LightGBM расширяет алгоритм градиентного бустинга, добавляя тип автоматического выбора объектов, а также фокусируясь на примерах бустинга с большими градиентами. Это может привести к резкому ускорению обучения и улучшению прогнозных показателей. Таким образом, LightGBM стала де-факто алгоритмом для соревнований по машинному обучению при работе с табличными данными для задач регрессионного и классификационного прогностического моделирования. В этом туториале вы узнаете, как разрабатывать ансамбли машин Light Gradient Boosted для классификации и регрессии. После завершения этого урока вы будете знать:
- Light Gradient Boosted Machine (LightGBM) — эффективную реализацию ансамбля стохастического градиентного бустинга с открытым исходным кодом.
- Как разрабатывать ансамбли LightGBM для классификации и регрессии с помощью API scikit-learn.
- Как исследовать влияние гиперпараметров модели LightGBM на её производительность.

Этот туториал состоит из трёх частей
- Алгоритм LightBLM.
- Scikit-Learn API для LightGBM.
— Ансамбль LightGBM для классификации.
— Ансамбль LightGBM для регрессии. - Гиперпараметры LightGBM.
— Исследование количества деревьев.
— Исследование глубины дерева.
— Исследование скорости обучения.
— Исследование типа бустинга.
Алгоритм LightBLM
Градиентный бустинг относится к классу ансамблевых алгоритмов машинного обучения, которые могут использоваться для задач классификации или регрессионного прогностического моделирования.
Ансамбли строятся на основе моделей дерева решений. Деревья добавляются по одному в ансамбль и обучаются для исправления ошибок прогнозирования, сделанных предыдущими моделями. Это тип ансамблевой модели машинного обучения, называемой бустингом.
Модели обучаются с использованием любой произвольной дифференцируемой функции потерь и алгоритма оптимизации градиентного спуска. Это даёт методу его название «градиентный бустинг», поскольку градиент потерь минимизируется по мере обучения модели, подобно нейронной сети. Дополнительные сведения о градиентном бустинге см. в туториале: «Мягкое введение в алгоритм градиентного бустинга в ML».
LightGBM — это реализация градиентного бустинга с открытым исходным кодом, разработанная для того, чтобы быть эффективной и даже, возможно, более эффективной, чем другие реализации.
Как таковой LightGBM — это проект с открытым исходным кодом, библиотека программного обеспечения и алгоритм машинного обучения. То есть проект очень похож на Extreme Gradient Boosting или XGBoost technique.
LightGBM была описана Голинь К., и соавт. в статье 2017 года под названием «LightGBM: A Highly Efficient Gradient Boosting Decision Tree». Реализация вводит две ключевые идеи: GOSS и EFB.
Градиентная односторонняя выборка (GOSS) является модификацией градиентного бустинга, который фокусирует внимание на тех учебных примерах, которые приводят к большему градиенту, в свою очередь, ускоряя обучение и уменьшая вычислительную сложность метода.
С помощью GOSS мы исключаем значительную долю экземпляров данных с небольшими градиентами и используем только остальные экземпляры для оценки прироста информации. Мы доказываем, что, поскольку экземпляры данных с большими градиентами играют более важную роль в вычислении информационного выигрыша, GOSS может получить довольно точную оценку информационного выигрыша с гораздо меньшим размером данных.
Exclusive Feature Bundling (объединение взаимоисключающих признаков), или EFB, — это подход объединения разрежённых (в основном нулевых) взаимоисключающих признаков, таких как категориальные переменные входных данных, закодированные унитарным кодированием. Таким образом, это тип автоматического подбора признаков.
… мы пакетируем взаимоисключающие признаки (то есть они редко принимают ненулевые значения одновременно), чтобы уменьшить количество признаков.
Вместе эти два изменения могут ускорить время обучения алгоритма до 20 раз. Таким образом, LightGBM можно рассматривать как деревья решений с градиентным бустингом (GBDT) с добавлением GOSS и EFB.
Мы называем нашу новую реализацию GBDT с помощью GOSS и EFB LightGBM. Наши эксперименты на нескольких общедоступных наборах данных показывают, что LightGBM ускоряет процесс обучения обычного GBDT более чем в 20 раз, достигая почти такой же точности.
Scikit-Learn API для LightGBM
LightGBM может устанавливаться как автономная библиотека, а модель LightGBM может разрабатываться с помощью API scikit-learn.
Первый шаг — установка библиотеки LightGBM. На большинстве платформ её можно выполнить с помощью менеджера пакетов pip; например:
sudo pip install lightgbmПроверить установку и версию можно так:
# check lightgbm version import lightgbm print(lightgbm.__version__)Скрипт выведет версию установленной LightGBM. Ваша версия должна быть как здесь или выше. Если это не так, обновите LightGBM. Если нужны конкретные инструкции для вашей среды разработки, обратитесь к туториалу: «Руководство по установке LightGBM».
Библиотека LightGBM имеет собственный API, хотя мы используем метод через классы-оболочки scikit-learn: LGBMRegressor и LGBMClassifier. Это позволит применять весь набор инструментов из библиотеки машинного обучения scikit-learn для подготовки данных и оценки моделей.
Обе модели работают одинаково и используют одни и те же аргументы, влияющие на то, как деревья решений создаются и добавляются в ансамбль. При построении модели используется случайность. Это означает, что каждый раз, когда алгоритм запускается на одних и тех же данных, он создаёт несколько иную модель.
При использовании алгоритмов машинного обучения со стохастическим алгоритмом обучения рекомендуется оценивать их путём усреднения их производительности по нескольким запускам или повторениям кросс-валидации. При подгонке окончательной модели может оказаться желательным либо увеличивать число деревьев до тех пор, пока дисперсия модели не уменьшится при повторных оценках, либо обучать несколько конечных моделей и усреднить их прогнозы. Давайте рассмотрим разработку ансамбля LightGBM как для классификации, так и для регрессии.
Ансамбль LightGBM для классификации
В этом разделе рассмотрим применение LightGBM для задачи классификации. Во-первых, мы можем использовать функцию make_classification() создать синтетическую задачу бинарной классификации с 1000 примерами и 20 входными признаками. Весь пример смотрите ниже.
# test classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # summarize the datasetПри выполнении примера создается набор данных и суммируется форма входных и выходных компонентов.
(1000, 20) (1000,)Затем мы можем оценить алгоритм LightGBM на этом наборе данных. Мы будем оценивать модель с помощью повторной стратифицированной k-кратной кросс-валидации с тремя повторами и k, равным 10. Мы сообщим среднее и стандартное отклонения точности модели по всем повторениям и сгибам.
# evaluate lightgbm algorithm for classification from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # define the model model = LGBMClassifier() # evaluate the model cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # report performance print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Запуск примера показывает точность среднего и стандартного отклонений модели.
Примечание: ваши результаты могут отличаться, учитывая стохастический характер алгоритма или процедуры оценки, или различия в числовой точности. Попробуйте выполнить пример несколько раз и сравнить средний результат.
В этом случае мы видим, что ансамбль LightGBM с гиперпараметрами по умолчанию достигает точности классификации около 92,5 % в этом тестовом наборе данных.
Accuracy: 0.925 (0.031)Мы также можем использовать модель LightGBM в качестве окончательной модели и делать прогнозы для классификации. Во-первых, ансамбль LightGBM подходит для всех доступных данных, во-вторых, можно вызвать функцию predict(), чтобы сделать прогнозы по новым данным. Приведённый ниже пример демонстрирует это на нашем наборе данных бинарной классификации.
# make predictions using lightgbm for classification from sklearn.datasets import make_classification from lightgbm import LGBMClassifier # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) # define the model model = LGBMClassifier() # fit the model on the whole dataset model.fit(X, y) # make a single prediction row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808] yhat = model.predict([row]) print('Predicted Class: %d' % yhat[0])Запуск примера обучает модели ансамбля LightGBM для всего набора данных, а затем используется для прогнозирования новой строки данных, как это было бы при использовании модели в приложении.
Predicted Class: 1Теперь, когда мы знакомы с использованием LightGBM для классификации, давайте рассмотрим API для регрессии.
Ансамбль LightGBM для регрессии
В этом разделе мы рассмотрим использование LightGBM для регрессионной задачи. Во-первых, мы можем использовать функцию make_regression()
создать задачу синтетической регрессии с 1000 примерами и 20 входными объектами. Весь пример смотрите ниже.
# test regression dataset from sklearn.datasets import make_regression # define dataset X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # summarize the dataset print(X.shape, y.shape)При выполнении примера создается набор данных и резюмируются входные и выходные компоненты.
(1000, 20) (1000,)Во-вторых, мы можем оценить алгоритм LightGBM на этом наборе данных.
Как и в последнем разделе, мы будем оценивать модель с помощью повторной k-кратной кросс-валидации с тремя повторами и k равным 10. Мы сообщим о средней абсолютной ошибке (MAE) модели по всем повторам и группам кросс-валидации. Библиотека scikit-learn делает MAE отрицательным, так что она максимизируется, а не минимизируется. Это означает, что большие отрицательные MAE лучше, а идеальная модель имеет MAE 0. Полный пример приведён ниже.
# evaluate lightgbm ensemble for regression from numpy import mean from numpy import std from sklearn.datasets import make_regression from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedKFold from lightgbm import LGBMRegressor # define dataset X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # define the model model = LGBMRegressor() # evaluate the model cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise') # report performance print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))Запуск примера сообщает о средней и стандартной точности отклонения модели.
Примечание: ваши результаты могут различаться, учитывая стохастический характер алгоритма или процедуры оценки, или различия в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат. В этом случае мы видим, что ансамбль LightGBM с гиперпараметрами по умолчанию достигает MAE около 60.
MAE: -60.004 (2.887)Мы также можем использовать модель LightGBM в качестве окончательной модели и делать прогнозы для регрессии. Сначала ансамбль LightGBM обучается на всех доступных данных, затем может быть вызвана функция predict() для предсказания новых данных. Пример ниже демонстрирует это на нашем наборе данных регрессии.
# gradient lightgbm for making predictions for regression from sklearn.datasets import make_regression from lightgbm import LGBMRegressor # define dataset X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7) # define the model model = LGBMRegressor() # fit the model on the whole dataset model.fit(X, y) # make a single prediction row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792] yhat = model.predict([row]) print('Prediction: %d' % yhat[0]) Запуск примера обучает модель ансамбля LightGBM на всем наборе данных и затем используется для прогнозирования новой строки данных, как это было бы при использовании модели в приложении.
Prediction: 52Теперь, когда мы знакомы с использованием API scikit-learn для оценки и применения ансамблей LightGBM, давайте посмотрим на настройку модели.
Гиперпараметры LightGBM
В этом разделе подробнее рассмотрим некоторые гиперпараметры, важные для ансамбля LightGBM, а также их влияние на производительность модели. У LightGBM есть множество гиперпараметров, на которые можно посмотреть, здесь посмотрим на количество деревьев и их глубину, скорость обучения и тип бустинга. Общие советы по настройке гиперпараметров LightGBM см. в документации: «Настройка параметров LightGBM».
Исследование количества деревьев
Важным гиперпараметром для алгоритма ансамбля LightGBM является количество деревьев решений, используемых в ансамбле. Напомним, что деревья принятия решений добавляются в модель последовательно в попытке исправить и улучшить прогнозы, сделанные предыдущими деревьями. Часто работает правило: больше деревьев — лучше. Количество деревьев можно задать с помощью аргумента n_estimators, по умолчанию равного 100. В приведенном ниже примере исследуется влияние количества деревьев, взяты значения от 10 до 5000.
# explore lightgbm number of trees effect on performance from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier from matplotlib import pyplot # get the dataset def get_dataset(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) return X, y # get a list of models to evaluate def get_models(): models = dict() trees = [10, 50, 100, 500, 1000, 5000] for n in trees: models[str(n)] = LGBMClassifier(n_estimators=n) return models # evaluate a give model using cross-validation def evaluate_model(model): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define dataset X, y = get_dataset() # get the models to evaluate models = get_models() # evaluate the models and store results results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # plot model performance for comparison pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show()При выполнении примера сначала отображается средняя точность для каждого количества деревьев решений.
Примечание: ваши результаты могут отличаться с учетом стохастического характера алгоритма или процедуры оценки, или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
Здесь видим, что производительность улучшается для этого набора данных примерно до 500 деревьев, после чего она, похоже, выравнивается.
>10 0.857 (0.033) >50 0.916 (0.032) >100 0.925 (0.031) >500 0.938 (0.026) >1000 0.938 (0.028) >5000 0.937 (0.028)График в виде ящика с усами создается для распределения оценок точности каждого настроенного количества деревьев. Видно общую тенденцию увеличения производительности модели и размера ансамбля.
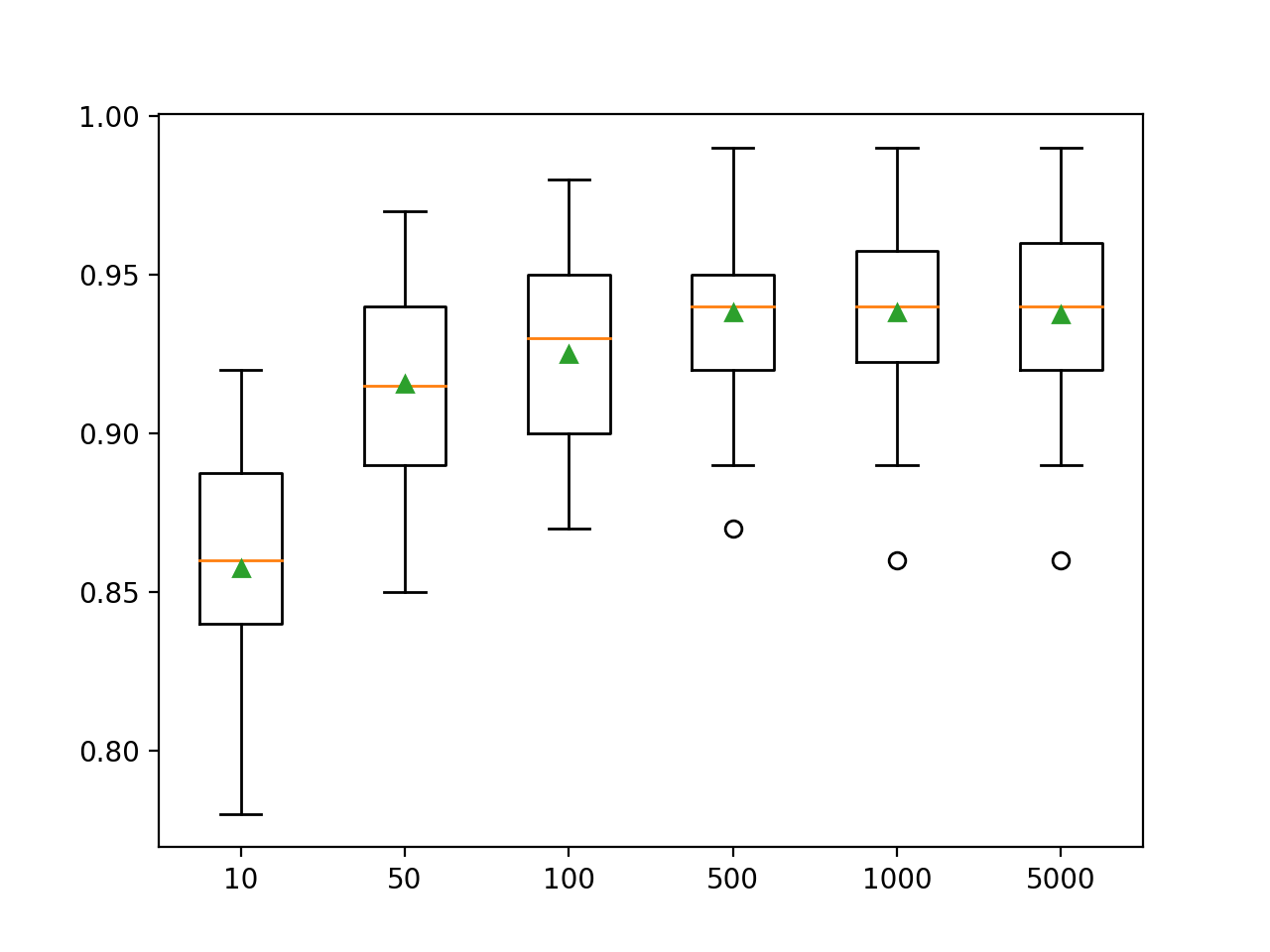
Исследование глубины дерева
Изменение глубины каждого дерева, добавляемого в ансамбль, — ещё один важный гиперпараметр для градиентного бустинга. Глубина дерева определяет, насколько каждое дерево специализируется на обучающем наборе данных: насколько оно может быть общим или обученным. Предпочтительны деревья, которые не должны быть слишком мелкими и общими (например, AdaBoost) и не слишком глубокие и специализированными (например бутстреп-агрегация).
Градиентный бустинг обычно хорошо работает с деревьями, имеющими умеренную глубину, находящую баланс между обученностью и обобщенностью. Глубина дерева контролируется аргументом max_depth, и по умолчанию используется неопредёленное значение, поскольку механизм по умолчанию для управления сложностью деревьев заключается в использовании конечного количества узлов.
Существует два основных способа управления сложностью дерева: через максимальную глубину дерева и максимальное количество терминальных узлов (листьев) дерева. Здесь мы изучаем количество листьев, поэтому нам нужно увеличить их количество, чтобы поддерживать более глубокие деревья, задав аргумент num_leaves. Ниже исследуются глубины дерева от 1 до 10 и их влияние на производительность модели.
# explore lightgbm tree depth effect on performance from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier from matplotlib import pyplot # get the dataset def get_dataset(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) return X, y # get a list of models to evaluate def get_models(): models = dict() for i in range(1,11): models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i) return models # evaluate a give model using cross-validation def evaluate_model(model): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define dataset X, y = get_dataset() # get the models to evaluate models = get_models() # evaluate the models and store results results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # plot model performance for comparison pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show()При выполнении примера сначала отображается средняя точность для каждой настроенной глубины дерева.
Примечание: ваши результаты могут отличаться с учётом стохастического характера алгоритма или процедуры оценки, или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
Здесь мы видим, что производительность улучшается с увеличением глубины дерева, возможно, вплоть до 10 уровней. Было бы интересно исследовать даже более глубокие деревья.
>1 0.833 (0.028) >2 0.870 (0.033) >3 0.899 (0.032) >4 0.912 (0.026) >5 0.925 (0.031) >6 0.924 (0.029) >7 0.922 (0.027) >8 0.926 (0.027) >9 0.925 (0.028) >10 0.928 (0.029)График в виде прямоугольников и усов создается для распределения оценок точности для каждой настроенной глубины дерева. Видно общую тенденцию увеличения производительности модели с глубиной дерева до пяти уровней, после чего производительность остаётся достаточно ровной.
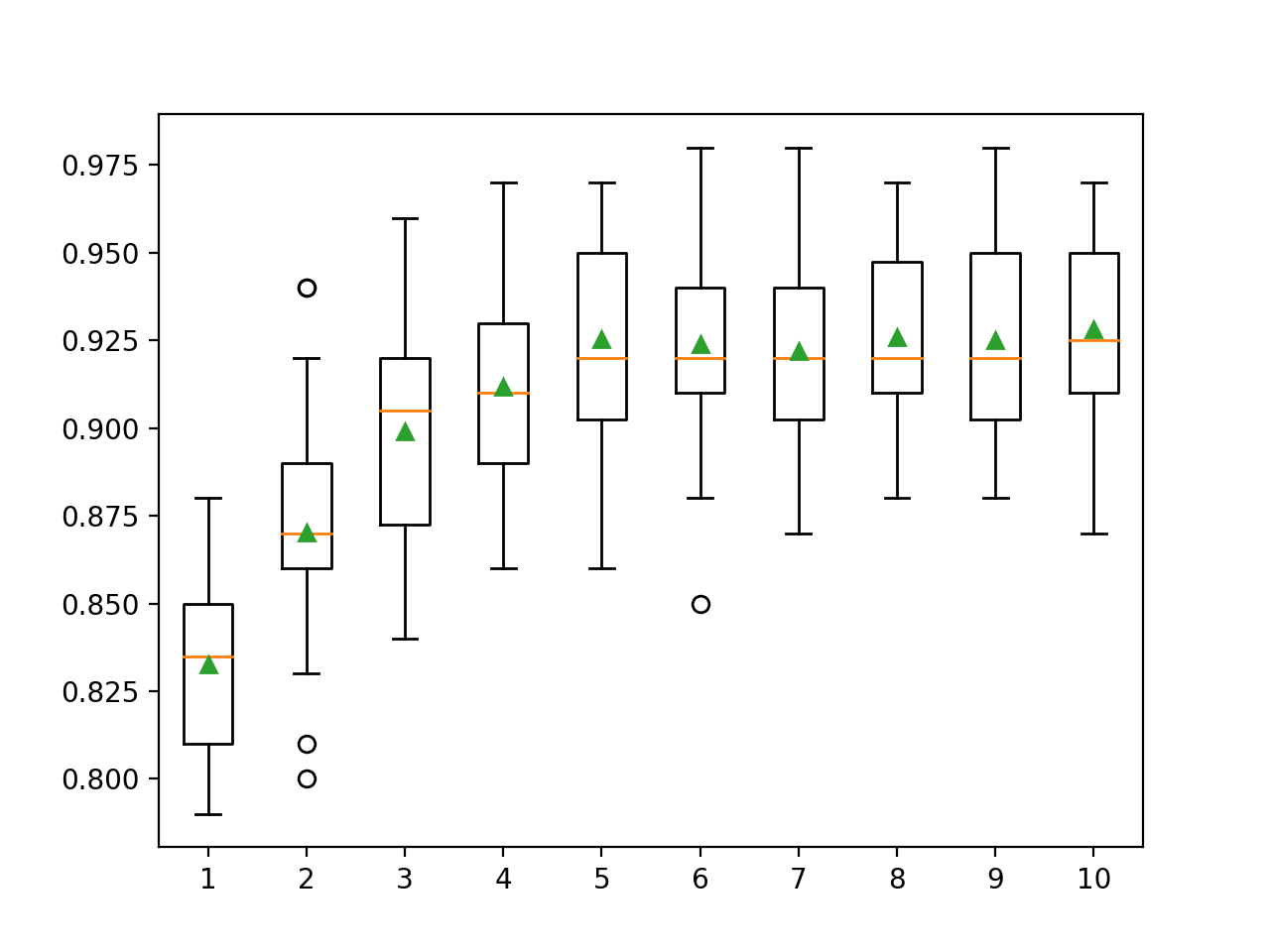
Исследование скорости обучения
Скорость обучения контролирует степень вклада каждой модели в прогнозирование ансамбля. Меньшие скорости могут потребовать большего количества деревьев решений в ансамбле. Скорость обучения можно контролировать с помощью аргумента learning_rate, по умолчанию она равна 0,1. Ниже исследуется скорость обучения и сравнивается влияние значений от 0,0001 до 1,0.
# explore lightgbm learning rate effect on performance from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier from matplotlib import pyplot # get the dataset def get_dataset(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) return X, y # get a list of models to evaluate def get_models(): models = dict() rates = [0.0001, 0.001, 0.01, 0.1, 1.0] for r in rates: key = '%.4f' % r models[key] = LGBMClassifier(learning_rate=r) return models # evaluate a give model using cross-validation def evaluate_model(model): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define dataset X, y = get_dataset() # get the models to evaluate models = get_models() # evaluate the models and store results results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # plot model performance for comparison pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show()При выполнении примера сначала отображается средняя точность для каждой настроенной скорости обучения.
Примечание: ваши результаты могут различаться с учётом стохастического характера алгоритма или процедуры оценки, или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
Здесь видим, что более высокая скорость обучения приводит к лучшей производительности на этом наборе данных. Мы ожидаем, что добавление большего количества деревьев в ансамбль для меньшей скорости обучения ещё больше повысит производительность.
>0.0001 0.800 (0.038) >0.0010 0.811 (0.035) >0.0100 0.859 (0.035) >0.1000 0.925 (0.031) >1.0000 0.928 (0.025)Ящик с усами создаётся для распределения оценок точности каждой настроенной скорости обучения. Видно общую тенденцию увеличения производительности модели с увеличением скорости обучения вплоть до 1,0.

Исследование типа бустинга
Особенность LightGBM — то, что он поддерживает ряд алгоритмов бустинга, называемых типами бустинга. Тип бустинга указывается с помощью аргумента boosting_type и для определения типа принимает строку. Возможные значения:
- ‘gbdt‘: дерево решений с градиеным бустингом (GDBT);
- ‘dart‘: понятие отсева (dropout) вводится в MART, получаем DART;
- ‘goss‘: односторонняя выборка на основе градиента (GOSS).
По умолчанию используется GDBT, классический алгоритм градиентного бустинга.
DART описан в статье 2015 года под названием «DART: Dropouts meet Multiple Additive Regression Trees» и, как следует из названия, добавляет понятие dropout из глубокого обучения в алгоритм множественных аддитивных регрессионных деревьев (MART), предшественник деревьев решений с градиентным бустингом.
Этот алгоритм известен под многими названиями, включая Gradient TreeBoost, Boosted Trees и деревья и деревья множественной аддитивной регрессии (MART). Для обозначения алгоритма мы используем последнее название.
GOSS представлен с работой по LightGBM и библиотекой lightbgm. Этот подход направлен на использование только тех экземпляров, которые приводят к большому градиенту ошибки, для обновления модели и удаления остальных экземпляров.
… Мы исключаем значительную часть экземпляров данных с небольшими градиентами и используем только остальные для оценки прироста информации.
Ниже LightGBM обучается на наборе данных синтетической классификации с тремя ключевыми методами бустинга.
# explore lightgbm boosting type effect on performance from numpy import arange from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from lightgbm import LGBMClassifier from matplotlib import pyplot # get the dataset def get_dataset(): X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7) return X, y # get a list of models to evaluate def get_models(): models = dict() types = ['gbdt', 'dart', 'goss'] for t in types: models[t] = LGBMClassifier(boosting_type=t) return models # evaluate a give model using cross-validation def evaluate_model(model): cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define dataset X, y = get_dataset() # get the models to evaluate models = get_models() # evaluate the models and store results results, names = list(), list() for name, model in models.items(): scores = evaluate_model(model) results.append(scores) names.append(name) print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores))) # plot model performance for comparison pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show()При выполнении примера сначала отображается средняя точность для каждого настроенного типа бустинга.
Примечание: ваши результаты могут отличаться с учетом стохастического характера алгоритма или процедуры оценки, или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
Мы видим, что метод повышения по умолчанию работает лучше, чем два других оцененных метода.
>gbdt 0.925 (0.031) >dart 0.912 (0.028) >goss 0.918 (0.027)Для распределения оценок точности каждого сконфигурированного метода усиления создается диаграмма ящик с усами, что позволяет напрямую сравнивать методы.
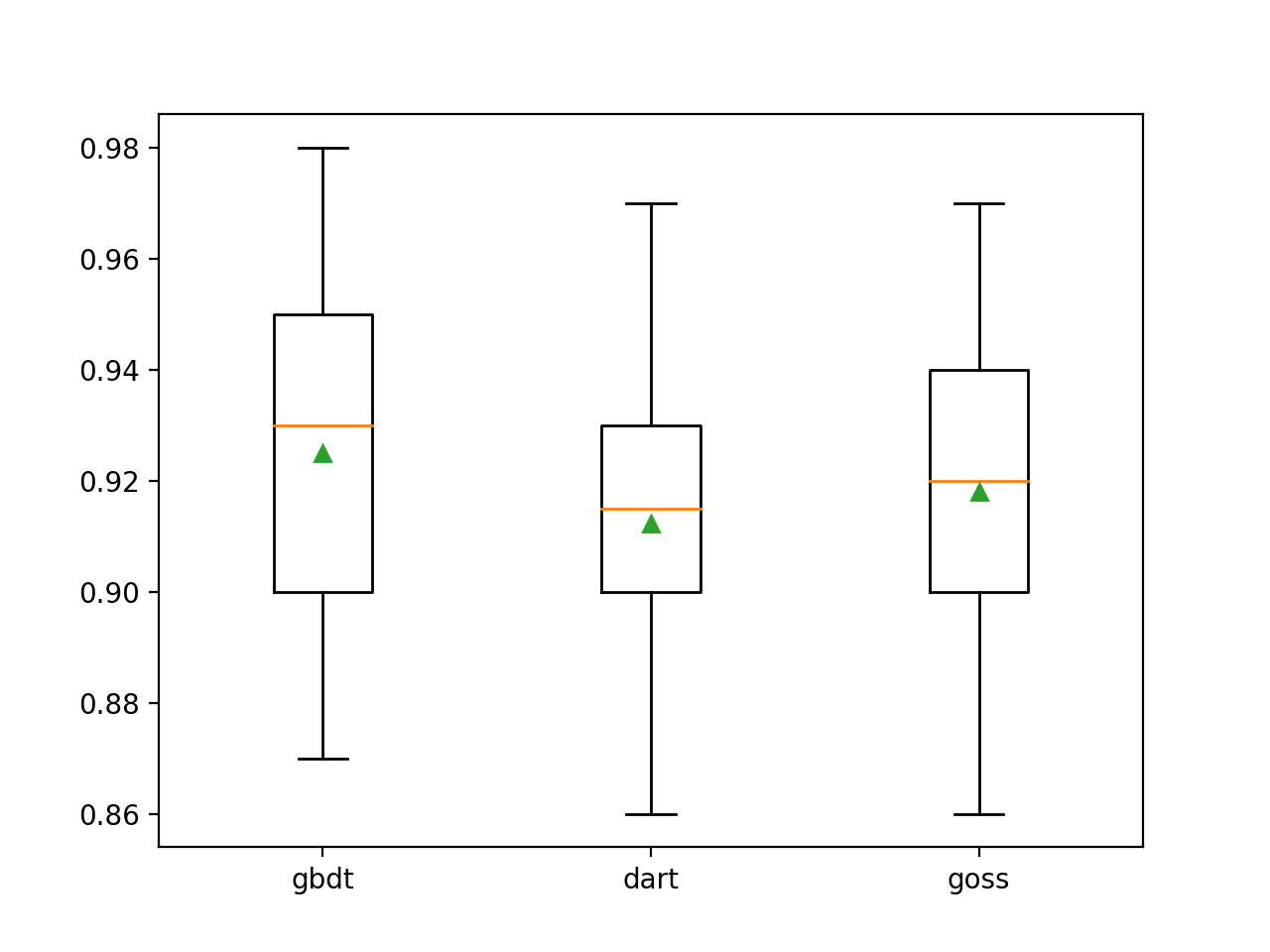

- Курс по Machine Learning
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Курс «Python для веб-разработки»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Математика и Machine Learning для Data Science»
- Профессия Этичный хакер
- Разработчик игр на Unity
- Курс по JavaScript
- Профессия Веб-разработчик
- Профессия Java-разработчик
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Сколько зарабатывает дата-сайентист: обзор зарплат и вакансий в 2020
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в 2020
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Machine Learning и Computer Vision в добывающей промышленности
- Machine Learning и Computer Vision на обогатительных фабриках
ссылка на оригинал статьи https://habr.com/ru/company/skillfactory/blog/530594/
Добавить комментарий