Детекция аномалий с помощью методов глубокого обучения
Выявление аномалий (или выбросов) в данных — задача, интересующая ученых и инженеров из разных областей науки и технологий. Хотя выявлением аномалий (объектов, подозрительно не похожих на основной массив данных) занимаются уже давно и первые алгоритмы были разработаны еще в 60-ых годах прошлого столетия, в этой области остается много неразрешенных вопросов и проблем, с которыми сталкиваются люди в таких сферах, как консалтинг, банковский скоринг, защита информации, финансовые операции и здравоохранение. В связи с бурным развитием алгоритмов глубоко обучения за последние несколько лет было предложено много современных подходов к решению данной проблемы для различных видов исследуемых данных, будь то изображения, записи с камер видеонаблюдений, табличные данные (о финансовых операциях) и др.
Глубокое обучение для детекции аномалий — Deep Anomaly Detection (DAD) — позволяет разрешить следующий ряд ограничений:
-
Неизвестность новых данных: т. к. аномалий — это объекты не похожие на все остальные, алгоритм должен быть способен генерализовать информацию об объекте с уже имеющейся информацией ранее полученных данных и определить отсутствие схожести, если таковое наблюдается
-
Гетерогенность разных классов объектов: непохожесть может быть разной
-
Редкость появление аномалий: имбаланс классов в обучении
-
Различные типы аномалий: одиночные объекты, обычные объекты, но в аномальных условиях, группы объектов (слишком плотный граф фейк-аккаунтов социальной сети)
При этом с точки зрения машинного обучения можно назвать следующие основные трудности в поставленной задаче:
-
Низкие значения precision метрики в задаче классификации на аномальный / нормальный (частое ложное срабатывание алгоритмов на нормальных данных)
-
Проблема больших размерностей данных
-
Отсутствие или недостаток размеченных данных
-
Неустойчивость алгоритмов к зашумленным объектам
-
Детекция аномалий целой группы объектов
-
Низкая интерпретируемость результатов
Категоризация подходов
В своей недавней статье [2] G. Pang приводит следующую классификацию существующих подходов для решения поставленной задачи.
Автор разбивает все алгоритмы на три большие группы:
Deep learning for feature extraction — по сути раздельная задача получения нового домена признаков меньшего размера, чем исходный (при этом можно будет использовать предобученные модели из других задач глубокого обучения), и решение задачи классификации уже на данных нового домена с помощью классических методов детекции аномалий. Тут две части решения никак не связаны между собой и только первую часть можно отнести к DAD.
На рис.2 схематично показан пайплайн данного подхода. Сначала мы с помощью нейронной сети φ(·) : X→ Z переводим исходное признаковое пространство в пространство низкой размерности Z, а потом независимо делаем скоринг наличия аномалий классическими методами.

Learning feature representation of normality — теперь нейросеть φ(·) : X→ Z является не независимым экстрактором новых признаков, а обучается вместе с скоринговой системой аномалий, то есть пространство Z будет формироваться с оглядкой на поставленную в конечном итоге задачу.

End-to-end anomaly score learning — end-to-end пайплайн, где нейронная сеть будет сразу предсказывать anomaly score.

Далее рассмотрим каждую группы по отдельности, указывая уже конкретные методы глубокого обучения для решения задачи в сформулированных рамках.
Deep learning for feature extraction
Как уже отмечалось в этом подходе мы попытаемся уменьшить размерность входных данных. Можно было бы использовать стандартный методы, такие как PCA (principal component analysis) [3] или random projection [4], но для детекции аномалий необходимо сохранить семантическую составляющую каждого объекта, с чем отлично справятся нейронные сети. И в зависимости от типа данных можем выбрать предобученные модели MLP, если имеем дело с табличный данными, СNNs для работы с изображениями, RNNs для предобработки последовательных данных (видеоряд).
При этом основным плюсом такого подхода будет наличие предобученных моделей для почти любого типа данных, но при этом для нахождении anomaly score полученное признаковое пространство может быть далеко не оптимальным.
Learning feature representation of normality
Как видно из рис.1 этот тип можно разделить на два подтипа.
Generic Normality Feature Learning. Подходы в этом классе алгоритмов при преобразовании исходных признаков всё ещё используют функцию потерь не для детекции аномалий напрямую. Но генеративные модели здесь позволяют вычленить ключевую информацию о структуре объектов, тем самым способствуя самой детекции выбросов.
Математическое описание семейства алгоритмов
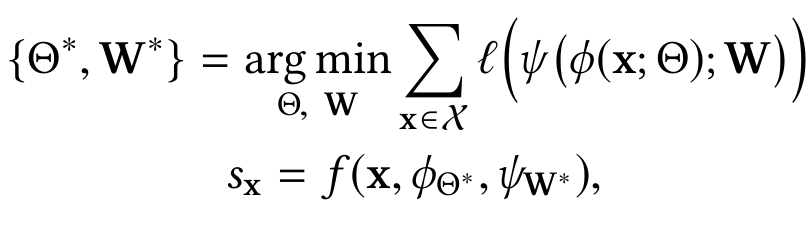
где ψ — нейронная сеть для выделения структурной информации объекта, l — функция потерь, соответствующая выбранным ψ, φ (конкретному подходу генеративных моделей), f — скоринговая функция аномалий.
Рассмотрим конкретные виды архитектур:
Автоэнкодеры
Для задачи DAD главная идея заключается в том, что нормальные данные будут легко реконструированы автоэнкодером, тогда как аномальный объект для модели будет восстановить сложно. [5]
Подробнее об алгоритме
Автоэнкодеры — архитектура нейронных сетей, позволяющая применять обучение без учителя, основной принцип которой получить на выходном слое отклик, наиболее близкий к входному.
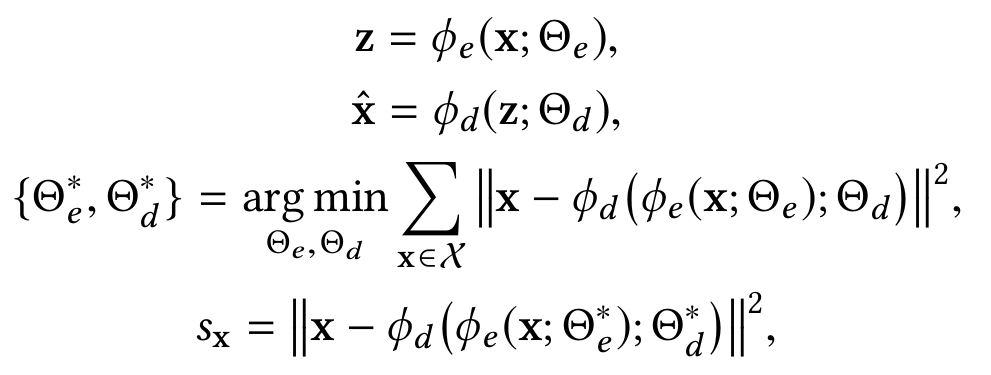
где φ_e (.) — энкодер, преобразующий объекты в промежуточное пространство низкой размерности, φ_d (.) — декодер, пытающийся восстановить исходный объект. При этом s_x (data reconstruction error) будет играть роль меры аномальности.
Generative Adversarial Networks
Опредение подхода
GANs — это алгоритм машинного обучения без учителя, построенный на комбинации двух нейросетей с противоположными целями, где первая сеть (генератор G) генерирует образы, а другая (дискриминатор D) старается отличить правильные образы от неправильных.
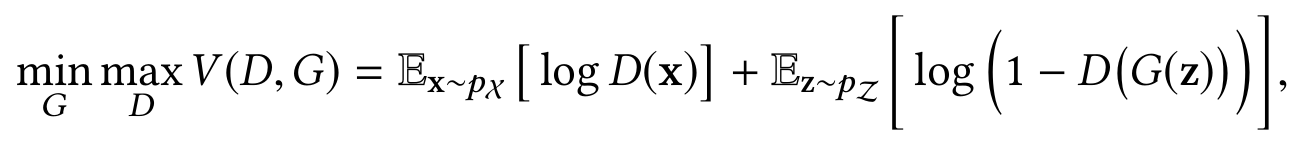
здесь G и D — генератор и дискриминатор соответственно.
В конкретной задаче DAD генератор будет стараться найти в обученном латентном пространстве вектор, соответветствующий поступающему в него объекту. При этом делается предположение, что так как аномальный объект придет из другого распределения, система быстро различит выброс. AnoGAN [6].
Predictability Modeling. В этом семействе алгоритмов каждый элемент рассматривается как часть последовательности.
Формульное описание

x̂_(t +1) = ψ (φ (x1 , x2 , · · · , xt ; Θ); W),
l_pred и l_adv — предсказательный и адверсариал лоссы, выступающие здесь в роли меры аномальности.
Предполагается, что нормальные данные будут предсказаны в последовательности с большей вероятностью, чем выбросы. Однако подход является вычислительно дорогим. [7]
Self-supervised Classification. Основная идея данного подхода в том, что на признаках исходных объектов решается задачи классификации (где новые признаки — это (n — 1) фичей, целевая переменная — оставшийся признак, и так для каждого признака). Тогда пришедший в обученную модель аномальный объект не будет подходить к построенным таким образом классификаторам. Заметим, что для такой постановки задачи размеченные данные будут и вовсе не обязательны.
Anomaly Measure-dependent Feature Learning.
Теперь будем обучать модель φ(·) : X→ Z, оптимизируясь уже на специальную функцию теперь аномальности.
Математическое описание
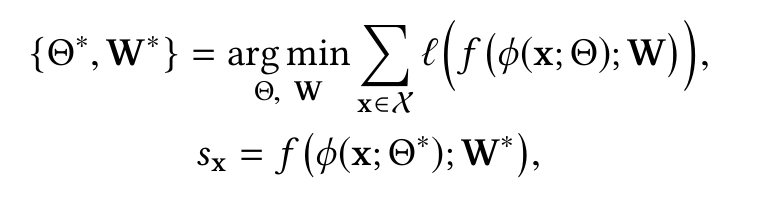
здесь l — функция потерь специальная для детекции аномалий.
Конкретные подходы в этом семействе:
-
Distance-based Measure. Оптимизируется конкретно по мерам, связанным с расстояниями: DB outliers [8], k-nearest neighbor distance [9] и др. При этом легко определить выброс — он не лежит в скоплении большого числа соседей, как это делают нормальные данные.
-
One-class Classification-based Measure. Предполагаем, что нормальные данные приходят из одного класса, который может быть описан одной моделью, когда как аномальный объект в этот класс на попадёт. Тут можно найти one-class SVM [10], Support Vector Data Description (SVDD) [11].
-
Clustering-based Measure. Классический подход детекции аномалий, где предполагается, что выбросы легко отделимы от кластеров в сформированном на обучающей выборке новом подпространстве [12].
End-to-end anomaly score learning
Из названия видим, что нейронная сеть будет теперь напрямую вычислять anomaly score.
Формульное описание
Семейство таких пайплайнов можно описать следующим образом:
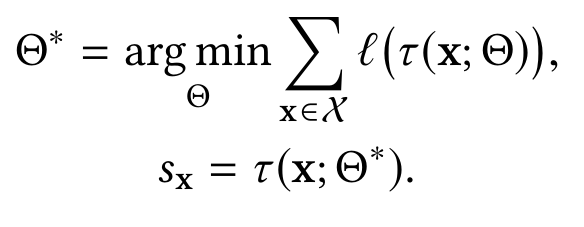
где τ (x; Θ) : X→ R нейронная сеть, выдающая сразу скоринговую величину.
Ranking Models. Один из разновидностей end-to-end подхода. Здесь нейронная сеть сортирует все объекты по некоторой величине, ассоциирующейся у модели со степенью аномальности. Self-trained deep ordinal regression model [13].
Prior-driven Models. Основной подход — the Bayesian inverse RL-based sequential anomaly detection. Здесь основная идея — агент получает на вход последовательность данных, и его нормальное поведение рассматривается как получение вознаграждения. В случае же аномальных данных агент получит слабое вознаграждение за последовательность [14].
Softmax Models. В данных архитектурах модели обучаются, максимизируя функцию правдоподобия нормального объекта из входных данных. При этом предполагается, что выброс будет иметь низкую вероятность в качетсве события.
Deviation Networks (end-to-end pipeline) [1]
Как на одном из наиболее актуальных подходов остановимся отдельно на архитектуре, предложенной G. Pang для обнаружения выбросов в задаче, где предполагается наличие лишь небольшого набора размеченных аномальных данных и большого массива неразмеченных объектов. На рис.5 представлена архитектура модели.
здесь function φ — anomaly scoring network, которая будет в качестве выхода отдавать предсказанные значения меры аномальности. Reference score generator — генератор референсных величин той же меры, полученных сэмплированием для случайных объектов неразмеченного сета (принимаемого за нормальный). Далее обе величины (предсказанная φ(x; Θ) и референсная μ_R) отправляются в deviation loss function L, целью которой будет заставить anomaly scoring network для нормальных объектов выдавать значения, близкие к референсным, и сильно отличные от референсных для аномальных.
Объяснение работы deviation loss function
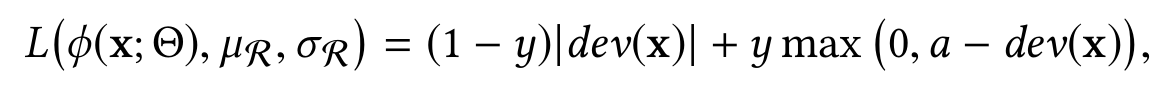

где y = 1, если объект является аномальным, y = 0 иначе. При этом из функции потерь можно заметить, что в процессе оптимизации модель будет стараться приблизить значения anomaly score к референсному у нормальных объектах, тогда как для аномальных будет заставлять предсказательную сеть выдавать такие значения φ(x; Θ), чтобы dev(x) было положительным, а значит, будет устремлять его к «a» (заранее заданной достаточно большой положительной величиной). Тем самым модель обучится четко разделять аномальные и нормальные объекты.
Заключение
В качестве заключения стоит отметить, что для тех или иных условий, в которых предполагается решать задачу выявления аномальных объектов подходят совершенно разные архитектуру и идеи решения. В каждом из рассмотренных типов есть свои SOTA-подходы. Хотя за последние несколько лет всё больше и больше популярность набирают именно end-to-end алгоритмы.
Ссылки на литературу
[1] Deep Anomaly Detection with Deviation Networks. G. Pang
[2] Deep Learning for Anomaly Detection: A Review. G. Pang
[3] Emmanuel J Candès, Xiaodong Li, Yi Ma, and John Wright. 2011. Robust principal component analysis?
[4] Ping Li, Trevor J Hastie, and Kenneth W Church. 2006. Very sparse random projections.
[5] Alireza Makhzani and Brendan Frey. 2014. K-sparse autoencoders. In ICLR.
[6] Thomas Schlegl, Philipp Seeböck, Sebastian M Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. 2017. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery.
[7] Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. 2018. Future frame prediction for anomaly detection–a new baseline.
[8] Edwin M Knorr and Raymond T Ng. 1999. Finding intensional knowledge of distance-based outliers.[9] Fabrizio Angiulli and Clara Pizzuti. 2002. Fast outlier detection in high dimensional spaces.
[10] Bernhard Schölkopf, John C Platt, John Shawe-Taylor, Alex J Smola, and Robert C Williamson. 2001. Estimating the support of a high-dimensional distribution.
[11] David MJ Tax and Robert PW Duin. 2004. Support vector data description.
[12] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. 2018. Deep clustering for unsupervised learning of visual features.
[13] Guansong Pang, Cheng Yan, Chunhua Shen, Anton van den Hengel, and Xiao Bai. 2020. Self-trained Deep Ordinal Regression for End-to-End Video Anomaly Detection.
[14] Andrew Y Ng and Stuart J Russell. 2000. Algorithms for Inverse Reinforcement Learning.
ссылка на оригинал статьи https://habr.com/ru/post/530574/
Добавить комментарий