Меня зовут Сергей Раков, я руководитель B2G-направления в компании «Ростелеком ИТ». Я хочу рассказать про язык Jira Query Language (JQL): как им пользоваться на практике, основные приемы, с какими проблемами мы сталкивались и как их решали.
 Оригинал картинки взят у deviniti.com/atlassian
Оригинал картинки взят у deviniti.com/atlassian
Таск-трекеров очень много, каждый подходит для решения одних задач и не очень помогает решать другие. Многими из них мы пользовались, но сейчас остановились на Jira — она наш основной инструмент. Лично мне очень нравится ее язык JQL, который сильно упрощает работу и позволяет из коробки иметь мощный и гибкий инструмент для поиска тикетов.
Из коробки в Jira существуют базовый и продвинутый поиски. Эти два варианта поиска позволяют решить бóльшую часть стоящих перед пользователем задач. Базовый поиск привычен глазу любого человека, кто хоть раз пользовался услугами интернет-магазинов — работает по точно такой же простой схеме. Есть множество фильтров: по проектам, типам задач, по исполнителю и статусу. Также можно добавить дополнительные поля по критериям, которые поддерживаются Jira.
Но возникает проблема, если нужно выйти за рамки базовых запросов. Например, если мы хотим найти задачи, которые были на конкретном исполнителе когда-либо, или найти все задачи, исключая один проект. Сделать хитрую выборку для проекта с одним статусом задач и исполнителем и еще одним исполнителем и другим статусом задач силами базового поиска уже сделать нельзя.
На помощь приходит продвинутый поиск. Синтаксис JQL очень похож на SQL. Но в JQL не нужно выбирать конкретные поля, которые будем селектить, указывать таблицы и базы данных, из которых будем выводить. Мы указываем только блок с условиями и работаем с сортировкой — все остальное Jira автоматически делает сама.
Все, что нужно знать для работы с JQL — это названия полей, по которым будем выбирать тикеты, операторы (=, !=, <, >, in, not in, was, is и т.д.), ключевые слова (AND, OR, NOT, EMPTY, ORDER BY и т.д.) и функции, которые из коробки доступны в продвинутом режиме (Now(), CurrentUser(), IssueHistory(), EndOfDay() и другие).
Поля
Jira при вводе в строку поиска сама выдает подсказки всех возможных значений, которые вы ищете: как по полям, так и по значениям этих полей. Для себя я недавно открыл интересное системное поле lastViewed. Jira хранит историю ваших просмотров тикетов.

Здесь представлены два варианта составления фильтров для просмотра последних задач. Первый — мой вариант с lastViewed, где Jira выдаст просмотренные мной задачи за последние семь дней, отсортированные по убыванию. Этот фильтр настроен на моем дашборде в виде гаджета, и я к нему часто прибегаю. Потому что тикет закрылся, вкладку и номер не запомнил, быстро открыл, посмотрел, какой был последний тикет.
Есть стандартный фильтр Viewed Recently. Он использует функцию IssueHistory(), сортировка тоже производится по полю lastViewed. Результат одинаковый, но способ, даже в Jira, можно использовать разный. Стоит отметить, что поле LastViewed и IssueHistory() возвращают только вашу историю просмотра — историю третьих лиц таким образом посмотреть не получится.
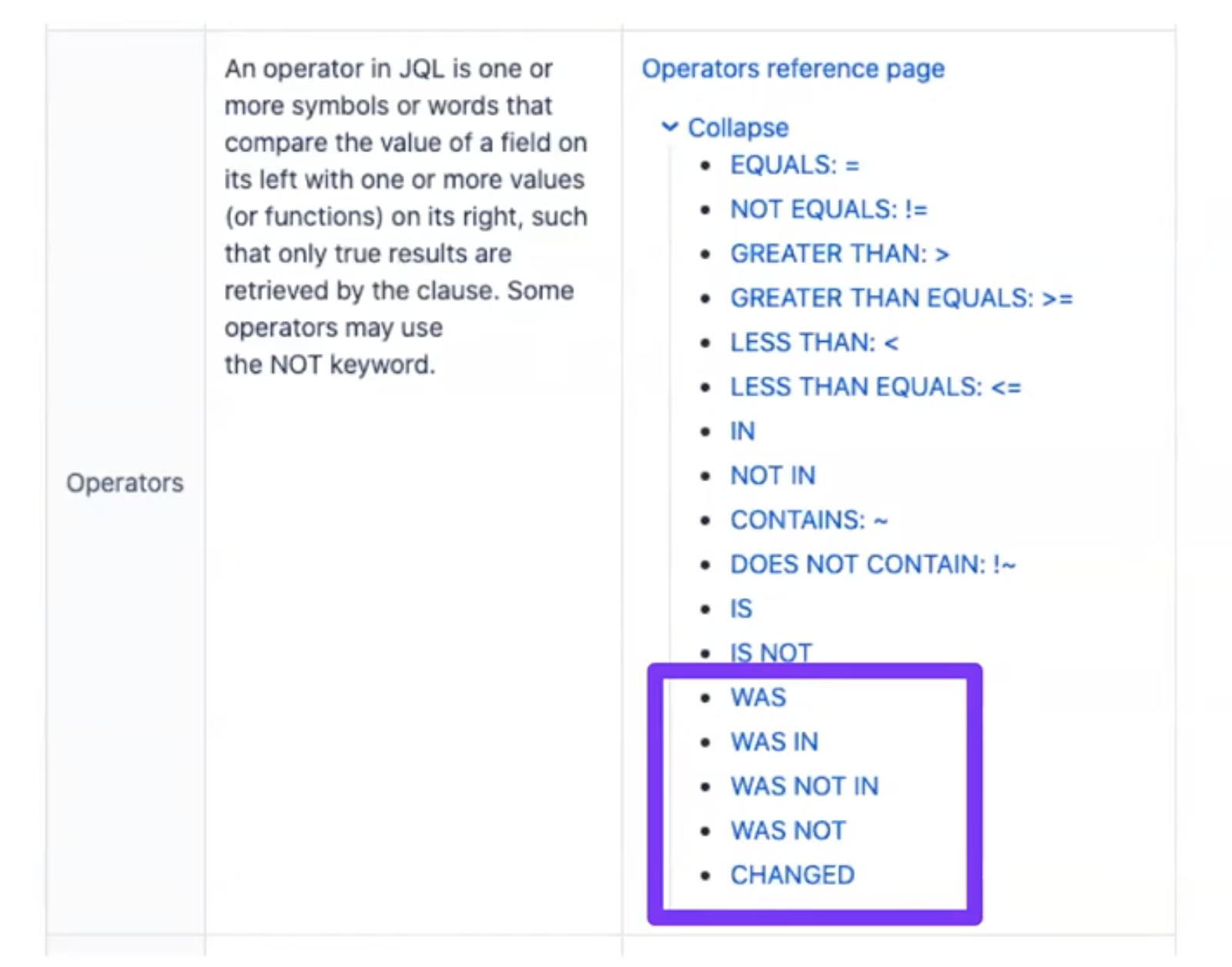
По большей части в Jira все операторы стандартные. Мне больше всего нравятся операторы WAS, WAS IN, WAS NOT IN, WAS NOT, CHANGED, потому что они работают с временем. В обычных базах данных такой возможности нет.

Jira из коробки позволяет работать с историческими данными. С помощью оператора WAS можно найти тикеты, где исполнителем был и есть User1. Если тикет был на мне, а потом перешел на кого-то еще, запрос покажет, что этот тикет когда-то был на мне. Понятно, что для более подробной выборки нужно добавить еще какие-нибудь условия, но мы к этому еще подойдем.
Правда, есть одна оговорка: Jira не хранит историю для текстовых полей: названий тикетов и их описаний. Там нельзя написать: «Выведи мне тикеты, в которых поле Summary содержало слово “Ростелеком”».
Второй пример с оператором CHANGED. Мы хотим получить тикеты, в которых исполнитель был изменен после 1 января 2020 года. Можно использовать другие дополнительные слова, например, BEFORE или знаки >, <, кому как удобнее, и конкретную дату. В этом же примере можно еще сделать отрицание и увидеть, какие тикеты на каких пользователях зависли: assignee not changed AFTER ‘2020-01-01’.
Ключевые слова

Основные ключевые слова — OR, AND, NOT. Они работают так же, как и логические операторы. Используя OR, мы получим полный набор тикетов из двух проектов A и B. Если нужно сузить выборку, используем AND. Пример — нам нужны тикеты из проекта A, по которым исполнителем был юзер B: project = A AND assignee = B. С отрицанием то же самое.
Функции
Согласно документации, в Jira 47 функций, но я никогда не использовал их все. Вот несколько, по моему мнению, основных:
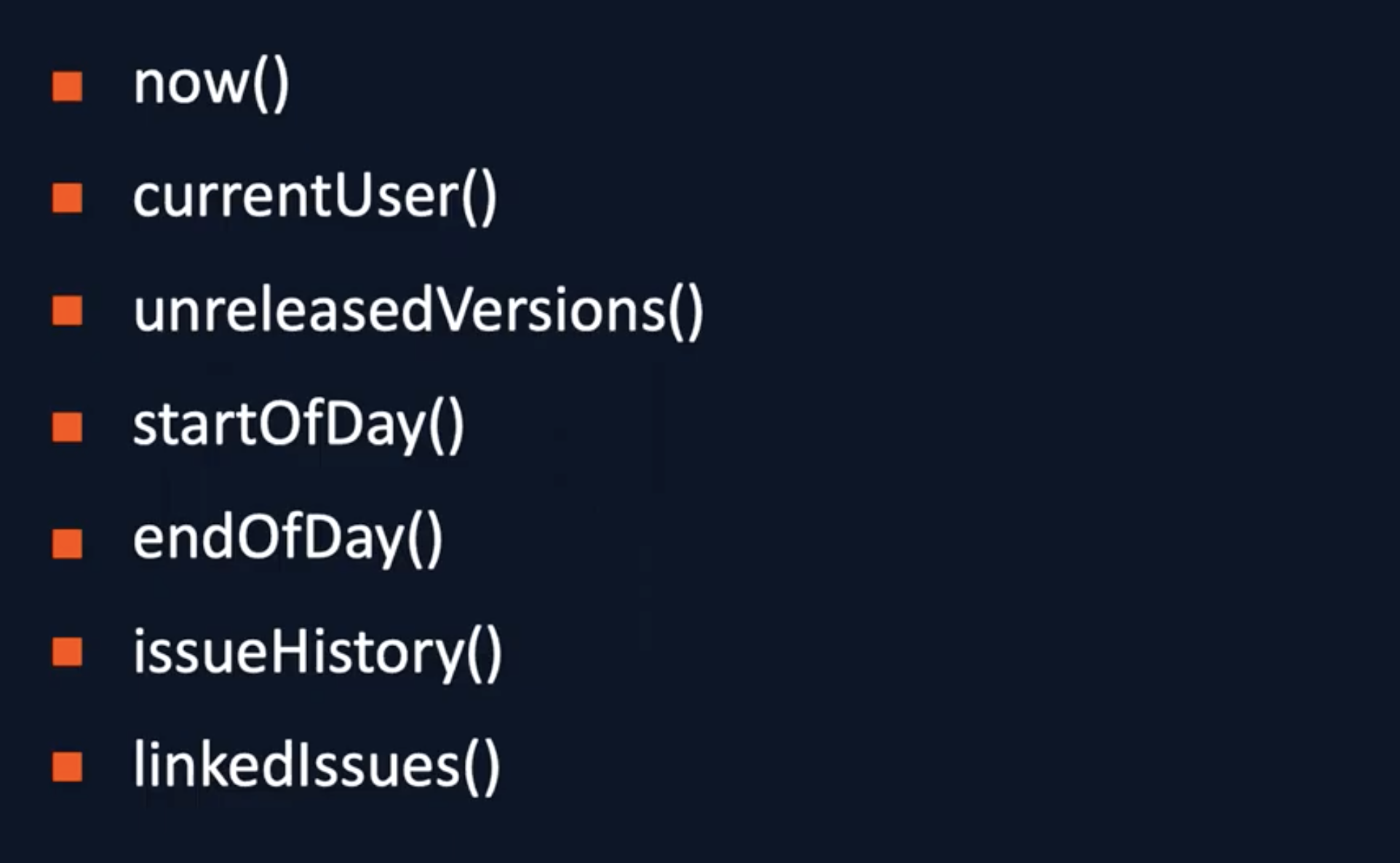
now() популярная функция, которая позволяет найти тикеты у которых, например, истек планируемый срок реализации.
currentUser() возвращает текущего пользователя. Jira содержит преднастроенные фильтры, в которых используется эта функция. С currentUser() можно делать универсальные поисковые запросы. Я так делал универсальный дашборд для всей команды разработки: напихал гаджетов на дашборд и в каждом указал вместо конкретного юзера currentUser(). Этот дашборд будет уникальным для каждого залогиненного пользователя, хотя конфигурация будет одинаковая.
unreleasedVersions() — это функция, возвращающая тикеты, которые находятся в невыпущенных версиях. Но она не возвращает тикеты, у которых версия не проставлена.
startOfDay() возвращает начало текущего дня. Есть функции для недели, месяца и года. Это же относится и к закрывающей функции endOfDay(). Они позволяют отвязаться от конкретных дат, им можно задавать аргументы: если написать startOfDay(-1), то вернется начало предыдущего дня. Если оставить все как есть, то отобразится начало дня текущего — на выходе будет время. Эти функции помогают избежать хардкода, мы очень часто ими пользуемся.
С issueHistory() я уже приводил пример, эта функция возвращает список только ваших просмотров.
linkedIssues() — функция, которая позволяет найти тикеты, которые прилинкованы к конкретному тикету.
Это самые простые функции. Но давайте немного углубимся и посмотрим на более сложные связи.
assignee was currentUser() AND fixVersion was in unreleasedVersions() AND created > startOfYear() Немного синтетический пример, но тем не менее. Это единый запрос, разделенный на три блока. После выполнения первой части запроса мы получим тикеты, на которых я когда-либо был исполнителем или являюсь им в данный момент. Очень важно, что WAS это не только был, но и есть.
Во второй части добавляется фильтрация: мы отфильтруем тот полученный скоуп моих тикетов, которые когда-либо находились в невыпущенных версиях на данный момент. То есть если был тикет в этой невыпущенной версии и она на текущий момент все еще не вышла, но потом я перенес тикет в другую версию, и она уже вышла, то тикет попадет в эту выборку.
Третье условие — дата создания. Мы фильтруем только те тикеты, которые были созданы с момента начала текущего года.
Функции ScriptRunner
Это плагин, значительно расширяющий возможности Jira. Обычно его используют для автоматизации процессов, но также он добавляет очень много дополнительных функций к JQL. ScriptRunner был нашим самым первым плагином, который мы поставили сразу, как только переехали в Jira — в конце 2018 года. Я очень активно просил поставить этот плагин, потому что без него не мог собрать данные по связям с эпиками. Мне, например, часто нужно было вернуть все тикеты эпиков по определенному запросу или все эпики для тикетов из подзапросов. ScriptRunner позволяет все это успешно проделывать.
Чтобы пользоваться функциями ScriptRunner, нужно в JQL добавить дополнительное слово issueFunction in или not in. Далее идет функция, например, epicsOf() — она возвращает эпики тикетов, которые удовлетворяют условиям подзапроса. Подзапрос идет на второй строке в скобках, и мы его рассмотрим подробнее.
issueFunction in epicsOf ("worklogDate >= startOfWeek(-1) AND worklogDate <= endOfWeek(-1)") AND project in ("Видео.B2G")В первом примере ищем эпики со списаниями времени за прошлую неделю. Лайфхак для тимлидов и менеджеров: если забыли заполнить тайм-шиты, и не помните, чем занимались прошлую неделю, выполнив этот запрос, увидите, над какими эпиками работала команда. И скорее всего, вы тоже работали над ними, ведь команда явно приходила с вопросами. В общем, этот запрос помогает вспомнить, чем занимались, и все нормально расписать.
Сам запрос начинает выполняться со скобок, то есть с подзапроса worklogDate — даты списания. Дальше идет уточнение >= startOfWeek(-1) — начало недели. Но обратите внимание на цифру -1: она означает, что нам нужен не этот понедельник, а прошлый. А еще worklogDate <= endOfWeek(-1), то есть она меньше окончания прошлой недели. Этот запрос будет выдавать тикеты, не важно какие — баги, таски, user story, — на которые сотрудники списывали времяс понедельника по воскресенье прошлой недели.
Фишка в том, что функции startOfWeek() и endOfWeek() позволяют отвязаться от даты. Вне зависимости от того, в какой промежуток текущей недели я делаю этот запрос, он отдаст мне один и тот же скоуп эпиков. Как только закончится эта неделя, он вернет эпики по ней. Удивительно, но не все пользуются этой возможностью: недавно изучал открытые запросы, которые публично расшарены, и увидел там много хардкодных дат. И есть подозрение, что эти даты постоянно меняются. Да и что говорить, в начале сам так делал.
Выполнив подзапрос, мы получаем обычный набор тикетов. Дальше вступает функция epicsOf, которая дает нам перечень эпиков, связанных с этими тикетами. А дальше идет фильтрация по проекту, ведь мне нужны эпики только по моему проекту, и не интересны все остальные.
Следующий запрос — эпики со списаниями в этом году, но без контрактов. Этот запрос появился из-за того, что мы используем Jira не только как таск трекер, но и для ведения финансового учета. Есть отдельный проект под контракты, которые мы ведем в виде тикетов, и используем как систему электронного документооборота: статусы постоянно меняются, мы линкуем контракты с эпиками, знаем, сколько у нас людей списалось в какой эпик, знаем, сколько это стоит, и затем по каждому контракту выставляем стоимость работ. Плюс через контракты переносятся трудозатраты в Redmine 2.0. То есть мы списываемся в Jira, а затем автоматические скрипты переносят наши затраты в в Redmine 2.0 по этим контрактам.
Когда эта автоматика заработала, ко мне начали прилетать запросы от коллег вида: есть эпики, трудозатраты которых нельзя перенести в Redmine, потому что там нет контрактов. Рассмотрим запрос подробнее.
issueFunction in epicsOf("worklogDate >= startOfYear()") AND issueFunction not in hasLinkType(Contract) AND project in ("Видео.B2G")Вложенный запрос означает, что нас интересуют тикеты, в которых были списания за этот год. Функция epicsOf перетекает из предыдущего примера и выдает нам список эпиков. Далее мы хотим отфильтровать по наличию контрактов.
Contract в скобках это тип внутренней связи, соединяющей контракты с эпиками. hasLinkType() — функция в ScriptRunner, возвращающая тикеты с этим типом связи. Но мне нужны тикеты, которые не содержат этот тип связи, и поэтому использую отрицание not in.
При выполнении первого условия у меня появился скоуп эпиков, актуальных в этом году. Далее отфильтровались эпики без контрактов, и в финале — по конкретному проекту «Видео.B2G». Таким образом я получил все эпики, с которыми можно работать.
И в конце хочу предложить пройти небольшой тест из трёх вопросов по теме этого поста. Займет 2 минуты. После прохождения увидите свою оценку.
Буду рад что-то уточнить или ответить на вопросы в комментариях, если они у вас есть.
Спасибо.
ссылка на оригинал статьи https://habr.com/ru/company/rostelecom/blog/532784/
Добавить комментарий