Вот и прошла конференция Joker 2020 для Java senior-ов. Для меня эта конференция стала особенной сразу по нескольким причинам — это первая "серьёзная" техническая конференция на которую я попал (в качестве зрителя), это моя первая онлайн-конференция, и это первая конференция, билет на которую я купил сам, а не за счёт работодателя.
Потраченные деньги, плюс возможность пересматривать любую трансляцию мотивировали меня просмотреть как можно больше материала, в результате даже через неделю после завершения конференции, я всё ещё продолжал сидеть и конспектировать выступление за выступлением. Совершенно нормальное поведение, хватит всем на меня так пялиться. Нет, я не пойду с добрым дядей доктором на обследование, спасибо.
Сразу предупреждаю, что даже так я не сумел просмотреть все трансляции, но если кому-то интересно, что же из этого получилось — добро пожаловать под кат.
Spring: Your next Java microframework
Презентация от Алексея Нестерова, в которой он доказывает, что Spring Boot может выглядеть как микрофреймворк, вести себя как микрофреймворк и даже крякать как микрофреймвок, а если так — то что же нам ещё нужно?
От микрофрейморках люди как правило ожидают несколько качеств: простоты разработки, "понятности" работы (simple vs easy), скорости работы, и готовности к работе в "облаке" (cloud-readiness, cloud-native). Как ни странно, Спринг может соответствовать всем этим критериям, и Алексей готов это доказать.
Лёгкость разработки
У Spring есть Boot Devtools, позволяющий, помимо всего прочего:
- получить LiveReload в браузере
- отключить кэширование шаблонов
- перезагружать сервис при обновлении файлов в classpath как локально, так и удалённо (но только не делайте так на продакшене, пожалуйста)
Скорость запуска
Спринг может быть быстр для запуска, но надо понимать что вообще делает ваш код. Если вы грузите сторонние сервисы, или лезите в БД при запуске — нечего пенять на Спринг! Помимо этого оптимизировать старт могут следующие советы:
- распакуйте executable JAR и укажите Main класс
- используйте spring-context-indexer
- используйте функциональные бины
- уберите Actuator
- используйте реактивный стек
Боттлнеком всегда может стать ваш CPU, может быть проблема ещё в JVM — попробуйте разные, например J9, попробуйте CDS, или скомпилируйте в нативный файл с GraalVM.
Если совсем ничего не остаётся (или если вам платят только за оптимизацию времени старта) — переделайте все бины на ленивые, и используйте ленивую загрузку для репозиториев. И пусть кто-то другой разбирается с проблемой тормозящего первого запроса.
Примечания в курсиве — от меня, это не слова презентатора.
Простота (понятность) в разработке
Тут презентатор потратил время на объяснение о том, чем в его представлении "easy" отличается от "simple". Очень надеюсь, что я понял правильно, что "easy" — это та "магия" Спринга, при которой ты просто вешаешь пачку аннотаций по коду и всё начинает работать "само собой" — на механизмах, зашитых в сам Спринг. В противовес этому есть "simple" — когда вы явно прописываете что идёт за чем, имеете полный контроль над кодом, но добавление новых компонент будет сопровождаться дополнительной работой с вашей стороны. Здесь не будет идеального решения, каждому разработчику/команде надо решать для себя, что им конкретно сейчас важнее.
Для обеспечения "понятности" разработки, в новых версиях Спринга появились такие альтернативы уже существующим механизмам:
- Functional beans вместо Component Scanning
- Functional routing вместо Route mapping
- Использование
@Queryили миграция с JPA вместо использования Generated Queries - Manual import вместо Autoconfigurations
Оказывается, пока я учился мигрировать конфигурацию сервисов с XML на аннотации спринга, умные люди сделали ещё и Functional beans с Functional routing на лямбдах. Все три метода поддерживаются и могут работать дополняя друг друга, но новая функциональная конфигурация должна быть чуть-чуть быстрее, потому что не использует рефлексию.
С помощью новых механизмов, весь (микро-)сервис можно описать исключительно из Main-а, не используя никаких других методов конфигурации.
Все четыре тезиса были подкреплены демонстрацией примеров, в этом случае — на использование applicationContext.registerBean(...) и RouterFunction, route().GET("/foo", request -> { ... }).
Cloud-ready
Напоследок, cloud-ready, но тут даже и обсуждать нечего — это движение по-сути, со спринга и началось, Spring Cloud содержит готовые механизмы для Circuit Breakers, конфигурации, Service registry, балансировка нагрузки, API gateways, даже Serverless с Spring Cloud Function.
Сприг поддерживает такие платформы как Kubernetes, Cloud Foundry, AWS, Alibaba и другие.
Презентатор так же посоветовал посмотреть на Java Memory Calculator проект для тех, кто редактирует Dockerfile руками.
Из диалога с экспертами и ответов на вопросы стало понятно, что Spring DevTools перезагружают весь сервис — если у вас какие-то свои сессии на Spring Security — они будут пропадать. Функциональные бины работают так же, как и обычные. Пост процессоры бинов могут быть зарегестрированны точно так же.
How we did SQL in Hazelcast
Презентация от Владимира Озерова, в которой он показал основные принципы проектирования своего распределенного SQL хранилища, основываясь на опыте своей компании.
Изначально у них было предикатное API для хранения in-memory индексов, но этого было не достаточно, так как не давало нужной гибкости. В первых версиях они перешли на простые запросы вида select ... from ... where с использованием индексов. Оптимизация SQL запросов — это очень сложные задачи, к счастью в мире есть несколько решений, и одно из которых они решили использовать — это Apache Calcite.
Процесс оптимизации запроса "по верхам" состоит из трёх шагов: анализ синтаксиса, анализ семантики, и оптимизация. По теме оптимизации есть множество исследовательских работ, например, “Access Path Selection in a Relational Database Management System”, “The Cascades Framework for Query Optimization”.
Ремарка от меня. До сих пор мне приходилось работать с SQL, например, с такими задачами как поддержка вызовов хранимых процедур на легаси системах, или использование больших и сложных SQL запросов, предоставленных нам от DBA. Так что название презентации меня очень заинтересовало, и я с интересом был готов послушать что-то новое. Однако, в этот момент даже до меня дошло, что что-то здесь не так, и тема как-то не похожа на ту, что я ожидал услышать, так что я решил "откланяться" и пойти слушать другой доклад. Тем не менее, тема должна быть интересна, и кто хочет — может досмотреть её самостоятельно.
Spring Boot “fat” JAR: Thin parts of a thick artifact
Здесь презентатор по имени Владимир Плизга, вместе с экспертами Андреем Беляевым и Андреем Когуном разобрал устройство "fat" JAR-а.
Вообще, технология "fat" JAR — не нова, и первые образцы технологии были представлены ещё в 1890 году Василием Звёздочкиным. В спринге же существует с первой версии.
При запуске такого архива происходит следующая цепочка вызовов:
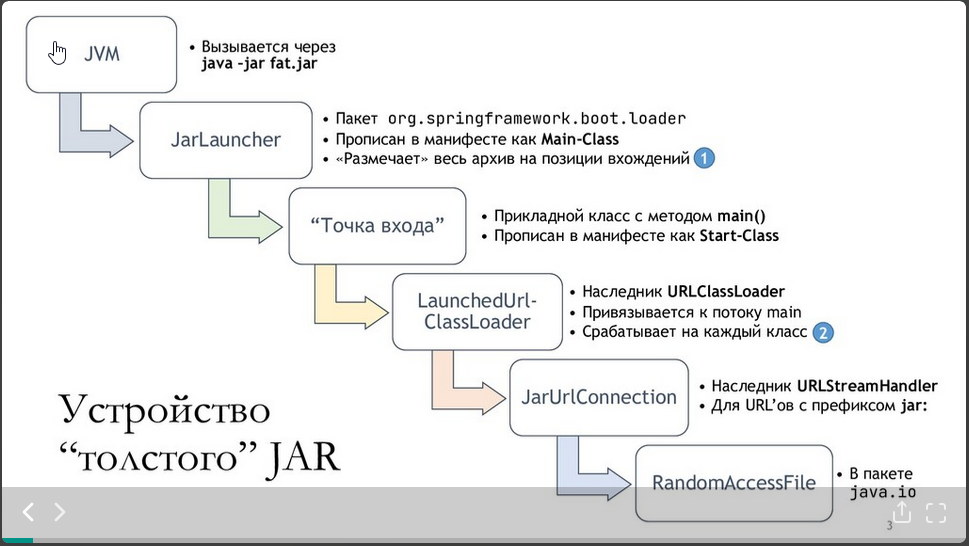
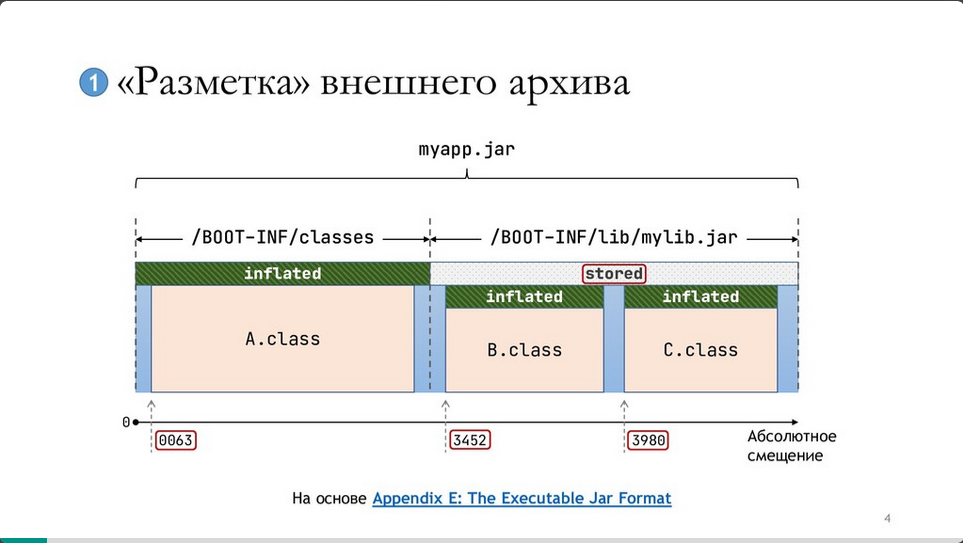
Внешний архив размечается так:
А вот так классы грузятся из архива:

Все слайды — из презентации Владимира, он поделился ими по следующей ссылке
Несколько замечаний презентатора: внутренние архивы не сжаты;
Spring вешает собственный наследник URLClassLoader-а на главный поток;
По-сути чтение классов работает как чтение из внешнего архива с правильным отступом с использованием RandomAccessFile.
Если что-то пошло не так, то загрузку "fat" JAR-а можно отдебажить следующей последовательностью действий:
- Скачать нужную версию Spring Boot-а
- Поставить брейкпойнт на
org.springframework.boot.loader.JarLauncher#main - Запустить джарку с параметром
-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:5005 - Подключиться дебагером из проекта
Тут завязалась дискуссия с экспертами, из которой прояснили ещё несколько моментов:
- Загрузка может поломаться: например — может появиться Class/MethodNotFoundException если порядок JAR-ок в "fat" JAR-е различается
- Запуск проекта из Идеи отличается от запуска самой джарки
Мораль — тестируйте fat JAR ещё на этапе разработки, что бы избежать проблем на продакшене
Использование "fat" JAR-а может потенциально поломать такие утилиты как jshell, jdeps, jmint, а так же пакет java.util.logging со всеми наследниками. Что бы это починить, постарайтесь не использовать ClassLoader.getSystemClassLoader(), или просто распаковывайте "fat" JAR перед использованием. Однако, даже со всеми этими недостатками fat "JAR" может помочь в миграции с application server’а на Спринг бут.
Поддержка докера с версии Spring Boot 2.3 (опционально — и с 2.4 — по умолчанию) в fat JAR добавился новый режим -Djarmode=layertools, позволяющий собирать артефакт по слоям, и это работает как с Maven так и с Gradle плагинами. Посмотреть слои можно командой
java -Djarmode=layertools -jar fat.jar list
По умолчанию идут в таком порядке: зависимости, загрузчик спринг бута, snapshot зависимости, сгенерированный код, код приложения. Что именно попадёт в какой слой — можно менять и настраивать. Далее, распакованный по слоям артефакт можно упаковать в докер вручную, с помощью докерфайла как-то так:
FROM .../openjdk-alpine:11 as builder WORKDIR application COPY fat.jar fat.jar RUN java -Djarmode=layertools -jar fat.jar extract ... FROM ...openjdk-alpine:11 WORKDIR application COPY --from=builder application/dependencies/ ./ COPY --from=builder application/spring-boot-loader/ ./ ... ENTRYPOINT ["java", "org.springframework.boot.loader.JarLauncher"]
Использование спрнгового JarLauncher’а даже на распакованном артефакте позволяет нам сохранить "магию" Спринга, и, например, читать версию артефакта из манифеста.
Из презентации я так же узнал об утилите "dive", которую презентатор использовал для просмотра слоёв в контейнере.
Разобравшись с ручной упаковкой докерфайла у экспертов возник закономерный вопрос: "А где тут кнопка <сделать хорошо>"?
Оказывается, есть и такое — разные инструменты, вроде Buildpacs, или Google Jib.
Разница между ними такая — если нужен полный контроль, то используйте Layertools, если нужна "магия" и размеры полученного артефакта не заботят — то Buildpacs, если нет возможности использовать докер, или невозможно обновить Спринг Бут до версии 2.3 — берите Jib.
Общие рекомендации с презентации:
- Проверяйте что идёт в class-path в IDE
- Обновляйте Spring Boot до последней версии
- Распаковывайте fat JAR в целевом окружении
- Запускайте проект через JarLauncher, не Main-Class манифеста
- Подумайте об удобстве использования с Buildpacs
Дополнительные ссылки:
- https://youtu.be/WL7U-yGfUXA
- https://reflectoring.io/spring-boot-docker/
- https://www.profit4cloud.nl/blog/building-containers-with-spring-boot-2-3/
Hidden pearls for high-performance-persistence in Java
Презентация от Свена Рупперта. Свен по максимуму воспользовался форматом онлайн презентации, и записал свою речь во время неторопливой прогулки по осеннему лесу с чашкой кофе. Несмотря на умиротворяющую атмосферу, сама презентация прошла в очень бодром темпе, а Свен успел перечислить и рассказать особенности множества интересных библиотек из мира Джавы.
JOOQ: кодогенератор для вызовов БД. Вот только я подумал, что у меня наконец-то появилась идея своего проекта, которой ещё ни у кого не было…

Позволяет генерировать DSL в зависимости от БД, со всеми таблицами и колонками, и использовать дальше в своих проектах. В бесплатной версии не поддерживает Oracle, SQL Server и MS Access.
Speedment. хотел дать ссылку на их сайт, но там ошибка 500 — по злой иронии не может подключиться к БД и так лежит уже неделю
Позволяет генерировать DSL под БД, но на потоках Java 8. Все фильтры и выборки задаются в лямбдах, выглядит интересно. Сюда же можно отнести и JPA Streamer — библиотеку, которая добавляет Java 8 streams поверх Hibernate.
Chronicle Bytes: даёт два класса Bytes — для создания массивов байтов и MappedBytes -для привязки буфера к файлу. Написал в стиле С/С++ — записывать можешь что угодно в каком порядке, доставать обратно — тоже. Описания полей/классов не сохраняются, если при чтении перепутаешь порядок или попытаешься прочитать лишнее — сам виноват.
Chronicle Map — быстрое key-value хранилище разработанное для высоконагруженных многопоточных приложений, не ограничено размерами RAM-а, и может сохранять данные на диск.
XODUS транзакционная schema-less встроенная БД, разработанная в JetBrains. Все изменения пишутся в иммутабельный лог.
MapDB совмещает движок БД и коллекции Java. Позволяет использовать словари, списки, для хранения данных либо вне сборщика мусора, либо на диске.
DB db = DBMaker.fileDB("/some/file").encryptionEnable("password").make(); ConcurrentNavigatableMap<Integer, String> map = db.treeMap(...);
Можно использовать для получения многоуровнего кеша с истечением срока хранения, для хранения не влезающих в RAM данных диске, для последовательных бекапов, для фильтрации и обработки данных. Всё это достигается за счёт того, что типы хранилиш можно совмещать: например завести словарь вне GC, пишущий часть данных на диск.
Microstream — проект, реализовавший собственную сериализацию для объектов, и хорошо умеющий работать с графами. В бесплатной версии не работает с Oracle БД, и не даёт параллельное чтение/запись. Стартовый класс — EmbeddedStorageManager, в нём можно задать корень графа, сохранить на диск. Позволяет хранить модели как есть, или в виде коллекций. Позволяет работать только с частями графов, но даже зацикленные графы для них не проблема. Могут быть проблемы с наследованиями.
Помимо этого Mictorstream устраивают хакатон с призовым фондом в 20к$, на котором Свен будет одним из членов жюри. До февраля есть возможность придумать какое-то интересное использование для этой библиотеки, выложить под лицензией Apache 2 и попробовать получить 5к$ на первом месте (всем участникам гарантируют майку).
Spring Patterns for adults
Последний крупный доклад, о котором я хотел бы здесь написать — это работа Евгения Борисова, которую он презентовал с приглашенными экспертами Андреем и Кириллом. Говорили много и интересно — по докладу видно, что Евгений отлично разбирается в теме и очень живо делится своими знаниями, я попробую передать лишь основное.
При запуске @ComponentScan, Спринг начинает сканировать все компоненты, включая унаследованные @Service/@Repository/@Controller/@RestController и даже @Configuration — это тоже компонента. Работает это потому, что Спринг не ищет конкретные аннотации, а проверяет каждую найденную и перебирает всех её предков. Таким образом можно писать собственные аннотации (как @MyCompanyController), наследующие, или аннотированные аннотациями Спринга, и они будут работать точно так же с остальными контроллерами.
Довольно распространённая ошибка — кто-то пишет @Lazy компонент (@Lazy Component, @Lazy @Service, …) и не понимает, почему этот компонент стартует вместе со всеми, даже когда им никто не пользуется. Проблема в том, что любой @Autowire для компоненты — автоматически означает, что компонента нужна, и заставляет Спринг её создать. Решение простое — с версии 4.3 можно сделать @Autowire @Lazy — и вместо компоненты будет прокси-объект, который создаст реальную компоненту лишь тогда, когда кто-то начнёт ею пользоваться.
При тестировании приложений всегда есть проблема контекста, который надо разворачивать для тестирования. Разворачивать всё и всегда — долго, разворачивать только часть контекста в зависимости от теста — всегда есть риск, что что-то где-то будет падать из-за какой-то части проекта, в результате всё будет скатываться в первую ситуацию — когда для каждого теста разворачивается весь контекст. Для решения этой проблемы на тестах можно использовать @ComponentScan(lazyInit = true) (либо spring.main.lazy-initialization=true в файле настроек).
Была интересная дискуссия о том, так ли полезна иньекция параметров конструктора, которая, в отличии от иньекции по полям не должна — в теории — позволить растянуться коду в классе и должна помочь избежать создание "божественных объектов", которые делают слишком много всего сразу. На практике же программист просто лепит @RequiredArgsConstructor и классы продолжают расползаться.
Была ещё более интересная дискуссия о том, как использовать квалификаторы. К сожалению, текстом и в виде конспекта её не пересказать, я могу лишь показать картинку "Айтишники на троих разбирают запутанный случай Spring Boot’а".
Далее, по паттернам. Для использования паттерна Chain of Responsibility в спринге можно инжектить списки. @Autowired List<Handler> handlers;заинжектит все компоненты, имплементирующие интерфейс Hangler — таким образом не надо будет их биндить по одному. Порядок будет произвольный, если нужен порядок, или какой-то особый список — то надо будет использовать BeanPostProcessor и собирать список самостоятельно из ApplicationContext.
Можно использовать Intrpspector.decapitalize() для получения имени бинов из имени класса.
Интересный пример того, как можно взять какой-либо старый фреймворк (например, из либы, которую нам нельзя менять) и заставить работать все старые легаси-компоненты в спринге. Делается это так с использованием ImportBeanDefinitionRegistrar
class LegacyBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar { // ... registerBeanDefinition() { Reflections scanner = new Reflections("com.legacy.package"); Set<Class<?>> classes = scanner.getTypesAnnotatedWith(LegacySingleton.class); for(Class<?> aClass : classes) { GenericBeanDefinition bd = new GenericBeanDefinition(); bd.setBeanClass(aClass); // bd.addQualifier(new AutowireCandidateQualifier(Legacy.class)); // можно добавлять свои квалифаеры beanDefinition.setScope(beanDefinition.SCOPE_SINGLETON); // например registry.registerBeanDefinition(Introspector.decapitalize(aClass.getSimpleName()), bd); } } }
Начать использовать этот регистрар можно в классе с аннотацией @Configuration @Import(LegacyBeanDefinitionRegistrar.class).
Далее, разобрали несколько вариантов того, как работать с паттерном Strategy & Command. Например, если мы хотим, что бы от клиента приходил запрос о том, как именно обрабатывать его запрос. Тут возникает соблазн начать использовать switch, но это опасный путь — сперва у тебя 5 кейсов, потом 6, там и 7-ой добавить вроде не страшно, потом вдруг 10 — но рефакторить уже сложно и какая разница, почему бы не добавить 11? После чего всё превращается в "ну да, у нас 234 кейсов, но рефакторить сложно, так что какая разница, что 235 добавим?". Чтоб избежать этой порочной практики, лучше сразу начинать писать как профессионалы.
Спринг позволяет сделать код, который вызывает нужный обработчик в зависимости от какой-нибудь строки несколькими методами.
@Autowired private Map<String, Handler> map; // key = bean id, Handler - @Bean
Тут ключь — это айди бина, имя класса — может быть полезно, но не всегда применимо. Обойти это можно добавив какой-нибудь myType() метод в общий интерфейс, и собирая словарь в консрукторе, как в следующем примере.
interface HandlerInterface { String myType(); void doWork(); } /// -- public class Controller { private Map<String, Handler> map; public Controller()(List<HandlerInterface> somethings) { map = somethings.stream.collect(toMap(SomethingInterface::myType), Function.identity()); } // ... }
Ну и последний вариант — создать словарь как @Bean, использовать тот же метод группировки, что и в предыдущем.
Далее был интересный вариант того, как сделать так, что бы бины регистрировались на лету. Было показано несколько деталей, мне самым интересным показалось вот что: @Autowired можно вешать на любой метод, не обязательно сеттеры. Таким образом можно писать компоненты, которые при создании будут идти и регистрироваться у контроллера (например, из прошлого примера), добавив всего лишь один метод в общий интерфейс:
@Autowired default void regMe(Controller c) { c.register(this.getType, this); }
Под конец было упомянуто, что AspectJ лучше не использовать на бизнес-логике — вас все будут ненавидеть. Но это не означает, что AspectJ бесполезен! С его помощью можно отлавливать, например, когда бросаются исключения определенного типа — и либо логгировать их особым способом, либо высылать емейл админу "эта штука опять сломалась".
Презентация длилась два с половиной часа, но смотрелась на одном дыхании — настолько живо и интересно её подавали, так что кто ещё не смотрел — настоятельно рекомендую.
И ещё…
Java Licensing Tips
От Юрия. Разобрал тонкости в обновлении с JDK_8_202 на 203 — начиная с этой версии надо платить деньги в Оракл. Лучший совет здесь — советуйтесь с юристами, как именно это работает для вас, но вообще есть три варианта:
- Не обновляться, остаться на версии 202
- Мигрировать на OpenJDK со свободной лицензией
- Провести внутренний аудит, разобраться где что нужно, попробовать уменьшить количество лицензий, начать платить
С точки зрения Оракл — "использование — факт уустановки JDK/JRE на ваш сервер продукции". Да, даже если вы ею не пользуетесь. Лицензии надо покупать на ядра процессора.
Например, если у вас есть сервер с двумя процессорами Intel Xenon E3 — 2680 v4, и у каждого процессора 14 физических ядер работает и Hyper Threading — на каждом из ядер по 2 логических ядра. В этом случае нужно купить 28 (логических ядер) * 0.5 (коэффициент процессора из таблицы) = 14 лицензий.
Всякие облака или кубернетес — всё-равно плати. Если JDK установлено для какого-то продукта Oracle (например, DB/WebLogic) то платить не надо, но и другим приложениям нельзя использовать этот JDK.
На обычных пользователей — платить надо по пользователю. Один пользователь сидит на 5 компьютерах — одна лицензия, пять пользователей сидят на одном компьютере — 5 лицензий.
How to tell "no" to an architect? Tips for sizing a microservice
Андрей довольно адекватно высказался по поводу микросервисов, что процесс их проектирования не должен быть безумным процессом рисование стреловек и коробочек, где каждая коробочка — свой микросервис. Если какие-то части продукта связаны, и одна часть не может быть изменена без другой — надо ли разбивать их на два микросервиса, когда можно оставить всё в одном? В конце концов, разбить один сервис в несколько вы всегда успеете.
Will robots replace programmers?
Довольно интересный рассказ Тагира, где он анализирует тренды развития инструментов программирования. На мой взгляд, доклад скорее оптимистичный — да, тупой рутинной работы становится меньше, но и робот никогда не сможет точно отловить все нюансы. Скорее всего будущее — в тандеме между разработчиком и вспомогательными инструментами, часть из которых будет разработана с использованием техник машинного обучения.
Заключение
Теперь, спустя три, кажется, недели могу сказать, что конференция была просто отличной. Для себя я узнал много нового, добавил всех презентаторов, кого нашел, в твиттере, успел даже попробовать кое-что у себя на проектах. Жаль, не было времени походить по залам в игровом виде, но думаю, это уже на другой раз можно будет отложить.
Этот конспект я делал на английском, слушая оригинальные трансляции. Не был уверен в том, нужны ли они кому-то, но оказалось, что интерес был — поэтому перевёл обратно на русский и получил эту статью. Сам я синьер не настоящий, опыта маловато, и я допускаю, что допустил неточности в некоторых темах. Тем более при переводе терминов на русский — сам я всю жизнь работаю на английском, переводить не привык. Тем не менее, я очень надеюсь, что я не исказил смысла оригинальных презентаций, и не внёс никаких ошибок от себя. Но если что — пишите, всё исправлю!
ссылка на оригинал статьи https://habr.com/ru/post/531666/
Добавить комментарий