Тринадцать лет мы ищем способы масштабировать разработку, чтобы при росте всё работало надежно и, при этом, быстро выпускались новые фичи. Когда-то важным казалось легко переименовывать колонки в БД. Теперь — пришлось менять всю архитектуру на ходу.
Это — третий ежегодный пост про разработку по итогам черной пятницы — недели максимальной нагрузки. Почему наконец думаем, что мы молодцы; что для этого сделали; почему столкнулись с трудностями и что планируем делать дальше.
Резюме: два года работали не зря
Пятый год подряд нагрузка на Mindbox примерно удваивается ежегодно. В ноябре 2020 мы обработали 8,75 млрд запросов к API, против 4,48 млрд годом ранее. Пик — 400 тысяч запросов в минуту. Отправили 1,64 млрд писем и 440 млн мобильных пушей. Год назад писем было 1,1 млрд, а пушей почти не было.
Динамика количества рассылок в неделю черной пятницы:
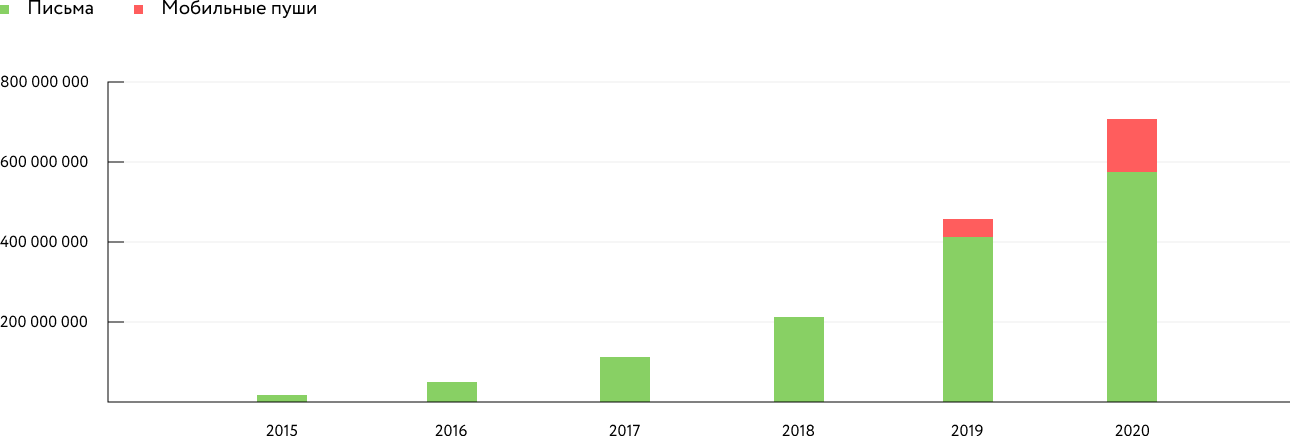
По нашим данным, это сравнимый с hh.ru уровень нагрузки по запросам к API, по нагрузке на базы данных — с Avito. Около трети от «Яндекс-такси» по запросам в минуту.
В 2018 и 2019 годах мы справлялись с этим плохо: клиенты страдали от отказов. По итогам 2018 я надеялся на быстрые улучшения и ожидал бизнес-роадмэп, выполнить который до сих пор удалось только на половину. В 2019 про роадмэп я решил умолчать, так как надежность ухудшилась, отказы начались уже в сентябре, а в черную пятницу повторились, несмотря на большой объем проделанной работы.
Сегодня можно делать вывод: справляться с ростом мы научились. Черная пятница в 2020 прошла без инцидентов, затронувших более одного клиента. Было два краткосрочных частичных отказа по вине внешней инфраструктуры, не нарушивших SLA. К сожалению, жалобы от нескольких самых крупных клиентов были, но это понятные нам единичные истории, над которыми мы работаем.
Более того, данные и субъективные отзывы пользователей показывают долгосрочный тренд увеличения качества разработки. Уменьшается количество дефектов — критических ошибок, отказов и случаев неудовлетворительной производительности.
На графике — нарушения внутреннего SLA (более строгого, чем внешнего), которое в этом году мы дополнительно сделали еще более строгим:

Количество нарушений внутреннего SLA у среднего клиента
Нам удалось за два года полностью «переизобрести» разработку, продолжая расти средним темпом 40% выручки в год (в 2019 — 431 млн, в 2020 — 618 млн) и выпуская новые фичи. Ощущения — примерно, как менять двигатель у машины на полном ходу.
Что сделали за два года:
— Попробовали централизованное управление разработкой (LESS) и отказались от него, выработав децентрализованные процессы, в том числе управления надежностью.
— Выделили до 50% ресурса разработки на улучшение качества, сформировали две (из восьми) выделенные инфраструктурные команды.
— Удвоили штат SRE. Теперь у нас семь SRE и круглосуточные дежурства.
— Сделали успешную школу разработчиков, закрывающую половину потребности в найме, научились нанимать сеньоров и лидов.
— Автоматизировали SLA и сбор других метрик разработки.
— Мигрировали критичные элементы инфраструктуры в «Яндекс-облако», полностью поменяв технологии разработки.
Это далеко не всё из запланированного. Продолжаем увеличивать объем выделенных на качество ресурсов. Ожидаем дальнейшего увеличения качества и ускорения выпуска новых функций в 2021 году и далее.
Кстати, мы регулярно пишем об обновлениях в продукте и ведем статус-страницу с историей инцидентов.
Истоки трудностей: 2008—2018
Mindbox — продукт со сложной бизнес-логикой, с 2008 года мы развивались как сервис для крупного бизнеса, с долей расходов на разработку более 30%. С точки зрения архитектуры это было традиционное монолитное приложение, но очень качественное: каждый день мы выпускали и до сих пор выпускам несколько обновлений монолита.
В 2014 рынок заставил нас повернуть в сторону более массового сегмента, в том числе е-commerce и retail. Это потребовало вложений в клиентский сервис, продажи и маркетинг.
Компания никогда не привлекала внешних инвестиций, всегда развивалась на свою прибыль. Вдобавок в 2017 году, через полгода после того как я стал CEO, мы столкнулись с нехваткой денег, я испугался и избыточно нарастил рентабельность. Всё это привело к сокращению расходов на разработку до 24% от выручки в 2018—2019 годах.
Одновременно с этим нужно было выпустить множество нужных новым клиентам функций — при быстром росте нагрузки и количества клиентов. Мы справились за счет задела исходного продукта и архитектуры, а также децентрализации — формирования автономных продуктовых команд.
К сожалению, техническая экспертиза таких команд не поспела за ростом компании, что дополнительно усугубилось пределами возможного в монолитной архитектуре. Технический долг копился, набор используемых технологий устаревал, зарплаты были ниже рынка. Нанимать инженеров становилось всё сложнее, несмотря на интересные задачи и уникальную культуру компании. К 2018 количество клиентов выросло в 10 раз, успех продукта стал очевиден, как и проблемы в надежности и разработке в целом.
Какие меры мы приняли
Процессы и ресурсы
Первой гипотезой была централизация: в 2019 внедрили LESS — это когда над одним проектом работает одновременно несколько команд. Начали совместно проектировать эпики и работать с надежностью, удалось увеличить предсказуемость и нащупать полезные практики проектирования. Однако по прошествии года стала очевидна неэффективность процесса: демотивация и снижение ответственности команд из-за отсутствия чувства «своих» фичей, большие затраты на управление, заниматься которым никому не нравилось.
За год совместного проектирования появилось видение децентрализованной архитектуры, которая позволила бы каждой команде отвечать за изолированные микросервисы, при этом продолжая поставлять единый продукт клиентам. Вместе с видением возникли бэклоги задач и стало понятно, что над инфраструктурой необходимо работать выделенными специалистами, не прерывая её бизнес-роадмэпом.
Договорились выделить 30% ресурса на технический долг на постоянной основе. Была сформирована первая инфраструктурная команда, начали снова выделять автономные команды. При этом сохранили ряд централизованных процессов совместной работы, прежде всего нацеленных на поддержание качества:
— проектирования,
— анализа дефектов,
— моделирования нагрузки на железо,
— демо и синхронизационных статусов.
Пришли к ответственности архитекторов и команд за метрики надежности и прогноз стоимости серверов. Дополнительно выделили 30% в каждой команде на техдолг и баги, при ожидании непрерывности поставки бизнеса.
В 2020 процессы устоялись: сформировали вторую инфраструктурную команду, наладилась поставка. Доля ресурсов на бизнес-задачи стала медленно расти с нижней точки около 50%, а доля багов стала уменьшаться:

Распределение ресурсов разработки по задачам. График не очень информативен, так как надежную метрику наладили относительно недавно, но подкрепляется впечатлениями с мест
За это время научились нанимать и онбордить SRE, отделили их от DevOps и офисного IT, сформировали процессы дежурства и описали роль.
Дефицит инженеров удалось снизить двумя способами:
— Создали школу разработки, выпускающую 8-12 junior-разработчиков в год. Это разработчики, имеющие опыт с нашим стэком, в способностях которых мы уверены. На сегодня в школе постоянно учатся 2 команды по 4 стажера.
— Планомерно повышали ФОТ разработки, благо бизнес-результаты позволили. Средняя зарплата в разработке выросла со 120 тысяч рублей в 2015, до 170+ на конец 2020 и продолжает расти. Это позволило нанять несколько новых сильных сеньоров и техлидов. Доля расходов на разработку поднялась до 28%, а количество людей выросло с 27 до 64.
Метрики, метрики и автоматические метрики
В нашей культуре принято управлять на основе данных, а не личного мнения. Эффективные метрики, пожалуй, один из сложных вопросов, на который современные методологии управления разработкой прямого ответа не дают.
Мы начали с автоматизации четырех метрик из книги Accelerate и ускорения конвейера поставки. Это не дало немедленных очевидных эффектов. Зато обмен опытом с hh.ru и «Яндекс-облаком» привел нас к автоматизации метрики нарушения SLA и автоматическому заведению дефектов. Тут мы ясно ощутили пользу и связь с прикладываемыми усилиями. График этой метрики с трендом — в начале поста.
Нескромно, но, думаю, мы одна из немногих в мире компаний, у которой есть API для клиентов, позволяющий получать метрику доступности компонентов платформы в реальном времени.
Описанная выше метрика доли багов и техдолга в команде тоже кажется полезной. Дополнительно считаем, как команды выполняют обещания, данные на спринт, а разработчики соблюдают сроки ежедневных и еженедельных задач.
Наконец, анонимные квартальные опросы (тексты с тех пор улучшились, но суть опроса не поменялась) и высокая оценка на «Хабр-карьере» показывают уменьшение несчастья разработки. Это касается оценки своего дохода относительно рынка, переработок и eNPS (данные пока только за два квартала).
Опрос о доходах разработчиков:
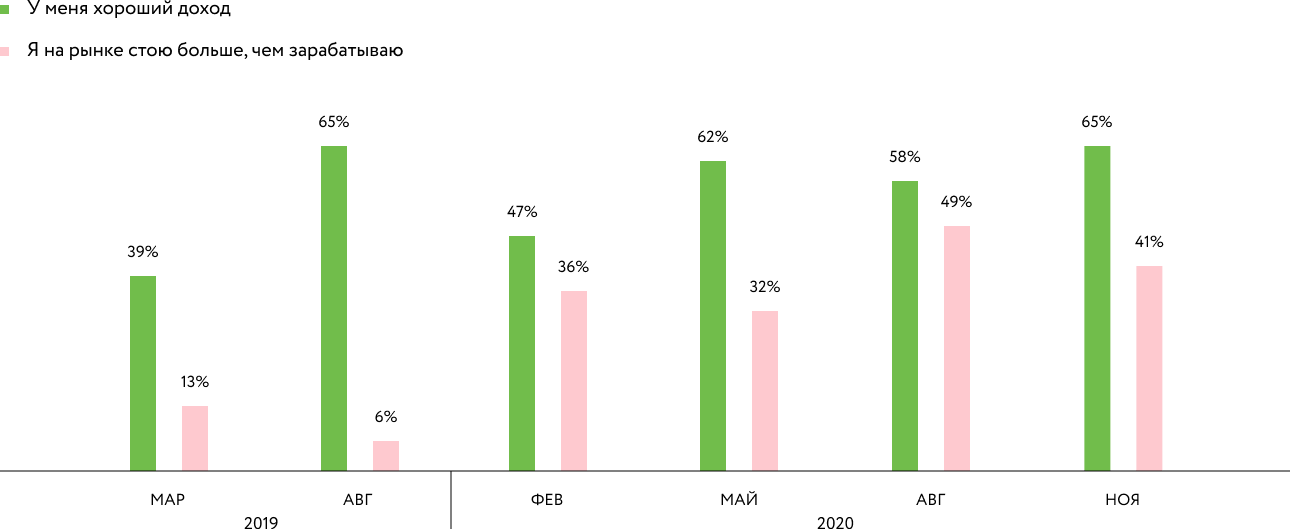
Опрос о переработках разработчиков:

eNPS разработчиков:

По шкале от 1 до 10 насколько вероятно, что порекомендуешь Mindbox как место работы?
Наконец, но не в последнюю очередь — техника
Всё это позволило организовать переписывание монолитного продукта — более 2 млн строк кода на IIS + ASP.NET + NLB / Windows Service / MS SQL — одновременно по всем направлениям:
— Микросервисный API и бэкенд, когда один запрос клиента к API Gateway прозрачно обрабатывается несколькими микросервисами, в том числе синхронные запросы (saga pattern).
— Микрофронтенд, где разделы интерфейса — отделенные от бэкенда SPA-приложения, способные размещаться в собственных репозиториях, со своим конвейером выкладки.
— Перевод мультитенантных микросервисов с MS SQL на распределенные масштабируемые хранилища: Cassandra, Сlickhouse. Kafka вместо RabbitMQ.
— Перевод приложения на .NET Core, linux и частичный переезд в Managed Kubernetes «Яндекс-облака». Тут же внедрение современных SRE и DevOps технологий: OctopusDeploy + Helm, Prometheus, Grafana, Graylog + Sentry, Amixr.IO.
Возможно, мы один из самых нагруженных клиентов «Яндекс-облака», поэтому о нашем внедрении и совместном с Яндексом преодолении трудностей CTO Никита Прудников рассказал на Yandex Scale 2020.
В нашей статье о черной пятнице можно почитать об основных применяемых нами подходах к масштабированию на примере компонента рассылок, который не сломался уже в прошлом году и не сломался в этом.
Дальнейшие планы развития
Несмотря на достигнутые результаты, должен сказать, что сделано меньше половины из запланированного. Впереди:
— Продолжение повышения доходов разработчиков и найма лучших сеньоров и техлидов.
— Третья команда школы разработчиков, позволяющая выпускать до 12 разработчиков в год.
— Продолжение перевода приложения на .NET, k8s и «Яндекс-облако», автомасштабирование, blue-green выкладка с моментальными rollback.
— Движение к автоматическому заведению инцидентов на статус-странице, избавление от ложных срабатываний SLA.
— Переход на .NET 5, EF.Core и PostgreSQL (а разработчиков на новые макбуки)&
— Выделение еще нескольких крупномасштабных кусков из монолита.
Призываю мотивированных расти .NET-разработчиков, техлидов и SRE-специалистов откликаться на наши на наши вакансии на hh.ru. Будет интересно, можно приобрести уникальный на рынке опыт и делать штуки.
Роадмэп платформы в 2021 году
Мы ощутили твердый фундамент под ногами, который позволяет надеяться, что мы снова можем выполнять обещания по бизнес-роадмэпу. Процессы децентрализованного планирования на год пробуем первый раз, но опрометчиво позволю себе сформировать публичные ожидания.
В этом году добавим в платформе:
— Конструктор сценариев.
— Хранение анонимных заказов и отчетность по ним.
— Больше быстрых отчетов в интерфейсе (как в нашем курсе).
— Интеграцию с BI.
— Новый модуль мобильных пушей, в том числе. новый SDK.
— Возможность быстро удалять любые сущности с учетом зависимостей друг от друга.
— Больше ML-алгоритмов и множество улучшений качества существующих.
— Больше страниц в новом дизайне с улучшенной отзывчивостью интерфейса.
— Упрощенную настройку стандартных интеграций и механик.
Планы на 2022 более грандиозные, но о них надеюсь написать через год, если оптимизм окажется оправдан.
Спасибо
Как и клиентские истории успеха, эта — заслуга конкретных людей, которым выражаю благодарность:
Никите Прудникову, CTO, за видение, системность и планомерное дожимание.
Роману Ивонину, ведущему архитектору, за терпение, построение команд, широкую ответственность, неформальное лидерство и бессонные ночи.
Игорю Кудрину, CIO, за фундамент SRE-экспертизы, видение и спасение всего, когда никто не знает как.
Ростиславу, Леониду, Дмитрию, Мите, Илье, двум Артёмам, Алексею, Сергею, Николаю, Ивану, Славе, Жене и другим неравнодушным разработчикам, продуктам, техлидам и SRE, сделавшим всё это реальностью. Простите, если кого-то не упомянул.
Отдельное спасибо — клиентам, которые терпели, не смотря на то что мы подводили, и дали возможность исправиться. Приложим все усилия, чтобы дальше становилось только лучше.
ссылка на оригинал статьи https://habr.com/ru/company/mindbox/blog/532888/
Добавить комментарий