
Для масштабирования коллектора мы используем многопроцессный подход, с одним управляющим и несколькими рабочими процессами, межпроцессное взаимодействие происходит только между рабочим и управляющим процессом.
Рабочие процессы выполняют одинаковые задачи — сбор, обработка и запись логов с серверов PostgreSQL. При этом сбор и запись — это по сути IO-задачи, в которых nodejs очень хороша. А вот обработка и парсинг планов запросов — это довольно CPU-емкая задача, блокирующая event-loop. Поэтому такие задачи лучше выносить в отдельный воркер или пул воркеров, передавая им данные на обработку посредством обмена IPC-сообщениями.

Раньше, для задачи обработки и парсинга планов запросов мы использовали именно такой подход. Но у него есть недостаток — большие объемы передаваемых данных по IPC могут привести к значительному увеличению затрат на сериализацию в JSON и обратно.
Например при передаче по IPC буфера, в которой содержится строка ‘test’ происходит передача строки:
'{"type":"Buffer","data":[116,101,115,116]}'При большом количестве передаваемых данных накладные расходы могут стать такими:

Решением для нас стало использование worker_threads, появившихся в Node.JS 10.5.0, работающих в рамках одного процесса и позволяющих использовать новые методы коммуникации между потоками.
Архитектура изменилась:
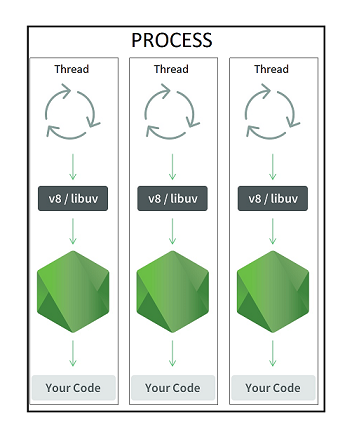
А вместе с ней и подходы к мониторингу. Например, использование CPU внутри worker_thread традиционным способом измерить не получится.
Т.е. раньше, для каждого процесса-воркера, мы измеряли CPU-usage с помощью process.cpuUsage() и process.hrtime() примерно так:
let startCpuUsage = process.cpuUsage(); let startTime = process.hrtime(); let n = 1000; while (n--) Math.sin(n); let {user, system} = process.cpuUsage(startCpuUsage); // время в микросекундах let time = process.hrtime(startTime); // наносекунды let cpuUsage = 100 * 1000 * (user + system) / (time[0] * 1e9 + time[1]); Но для процесса с worker_threads вызов process.cpuUsage() выдает процессорное время для всего процесса в целом, суммируя все его потоки. И такой же результат мы получим, если вызовем process.cpuUsage() изнутри worker_thread.
Почему так происходит?
Дело в то что process.cpuUsage() использует вызов uv_getrusage, а тот в ОС Linux выполняет системный вызов getrusage с параметром RUSAGE_SELF, т.е. возвращает статистику для вызывающего процесса как сумму по всем его потокам, при этом не важно из какого потока мы делаем этот вызов — во всех потоках он будет возвращать одинаковые значения.
Как же получить CPU-usage для worker_threads и почему в Node.JS нет встроенных методов для профилирования CPU worker_threrads?
Здесь есть ответ разработчика worker_threads.
Предложено два варианта — либо с помощью системного вызова gettid() получить tid для worker_thread и просматривать данные в /proc/${tid}, либо использовать getrusage() с параметром RUSAGE_THREAD, позволяющим получать статистику только для вызывающего потока.
Кстати, таким же образом можно получать метрики использования CPU и для основного потока процесса, без учета всех дополнительных потоков и worker_threads.
Итак, разобравшись с этим вопросом, мы стали искать готовые модули для мониторинга worker_threads, и не нашли… Поэтому сделали свой , заодно добавив в него выдачу всех остальных метрик для мониторинга Node.JS приложения. Серверные метрики мы уже получаем с помощью своей системы сбора метрик .
Мониторинг CPU
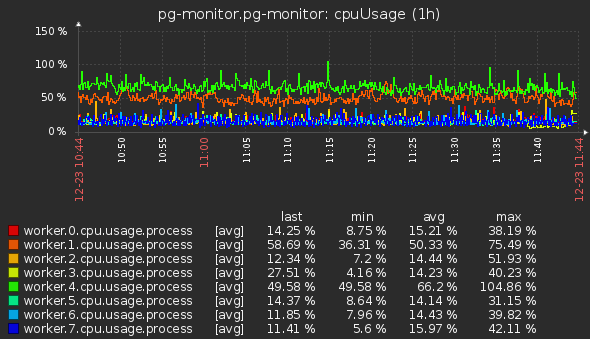
Для анализа использования CPU мы берем метрики от воркеров и worker_threads, а также метрики общей загруженности CPU и в разрезе ядер:
- Для воркеров в целом:
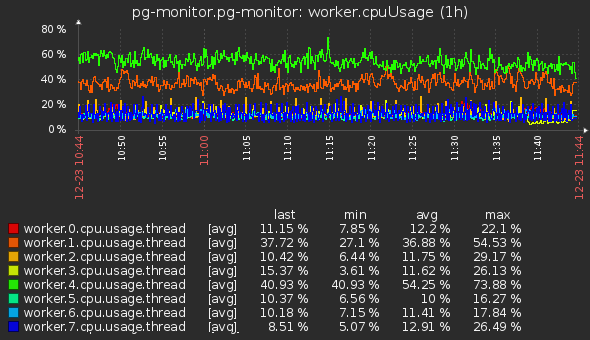
- Для основных потоков воркеров:
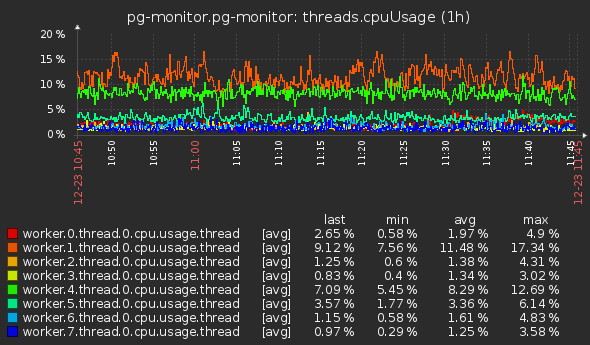
- Для worker_threads (по первым из пула, но полезным будет и суммарный в разрезе воркера):
- Общая загрузка CPU на сервере:

С метриками CPU разобрались, а что насчет профайлинга worker_threads?
Проверим, запустив этот небольшой тест с параметром node —prof
const { Worker, isMainThread} = require('worker_threads'); const crypto = require('crypto'); function mainTest() { let cnt = 10000; while (cnt--) crypto.randomBytes(cnt); } function threadTest() { let cnt = 10000; while (cnt--) crypto.randomBytes(cnt); } if (isMainThread) { let worker = new Worker(__filename); setInterval(mainTest, 1000); } else { setInterval(threadTest, 1000); }
В результате получили два isolate-* файла, для основного потока и для worker_thread.
Далее, с помощью node —prof-process <isolate_file> можем посмотреть нужный профайл.
Кстати, с опцией —no-logfile-per-isolate вместо нескольких isolate* файлов будет один — v8.log с суммарным результатом по всем потокам, включая основной.
И еще — используя опцию node —inspect или послав сигнал SIGUSR1 работающему процессу с целью снять CPU профайл в Chrome DevTools, мы увидим данные только по основному потоку.
Использование памяти
Также как и для CPU, снимая профайл в Chrome DevTools мы получим Heap snapshot только основного потока.
К счастью, с версии node 12.17.0 появилась возможность получить heap snapshot прямо из кода worker_threads с помощью вызова worker.getHeapSnapshot(), а с версии 11.13.0 также для основного потока вызовом v8.getHeapSnapshot()
const { Worker, isMainThread } = require('worker_threads'); const v8 = require('v8'); const fs = require('fs'); if (isMainThread) { let worker = new Worker(__filename); let mainArray = []; function mainTest() { let cnt = 100; while (cnt--) mainArray.push(`main-msg-${cnt}`); } process.on('SIGUSR2', () => { v8.getHeapSnapshot().pipe(fs.createWriteStream(`process_${process.pid}.heapsnapshot`)); worker.getHeapSnapshot().then((heapsnapshot) => { heapsnapshot.pipe(fs.createWriteStream(`process_${process.pid}_wt_${worker.threadId}.heapsnapshot`)); }) }); setInterval(mainTest, 1000); } else { let threadArray = []; function threadTest() { let cnt = 100; while (cnt--) threadArray.push(`thread-msg-${cnt}`); } setInterval(threadTest, 1000); }
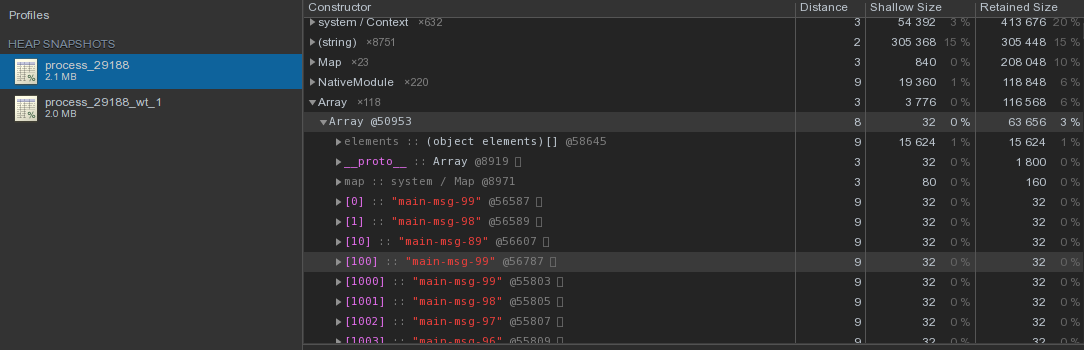
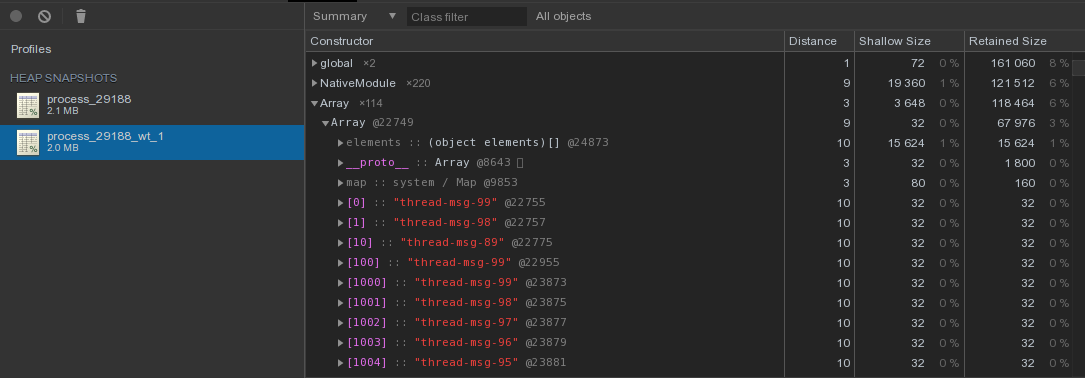
Послав сигнал SIGUSR2 процессу, мы получим два heapsnapshot, которые затем можно проанализировать в Chrome DevTools:
- Основной процесс:
- worker_thread:
Какие метрики памяти интересны для анализа?
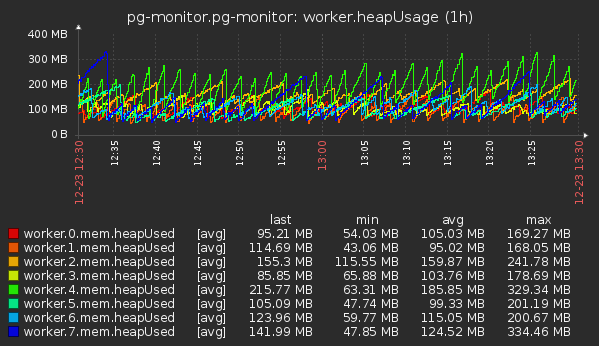
Мы используем те, что выдает process.memoryUsage() — rss, heapTotal, heapUsed, external.
И также v8.getHeapSpaceStatistics(), с его помощью можно получить данные по сегментам Heap — new_space, old_space, code_space, large_object_space.
rss всегда выдается для всего процесса, а остальные метрики — в рамках вызывающего контекста.
- Суммарный по воркерам:
- По воркеру:

- По worker_threads:
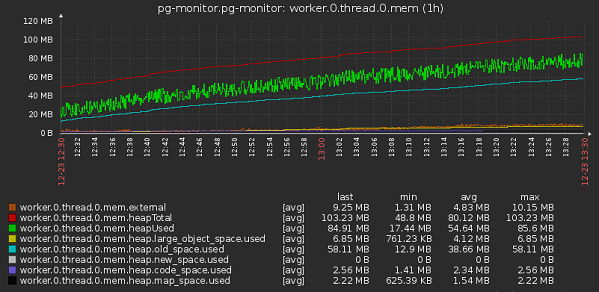
Сборка мусора
Т.к. в каждом worker_thread запускается свой инстанс Node.JS с v8/libuv, то и GC у каждого тоже свой и мониторить их надо по отдельности.
Для мониторинга GC нам нужно получать данные об общей продолжительности сборки мусора, а также количество запусков и время выполнения каждого цикла.
Уже довольно давно, с версии 8.5.0, в Node.JS появился механизм PerformanceObserver, позволяющий кроме всего прочего получить всю необходимую информацию по циклам GC.
const { PerformanceObserver, constants } = require('perf_hooks'); let stats = {}; let gcObserver = new PerformanceObserver((list) => { list .getEntries() .map(({kind, duration}) => { stats['gc.time'] += duration; switch (kind) { case constants.NODE_PERFORMANCE_GC_MINOR: stats['gc.Scavenge.count']++; stats['gc.Scavenge.time'] += duration; break; case constants.NODE_PERFORMANCE_GC_MAJOR: stats['gc.MarkSweepCompact.count']++; stats['gc.MarkSweepCompact.time'] += duration; break; case constants.NODE_PERFORMANCE_GC_INCREMENTAL: stats['gc.IncrementalMarking.count']++; stats['gc.IncrementalMarking.time'] += duration; break; case constants.NODE_PERFORMANCE_GC_WEAKCB: stats['gc.ProcessWeakCallbacks.count']++; stats['gc.ProcessWeakCallbacks.time'] += duration; break; } }) }); function resetStats() { Object.assign(stats, { 'gc.time': 0, 'gc.Scavenge.count': 0, 'gc.Scavenge.time': 0, 'gc.MarkSweepCompact.count': 0, 'gc.MarkSweepCompact.time': 0, 'gc.IncrementalMarking.count': 0, 'gc.IncrementalMarking.time': 0, 'gc.ProcessWeakCallbacks.count': 0, 'gc.ProcessWeakCallbacks.time': 0, }); } resetStats(); gcObserver.observe({entryTypes: ['gc'], buffered: true}); function triggerScavenge() { let arr = []; for (let i = 0; i < 5000; i++) { arr.push({}); } setTimeout(triggerScavenge, 50); } let ds = []; function triggerMarkCompact() { for (let i = 0; i < 10000; i++) { ds.push(new ArrayBuffer(1024)); } if (ds.length > 40000) { ds = []; } setTimeout(triggerMarkCompact, 200); } triggerScavenge(); triggerMarkCompact(); setInterval(() => { console.log(stats); resetStats(); }, 5000); Результат:
{ 'gc.time': 158.716144, 'gc.Scavenge.count': 11, 'gc.Scavenge.time': 135.690545, 'gc.MarkSweepCompact.count': 2, 'gc.MarkSweepCompact.time': 22.96941, 'gc.IncrementalMarking.count': 2, 'gc.IncrementalMarking.time': 0.056189, 'gc.ProcessWeakCallbacks.count': 0, 'gc.ProcessWeakCallbacks.time': 0 }
Этот метод работает как в основном потоке так и в worker_threads, для нашего коллектора мы получаем графики с метриками за секунду:
- По воркерам
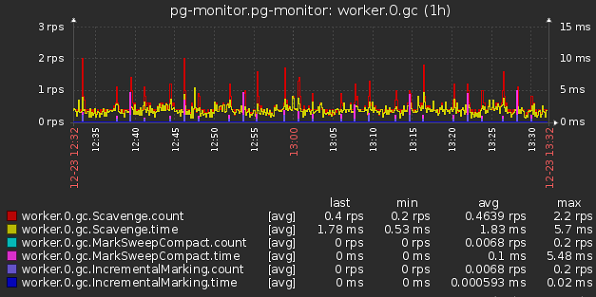
- По worker_threads
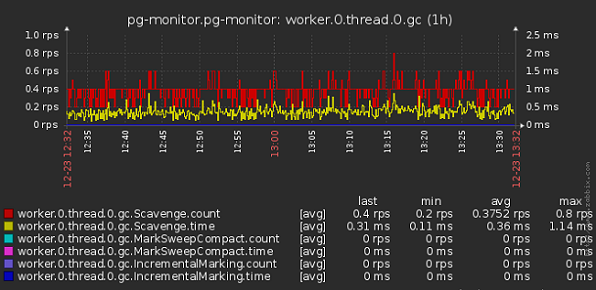
- Общее время GC в разрезе воркеров
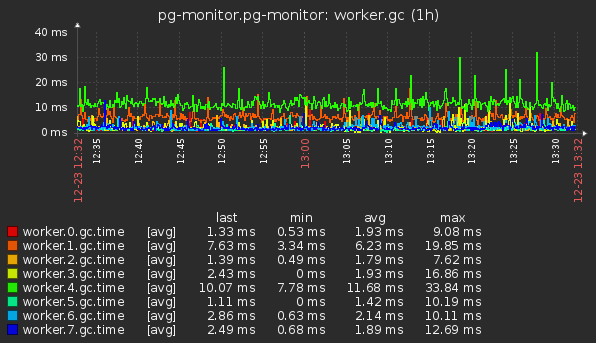
- Общее время GC в разрезе worker_threads

Event-loop latency
Для мониторинга задержек event-loop удобно использовать появившийся в версии 11.10.0 monitorEventLoopDelay — тут можно получить не только среднее и предельные значения, но и различные перцентили.
Мы используем max, min, mean, и percentile(99):
- Суммарный по всем воркерам
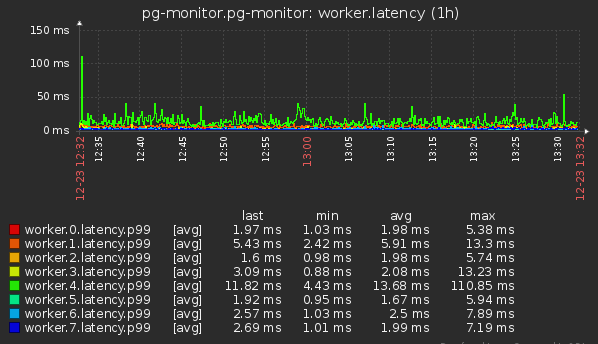
- Суммарный по worker_threads

- По воркеру
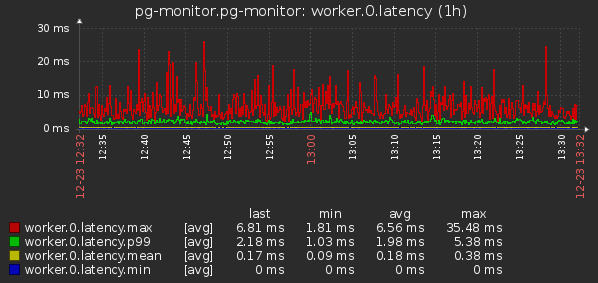
- По worker_thread

Мониторинг пула worker_threads
Системные показатели работы пула уже приведены выше, а здесь поговорим о метриках производительности многопоточного приложения.
При старте каждый воркер коллектора запускает пул с одним worker_thread, который обрабатывает очередь поступающих планов запросов.
Дополнительные worker_thread запускаются при увеличении размера очереди и при нахождении задач в очереди дольше определенного времени. Также они автоматически завершаются после периода неактивности.
const SPAWN_LAG = 2000; this._queue = []; assignTask(msg) { if (this.mainExplainer.ready === true) { this.mainExplainer.ready = false; this.mainExplainer.sendMessage(msg); } else if (this._idleExplainers.length > 0) { let explainer = this._idleExplainers.pop(); clearTimeout(explainer.timeoutIdle); explainer.sendMessage(msg); } else { this._checkAndStartNew(msg); } } _checkAndStartNew(msg) { let ts = Date.now(); let q = this._queue; if (msg && process[hasFreeRAM]) q.push({msg, ts}); if (this._canCreateExplainer && q.length > this._workersCnt() && q[0].ts + SPAWN_LAG < ts) { this._createExplainer(); } } explainer.on('explainDone', (msg) => { explainer.pulse(); }); explainer.pulse = () => { if (this._queue.length > explainer.id) { explainer.sendMessage(this._queue.shift().msg); } else if (this._isMain(explainer)) { explainer.ready = true; } else { this._idleExplainers.push(explainer); explainer.unpool(); } };
Важными метриками пула worker_thread являются размер очереди и количество работающих потоков:

Кроме этого мы мониторим скорость и производительность worker_thread и воркеров в целом:
- Скорость обработки планов запросов:

- Производительность воркеров по количеству задач:

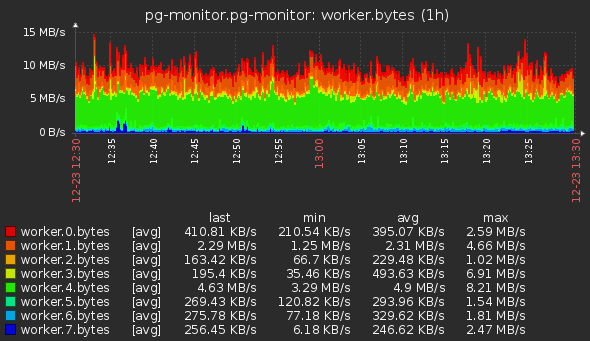
- Производительность воркеров по объему данных:
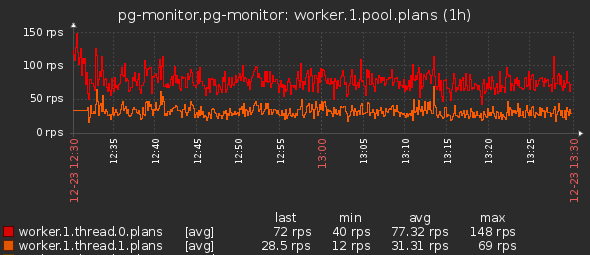
- Производительность worker_thread по количеству задач:
- Производительность worker_thread по объему данных:

Заключение
Мы рассмотрели особенности мониторинга многопоточного приложения Node.JS.
Для комплексного анализа работы приложения необходимо отслеживать массу показателей — метрики по серверу в целом, использование приложением системных ресурсов, метрики среды выполнения, а также различные показатели самого приложения. В общем всего, что включает в себя APM.
ссылка на оригинал статьи https://habr.com/ru/company/tensor/blog/533738/
Добавить комментарий