Очень часто бывает, когда конверсий много, их цена приемлема, а продажи не растут и даже падают. Здесь аналитики «до прибыли с клика» уже не хватает, чтобы выяснить причину. И тогда на помощь приходит анализ «до прибыли с менеджера». Потому что как бы идеально не была настроена реклама, клиенты сначала взаимодействуют с менеджерами, а уже потом принимают решение. Именно от качества работы сотрудников зависит успешность вашего бизнеса.
Традиционные системы аналитики используют CRM, чтобы зафиксировать факт продажи/обращения с менеджером. Однако такой подход лишь частично решает задачу: оценивает эффективность сотрудника «в сухом остатке». То есть показывает продажи и конверсию, но оставляет «за бортом» само общение с клиентом. А ведь от уровня коммуникаций и зависит результат.
Чтобы заполнить «пробел» мы разработали инструмент, который автоматически свяжет каждый звонок с обработавшим его менеджером. Не придется привлекать CRM и сторонние сервисы. По сути, наша система ставит тег «имя менеджера» на каждый входящий звонок.
Так руководители отдела продаж/клиентского сервиса проконтролируют качество работы, найдут проблемные участки и построят аналитику. В этом поможет быстрое сегментирование звонков на тех менеджеров, которые их принимают.
Постановка задачи
Задача, которую мы поставили себе, звучит следующим образом: пусть системе известны образцы речи всех менеджеров, которые могут принимать звонки. Тогда для нового звонка нужно поставить тег менеджера, голос которого наиболее «похож» в разговоре из списка известных.
При этом априори считается, что новый телефонный звонок успешен. То есть разговор между менеджером и клиентом фактически состоялся. Если говорить неформально, эту задачу можно отнести к классу задач «обучения с учителем», то есть классификации.
В качестве объектов – некоторым образом векторизованные (оцифрованные) аудиозаписи, где звучит только голос менеджера. В роли ответов – метки классов (имена менеджеров). Тогда задача алгоритма тегирования состоит в:
- Извлечении значимых признаков из аудиофайлов
- Выборе наиболее подходящего алгоритма классификации
- Обучении алгоритма и сохранении моделей менеджеров
- Оценке качества работы алгоритма и модификации его параметров
- Тегировании (классификации) новых звонков
Некоторые из этих задач распадаются на отдельные подзадачи. Это связано со спецификой тех условий, в которых должен работать алгоритм. Телефонные звонки, как правило, зашумлены. Клиент в рамках одного разговора может общаться с несколькими менеджерами. Также вообще не состояться, а еще звонки часто включают в себя IVR и т. д.
Например, задача тегирования новых звонков может быть разделена на:
- Проверку звонка на успешность (факт наличия разговора)
- Разделение стерео на моно-дорожки
- Фильтрацию шумов
- Выявление участков с речью (фильтрация музыки и других посторонних звуков)
В дальнейшем мы поговорим о каждой такой подзадаче отдельно. А пока сформулируем технические ограничения, которые мы накладываем на входные данные, полученное решение, а также на сам алгоритм классификации.
Ограничения на решение
Необходимость ограничений отчасти продиктованы техникой и требованиями сложности реализации, а еще – балансом между универсальностью алгоритма и точностью его работы.
Ограничения на входной файл и файлы обучающей выборки:
- Формат – wav или wave (можно далее перекодировать в mp3)
- Стерео необходимо впоследствии делить на 2 дорожки – оператора и клиента
- Частота дискретизации – 16 000 Гц и выше
- Разрядность – от 16 бит и выше
- Файл для обучения модели должен иметь длительность от 30 секунд и содержать только голос конкретного менеджера
- Файл, который тегируется моделью, должен содержать разговор, то есть должен быть успешным
Все указанные выше требования кроме последнего были сформулированы в результате серии экспериментов, которые проводились на этапе настройки алгоритмов. Эта комбинация показала себя самой эффективной с точки зрения минимизации вероятности ошибки, а именно неправильной классификации при необременительных условиях настройки.
Например, очевидно, что чем длиннее файл в обучающей выборке, тем точнее будет классификатор. Но тем сложнее найти такой файл в журнале звонков (нашей обучающей выборке). Поэтому длительность 30 секунд – компромисс между точностью и сложностью настроек. Последнее требование (успешности) необходимо. Система не должна ставить тег менеджера звонку, где фактически не было разговора.
Ограничения алгоритма привели к следующему решению:
- Система всегда ставит тег менеджера в предположении, что звонок успешный. В модели недопустим «неизвестный менеджер». Такой тег не появится. Если в обучающей выборке не был размечен кто-то из менеджеров, то система всегда будет ошибаться.
- Система всегда ставит только один тег для каждого звонка. Если с клиентом общалось несколько менеджеров, то будет выбран тот, кто вел коммуникацию дольше.
Первое требование появилось в результате экспериментов. Тогда выяснилось, что «неизвестный» менеджер усложняет архитектуру решения. Для этого надо подбирать пороги, после которых сотрудник будет классифицирован как «нераспознанный». Также «неизвестный» менеджер уменьшает точность на 10 процентных пунктов.
Кроме того, появляется ошибка второго рода, когда известный менеджер классифицируется как неизвестный. Вероятность такой ошибки – 7-10% в зависимости от числа известных. Это требование можно назвать существенным. Оно обязывает настройщика алгоритма указать в обучающей выборке всех менеджеров. А также вносить туда модели новых сотрудников и удалять уволившихся.
Второе требование проистекает из практических соображений и архитектуры алгоритма, который мы используем. Если кратко, алгоритм разбивает исследуемое аудио на фрагменты с речью и «сравнивает» каждый со всеми обученными моделями менеджеров поочередно.
В итоге «мини-тег» ставится каждому из мини-фрагментов. При таком подходе велика вероятность, что часть фрагментов распознается неверно. Например, если они остались зашумленными или их длина слишком коротка.
Тогда, если в итоговом решении отображать все «мини-теги», то помимо тега реального менеджера, будет отображаться множество «мусорных». Поэтому выводится лишь наиболее «частый» тег.
Описание входных/выходных данных
Входные данные мы разделим на 2 типа:
Данные на входе алгоритма формирования моделей менеджеров (данные для обучения):
- Аудиофайл + метка класса
Данные на входе алгоритма тегирования (данные для тестирования/штатного режима работы):
- Внешние данные (аудиофайл)
- Внутренние данные (сохраненные модели)
Выходные данные также разделяются на 2 типа:
- Выходные данные алгоритма формирования моделей
- Обученные модели менеджеров
- Выходные данные алгоритма тегирования
- Тег менеджера
На вход алгоритму при любом режиме его работы поступает аудиофайл, которые удовлетворяют требованиям. Они есть в разделе «ограничения».
На входе алгоритма формирования моделей допускается, чтобы одному классу (менеджеру) соответствовало несколько входных файлов. Но один файл не может соответствовать нескольким менеджерам. Имя метки класса можно поместить в название файла. Или просто создать отдельный каталог под каждого сотрудника.
Алгоритм обучения моделей на основе входных данных формирует множество моделей, которые можно загружать при обучении. Их количество соответствует числу различных тегов во множестве аудиофайлов.
Таким образом, если имеется M файлов, которые размечены n различными метками классов, то алгоритм на этапе обучения создает n моделей менеджеров:
- Model_manager_1.pkl
- Model_manager_2.pkl
- …
- Model_manager_n.pkl
где вместо «manager_…» указывается имя класса.
На вход алгоритму тегирования поступает неразмеченный аудиофайл, в котором априори присутствует разговор между менеджером и клиентом, а также n моделей сотрудника. В результате алгоритм возвращает тег – имя класса наиболее «правдоподобного» менеджера.
Предобработка данных
Предобработке подвергаются аудиофайлы. Она последовательна и проходит как в режиме тегирования, так и в режиме обучения моделей:
- Проверка успешности звонка – только на этапе тегирования
- Разделение стерео на 2 моно-дорожки и дальнейшая работа только с дорожкой оператора
- Оцифровка – выделение параметров звукового сигнала
- Фильтрация шумов
- Удаление «длинных» пауз – выявление фрагментов со звуком
- Фильтрация фрагментов не с речью – удаление музыки, фона и т. д.
- Склейка фрагментов с речью (только на этапе обучения)
Мы не будем подробно останавливаться на этапе проверки успешности. Это предмет для отдельной статьи. Если кратко, суть этапа состоит в том, что звонок классифицируется согласно тому, есть ли в нем разговор «живых людей». Под «живыми людьми» имеется в виду клиент и менеджер, а не голосовой помощник, музыка и т. д.
Успешность звонка проверяется при помощи специально обученного классификатора с внешним порогом – «минимальная длительность разговора, после которого звонок считается успешным».
На втором этапе происходит разделение стерео-файла на 2 дорожки: менеджера и клиента. В дальнейшем обработка осуществляется только для дорожки сотрудника.
На этапе оцифровки из операторской дорожки извлекаются параметры «фичи», которые представляют из себя цифровое представление сигнала. Мы в Calltouch использовали мел-кепстральные компоненты. Кроме того, извлечение параметров происходит на очень маленьком по длительности фрагменте, которое называется шириной окна (0.025 секунды). Все фичи при этом нормализуются.
nfft=2048 // длина преобразования Фурье appendEnergy = False def get_MFCC(sr,audio): //функция извлечения фич из аудио, sr=16000 - частота features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy) features = preprocessing.scale(features) return features count = 1 features = np.asarray(()) //пустой вектор признаков for path in file_paths: //цикл по всем файлам модели path = path.strip() sr,audio = read(source + path) // считываем аудио vector = get_MFCC (sr, audio) #извлекаем признаки из файла if features.size == 0: features = vector else: features = np.vstack((features, vector))На выходе каждый аудиофайл превращается в массив, в котором построчно записаны мел-кепстральные характеристики каждого фрагмента длительностью 0.025 секунды.
Дальнейшая обработка файла состоит в фильтрации шумов, удалении длинных пауз (а не пауз между звуками), поиске речи. Эти задачи можно решать при использовании различных инструментов. В своем решении мы использовали методы из библиотеки pyaudioanalysis:
clear_noise(fname,outname,ch_n) # для очистки шума.
- fname – входной файл
- outname – выходной файл
- ch_n – число каналов
На выходе получаем файл outname, в который записан очищенный от шумов звук из файла fname.
silenceRemoval(x, Fs, stWin, stStep) # для удаления «длинных пауз»- x – входной массив (оцифрованный сигнал)
- Fs – частота дискретизации
- stWin – ширина окна извлечения признаков
- stStep – величина шага смещения
На выходе получаем массив вида:
[l_1,r_1]
[l_2,r_2]
[l_3,r_3]
…
[l_N,r_N]
где l_i — время начала i-ого сегмента (сек), r_i — время окончания i-ого сегмента (сек).
detect_audio_segment(x,thrs) # извлечение речи.- x – входной массив (оцифрованный сигнал)
- hrs – минимальная длина (в секундах) детектируемого фрагмента с речью
На выходе получаем те фрагменты [l_i,r_i], которые содержат речь длительностью от thrs секунд.
В результате предобработки входной аудиофайл преобразуется к виду массива:
[l_1,r_1]
[l_2,r_2]
[l_3,r_3]
…
[l_N,r_N],
где каждый фрагмент представляет из себя временной интервал очищенного файла с речью.
Таким образом, мы можем каждому такому фрагменту сопоставить матрицу признаков (мел-кепстральных характеристик), которая будет использоваться для обучения модели и на этапе тегирования.
Используемые методы / алгоритмы
Как уже было отмечено выше, наше решение базируется на библиотеке pyaudioanalysis.py, написанной на Python 2.7. Ввиду того, что наше общее решение реализовано на версии Python 3.7, то некоторые функции библиотеки были модифицированы и адаптированы для данной версии языка.
В целом алгоритм инструмента по тегированию менеджеров можно разделить на 2 части:
- Обучение моделей менеджеров
- Тегирование
Более детальное описание каждой части выглядит так.
Обучение моделей менеджеров:
- Загрузка обучающей выборки
- Предобработка данных
- Подсчет числа классов
- Создание модели менеджера для каждого из классов
- Сохранение модели
Тегирование:
- Загрузка звонка
- Проверка звонка на успешность
- Предобработка успешного звонка
- Загрузка всех обученных моделей менеджеров
- Классификация каждого фрагмента обработанного звонка
- Поиск наиболее вероятной модели менеджера
- Проставление тега
Мы уже подробно останавливались на задачах предобработки данных. Теперь рассмотрим методы создания моделей менеджеров.
В качестве модели мы использовали алгоритм GMM (Gaussian Mixture Model). Он моделирует наши данные при предположении о том, что они являются реализациями случайной величины с распределением, которое описывается смесью гауссиан – каждая со своей дисперсией и своим математическим ожиданием.
Известно, что наиболее распространенным алгоритмом поиска оптимальных параметров такой смеси – EM-алгоритм (Expectation Maximization). Он разделяет сложную задачу максимизации правдоподобия многомерной случайной величины на серию задач максимизации меньшей размерности.
В результате серии экспериментов мы пришли к следующим параметрам алгоритма GMM:
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)Такая модель создается под каждого менеджера, и затем она обучается – ее параметры настраиваются на конкретные данные.
gmm.fit(features)Далее модель сохраняется, чтобы ее использовать на этапе тегирования:
picklefile = path[path.find('/')+1:path.find('.')]+".gmm" pickle.dump(gmm,open(dest + picklefile,'wb'))На этапе тегирования мы загружаем сохраненные ранее модели:
gmm_files = [os.path.join(modelpath,fname) for fname in os.listdir(modelpath) if fname.endswith('.gmm')]modelpath – директория, куда мы сохранили модели.
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]А также загружаем имена моделей (это наши теги):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname in gmm_files]Загруженный аудиофайл, для которого нужно поставить тег, векторизуется и предобрабатывается. Далее каждый фрагмент с речью в нем сравнивается с обученными моделями и определяется победитель c точки зрения максимума логарифма правдоподобия:
log_likelihood = np.zeros(len(models)) #начальный пустой вектор правдоподобий for i in range(len(models)): gmm = models[i] #сравнение с каждой моделью scores = np.array(gmm.score(vector)) log_likelihood[i] = scores.sum() #итоговое правдоподобие i модели – сумма правдоподобий winner = np.argmax(log_likelihood) # определяем победителя print("\tdetected as - ", speakers[winner])В итоге наш алгоритм имеет примерно следующий вывод:
starts in: 1.92 ends in: 8.72
[-10400.93604115 -12111.38278205]
detected as — Olga
starts in: 9.22 ends in: 15.72
[-10193.80504138 -11911.11095894]
detected as — Olga
starts in: 26.7 ends in: 29.82
[-4867.97641331 -5506.44233563]
detected as — Ivan
starts in: 33.34 ends in: 47.14
[-21143.02629011 -24796.44582627]
detected as — Ivan
starts in: 52.56 ends in: 59.24
[-10916.83282132 -12124.26855538]
detected as — Olga
starts in: 116.32 ends in: 134.56
[-36764.94876054 -34810.38959083]
detected as — Olga
starts in: 151.18 ends in: 154.86
[-8041.33666572 -6859.14253903]
detected as — Olga
starts in: 159.7 ends in: 162.92
[-6421.72235531 -5983.90538059]
detected as — Olga
starts in: 185.02 ends in: 208.7
…
starts in: 442.04 ends in: 445.5
[-7451.0289772 -6286.66194982]
detected as – Olga
*******
WINNER — Olga
В данном примере предполагается, что есть по крайней мере 2 класса – [ Olga, Ivan]. Аудиофайл разрезан на сегменты [1.92, 8.72], [9.22, 15.72], …, [442.04, 445.5] и для каждого из сегментов определяется наиболее подходящая модель.
Суммарный логарифм правдоподобия указан в скобках рядом с каждым фрагментом: [-10400.93604115 -12111.38278205], первый элемент – правдоподобие Olga, а второй – Ivan. Так как первый аргумент больше второго, то данный сегмент классифицирован как Olga. Итоговый победитель определяется по большинству «голосов» фрагментов.
Результаты
Изначально мы проектировали алгоритм из предположения, что во входящих звонках может присутствовать «неизвестный» менеджер – то есть такой, что его модель не присутствует обучающей выборке.
Чтобы детектировать такого пользователя, нам требуется ввести некоторую метрику на векторе log_likelihood. Такую, что определенные ее значения будут указывать на то, что скорее всего этот фрагмент не описывается адекватно ни одной из существующих моделей. В качестве теста мы предложили следующую метрику:
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood)) -sorted(-np.array(Leukl))[1]<TДанная величина указывает, насколько «равномерно» распределены оценки в векторе log_likelihood. Равномерность оценок (их близость друг к другу) обозначает, что все модели ведут себя одинаково и явного лидера нет.
Это говорит о том, что скорее всего все модели ошибаются и перед нами менеджер, который не был на этапе обучения. Зависимость между T и качеством классификации представлено на рисунках.
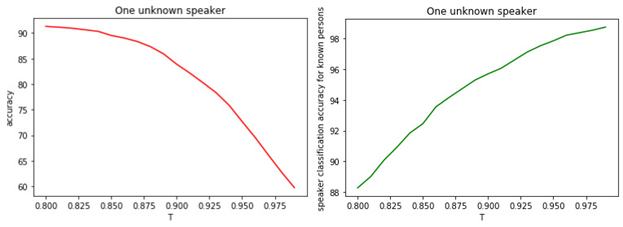
Рис. 1.
а) Точность бинарной классификации известных и неизвестных менеджеров.
б) Точность классификация известных менеджеров.

Рис. 2.
а) Доля известных менеджеров, определенных к классу известных.
б) Доля неизвестных менеджеров, определенных к классу известных.
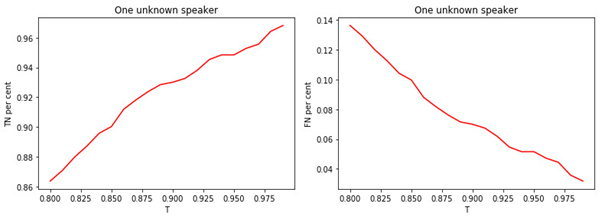
Рис. 3.
а) Доля неизвестных менеджеров, определенных к классу неизвестных.
б) Доля известных менеджеров, определенных к классу неизвестных.
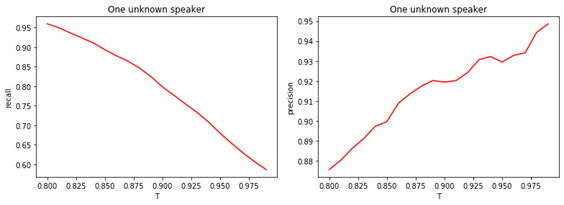
Рис. 4.
а) Полнота бинарной классификации (recall).
б) Точность бинарной классификации (precision).
Зависимость между величиной порога T и качеством классификации (тегирования) очевидна. Чем больше T (более строгие условия на отнесение менеджера к классу неизвестных), тем меньше вероятность отнести известного менеджера к классу неизвестных. Но при этом больше вероятность «пропустить» неизвестного менеджера.
Оптимальным значением порога является величина 0.8. Потому что мы классифицируем известных менеджеров с точностью около 90% и определяем «неизвестных» с точностью 81%. Если же допустить, что все менеджеры нам «знакомы», то точность будет порядка 98%.
Выводы
В статье мы описали общие идеи функционирования нашего инструмента по определению менеджеров в звонках. Конечно, мы не претендуем на то, что наш алгоритм оптимален и не способен улучшаться.
Он основан на ряде предположений, которые не всегда выполняются на практике. Например, можем столкнуться с неизвестным менеджером в том случае, если данные о нем нет. Или же два и более менеджеров могут вести беседу с клиентом «в равных долях». С точки зрения алгоритма, можно предложить следующие направления для дальнейших улучшений:
- Выбор другой модели алгоритма, отличной от GMM
- Оптимизация параметров GMM
- Выбор другой метрики детектирования нового менеджера
- Поиск наиболее значимых фич речевого сигнала
- Комбинация различных средств предварительной обработки аудио и оптимизация параметров этих методов
ссылка на оригинал статьи https://habr.com/ru/post/521430/
Добавить комментарий