Потребности заказчика можно выразить следующими характеристиками желаемого профилировщика:
- иметь инструмент анализа производительности для определенного набора архитектур;
- иметь возможность делать глубокий анализ производительности с точностью до инструкции в дизассемблированном коде;
- иметь средство просмотра и работы с выводом дизассемблированного кода в удобном GUI для такого набора архитектур — x86_64, ARMv7, ARMv8.
То есть требовался профилировщик, который должен:
- быть кросс-платформенным;
- уметь генерировать дизассемблер для функций для архитектур из этого набора — x86_64, ARMv7, ARMv8;
- отображать результаты и взаимодействовать с пользователем через GUI и поддерживать юзабилити.
Для удовлетворения потребностей заказчика, нами был разработан новый компонент системы — кросс-платформенный дизассемблер с генерацией кода для x86_64, ARMv7, ARMv8 (функциональность и GUI для работы с его выводом).
Посмотрим на примере простого демо С++ кода на Hotspot в действии и возможности для анализа производительности, которые он предоставляет. Пример:
cat demo.cpp: #include <iostream> int g (int arg) { return abs(rand()) * arg; } int f() { int i = 1; int res = 1 ; std::cout << abs(rand()) << std::endl; while (i < 1000000) { res += i * g(res); i++; } std::cout << res << std::endl; return res; } int main() { std::cout << f() << std::endl; return 0; }Компилируем, собираем наше демо-приложение:
g++ demo.cpp -o demoЗапускаем наш профилировщик:
./hotspotШаг 1 — собираем и записываем данные в perf.data файл.
Это можно сделать двумя способами — с командной строки при помощи явного вызова perf
record -o /home/demo/perf.data --call-graph dwarf ./demoЛибо при помощи Hotspot меню File->Record Data.
Для нашего демо собираем события типа cycles, но можно задать любой другой или набор типов событий (cache-misses, instructions, branch-misses и др.)

Жмем Start Recording, ждем, пока загорится View Results:

Погружаемся в мир анализа производительности.
Здесь нас ждет сводная информация и чемпионы среди потребителей времени исполнения нашего demo.

Цепочки вызовов в обоих направлениях – от вызываемого к вызывающему методу (Bottom Up) и наоборот (Bottom Down) с временами (весами).


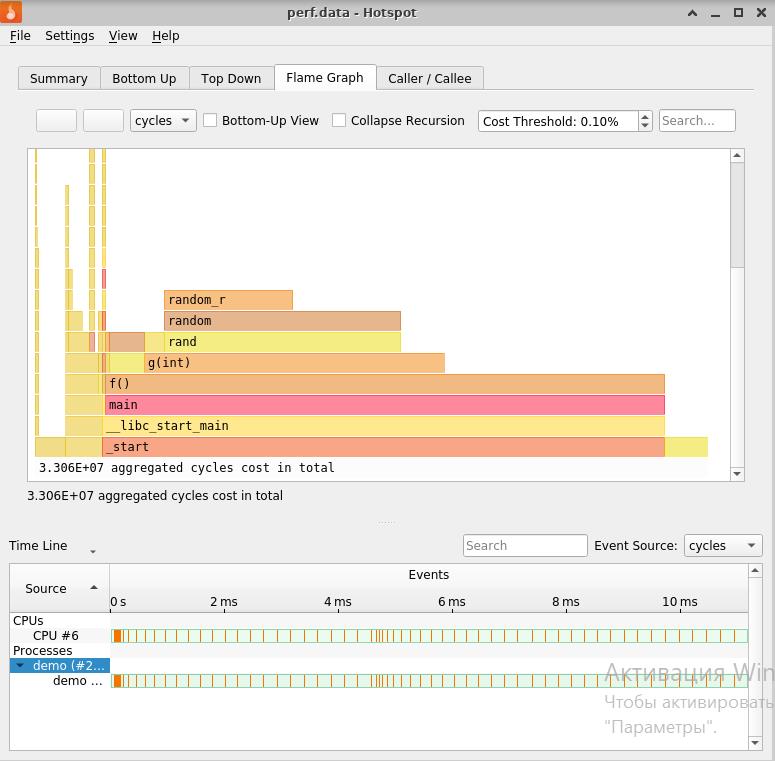
Flame Graph и данные о производительности, времени исполнения по каждой
значимой для него функции/методу.
Чтобы получить более детальную информации о заинтересовавшей нас функции, с распределением событий внутри нее (с точностью до инструкции дизассемблированного кода), жмем Disassembly пункт контекстного меню. Оно открывается по right-click на приглянувшейся функции:

Теперь мы знаем об этой функции все!

Можно перемещаться по стеку вызовов. Двойной щелчок мыши на подсвеченной синим цветом инструкции вызова. И перед нами дизассемблер для вызываемой функции g(int). Здесь у инструкции, потребляющей процессорное время, нет конкурентов.

Ctrl+B, Ctrl+D — и перед нами еще и машинные коды команд, а дизассемблер сгенерирован при помощи objdump. В предыдущих случаях был показан код, полученный вызовом perf annotate.

Загорелась кнопка Back, можно двигаться по стеку вызовов в обоих направлениях!
Переходим и двойным щелчком мыши по инструкции с адресом 1236 перемещаемся на инструкцию с адресом 124f. И снова доступен переход обратно на инструкцию с адресом 1236.

Ctrl+B, Ctrl+I переключает нас на Intel синтаксис Ассемблера:

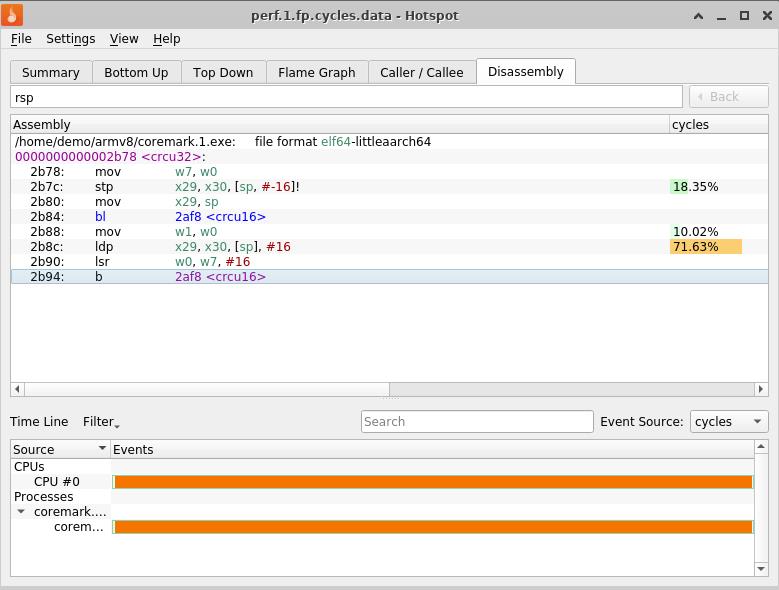
Порадуемся возможности поискать текст по введенному шаблону, например, использование регистра %rsp:

И…не сходя с места, перемещаемся на ARM. Для этого нам понадобятся, в основном, две сущности – исполняемый файл пользовательского приложения, собранный на ARM, и perf.data файл для него, записанный там же. В нашем демо – это coremark.1.exe и perf.1.fp.cycles.data, собранные на ARMv8. Кладем их в /home/demo/armv8/ и загружаем perf.data –

Таким образом, мы не только выполнили поставленные заказчиком задачи, но и перевыполнили их – в частности, вычисление и отображение распределения событий по инструкциям дизассемблера позволяет делать глубокий анализ с точностью до инструкции, которую можно связать со строкой в коде, программа имеет GUI — удобный интерфейс с настройками кросс-профилирования.
По договоренности с нашими партнерами Linux perf gui Hotspot распространяется на условиях GNU General Public License (Открытое лицензионное соглашение GNU). Иными словами, мы предоставляем всем желающим пользователям право бесплатно копировать, модифицировать и распространять эту программу-профилировщик.
Вместе с инструкцией по скачиванию и установке он размещен на GitHub. Все желающие могут с ним ознакомиться и оценить по достоинству.
Приглашаем и вас, взяв в путеводители Linux Perf GUI (Hotspot), в увлекательное путешествие по вашему приложению и особенностям его работы, окунуться в элитную атмосферу ассемблерных команд, посетить различные архитектуры и многое другое.
ссылка на оригинал статьи https://habr.com/ru/post/525560/
Добавить комментарий