пути с минимальной стоимостью (основной + две альтернативы)
|
 |
Аналогично – в данном случае отсутствует информация о непосредственных стыках МВН с RNC. Но это не мешает построить путь сервиса, пусть и предполагаемый алгоритмом (об этом — позже).
3.2. Трудозатраты
Реализация Прямой задачи, показанная сейчас, разительно отличается от подхода “разработай алгоритм, программу, способ хранения и извлечения результатов” – здесь всё сводится к “напиши запрос к БД”. Забегая вперёд, отметим, что весь цикл от разработки простой модели графа, загрузки данных в Neo4j из реляционной БД, написания запросов, и до получения результата занял, в общей сложности, один день.
3-4 месяца vs 1 день!!! Это было последним доводом для окончательного ухода в графовую БД.
Часть 4. Графовая БД Neо4j и загрузка данных в неё
4.1. Сравнение реляционных и графовых БД
| Сравнительная характеристика | Реляционная БД | Графовая БД |
|---|---|---|
| Хранение данных | Данные хранятся в наборе отдельных таблиц, связи между строками которых могут быть определены по ключевым полям через специальные отношения: один к одному, один ко многим, многие ко многим.

|
Данные хранятся или в виде узлов или в виде отношений (направленных связей/ссылок между узлами). И у тех и у других может быть произвольный набор параметров.

|
| Структура данных | Тот, кто строит запросы к БД, должен точно знать структуру хранения данных, и какие связи между данными, помимо определенных через внешние ключи, могут быть. Любые изменения/дополнения в структуре данных требуется соотносить с моделью хранения, при этом заранее оценивая последствия для производительности БД в целом. По этой причине коммерческие системы, использующие для хранения РБД, берут с клиентов деньги за адаптацию потребностей последних к своей модели хранения данных | Структура данных (узлов и взаимосвязей между ними) определяется самими данными. Пользователю доступна вся информация о текущей структуре. Отсутствует жесткая фиксированная схема – возможно одновременное существование нескольких вариантов представления данных. Прямое и универсальное моделирование данных пользователем. Любой объект может быть представлен набором из трех сущностей: Узел, Связь, Параметры. |
| Проблема JOIN | Не всегда поля, по которым понадобится сделать объединение данных при запросе – индексированы. Это может значительно снизить быстродействие запроса, т.к. заставляет планировщик прибегать к NESTED-LOOP | Связи между узлами определяются на этапе загрузки в БД или на этапах постпроцессинга (вычисления связей). Если угодно – ГБД это как если бы в РБД все нужные JOIN уже были сделаны, причем на уровне отдельных полей отдельных строк. |
| JOIN chain | Чем больше мы сцепляем JOIN операций друг за другом в одном запросе – тем больше падение производительности. Т.е. мы экспоненциально теряем в производительности на каждый вложенный JOIN в запросе. В данной статье приведен пример решения задачи поиска “в глубину” – запросами к РБД Oracle, и к ГБД Neo4j:

|
Проблемы не существует. Обход графа в глубину – нативное свойство ГБД. |
| Зависимость от кол-ва записей/размера БД | Чем больше записей в объединяемых таблицах, тем большее время требуется от РБД для обработки запроса, даже если количество реально возвращаемых записей неизменно | Запрос отсекает именно ту часть графа, которая связана с интересующими узлами/связями и работает только с ней, при этом размер БД графа может быть любым. Например, запрос идет от узла “МВН-Х”, при этом всего в графе может быть как 1000 так и 1 млн узлов МВН – поиск всё равно будет внутри “сегмента” графа, включающего только “МВН-Х”. |
4.2. Модель данных
Базовая модель представления ТС до уровня L3 топологии включительно:

Разумеется, модель обширнее представленной, и содержит также и MPLS сервисы, и виртуальные интерфейсы, но для упрощения рассмотрим её ограниченный фрагмент.
В такой модели связь между двумя сетевыми элементами одного региона может быть представлена как:

4.3. Загрузка данных
Загрузку данных выполняем из БД параметрии и топологии ТС. Для загрузки в Neo4j из SQL БД используется библиотеки APOC – apoc.load.jdbc, которая принимает на вход строку подключения к RDBMS и текст SQL запроса, и возвращает множество строк, которые через CYHPER –выражения отображаются на узлы, связи, или параметры. Такие операции выполняются слой за слоем для каждого типа объектов модели.
Например, проход для загрузки/обновления узлов, представляющих сетевые элементы (Nodes):
|
Вызов процедуры apoc.load.jdbc, получение набора данных |
|
Для каждой строки из набора данных по коду региона и сайта ищутся узлы представляющие соответствующие площадки |
|
Для каждого объекта площадки обновляются связанные с ней сетевые элементы (node). Используется инструкция MERGE + SET, которая обновляет параметры объекта, если он уже существует в БД, если нет – то создает объект. Тут же записываются параметры узла Node и его связей с узлом PL |
И так далее – по всем уровням модели ТС.
Поле Updated используется при контроле актуальности данных в графе – не обновляемые дольше определенного периода объекты удаляются.
Часть 5. Решаем обратную задачу в Neo4j
Когда мы только начинали, выражение “трассировка сервиса” в первую очередь вызывало следующие ассоциации:

Т.е., что трассируется непосредственно текущий путь прохождения сервиса, в данный момент времени.
Это не совсем то, что мы имеем в графовой БД. В ГБД трассируется сервис по взаимосвязям объектов, определяющих его конфигурацию в каждом задействованном сетевом элементе. Т.е., в виде графовой модели представляется конфигурация, и результирующая трасса – это проход по модели, представляющей эту конфигурацию.
Так как, в отличие от коммутируемого сегмента, фактические маршруты сервиса в сегменте mpls определяются динамическими протоколами, нам пришлось принять некоторые…
5.1. Допущения для маршрутизируемых сегментов
Т.к. из данных конфигурации mpls сервисов нет возможности определить их точный путь прохождения через сегменты, управляемые динамическими протоколами маршрутизации (тем более, если используется Traffic Engineering) – для решения используется алгоритм Дейкстры.
Да, есть системы управления, которые могут по NBI-интерфейсу предоставлять актуальный путь сервисных LSP, но пока у нас такой вендор только один, а вендоров на сегменте МВН – больше чем один.
Да, есть системы анализа протоколов маршрутизации внутри AS, которые, слушая обмен IGP протоколов, могут определить текущий маршрут интересующего префикса. Но стоят такие системы — как сбитый Боинг, а учитывая что такую систему нужно развернуть на всех AS того же мобильного бэкхола – стоимость решения вместе со всеми лицензиями составит стоимость Боинга, сбитого чугунным мостом, привязанным к ракете Ангара при полной заправке. И это ещё при том что подобными системами не вполне решены задачи учета маршрутов через несколько AS c использованием BGP.
Поэтому — пока так. Конечно, мы добавили несколько подпорок в условия стандартного алгоритма Дейкстра:
- Учёт статуса интерфейсов/портов. Отключенный линк повышается в стоимости и идет в конец возможных вариантов пути.
- Учёт резервного статуса линка. По данным системы Performance Monitoring вычисляется присутствие в mpls канала только трафика keepalive, соответственно, стоимость такого канала также увеличивается.
5.2. Как решить обратную задачу в Neo4j
Напоминание. Обратная задача – получение списка сервисов, зависимых от конкретного канала или узла транспортной сети (ТС).
5.2.1. Коммутируемый L2 сегмент
Для коммутируемого сегмента, где путь сервиса и конфигурация сервиса – это практически одно и то же, задачу ещё можно решить через CYPHER-запросы. Например, для радиолерейного пролета из результатов решения Прямой задачи в п 3.1.1., сделаем запрос от модема радиорелейного линка – “развернем” все цепочки Vlan, которые проходят через него:
match (tn:node {name:'RRN_29_XXXX_1'})-->(tn_port:port {name:'Modem-1'})-->(tn_vlan:vlan) with tn, tn_vlan, tn_port call apoc.path.spanningTree(tn_vlan,{relationshipFilter:"ptp_vlan>|v_ptp_vlan>", maxLevel:20}) yield path as pp with tn_vlan,pp,nodes(pp)[-1] as last_node, tn_port match (last_node)-[:vlan]->(:port)-->(n:node) return pp, n, tn_portКрасным узлом обозначен модем, Vlan которого разворачиваем. Обведены 3 БС на которые в итоге вывело развертывание транзитных Vlan с Modem1.

У такого подхода есть несколько проблем:
- Для портов должны быть известны и загружены в модель сконфигурированные Vlan.
- Из-за возможного фрагментирования, цепочка Vlan не всегда выводит на терминальный узел
- Невозможно определить – относится ли последний узел в цепочке Vlan к терминальному узлу или сервис, на самом деле, продолжается дальше.
То есть, сервис всегда удобнее трассировать между конечными узлами/точками его сегмента, а не из произвольной “середины”, и с одного уровня OSI.
5.2.2. Маршрутизируемый сегмент
С маршрутизируемым сегментом, как уже описано в п 5.1, выбирать не приходится – для решения обратной задачи на основании данных текущей конфигурации какого-то промежуточного линка MPLS никаких средств нет – конфигурация не определяет в явном виде трассу сервиса.
5.3. Решение
Решение было принято следующее.
- Проводится полная загрузка модели ТС, включая БС и контроллеры
- Для всех БС выполняется решение прямой задачи – трассировка сервисов Iub, S1 от БС до граничного МВН, а затем от граничного МВН до соответствующих контроллеров или шлюзов.
- Результаты трассировки записываются в обычную SQL БД в формате: Наименование БС – массив элементов пути сервиса
Соответственно, при обращении к БД с уловием Узел ТС или Узел ТС + Порт, возвращается список сервисов (БС), в массиве пути которых есть нужный Узел или Узел+Порт.

Часть 6. Результаты и выводы
6.1. Результаты
В итоге система работает следующим образом:

На данный момент для решения прямой задачи, т.е. при анализе причин деградации отдельных сервисов, разработано веб-приложение, показывающее результат трассировки (путь) из Neo4j, с наложенными данными о качестве и производительности отдельных участков пути.

Для получения списка сервисов, зависимых от узлов или каналов ТС (решение обратной задачи) разработан API для внешних систем (в частности – Remedy).
6.2. Выводы
- Оба решения подняли на качественно новый уровень автоматизацию анализа качества сервисов и транспортной сети.
- Кроме этого, при наличии готовых данных о трассах сервисов БС, стало возможно быстро предоставлять данные для бизнес-подразделений о технической возможности включения В2В клиентов на конкретных площадках — по емкости и качеству трассы.
- Neo4j показал себя как очень мощный инструмент для решения задач с сетевыми графами. Решение отлично документировано, имеет широкую поддержку в различных сообществах разработчиков, постоянно развивается и улучшается.
6.3. Планы
В планах у нас:
- расширение технологических сегментов, моделируемых в БД Neo4j
- разработка и внедрение алгоритмов трассировки сервисов ШПД
- увеличение производительности серверной платформы
Спасибо за внимание!
ссылка на оригинал статьи https://habr.com/ru/post/517254/
Добавить комментарий