
Пандемия и карантин изменили жизнь и поведение практически каждого жителя планеты. При этом некоторые изменения являются краткосрочными и исчезают со снятием карантинных мер, а другие могут остаться с нами надолго, возможно даже навсегда.
Мы в Dentsu Aegis Network в том числе прогнозируем изменения в поведении людей в части потребления видеоконтента, это необходимо для эффективного размещения рекламы наших клиентов в разных медиа. О том, как мы прогнозируем телесмотрение и насколько хорошо у нас это получается в реалиях динамично меняющегося 2020 года, и пойдёт речь в этой статье.
Задача
Специфика размещения рекламы заключается в том, что у каждого бренда есть своя целевая аудитория (ЦА) потенциальных покупателей, до которой нужно донести рекламное сообщение. При этом на ТВ у каждого канала и эфирного события (передачи, кино, рекламы) есть своя аудитория зрителей, которая не всегда совпадает с целевой аудиторией бренда.
Для того, чтобы эффективно разместить рекламную кампанию бренда на ТВ и проконтактировать с как можно большим числом представителей целевой аудитории бренда, нужно выбрать такие рекламные блоки, среди зрителей которых доля целевой аудитории бренда максимальна.
Ради такой оптимизации рекламных кампаний на ТВ мы построили модель, которая прогнозирует размер телесмотрения аудитории каждого рекламного блока, и разработали алгоритм оптимизации, который использует результаты полученного прогноза для эффективного проведения рекламных кампаний.
Давайте рассмотрим нашу модель прогнозирования более подробно.
Для начала нам придётся ввести несколько специфических терминов из области медиа и рекламного рынка:
· Целевая аудитория — это аудитория потенциальных потребителей, интересующая рекламодателя и имеющая определенные характеристики (как правило, речь идет о социально-демографических характеристиках, таких как пол, возраст, доход и т.д., но также могут использоваться психографические и поведенческие характеристики, такие как приверженность брендам или потребление каких-либо продуктов).
· Баинговая аудитория — это аудитория, определяемая телевизионным каналом как ее целевая аудитория. То есть канал определяет свою ЦА и показывает контент, соответствующий этой ЦА.
· TVR рекламного блока — рейтинг рекламного блока, который вычисляется как отношение суммы посмотревших телезрителей из определенной ЦА к сумме телезрителей всей ЦА.
· Affinity рекламного блока — отношения рейтинга рекламного блока, рассчитанного для ЦА бренда, к рейтингу блока, рассчитанного для баинговой аудитории канала (TVR ЦА / TVR баинговой аудитории).
Данные
Для построения прогностической модели на входе мы имели следующие данные.
· Исторические данные о телепросмотре. Мы покупаем данные компании Mediascope, которая измеряет аудиторию ТВ по всей России. Основа измерений – панельное исследование. Данные о телепросмотре собираются среди респондентов, у которых установлены пиплметры (устройства, которые фиксируют информацию о просмотре ТВ) в специальный софт компании. В этих данных содержится поминутная информация о том, какой респондент, что и когда смотрел. Также есть описание самого респондента: пол, возраст, семейное положение, уровень дохода и т.д.
· Сетка вещания с телевизионными передачами и рекламными блоками. Компания Национальный Рекламный Альянс (НРА) как основной продавец телерекламы предоставляет информацию об исторической и будущей телевизионных сетках вещания. Основные данные, используемые в модели: дата и время начала и окончания передачи\рекламного блока, номер рекламного блока в передаче, название и словесное описание и категория передачи (новости, сериал и т.д.). Раз в неделю приходит уточнение сетки на следующую неделю.
В процессе первичного анализа входных данных мы столкнулись с рядом проблем:
· COVID-19. Тут все ясно: люди сидели дома во время самоизоляции, телесмотрение резко увеличилось, потом так же резко снизилось. Телесмотрение в апреле-июле 2020 выросло относительно 2019 года, в августе-сентябре 2020 оно вернулось на прошлогодний уровень, то есть мы видим всплеск ТВ-потребления в карантинные месяца, с последующей возвращением к историческим значениям.

· В 2020 году изменилась география измерения телесмотрения в России. Если раньше мониторилось телесмотрение только в городах с населением от 100 тысяч человек (100+), то начиная с 2020 года в исследование были добавлены и малые города, и населённые пункты с населением менее 100 тысяч человек (100-). Сложность заключается в том, что с точки зрения генеральной совокупности в небольших населенных пунктах (население менее 100 тысяч человек) проживает почти столько же россиян, что и в крупных городах (население более 100 тысяч человек). При этом панелистов в небольших населенных пунктах в силу молодости панели пока меньше, чем в крупных городах. Это приводит к тому, что веса респондентов из малых городов в среднем больше, чем у респондентов из крупных городов, что в свою очередь приводит к изменению распределения TVR.
· Сильное отклонение аффинити на телеканалах с небольшой аудиторией. На таких “малых” каналах средний баинговый TVR блока составляет 0.10. С точки зрения бизнес-смысла нет особой разницы между целевым TVR 0.05 и 0.15 (всё равно очень мало), но аффинити получится 0.05 / 0.10 = 50% или 0.15 / 0.10 = 150%. То есть разница как будто бы огромная.
· Исследовательская панель измерения телесмотрения непрерывно ротируется, а два раза в год происходит обновление весов респондентов по результатам установочного исследования, чтобы выборка оставалась репрезентативной. Это может привести к изменению значений измеряемых характеристик телевизионной аудитории.
· Корректировка сетки вещания в течение дня.
· Много данных
Описание модели:
Так как мы за простоту, то самого начала было решено не использовать громоздкие решения, поэтому выбрали следующий стэк: MS SQL+Python+LightGBM(CPU) – и всё, нет причин усложнять.
Данные мы решили представить в следующем виде: берем только рекламные блоки и считаем по ним TVR, отбрасывая все остальное, нерекламное, время. Сделано это по той причине, что телесмотрение во время передачи сильно отличается от телесмотрения во время рекламы. Поэтому в использовании телесмотрения вне рекламного блока для нашей задачи нет необходимости (без дополнительных расчетов).
Поведение телезрителей постоянно меняется, также панель измерения телесмотрения компании Mediascope изменяется два раза в год. После проведения отдельных исследований решили ограничить горизонт обучения последними 6 месяцами. Конечно, для расчета годовых сезонок используются данные за 4 года, но для сезонки достаточно использовать месячные агрегаты, которые рассчитываются быстро, занимают мало места (12*4*[количество аудиторий=130] *[количество ТВ-каналов=24] = 150тыс. точек) и требуют пересчета только раз в месяц.
В итоге используемые данные здорово уменьшились. Так как в день в среднем 40 блоков на канал, вместо поминутного телесмотрения (60мин*24ч=1440), то есть в 36 раз меньше. Плюс, горизонт обучения всего 6 месяцев (не год и не два).
Прогнозировать нужно минимум на 2 месяца вперед – это требование со стороны бизнеса по объективным причинам. На рынке действует множество конкурирующих агентств, занимающихся размещением рекламы, поэтому нужно закупать блоки заранее, хотя бы на месяц вперед, иначе все раскупят.
И последнее, так как аудитории сильно разные, то для каждой аудитории обучаем отдельно модель со своими расчетами фичей. Всего 130 аудиторий.
До получения текущего варианта модели у нас была модель на другой гранулярности данных и с совершенно иным набором фичей. В какой-то момент мы уткнулись в потолок качества, и ничего лучше сделать не получалось, но глобально мы понимали, что можно прогнозировать точнее и быстрее. Было решено провести генеральное исследование и начать все с чистого листа, с учетом предыдущих проблем и ошибок.
Мы нагенерили множество идей. Что-то сработало, что-то было мимо. Вот основные фичи, которые так и не оправдали наших надежд:
· Избавление от корреляции фичей: PCA и ручное избавление.
· Города 100- . Использовать имеющуюся модель прогноза телесмотрения каждого респондента, чтобы выделить только респондентов 100-. Расчет оказался слишком медленным при весьма небольшом улучшении качества прогноза.
· Anomaly detection. Удаление аномально высоких\низких TVR во временном ряде. Также пробовали isolation forest — тоже не помог.
· Сезонки для каждого ТВ-канала.
Финальный набор фичей:
· Общие фичи: длительность передачи, длительность блока, описание передачи, ТВ-канал, день недели, день месяца, время с точностью до 30 минут, как давно существует передача (например, “Поле чудес”), праздничные дни. Здесь много категориальных переменных, поэтому использовали для них обычные техники обработки .
· Сезонки и тренды с учетом изменения весов. Производим декомпозицию временного ряда для каждой аудитории, реализованную вручную:
1. Получение тренда
a. Сначала строим линейную регрессию с dummy месяцев + фича с количеством уникальных респондентов “100-”, которые были заявлены в базе в течение соответствующего месяца, помноженная на dummy месяца.

b. Из полученной модели выделяем все остатки – получаем ряд, в котором нет сезонки.

c. Итоговый ряд остатков аппроксимируем кубическим сплайном. Получаем искомый тренд.

2. Используя полученный в п.1 тренд + dummy месяцев + фича с количеством уникальных респондентов “100-” (которые были заявлены в базе в течение соответствующего месяца), помноженная на dummy месяца, строим линейную регрессию.

3. Коэффициенты при dummy месяцев используем в качестве значений сезонки: собираем в единый ряд. Получаем чистую сезонку, без “100-”, и используем как единую фичу.

4. Используя тренд из п.3 + чистую сезонку + количество респондентов «100-», помноженное на чистую сезонку, строим линейную регрессию. Получаем веса регрессоров.

5. Конечный ряд сезонки (прогнозный!) равен сумме: чистая сезонка + количество респондентов «100-», помноженное на чистую сезонку и взятое с весами из линейной регрессии.

· COVID-19.
1. Берем понедельное отношение суммы времени телепросмотра блоков респондентами к количеству блоков.

2. Разбиваем полученный временной ряд на стадии самоизоляции:
a. 2020-03-05 — “первое” заражение России
b. 2020-03-25 — обращение президента
c. 2020-03-28 – как будто выходные
d. 2020-04-06 — строго сидим дома
e. 2020-06-01 — снятие самоизоляции для некоторых категорий граждан
f. 2020-06-14 — полное снятие ограничений

3. Прогнозируем временной ряд из п.1 линейной регрессией от одного регрессора — стадии самоизоляции. Этот прогноз используем как конечную фичу.
Такой подход дал нам следующее:
· Здорово описал уже произошедшие изменения,
· Но и не позволил модели сильно оверфититься на этих знаниях,
· И поможет модели (сильно надеемся) быстро перестроить прогнозы в случае новой волны самоизоляции, в зависимости от вида самоизоляции.
Да, в этих данных сидит много лишней информации (например, сезонка). В идеале нужно избавиться от этого шума, но пока даже такой подход здорово уточнил модель. Можете сравнить качество до и после в boxplot (ниже) от 2 и 4 сентября.
· Клиппирование по аффинити.
1. Берем 95 квантиль исторического фактического аффинити (целевой аудитории к баинговой) для каждого канала в каждой аудитории. Считаем, что это максимальные значения аффинити.
2. Производим обратное преобразование: фиксируя прогнозный TVR блока для баинговой аудитории и максимальный аффинити канала (из п.1), рассчитываем максимально возможный TVR блока целевой аудитории.
3. Если прогнозный TVR блока выше максимально возможного в этой аудитории, то приравнять максимально возможному.
· Замена TVR на log(TVR+1). В качестве целевой прогнозируем не TVR, а его логарифм. После построения модели и получения прогнозных значений обратно переводим в абсолютное значение.
В качестве развлечения предлагаем вам самим поиграть с данными и построить свою модель. Вполне возможно, что вы найдете какие-то новые инсайты.
https://download.dentsuaegis.ru/index.php/s/emtvlKKdPkUCdvn
Технические сложности и их решение
Для нас как Machine Learning Engineer отдельным челеджем было написать код на уровне developer. Будучи ML Engineer от нас изначально ожидается знание основ ООП и Clean Code Paradigm, однако даже на уровне разработчика бывает качественный код и не очень. Мы решили отнестись серьезно к написанию кода и часто консультировались с нашими архитекторами и Data Engineer’ами. Хотелось бы отдельно поделиться с двумя решениями, которые здорово ускорили работу кода: кастомная запись данных на MS SQL server и непрерывная работа скрипта.
Во-первых, запись данных на MS SQL. Методы записи реализованы в большом количестве библиотек. Один лишь SQLAlchemy имеет три варианта записи. Однако в результате тестирования, оказалось, что все они работают очень медленно и здорово тормозят весь код (возможно, это только с MS SQL так?). Но главное: заливка падала с deadlock’ом, когда пытались лить данные в конечную таблицу асинхронными трэдами. Как следствие, пришлось по крупицам узнавать хитрости и в итоге написать собственный метод записи, который использует классическую либу pyodbc. Метод состоит из трех хитростей:
1. Создаем временную таблицу без индексов (это важно) и льем туда данные параллельными трэдами. Так как нет индексов и constraints, параллельное записывание не падает с ошибкой race condition или deadlock.
2. Запись реализовать не построчно, а бакетами. Оказалось, что есть существенная разница в скорости между этими двумя конструкциями:
a. Insert into table(col1,col2) values (1,1);
Insert into table(col1,col2) values (1,2);
b. Insert into table(col1,col2) values
(1,1),
(1,2);
Оказывается, вариант а) пишет построчно как 2 отдельные транзакции, тогда как вариант б) выполняется как одна транзакция, бакетами. Но таких строк может быть до 1000 в бакете.
3. Для заливки\обновления данных из временной таблицы в конечную использовать merge tables с соответствующими индексами в target table (ускорение за счет использования индексов в target table).
В итоге скорость записи увеличивается во много раз. От 2 до 10 раз — смотря с каким методом записи сравнивать. Можете потестить сами, но чувствую, у вас здесь будет много сомнений — готов обсудить в комментах. И повторюсь, что, скорее всего, это работает эффективнее только с MS SQL.
Во-вторых, непрерывная работа скрипта. Дело в том, что сетка вещания часто корректируется: ежечасно появляются новые рекламные блоки со своим описанием. И мы, конечно, хотим как можно раньше решить, подходит ли нам этот новый блок и в какую кампанию. То есть нужно как можно скорее построить прогноз для новых блоков. Для этого реализовали следующий подход:
-
Обучаем модель раз в день, пересчитав все фичи, пишем\перезаписываем прогноз на два месяца вперед. Далее храним (точнее, не выгружаем) модель и ее окружение в памяти.
-
Раз в час проверяем наличие новых блоков и строим по ним прогноз по обученной модели из п.1.
Контроль качества модели
Телесмотрение меняется ежедневно и зависит от множества факторов, в том числе и ненаблюдаемых в данных. Поэтому требуется постоянно держать руку на пульсе. То есть нужна отчетность на ежедневной основе. Для этого мы раз в неделю сохраняем прогнозы на два месяца вперед в отдельную таблицу. Далее ежедневно подгружаем фактическое телесмотрение и считаем ошибку. Отчетность смотрим в tableau. Данные и отчет, конечно, собираются автоматически, но на результаты смотрим пока глазами, до автоматизации анализа ошибок руки не дошли. В качестве метрики ошибки выбрали формулу avg[(fact – predict) / (fact +predict +epsilon)]. Затем смотрим boxplot и просто почасовое среднее этой ошибки. Причин такого подхода множество. Вот основные:
· Распределения TVR сильно отличаются в каждом канале. Поэтому метрики типа R_squared не подходят – там используется единая дисперсия.
· Внутри канала выходные\рабочие и день\ночь имеют сильно разное распределение
· Гетероскедастичность прогноза — увеличение дисперсии ошибки с увеличением значения TVR.
· Желание отличать перепрогноз от недопрогноза – безопаснее недопрогнозить, чем перепрогнозить.
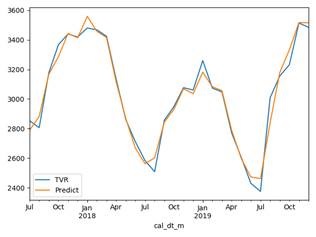
Эволюция развития качества прогноза.
Прогноз, составленный 22 июля дает много ошибок. Далее почти в каждом следующем прогнозе происходит улучшение качества за счет добавления новых фичей. Особенно это видно при сравнении 2 и 4 сентября: даты почти одинаковые, но разница ошибок очевидна.

Почасовая проверка качества:

Направления развития модели
· Особые выпуски (финалы, особые чемпионаты и т.д.).
· Конкуренция ТВ-каналов: если на одном из ТВ-каналов транслируется популярная программа, то остальные ТВ-каналы проседают (в разной степени).
· Каналы с небольшой аудиторией: сложно прогнозировать TVR блока на 2 месяца вперед, если изменение поведения небольшого количества респондентов значительно влияет на все показатели.
· Ночное время — см. предыдущий пункт.
ссылка на оригинал статьи https://habr.com/ru/company/dentsuaegisnetworkrussia/blog/521558/
Добавить комментарий