Для формирования нужного отчета с заданной периодичностью достаточно написать соответствующий настраиваемый Report-ресурс.
Сценарии использования
Настраиваемые отчеты Metering бывают нужны, например, в следующих случаях:
- В кластере OpenShift, который не относится к категории продакшн, исполнительные узлы (worker nodes) не обязаны работать все время. Часть из них может отключаться на выходные или в зависимости от количества доступных ресурсов. В этом случае администратору пригодились бы месячные отчеты по использованию CPU или памяти, чтобы люди, отвечающие за ИТ-инфраструктуру, могли выставлять счета пользователям или вести учет потребления ресурсов, отталкиваясь от реальной картины загрузки узлов.
- Для команд или подразделений часто развертываются выделенные кластеры OpenShift. В этом случае оператор Metering, конечно, предоставит данные по использовании узлов, но при выставлении счетов хотелось бы знать, какой именно команде или подразделению выделен тот или иной исполнительный узел. Этот вариант использования также может быть расширен, чтобы получить аналогичные сведения в ситуации, когда у нас есть кластер общего пользования и в нем есть узлы с меткам, где прописаны владельцы выполняющихся на этих узлах нагрузок.
- Кроме того, в ситуации с кластерами общего пользования отделу эксплуатации пригодилась бы возможность вести учет в разрезе команд и подразделений по суммарному времени работы принадлежащих им подов (или по тому, сколько на это ушло ресурсов CPU или памяти). Иначе говоря, нас опять интересует информация о том, кому принадлежит тот или иной под.
Для решения этих задачи в кластере достаточно создать определенные настраиваемые ресурсы, чем мы и займемся дальше. Установка оператора Metering выходит за рамки этой статьи, поэтому при необходимости советуем обратиться к документации по установке. Подробнее узнать о том, как использовать штатные отчеты Metering, можно в соответствующей документации.
Как работает Metering
Прежде чем создавать настраиваемые ресурсы, разберемся немного с Metering. После установки он создает шесть типов настраиваемых ресурсов, из которых мы остановимся на следующих:
- ReportDataSources (RDS) – этот механизм позволяет задать, какие данные будут доступны и могут использоваться в ReportQuery или в настраиваемых ресурсах Report. RDS также позволяет извлекать данные из нескольких источников. В OpenShift данные извлекаются из Prometheus, а также из настраиваемых ресурсов ReportQuery (RQ).
- ReportQuery (rq) – содержит SQL-запросы для анализа данных, хранящихся в RDS. Если на RQ-объект ссылается объект Report, то RQ-объект также будет управлять тем, о чем он будет рапортоваться при запуске отчета. Если на RQ-объект ссылается RDS-объект, то RQ-объект скажет оператору Metering создать объект view в таблицах Presto (создаются при установке Metering) по результатам запроса.
- Report – этот настраиваемый ресурс триггерит формирование отчетов, согласно тому, что задано в конфигурации ресурса ReportQuery. Это, собственно, и есть основной ресурс, с которым взаимодействует конечный пользователь Metering. Запуск ресурса Report можно настроить по расписанию.
Из коробки доступно множество RDS и RQ. Поскольку нас в первую очередь интересуют отчеты на уровне узлов, то рассмотрим те из них, которые помогут написать свои настраиваемые запросы. Запустите следующую команду, будучи в проекте «openshift-metering»:
$ oc project openshift-metering $ oc get reportdatasources | grep node node-allocatable-cpu-cores node-allocatable-memory-bytes node-capacity-cpu-cores node-capacity-memory-bytes node-cpu-allocatable-raw node-cpu-capacity-raw node-memory-allocatable-raw node-memory-capacity-raw Здесь нам интересны два RDS: node-capacity-cpu-core и node-capput-capacity—capacity-raw, поскольку мы хотим получить отчет о потреблении ресурсов CPU. Начнем с node-capacity-cpu-core и запустим следующую команду, чтобы посмотреть, как он собирает данные из Prometheus:
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml <showing only relevant snippet below> spec: prometheusMetricsImporter: query: | kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id) Здесь мы видим Prometheus-запрос, который извлекает данные из Prometheus и сохраняет их в Presto. Выполним этот же запрос в метрик-консоли OpenShift и посмотрим результат. У нас есть кластер OpenShift с двумя исполнительными узлами (worker nodes, каждое на 16 ядер) и тремя мастер-узлами (master nodes, каждое на 8 ядер). Последний столбец, Value, содержит количество ядер, назначенных узлу.

Итак, данные получены и сохранены в таблицы Presto. Теперь посмотрим настраиваемые ресурсы reportquery (RQ):
$ oc project openshift-metering $ oc get reportqueries | grep node-cpu node-cpu-allocatable node-cpu-allocatable-raw node-cpu-capacity node-cpu-capacity-raw node-cpu-utilization Здесь нас интересуют следующие RQS: node-cpu-capacity и node-cpu-capacity-raw. По названию видно, что эти метрики содержат как описательные данные (сколько времени работает узел, сколько ему выделено процессоров и т.д.), так и агрегированные данные.
Между собой интересующие нас два RDS и два RQS связаны следующей цепочкой:
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
Настраиваемые Reports
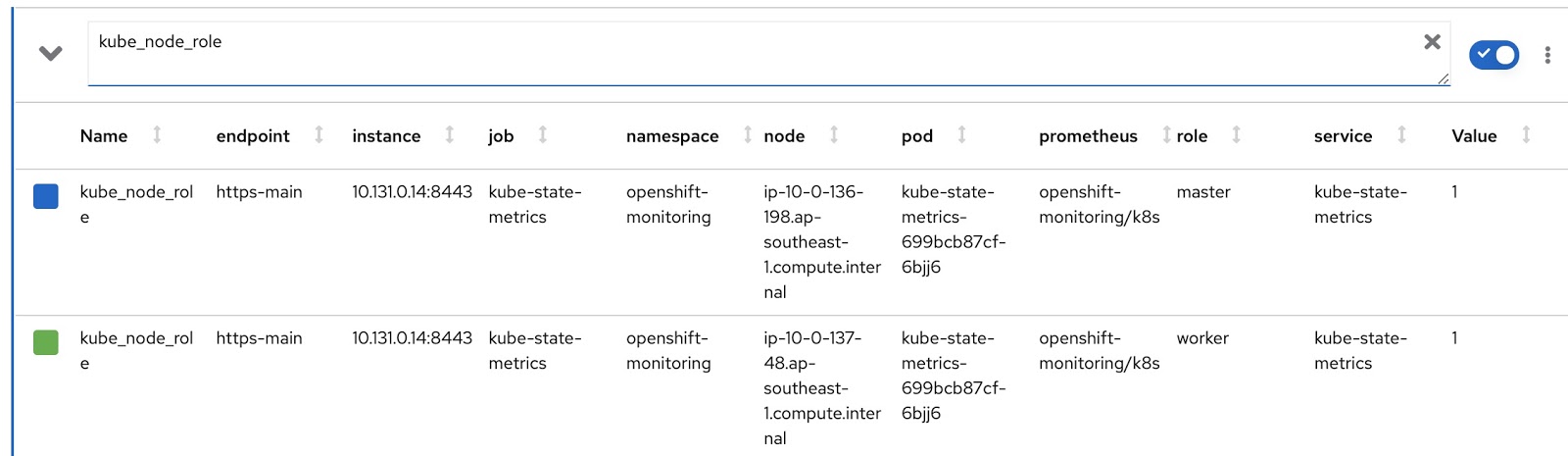
Теперь напишем свои, кастомизированные версии RDS и RQ. Нам надо изменить Prometheus-запрос так, чтобы он отображал режим работы узла (master/worker) и соответствующую метку узла, в которой указано, какой команде принадлежит этот узел. Режим работы узла содержится в Prometheus-метрике kube_node_role, см. столбец role:
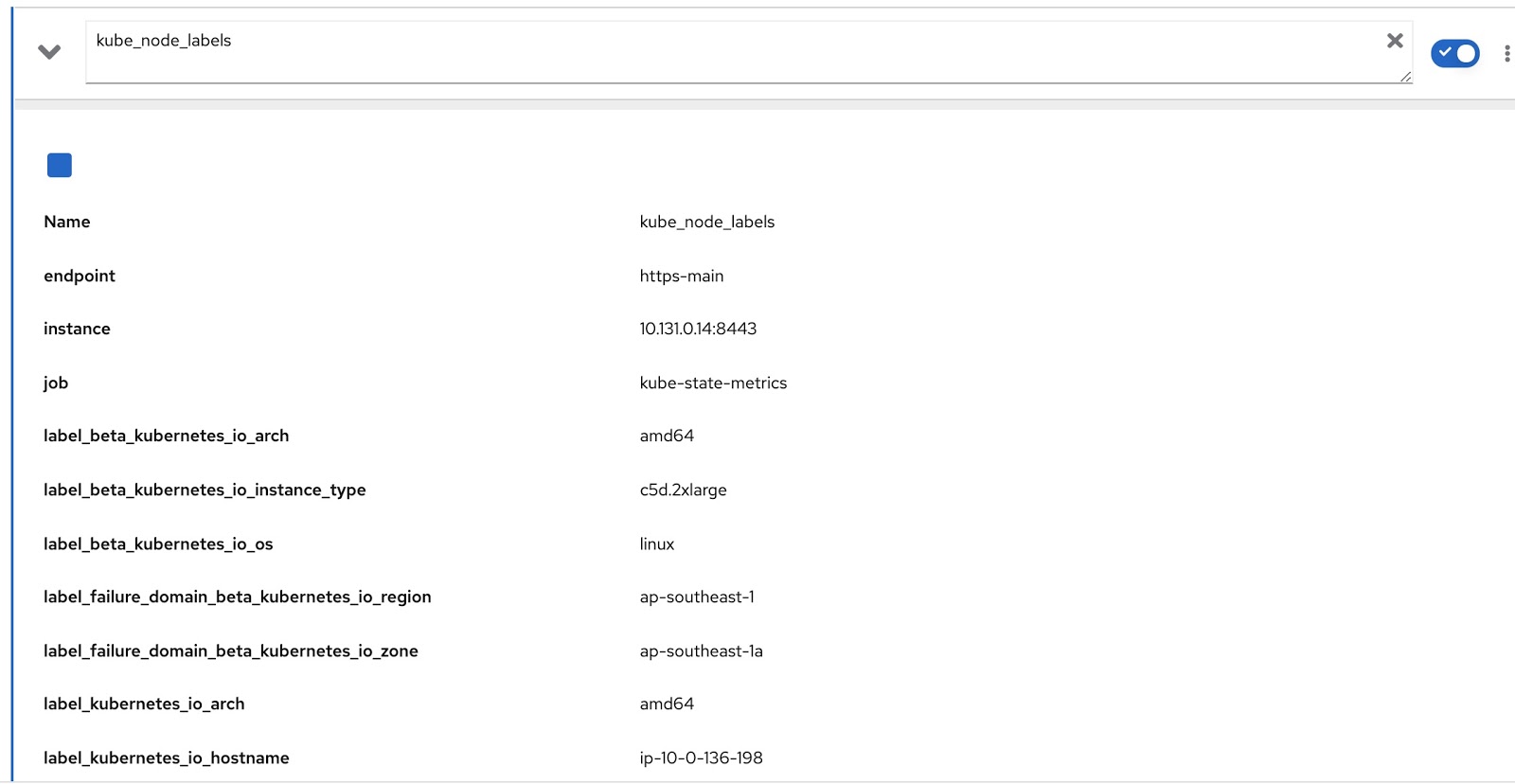
А все присвоенные узлу метки содержатся в Prometheus-метрике kube_node_labels, где они формируются по шаблону label_. например, если у узла есть метка node_lob, то в Prometheus-метрике она отобразится как label_node_lob.
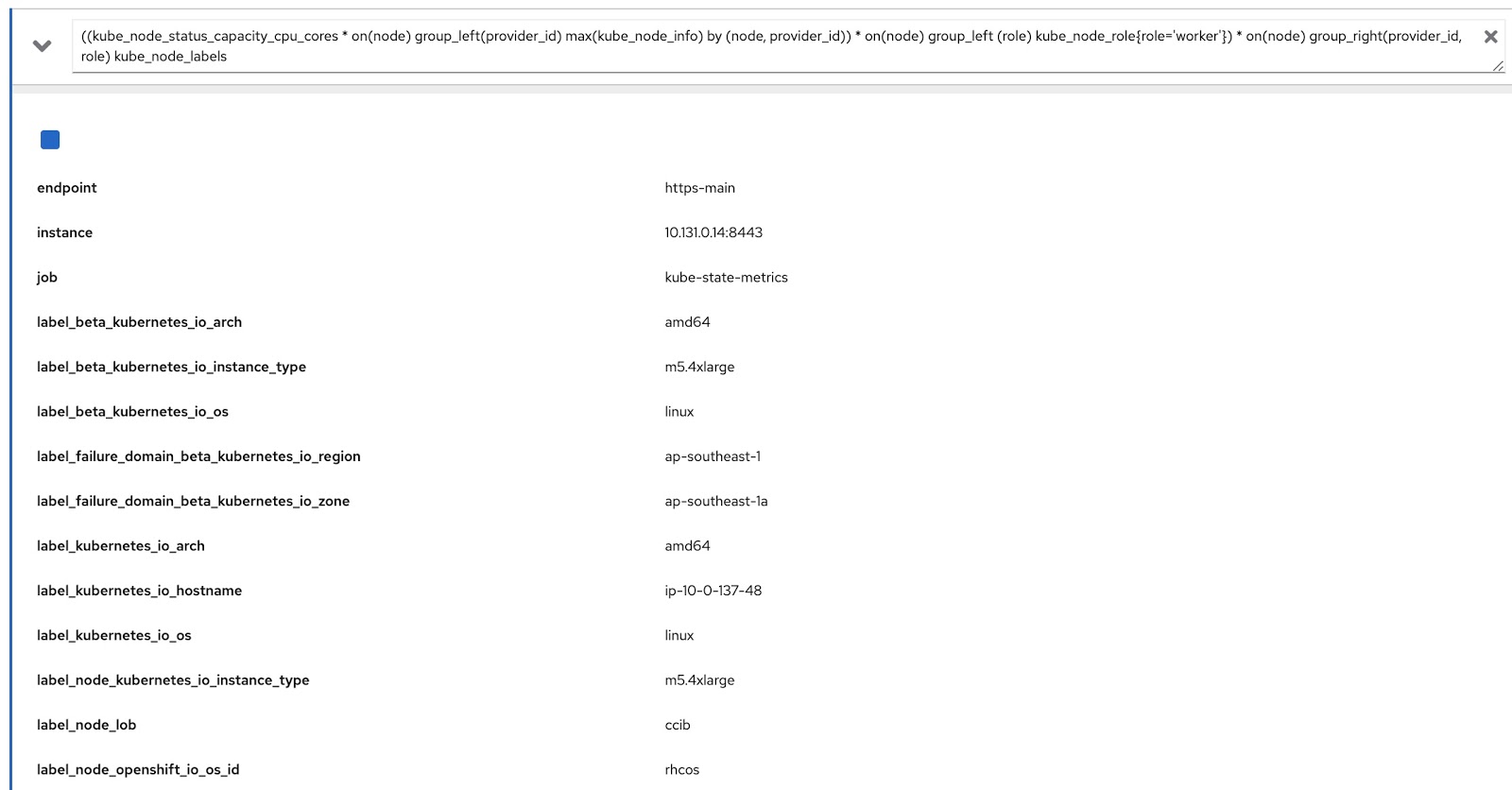
Теперь нам остается только модифицировать исходный запрос с помощью этих двух Prometheus- запросов, чтобы получить нужные нам данные, вот так:
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels Теперь запустим этот запрос в метрик-консоли OpenShift и убедимся, что он выдает данные как по меткам (node_lob), так и по ролям. На картинке ниже это, во-первых, label_node_lob, а также роль (она там есть, просто не попала на скриншот):
Итак, нам надо написать четыре настраиваемых ресурса (вы можете скачать их из списка ниже):
- rds-custom-node-capacity-cpu-cores.yaml – задает Prometheus-запрос.
- rq-custom-node-cpu-capacity-raw.yaml – ссылается на запрос из п.1 и выдает raw-данные.
- rds-custom-node-cpu-capacity-raw.yaml – ссылается на RQ из п.2 и создает в Presto объект view.
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml – ссылается на RDS из п.3 и выдает данные с учетом введенных дат начала и конца отчета. Кроме того, в этот же файл извлекаются столбцы роли и меток.
Создав эти четыре yaml-файла, переходим в проект openshift-metering и выполняем следующие команды:
$ oc project openshift-metering $ oc create -f rds-custom-node-capacity-cpu-cores.yaml $ oc create -f rq-custom-node-cpu-capacity-raw.yaml $ oc create -f rds-custom-node-cpu-capacity-raw.yaml $ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml Теперь осталось только написать настраиваемый Report-объект, который будет ссылаться на RQ-объект из п.4. Например, это можно сделать так, как показано ниже, чтобы отчет запустился немедленно и выдал данные с 15 по 30 сентября.
$ cat report_immediate.yaml apiVersion: metering.openshift.io/v1 kind: Report metadata: name: custom-role-node-cpu-capacity-lables-immediate namespace: openshift-metering spec: query: custom-role-node-cpu-capacity-labels reportingStart: "2020-09-15T00:00:00Z" reportingEnd: "2020-09-30T00:00:00Z" runImmediately: true $ oc create -f report-immediate.yaml После выполнения этого отчета файл результатов (csv или json) можно загрузить со следующего URL (только замените DOMAIN_NAME на свое):
Как видно на скрине CSV-файла, в нем есть и role, и node_lob. Чтобы получить время работы узла в секундах, надо разделить node_capacity_cpu_core_seconds на node_capacity_cpu_cores:

Заключение
Оператор Metering – это классная штука для кластеров OpenShift, развернутых где угодно. Предоставляя расширяемый фреймворк, он позволяет создавать настраиваемые ресурсы для формирования нужных вам отчетов. Все исходные коды, используемые в этой статье, можно загрузить здесь.
ссылка на оригинал статьи https://habr.com/ru/company/redhatrussia/blog/525562/
Добавить комментарий