
При поиске параллельных корпусов для своих нужд, — это может быть обучение модели машинного перевода или изучение иностранного языка, можно столкнуться с тем, что их не так уж и много, особенно, если речь идет не об английском, а каком-то редком языке. В этой статье мы попробуем создать свой корпус для популярной языковой пары русский-немецкий на основе романа Ремарка "Три товарища". Любителям параллельного чтения книг и разработчикам систем машинного перевода посвящается.
Задача
Такая задача называется выравниванием текстов и может быть до какой-то степени решена следующими способами:
- Использовать эвристики. Можно считать количество предложений в текстах, количество слов в них и на основе этого производить сопоставление. Такой способ не дает хорошего качества, но может тоже быть полезным.
- Использовать sentence embeddings. Наверняка вы слышали про модели типа word2vec или sent2vec или видели такой пример их использования — "король" + "женщина" — "мужчина" = "королева". Если коротко, то суть в том, чтобы перевести слова (предложения, тексты) в векторное пространство с сохранением семантического расстояния между ними. Такой подход открывает перед нами замечательные возможности по оценке близости текстов и их кусочков по смыслу.
Модели
В качестве моделей, из которых мы будем брать эмбеддинги, возьмем Universal Sentence Encoder, Sentence Transformers и недавно вышедший LaBSE (Language Agnostic BERT Sentence Embeddings).
Как бы не была хороша модель, одна она не справится, потому что при переводе текста с одного языка на другой переводчик частенько может объединять два предложение в одно, а одно сложное предложение разбивать на несколько простых. Особенно это характерно при переводе с русского на китайский. Для таких случаев можно придумать эвристики, наподобие такой — если длинна предложений отличается больше чем в два раза, то либо разбиваем одно из них по знаку препинания, либо склеиваем короткое со следующим или предыдущим. Потом оставляем наиболее близкие пары.
Модели, которые мы будем использовать, являются не только мультиязыковыми, но и выровненными, это означает, что, если им на вход подавать предложения на разных языках, то вектора все равно будут сохранять между собой семантическое расстояние, — вектор для "I love cats" будет близок вектору "Я люблю кошек". Разумеется, модель должна поддерживать необходимые нам языки, список таких приведен в таблице 1. Самый быстрый инференс у USE, если вам нужны более-менее редкие языки, то используйте xlm-r-100langs-bert-base или LaBSE.
Таблица 1. Multilingual sentence embedding models
| Модель | Поддерживаемые языки | Размер весов | Длина embedding’а |
|---|---|---|---|
| sentence transformers/distiluse-base-multilingual-cased | 13 языков (английский, арабский, испанский, итальянский, китайский, корейский, немецкий, нидерландский, польский, португальский, русский, турецкий и французский) | 500Mb | 512 |
| Universal Sentence Encoder | 15 языков (те же плюс тайский и японский) | 250Mb (300Mb large version) | 512 |
| sentence transfomers/xlm-r-100langs-bert-base | 100 языков*, полный список | 1Gb | 768 |
| LaBSE | 109 языков, полный список | 1.63Gb | 768 |
*В документации sentence transformers отмечается, что модели также дают неплохой результат для языков вне поддерживаемого списка.
Выравниватель
Чтобы любой мог сразу же поиграться с моделями и что-то сделать самостоятельно, эксперименты будем проводить в Colab’е, общедоступном jupyter блокноте. Все ссылки будут в конце статьи.
Нам понадобятся библиотеки для разбиения текстов на предложения и загрузки предобученных моделей. Установим их в нашу среду приступим к выравниванию.
!pip3 install razdel !pip3 install sentence-transformers
import re import seaborn as sns import numpy as np from scipy import spatial from matplotlib import pyplot as plt import razdel from sentence_transformers import SentenceTransformer
Предобработка
Итак, возьмем первую главу замечательного романа "Три товарища" в оригинале (1936 год) и в переводе И. Шрайбера и
Л. Яковленко (1959 год). Первым шагом будет разбить текст на предложения и посмотреть насколько сильно они отличаются по количеству. Так это просто сырые тексты из интернета, предварительно немного почистим текст. По предложениям текст разобъем razdel’ом (бывшая библиотека natasha), для немецкого языка такой способ тоже подойдет, если мы позаботимся о кавычках (в немецком языке они обратные — »«).
double_dash = re.compile(r'[--]+') quotes_de = re.compile(r'[»«]+') ru = re.sub('\n', ' ', text_ru) ru = re.sub(double_dash, '—', ru) de = re.sub('\n', ' ', text_de) de = re.sub(quotes_de, ' ', de) sent_ru = list(x.text for x in razdel.sentenize(ru)) sent_de = list(x.text for x in razdel.sentenize(de))
Предложения на русском:
['Небо было желтым, как латунь; его еще не закоптило дымом.', 'За крышами фабрики оно светилось особенно сильно.', 'Вот—вот должно было взойти солнце.', 'Я посмотрел на часы — еще не было восьми.', 'Я пришел на четверть часа раньше обычного.', 'Я открыл ворота и подготовил насос бензиновой колонки.', 'Всегда в это время уже подъезжали заправляться первые машины.', 'Вдруг за своей спиной я услышал хриплое кряхтение, — казалось, будто под землей проворачивают ржавый винт.', 'Я остановился и прислушался.', 'Потом пошел через двор обратно в мастерскую и осторожно приоткрыл дверь.']
И на немецком:
['Der Himmel war gelb wie Messing und noch nicht verqualmt vom Rauch der Schornsteine.', 'Hinter den Dächern der Fabrik leuchtete er sehr stark.', 'Die Sonne mußte gleich aufgehen.', 'Ich sah nach der Uhr.', 'Es war noch vor acht.', 'Eine Viertelstunde zu früh.', 'Ich schloß das Tor auf und machte die Benzinpumpe fertig.', 'Um diese Zeit kamen immer schon ein paar Wagen vorbei, die tanken wollten.', 'Plötzlich hörte ich hinter mir ein heiseres Krächzen, das klang, als ob unter der Erde ein rostiges Gewinde hochgedreht würde.', 'Ich blieb stehen und lauschte.']
По количеству их получилось 570 на русском против 561-го на немецком. Так как количество предложений различается не сильно, то скорее всего получится выровнять тексты с хорошим качеством.
Батчинг
Чтобы не грузить в модель сразу все вектора будем считать их батчами, при этом введем специальный коэффициент, который будет учитывать разницу в колчестве выравниваемых предложений для различных языков. Это необходимо, когда разница в количестве бдует более существенная.
def get_batch(iter1, iter2, batch_size): l1 = len(iter1) l2 = len(iter2) k = int(round(batch_size * l2/l1)) kdx = 0 - k for ndx in range(0, l1, batch_size): kdx += k yield iter1[ndx:min(ndx + n, l1)], iter2[kdx:min(kdx + k, l2)]
Эмбеддинги
В качестве модели возьмем sentence-transformers (distiluse-base-multilingual-cased), так как она поддерживает немецкий и русский языки, относительно немного весит (~500 Mb), и дает очень хорошие вектора.
model_st = SentenceTransformer('distiluse-base-multilingual-cased')
vectors1, vectors2 = [], [] for lines_ru_batch, lines_de_batch in get_batch(sent_ru, sent_de, batch_size): batch_number += 1 vectors1 = [*vectors1, *model_st.encode(lines_de_batch)] vectors2 = [*vectors2, *model_st.encode(lines_ru_batch)]
Полученные эмбеддинги представляют собой вектора размерностью 512.
[array([-0.03442561, 0.02094117, ... , 0.11265451])], dtype=float32)]
Близость
Посчитаем матрицу состоящую из косинусных близостей между парами векторов. Обсчитывать будем не все пары, а только те, которые находятся в окне — какое-то количество предложений вперед и назад от "оси выравнивания". Под осью понимается главная диагональ нашей матрицы.
def get_sim_matrix(vec1, vec2, window=10): sim_matrix=np.zeros((len(vec1), len(vec2))) k = len(vec1)/len(vec2) for i in range(len(vec1)): for j in range(len(vec2)): if (j*k > i-window) & (j*k < i+window): sim = 1 - spatial.distance.cosine(vec1[i], vec2[j]) sim_matrix[i,j] = sim return sim_matrix
sim_matrix = get_sim_matrix(vectors1, vectors2, window)
Визуализация
Посмотрим сначала на матрицу близостей для первых 50 строк. Красиво будет выглядеть heatmap, построеная через seaborn.
plt.figure(figsize=(12,10)) sns.heatmap(sim_matrix, cmap="Greens", vmin=threshold) plt.xlabel("russian", fontsize=18) plt.ylabel("chinese", fontsize=18) plt.show()
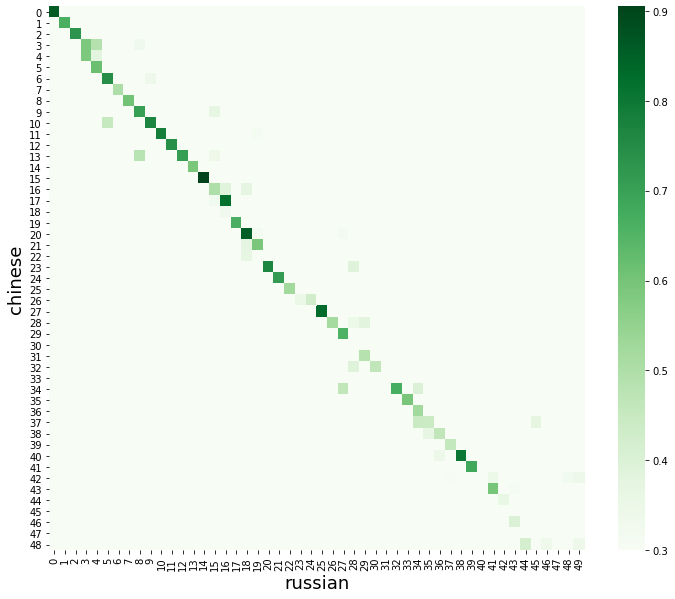
Для каждой строки будем брать наиболее близкий вариант. После это наша матрица будем выглядеть следующим образом.

А вот так для всего текста.

Проблемы
Видим, что в некоторых местах модель не смогла сопоставить предложения, основные причины я вижу такие:
- Литературный стиль. Так как выравниваемые тексты являются художественной литературой, то не удивительно, что есть пропуски, — как мы помним, модель обучалась на Википедии, common crawling’е и новостях, а не на литературных корпусах.
- Авторский стиль. В текстах могут встречаться придуманные автором или устаревшие слова, также часто могут встречаться жаргонизмы и разговорная лексика (например, уборщица фрау Штосс в начале романа, икая, все время повторяет nich вмесо nicht).
- Стиль переводчика. При переводе может не сохраняться синтаксическая структура, — одно предложение может быть переведено как два и наоборот. Это нормальная картина.
- Имена собственные. Если имена Роберт, Готфрид, Отто и Патриция ещё куда ни шли, то фамилии Локамп, Ленц, Кёстер и Хольман модели сопоставить трудно. Все они "разбавляют" близость между векторами. Сюда же можно отнести любые редкие имена, названия организаций и географических объектов.
- Особенности языка. У каждого языка есть свои "фишки". Немецкий язык известен своими склеивающимися словами и перескакивающими в конец приставками, зато порядок слов более-менее строгий. Русский очень богат морфологией, падежами (венгерский язык нервно засмеялся) и почти свободным порядком слов. В китайском нет пробелов и т.д.
Результат
Решать все эти проблемы можно по разному, можно взять наиболее удачные сопоставления, в них будет и авторский стиль и имена, и дообучить нашу модель на этих данных. Можно применить простые и хитрые эвристики, — если два предложения уверенно сошлись, то и то, что между ними, должно соответствовать, даже если модель не очень уверена. Пока же посмотрим, что у нас получилось.
Небо было желтым, как латунь; его еще не закоптило дымом. Der Himmel war gelb wie Messing und noch nicht verqualmt vom Rauch der Schornsteine. >> similarity 0.8614717125892639 За крышами фабрики оно светилось особенно сильно. Hinter den Dächern der Fabrik leuchtete er sehr stark. >> similarity 0.6654264330863953 Вот—вот должно было взойти солнце. Die Sonne mußte gleich aufgehen. >> similarity 0.7304455041885376 Я посмотрел на часы — еще не было восьми. Ich sah nach der Uhr. >> similarity 0.5894380807876587 Я посмотрел на часы — еще не было восьми. Es war noch vor acht. >> similarity 0.5892142057418823 Я пришел на четверть часа раньше обычного. Eine Viertelstunde zu früh. >> similarity 0.6182181239128113 Я открыл ворота и подготовил насос бензиновой колонки. Ich schloß das Tor auf und machte die Benzinpumpe fertig. >> similarity 0.7467120289802551 Всегда в это время уже подъезжали заправляться первые машины. Um diese Zeit kamen immer schon ein paar Wagen vorbei, die tanken wollten. >> similarity 0.5018423199653625 Вдруг за своей спиной я услышал хриплое кряхтение, — казалось, будто под землей проворачивают ржавый винт. Plötzlich hörte ich hinter mir ein heiseres Krächzen, das klang, als ob unter der Erde ein rostiges Gewinde hochgedreht würde. >> similarity 0.6064425110816956 Я остановился и прислушался. Ich blieb stehen und lauschte. >> similarity 0.7030230760574341 Потом пошел через двор обратно в мастерскую и осторожно приоткрыл дверь. Dann ging ich über den Hof zurück zur Werkstatt und machte vorsichtig die Tür auf. >> similarity 0.7700499296188354 В полутемном помещении, спотыкаясь, бродило привидение. In dem halbdunklen Raum taumelte ein Gespenst umher. >> similarity 0.7868185639381409
Дальше
Мы получили неплохой результат, в следующий раз мы попытаемся его улучшить и попробуем выровнять текст с участием редкого языка, которого на текущий момент нет в данных моделях. Якутский? Чувашский? Предлагайте и до новых встреч!
[1] Поиграйтесь в Google Colab.
[3] Universal Sentence Encoder.
ссылка на оригинал статьи https://habr.com/ru/post/517226/
Добавить комментарий