CREATE TABLE task AS SELECT id , (random() * 100)::integer person -- всего 100 сотрудников , least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- каждый следующий приоритет в 2 раза менее вероятен FROM generate_series(1, 1e5) id; -- 100K задач CREATE INDEX ON task(person, priority); Слово «есть» в SQL превращается в EXISTS — вот с самого простого варианта и начнем:
SELECT * FROM generate_series(0, 99) pid WHERE EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 10 ); 
все картинки планов кликабельны
Пока все выглядит неплохо, но…
EXISTS + IN
… тут к нам пришли, и попросили к «супер» отнести не только priority = 10, но еще и 8 и 9:
SELECT * FROM generate_series(0, 99) pid WHERE EXISTS( SELECT NULL FROM task WHERE person = pid AND priority IN (10, 9, 8) ); 
Читать стали в 1.5 раза больше, ну и на времени выполнения это сказалось.
OR + EXISTS
Давайте попробуем воспользоваться нашим знанием, что встретить запись с priority = 8 много вероятнее, чем с 10:
SELECT * FROM generate_series(0, 99) pid WHERE EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 8 ) OR EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 9 ) OR EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 10 ); 
Обратите внимание, что PostgreSQL 12 уже достаточно умен, чтобы после 100 поисков по значению 8 делать последующие EXISTS-подзапросы только для «ненайденных» предыдущими — всего 13 по значению 9, и лишь 4 — по 10.
CASE + EXISTS + …
На предыдущих версиях аналогичного результата можно добиться, «спрятав под CASE» последующие запросы:
SELECT * FROM generate_series(0, 99) pid WHERE CASE WHEN EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 8 ) THEN TRUE ELSE CASE WHEN EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 9 ) THEN TRUE ELSE EXISTS( SELECT NULL FROM task WHERE person = pid AND priority = 10 ) END END;
EXISTS + UNION ALL + LIMIT
То же самое, но чуть быстрее можно получить, если воспользоваться «хаком» UNION ALL + LIMIT:
SELECT * FROM generate_series(0, 99) pid WHERE EXISTS( ( SELECT NULL FROM task WHERE person = pid AND priority = 8 LIMIT 1 ) UNION ALL ( SELECT NULL FROM task WHERE person = pid AND priority = 9 LIMIT 1 ) UNION ALL ( SELECT NULL FROM task WHERE person = pid AND priority = 10 LIMIT 1 ) LIMIT 1 ); 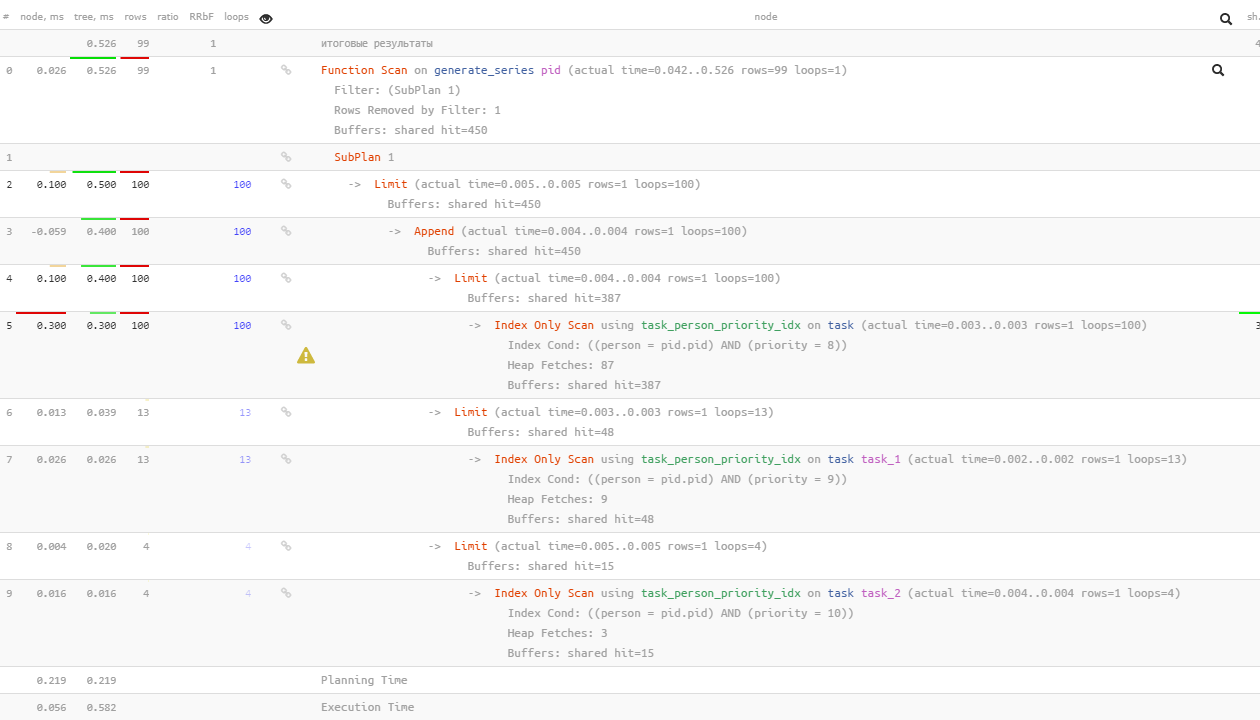
Правильные индексы — залог здоровья базы
А теперь зайдем на задачу совсем с другой стороны. Если мы точно знаем, что тех task-записей, которые мы хотим найти, в разы меньше, чем остальных — так сделаем подходящий частичный индекс. Заодно сразу перейдем от «точечного» перечисления 8, 9, 10 к >= 8:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT * FROM generate_series(0, 99) pid WHERE EXISTS( SELECT NULL FROM task WHERE person = pid AND priority >= 8 ); 
В 2 раза быстрее и в 1.5 раза меньше пришлось читать!
Но ведь, наверное, вычитать сразу вообще все подходящие task сразу — будет еще быстрее?..
SELECT DISTINCT person FROM task WHERE priority >= 8; 
Далеко не всегда, и точно не в этом случае — потому что вместо 100 чтений первых попавшихся записей, нам приходится вычитывать больше 400!
А чтобы не гадать, какой из вариантов запроса будет более эффективен, а знать это уверенно — пользуйтесь explain.tensor.ru.
ссылка на оригинал статьи https://habr.com/ru/company/tensor/blog/532852/
Добавить комментарий