В работе над одной задачей, понадобилось добавить в мониторинг все счетчики памяти из /proc/meminfo с нескольких linux хостов, для отслеживания состояние памяти в течении времени
root@server:~# cat /proc/meminfo MemTotal: 8139880 kB MemFree: 146344 kB MemAvailable: 4765352 kB Buffers: 115436 kB Cached: 6791672 kB SwapCached: 9356 kB Active: 4743296 kB Inactive: 2734088 kB Active(anon): 2410780 kB Inactive(anon): 340628 kB Active(file): 2332516 kB Inactive(file): 2393460 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 3906556 kB SwapFree: 3585788 kB Dirty: 804 kB Writeback: 0 kB AnonPages: 567172 kB Mapped: 2294276 kB Shmem: 2182128 kB KReclaimable: 198800 kB Slab: 340540 kB SReclaimable: 198800 kB SUnreclaim: 141740 kB KernelStack: 7008 kB PageTables: 90520 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 7976496 kB Committed_AS: 5171488 kB VmallocTotal: 34359738367 kB VmallocUsed: 25780 kB VmallocChunk: 0 kB Percpu: 24480 kB HardwareCorrupted: 0 kB AnonHugePages: 0 kB ShmemHugePages: 0 kB ShmemPmdMapped: 0 kB FileHugePages: 0 kB FilePmdMapped: 0 kB CmaTotal: 0 kB CmaFree: 0 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 0 kB DirectMap4k: 773632 kB DirectMap2M: 7606272 kB DirectMap1G: 2097152 kB root@server:~#Набор счетчиков должен приезжать в мониторинг автоматически при помощи discovery прямиком с файла /proc/meminfo
После разведки и создании метрик, все метрики должны приезжать в мониторинг раз в минуту одной операцией, для снижения эффекта наблюдения
Первое что пришло на ум — создать скрипт, запилить в нем всю логику, разложить на сервера и добавить юсер-параметр zabbix агента, но это уже не спортивно, так как эту же штуку можно сделать используя лишь gawk
Создадим шаблон в мониторинге, переходим во вкладку макросы, создаем три макроса:
макрос {$PATH} нужен для того чтобы gawk нашелся при попытке его запустить
Содержание макроса:
PATH=$PATH:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin; LANG=en_US.UTF-8;макрос {$S} нужен будет в discovery ( простыню про gawk, BEGIN я объясню в конце статьи )
gawk 'BEGIN {FS=":";ORS="";print "{\"data\": [ " }{b=gensub(/ +/,"","g",gensub(/kB/,"","g",$2) );$1=gensub(/\(|\)/,"_","g",$1);printf "%s{\"{#TYPE}\": \"%s\", \"{#VALUE}\": \"%s\"}",separator, $1, b;separator = ",";} END { print " ]}" }' /proc/meminfoмакрос {$VALUE} нужен будет при получении метрик раз в минуту
gawk 'BEGIN { FS=":"; ORS = ""; print "{" } { b=gensub(/ +/,"","g",gensub(/kB/,"","g",$2) ); $1=gensub(/\(|\)/,"_","g",$1); printf "%s\"%s\":\"%s\"",separator,$1,b;separator=",";} END { print "}" }' /proc/meminfoвот наш шаблон

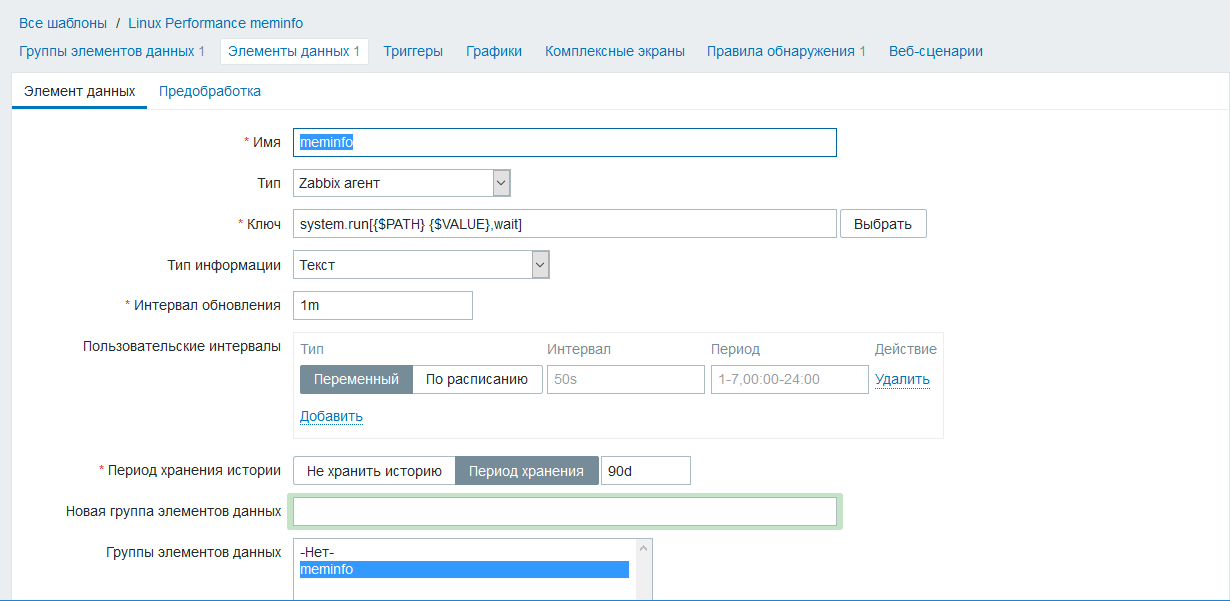
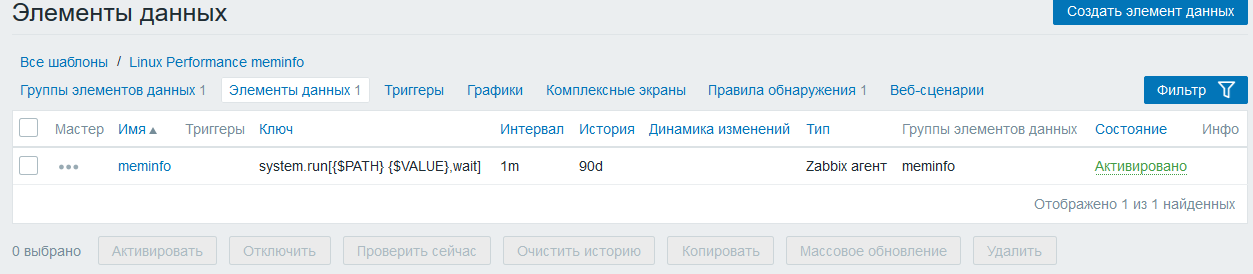
Создадим обычную метрику meminfo system.run[{$PATH} {$VALUE},wait]
Обратите внимание на конструкцию вызова system.run а внутри два макроса {$PATH} {$VALUE} очень коротко, лаконично и удобно
Метрика meminfo является источником данных для метрик которые будут обнаружены
С метрикой пока все
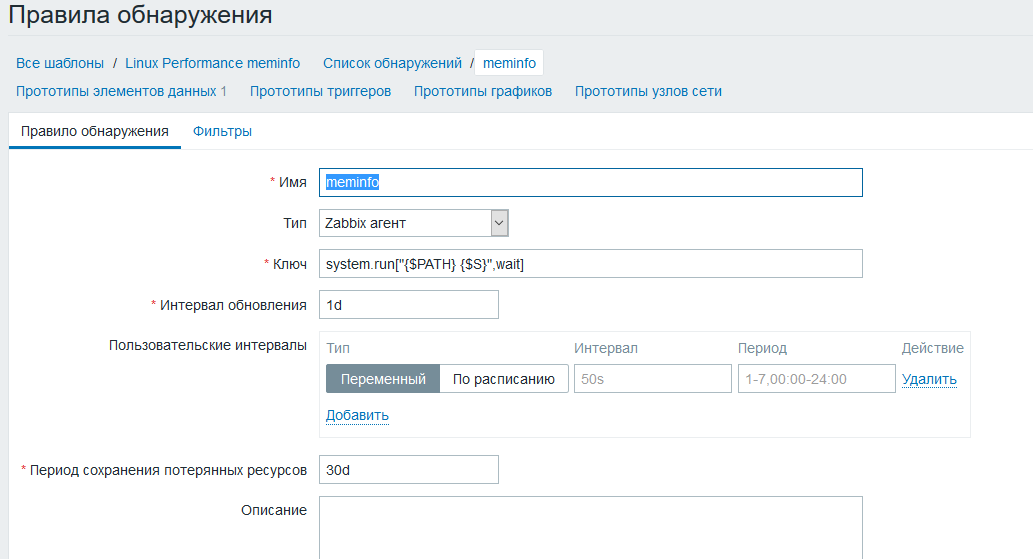
Создаем правило обнаружения meminfo
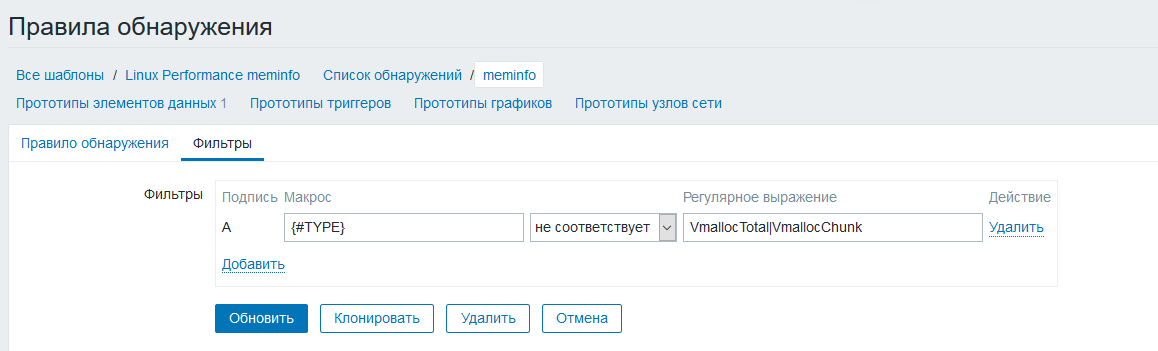
Перейдем в фильтр и добавим {#TYPE} [не равно] VmallocTotal|VmallocChunk это делается для исключения двух ненужных нам параметров
Создаем прототип элемента данных, тип данных зависимый элемент, в качестве источника данных выбираем метрику созданную ранее
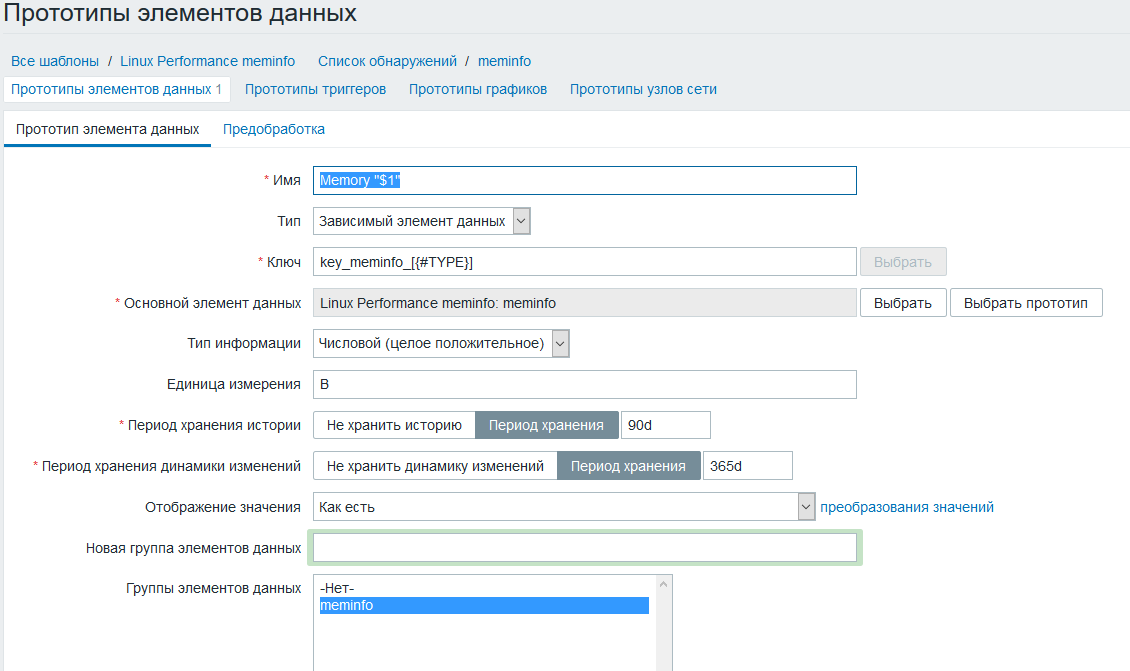
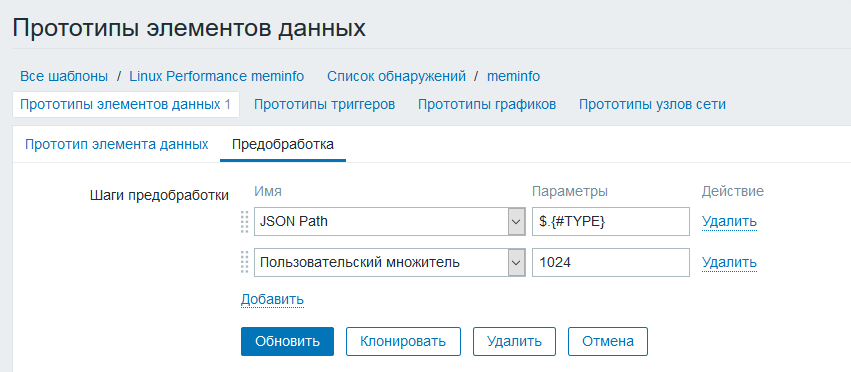
В пред-обработке настраиваем JSONPath + добавляем множитель так как цифры приезжают к килобайтах, а нужны в байтах.
Линкуем созданный шаблон с хостом
Пробуем
Должно получится
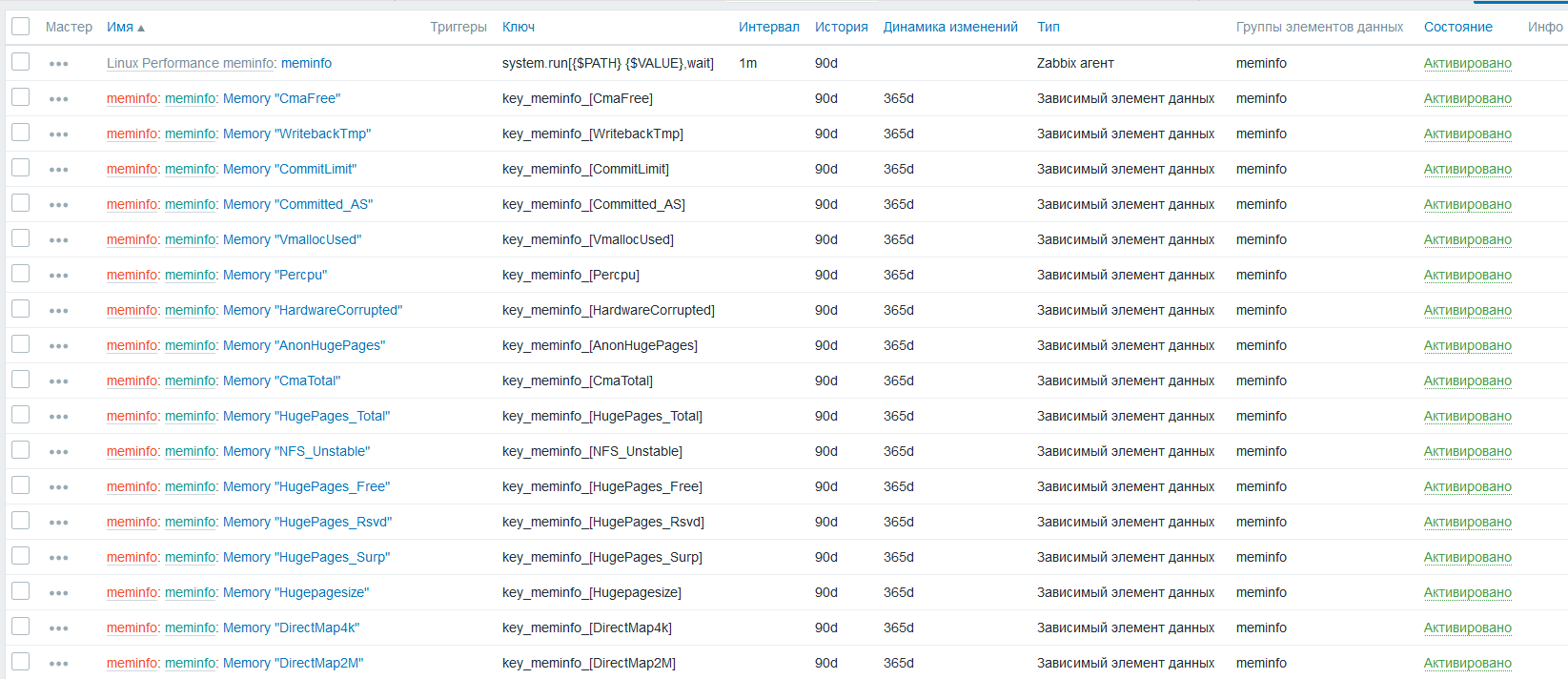
метрики нашлись, данные по ним распределились в правильном исчислении то есть в байтах

можем посмотреть и графики
Теперь самое интересное, как использовать gawk для создания JSON для discavery и для базовой метрики
Вот полный честный вывод JSON для discavery
root@server:~# gawk 'BEGIN {FS=":";ORS="";print "{\"data\": [ " }{b=gensub(/ +/,"","g",gensub(/kB/,"","g",$2) );$1=gensub(/\(|\)/,"_","g",$1);printf "%s{\"{#TYPE}\": \"%s\", \"{#VALUE}\": \"%s\"}",separator, $1, b;separator = ",";} END { print " ]}" }' /proc/meminfo {"data": [ {"{#TYPE}": "MemTotal", "{#VALUE}": "8139880"},{"{#TYPE}": "MemFree", "{#VALUE}": "147628"},{"{#TYPE}": "MemAvailable", "{#VALUE}": "4764232"},{"{#TYPE}": "Buffers", "{#VALUE}": "115316"},{"{#TYPE}": "Cached", "{#VALUE}": "6789504"},{"{#TYPE}": "SwapCached", "{#VALUE}": "9356"},{"{#TYPE}": "Active", "{#VALUE}": "4742408"},{"{#TYPE}": "Inactive", "{#VALUE}": "2733636"},{"{#TYPE}": "Active_anon_", "{#VALUE}": "2411644"},{"{#TYPE}": "Inactive_anon_", "{#VALUE}": "340828"},{"{#TYPE}": "Active_file_", "{#VALUE}": "2330764"},{"{#TYPE}": "Inactive_file_", "{#VALUE}": "2392808"},{"{#TYPE}": "Unevictable", "{#VALUE}": "0"},{"{#TYPE}": "Mlocked", "{#VALUE}": "0"},{"{#TYPE}": "SwapTotal", "{#VALUE}": "3906556"},{"{#TYPE}": "SwapFree", "{#VALUE}": "3585788"},{"{#TYPE}": "Dirty", "{#VALUE}": "368"},{"{#TYPE}": "Writeback", "{#VALUE}": "0"},{"{#TYPE}": "AnonPages", "{#VALUE}": "568164"},{"{#TYPE}": "Mapped", "{#VALUE}": "2294960"},{"{#TYPE}": "Shmem", "{#VALUE}": "2182128"},{"{#TYPE}": "KReclaimable", "{#VALUE}": "198800"},{"{#TYPE}": "Slab", "{#VALUE}": "340536"},{"{#TYPE}": "SReclaimable", "{#VALUE}": "198800"},{"{#TYPE}": "SUnreclaim", "{#VALUE}": "141736"},{"{#TYPE}": "KernelStack", "{#VALUE}": "7040"},{"{#TYPE}": "PageTables", "{#VALUE}": "90568"},{"{#TYPE}": "NFS_Unstable", "{#VALUE}": "0"},{"{#TYPE}": "Bounce", "{#VALUE}": "0"},{"{#TYPE}": "WritebackTmp", "{#VALUE}": "0"},{"{#TYPE}": "CommitLimit", "{#VALUE}": "7976496"},{"{#TYPE}": "Committed_AS", "{#VALUE}": "5189180"},{"{#TYPE}": "VmallocTotal", "{#VALUE}": "34359738367"},{"{#TYPE}": "VmallocUsed", "{#VALUE}": "25780"},{"{#TYPE}": "VmallocChunk", "{#VALUE}": "0"},{"{#TYPE}": "Percpu", "{#VALUE}": "24480"},{"{#TYPE}": "HardwareCorrupted", "{#VALUE}": "0"},{"{#TYPE}": "AnonHugePages", "{#VALUE}": "0"},{"{#TYPE}": "ShmemHugePages", "{#VALUE}": "0"},{"{#TYPE}": "ShmemPmdMapped", "{#VALUE}": "0"},{"{#TYPE}": "FileHugePages", "{#VALUE}": "0"},{"{#TYPE}": "FilePmdMapped", "{#VALUE}": "0"},{"{#TYPE}": "CmaTotal", "{#VALUE}": "0"},{"{#TYPE}": "CmaFree", "{#VALUE}": "0"},{"{#TYPE}": "HugePages_Total", "{#VALUE}": "0"},{"{#TYPE}": "HugePages_Free", "{#VALUE}": "0"},{"{#TYPE}": "HugePages_Rsvd", "{#VALUE}": "0"},{"{#TYPE}": "HugePages_Surp", "{#VALUE}": "0"},{"{#TYPE}": "Hugepagesize", "{#VALUE}": "2048"},{"{#TYPE}": "Hugetlb", "{#VALUE}": "0"},{"{#TYPE}": "DirectMap4k", "{#VALUE}": "773632"},{"{#TYPE}": "DirectMap2M", "{#VALUE}": "7606272"},{"{#TYPE}": "DirectMap1G", "{#VALUE}": "2097152"} ]} root@server:~#Вот так выглядит JSON для discavery
{"data": [ {"{#TYPE}": "MemTotal", "{#VALUE}": "8139880"}, {"{#TYPE}": "MemFree", "{#VALUE}": "147628"}, {"{#TYPE}": "MemAvailable", "{#VALUE}": "4764232"}, {"{#TYPE}": "Buffers", "{#VALUE}": "115316"}, {"{#TYPE}": "Cached", "{#VALUE}": "6789504"}, {"{#TYPE}": "SwapCached", "{#VALUE}": "9356"}, ..... {"{#TYPE}": "DirectMap4k", "{#VALUE}": "773632"}, {"{#TYPE}": "DirectMap2M", "{#VALUE}": "7606272"}, {"{#TYPE}": "DirectMap1G", "{#VALUE}": "2097152"} ]} root@server:~# root@server:~# gawk 'BEGIN {FS=":";ORS="";print "{\"data\": [ " } { b = gensub(/ +/,"","g", gensub(/kB/,"","g",$2) ); $1=gensub(/\(|\)/,"_","g",$1); printf "%s{\"{#TYPE}\": \"%s\", \"{#VALUE}\": \"%s\"}",separator, $1, b;separator = ",";} END { print " ]}" }' /proc/meminfoBEGIN {FS=":";ORS="";print "{\"data\": [ " }
FS=":"; — разделяет строку на части и передает разделившеся части в $1, $2 … $n
print "{\"data\": [ " — выполняется только один раз, в самом начале
Дальше происходит магия gawk организует сам цикл с перечислением всех полученных строк, принимая во внимание то что строки будут разделятся по «:» то мы в $1 получать всегда имя параметра, а в $2 всегда его значение, правда не очень в удобном формате
собственно это выглядит как: есть строка из цикла CommitLimit: 7976496 kB которая разделяется:
$1=CommitLimit
$2= 7976496 kB
Нужно предобработать обе строки
b = gensub(/ +/,"","g", gensub(/kB/,"","g",$2) ); содержится две функции gensub
Вложенная функция gensub(/kB/,"","g",$2) исключает из вывода kB а базовая gensub(/ +/,"","g", ........ ); исключает пробелы, получаем чистую цифиру.
Следом в имени параметров {#TYPE} нужно предусмотреть что недолжно быть символов скобок ( ) так как мониторинг их не перевариват, ни при создании метрик, ни при разнесении данных.
Сказанно — сделано, регуляркой уберем скобки из имени параметра, заменим поджопником нижней чертой _ $1=gensub(/\(|\)/,"_","g",$1);
После подготовленные параметры, собираем JSON и выводим
printf «%s{\»{#TYPE}\»: \»%s\», \»{#VALUE}\»: \»%s\»}»,separator, $1, b;separator = «,»;}
После того как все строки обработаны, gawk выполняет END { print " ]}" что закрывает JSON и финализирует.
Вот таким простым способом без скриптов можно сделать обнаружения и формирование JSON с данными, добавив метрики в мониторинг и получая максимальный эффект от простоты применения.
ссылка на оригинал статьи https://habr.com/ru/post/531386/
Добавить комментарий