Привет!
У нас есть огромные ночные отчёты по продуктовым метрикам, которые с утра попадают их владельцам. Пару лет назад они собирались обычным Cron’ом, но это оказалось очень нестабильной историей. Cron требует учёта определенных нюансов и дисциплины: если отчёт не собрался, то нужно перезапустить скрипт. А не собраться он может по многим причинам: одна из MySQL-баз не ответила, или не ответил опрашиваемый сервис, или сервер, на котором работает Cron, ночью перезагружался или вышел из строя. В большинстве своём такие отчеты создавались аналитиками, которые обычно всего этого не учитывали. Потому что они аналитики и это не их задача. Поэтому мы начали искать варианты, которые упростят жизнь всем.
И нашли.

В финальном решении используется планировщик Airflow с его возможностью взаимодействия с кластером Kubernetes. Система получилась гибкая и надежная и упрощает жизнь конечным потребителям. Для разработки таких систем есть мы, техническая команда из четырёх человек, называемая Data Team, а конечные потребители – аналитики, продакт-менеджеры и техлиды.
Что и как считается
Чаще всего – данные продаж, разные этапы действий пользователей, метрики приложений и сайта и так далее. Отчёты – не единственное средство посмотреть, что происходит с продуктом, есть ещё отдельный мониторинг критичных систем с уведомлениями в различные каналы связи. Тем не менее отчёты очень важны, и не только менеджерам, но и техлидам, потому что в отчётах важные продуктовые метрики, которые позволяют определять планирование технических задач для команды. Например, в день, когда поезда ППК вышли в отдельный шлюз, пришло уведомление в соответствующий чат с техническими проблемами, но именно ночной отчёт по продажам позволяет сразу понять, на сколько ситуация критична – необходимо всё бросать и чинить или возможно устранить проблему в штатном режиме, не нарушая текущих планов команды.
Какие были проблемы
В далёкие времена все отчёты делали разработчики продуктов. Нужны продукту отчёты – их делает его разработчик. Это был плохой подход: создание нового отчёта было медленным и дорогим, так как приходилось отвлекать разработчиков от реализации продуктовых фичей. Кроме этого, отчёты обитали в production-окружении, использовали боевые базы, создавая на них нездоровую ночную нагрузку. Постепенно отчётами стали заниматься аналитики, в распоряжении которых были реплики боевых баз данных. Помимо реплик для них постепенно наливалось озеро данных, которое для отчётов было даже удобнее. Такой подход оказался благоприятным и привел к экспоненциальному росту количества отчетов.
Когда отчёты стали быстрыми в разработке, продакт-менеджеры захотели очень много всего: разные отчёты с разной регулярностью. Аналитики оперативно собирали файлик с логикой на python, скармливали его Cron’у и уходили. Никто не думал о ревью, хороших практиках написания и сопровождения отказоустойчивого кода. И это неудивительно, так как аналитики хороши в анализе данных, а писать поддерживаемый код – задача разработчиков. В итоге отчёты были нестабильными: либо не собирались вовсе, либо, что ещё хуже, собирались частично и с вероятно недостоверными показателями.
DataTeam решила разобраться со всеми проблемами на уровне инфраструктуры. Путь был тернистым, но результат стоит проделанной работы.
Примечание: Далее контекст повествования уходит от отчётов и будет использоваться термин «задача», под которым понимается любая атомарная логика, которая может быть запущена по расписанию.
С чего все начиналось
Запустить что-то в определённое время или определённое количество раз за некий интервал времени – очень частая необходимость. Первый, самый очевидный и, скорее всего, подходящий вариант – использовать планировщик операционной системы. Как правило, это инструмент, который прост и надёжен, как топор. Если, конечно, вы не решили забивать обухом гвозди и лезвие не проносится в миллиметрах от вашей головы. Тот же Cron работает на одном сервере и встроен в ОС. Для запуска задачи по расписанию нужно только завести исполняемый скрипт с логикой задачи и сообщить планировщику, что этот скрипт следует запускать по расписанию.
Но сервер с Cron’ом состоит из одного узла. Сервер может выйти из строя в момент выполнения задачи или, что вероятнее, его просто отключили для проведения каких-либо профилактических работ. А у Cron’а нет механизма резервирования состояния запущенных задач. После восстановления сервера задача, выполнение которой прервалось, не будет перезапущена. Остается только ждать следующего запуска по расписанию или запускать руками.
Выход из строя сервера – далеко не единственная проблема, которая может прервать выполнение. В нужный момент может быть недоступна база данных или сервис, на который идет запрос, либо просто могут быть сетевые проблемы. Но тут уже всё зависит от самой задачи: чем больше в ней потенциальных точек отказа, тем выше вероятность, что что-то пойдёт не так и задача не будет выполнена вовремя. В какой-то степени риски нивелируются более регулярным запуском задач (такое можно позволить, только если задача является идемпотентной). Чем чаще запускается задача, тем выше шанс её успешного выполнения.
Повышаем надежность системы
Ограничения, вызванные ненадёжностью одиночных серверов (не только в вопросах регулярного запуска задач), давно решаются кластерными системами. У нас есть кластер Kubernetes’а. Там свой собственный планировщик, который называется CronJob. Из названия можно предположить, что принципиально он ничем не отличается от классического Cron’а. Но это не так: в первую очередь, CronJob запущен в кластере, и выход из строя одного узла не помешает запуску задач по расписанию. Для этого выйти из строя должен весь кластер, что тоже возможно, но менее вероятно. Помимо этого, Cron гарантирует запуск задачи строго один раз в указанный в расписании момент времени, согласно системным часам сервера. CronJob обещает запустить задачу «примерно» один раз согласно указанному расписанию (из документации: A cron job creates a job object about once per execution time of its schedule. Подробнее). «Примерно» означает, что в момент предполагаемого запуска задача может быть запущена более одного раза или не запущена вообще. Такое ограничение обязывает делать задачи идемпотентными. Ещё CronJob позволяет определять политики перезапуска и конкурентного запуска задач. Про это так же можно прочитать в документации.
Кажется, с появлением кластера Kubernetes’а гарантии выполнения задач строго по расписанию всё ещё нет. Это не значит, что CronJob бесполезный, мы им достаточно активно пользуемся для запуска небольших атомарных задач, которые необязательны к выполнению с точностью швейцарских часов. Если задача не запустилась сейчас – ничего критичного, запустится в следующий раз. Но есть задачи с более высокими требованиями к запуску, когда нужны гарантии, что задача запустится хотя бы один раз согласно расписанию, пусть и с некоторыми погрешностями во времени. Более того, запуск задачи должен зависеть от выполнения определённых предусловий, например, нужно убедиться, что какие-то предыдущие задачи, которые подготавливают данные для текущей, выполнились успешно.
Для соблюдения таких требований существуют продвинутые планировщики, которые являются отдельными самостоятельными инструментами планирования. В нашем случае это Airflow.
Airflow
Его уже разбирали в разных публикациях (например, в этой). Arflow мы используем давно, хоть и не на полную мощь. Основной сценарий – выстроить граф зависимостей между задачами (направленный ациклический граф или directed acyclic graph).
Возможность строить граф зависимостей – очень эффективный функционал, упрощающий планирование запусков логически взаимосвязанных задач. Часто так бывает, что по времени уже пора, но возникли проблемы с предыдущими задачами и запускаться нет смысла. Airflow это понимает и откладывает выполнение задачи до соблюдения всех предусловий. А если они всё же не соблюдаются, то текущая задача не будет запущена.
Для нас основное удобство в его использовании – это отсутствие привязки к платформе. Упомянутые выше Cron и CronJob работают исключительно в рамках установленных платформой границах. Для Cron’а это физический сервер, на котором он запускается, для CronJob – кластер Kubernetes’а. В свою очередь, Airflow запущен как отдельный сервис и может управлять запусками задач и в отдельно стоящих серверах, и в кластерах Kubernetes’а, и даже где-то в облаках. В нашем случае он занимается только оркестрацией и на своих мощностях задачи не выполняет, хотя и такое возможно. При определённой степени неаккуратности Airflow может стать маленьким монолитом, на который завязаны запуски всех задач, имеющихся в компании. В таком случае каждая из запускаемых задач может вывести из строя сервер и до устранения проблемы все задачи выполняться не будут.
Мы от такого исхода защищены, часто логика тяжёлых задачах у нас реализована в виде отдельных сервисов, запускаемых в Kubernetes’е. Airflow предоставляет удобный механизм запуска подов, точнее, даже два: KubernetesPodOperator и KubernetesExecutor. Мы используем KubernetesPodOperator: для запуска пода необходимо иметь собранный docker-образ сервиса в кластере Kubernetes’а.
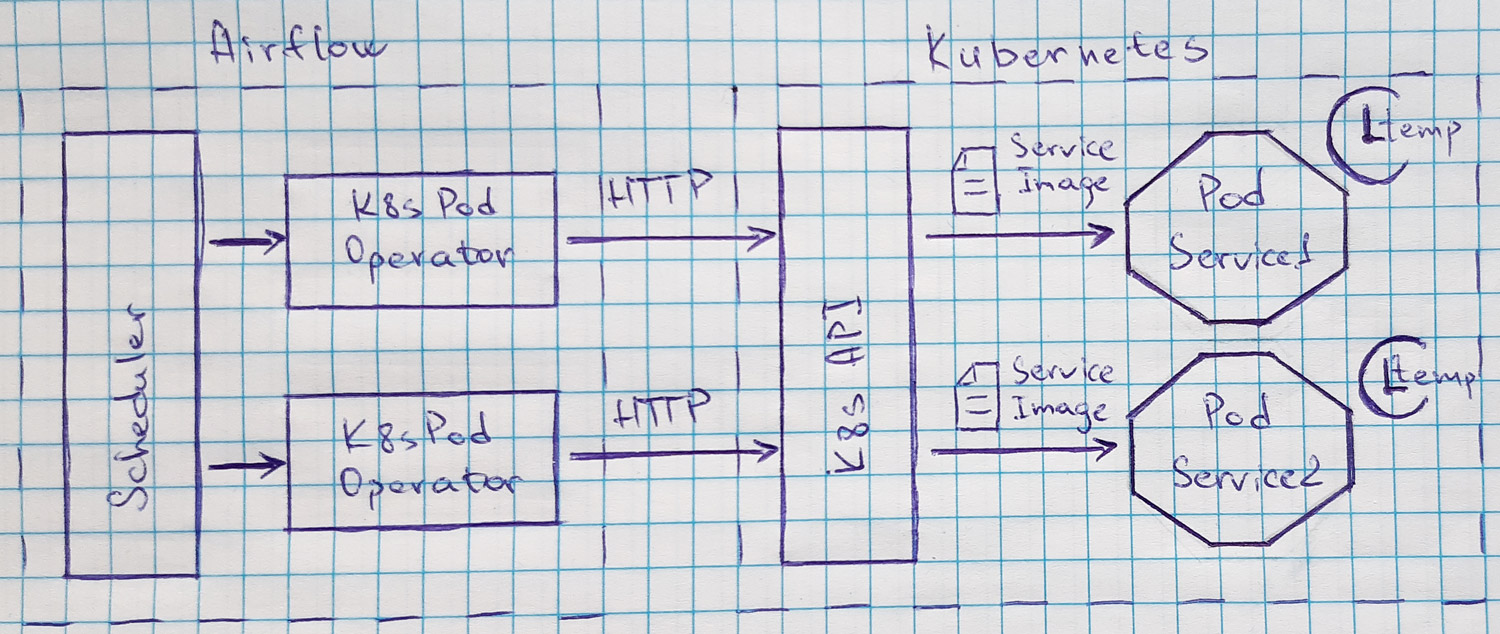
Оператор использует официальный kubernetes-client к API Kubernetes’а, что даёт возможность гибко конфигурировать запускаемые поды со стороны Airflow. В кластере можно завести configmap’ы или секреты, использование которых также указывается в операторе. У KubernetesExecutor’а другое предназначение: он позволяет динамически расширять мощности Airflow за счёт запуска подов, в которых будут выполняться различные операторы или набор операторов, выстроенных в ациклический граф.
Связка Airflow + KubernetesPodOperator + Kubernetes подходит нам по функциональности и надёжности планирования и запуска задач, позволяя спать ночами спокойно, зная, что в это время в меру дотошный и исполнительный Airflow проконтролирует выполнение всей необходимой работы на мощностях Kubernetes, который может быть запущен как и на соседней серверной стойке, так и в другом дата-центре или на стороне облачного провайдера.
Альтернатива KubernetesPodOperator’у
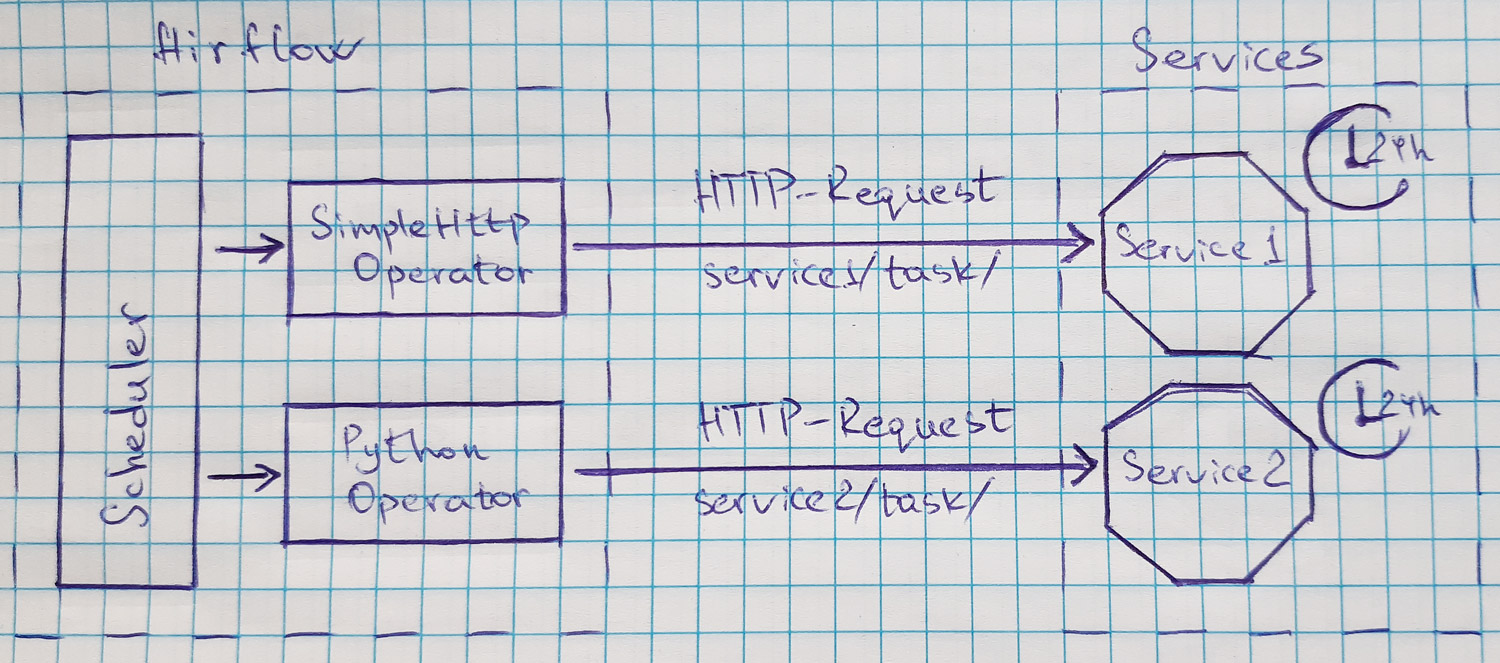
Отсутствие Kubernetes’а или даже Docker’а не ставит крест на возможностях Airflow. Какое-то время мы активно пользовались SimpleHttpOperator’ом или PythonOperator’ом, делая http-запросы на урлы сервиса, запуская тем самым логику задач. Такой вариант тоже имеет право на существование, но у него есть недостатки, из-за которых мы от него решили отказаться. Первый недостаток – все прокси или балансировщики перед сервисом требуют донастройки, потому что иначе запрос будет отваливаться по тайм-аутам. Этого можно избежать, сделав запуск асинхронным: запустили и, не дожидаясь окончания, считаем, что дело сделано. Но при таком подходе нет возможности использовать механизм перезапуска не выполнившихся задач Airflow. Второй недостаток – из-за задачи, которая запускается раз в день или вовсе раз в неделю, приходится иметь запущенный сервис, который бОльшую часть времени просто занимает ресурсы, не выполняя полезную работу.
Но если задачи запускаются регулярно и при этом они легковесные, то такой вариант определённо может оказаться полезным.
И снова немного об отчетах
У отчётов есть один явный недостаток: они статичны и для внесения изменений необходимо править генерирующий их скрипт. С ростом объёма и качества озера данных мы стали отказываться от подхода с генерацией отчётов. Заинтересованные в продуктовых метриках лица используют BI-систему Metabase, которая предоставляет гибкий и удобный интерфейс доступа к данным в аналитическом хранилище. Но это уже совсем другая история (с).
А связка Airflow + KubernetesPodOperator + Kubernetes продолжает активно использоваться для разного рода технических задач.
Что делать, если возникла мысль «Хочу так же!»?
Действия простые:
-
определиться с набором текущих проблем;
-
понять, какие именно проблемы решит усложнённая инфраструктура;
-
ещё раз подумать, точно ли хотите;
-
засучив рукава, начать затаскивать в окружение недостающие инструменты.
Повторюсь, что пользу от использования Airflow можно извлечь, не имея в эксплуатации контейнеров и/или систем их оркестрирования; -
пробовать, натыкаться на грабли и подводные камни, наращивать экспертизу;
-
вернуться к пункту 5.
А если тема окажется злободневной, мы поделимся своим опытом и в формате «how to» подробно расскажем про реализацию разных связок с Airflow и про проблемы, с которыми мы сталкивались.
ссылка на оригинал статьи https://habr.com/ru/company/tuturu/blog/530410/
Добавить комментарий