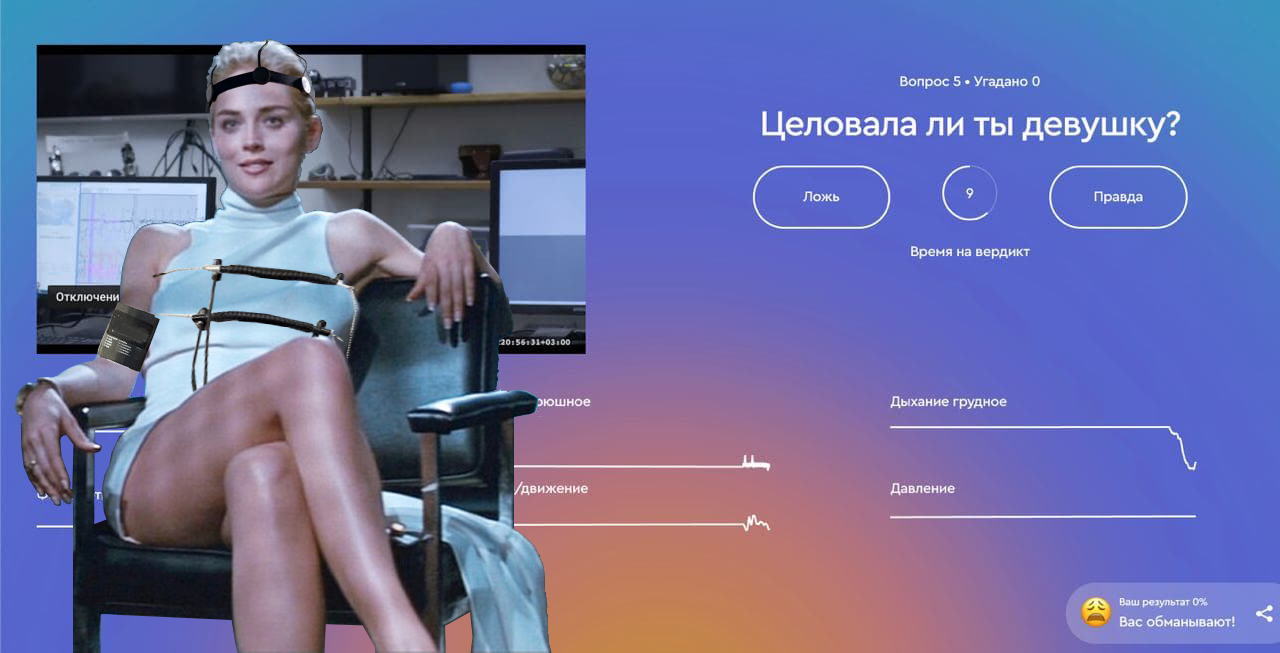
Мы очень любим спецпроекты. В начале декабря мы провели еще одну онлайн-игру, на этот раз с детектором лжи.
Это было 7-часовое онлайн-шоу, где девушек подключали к полиграфу и они отвечали на вопросы зрителей. Из комнаты велась прямая трансляция, на сайте проекта можно было отслеживать все показатели девушки во время ответа: дыхание, сердцебиение, проводимость кожи, давление и потоотделение.
Мы прикрутили к сайту геймификацию и каждый раз после ответа игроки получали 15 секунд, чтобы решить, правду говорит девушка или лжет. За правильные ответы набирались баллы.
В реализации этот проект оказался довольно сложным — рассказываем, как все было устроено с психологической и технической стороны.
Идея игры: режиссура, подбор актрис и вопросов
Первоначальная идея игры была другой: автор оригинальной идеи предлагал дозваниваться до девушек в прямом эфире, выводить их на разговор и смотреть, как их показатели меняются. Такое полностью интерактивное шоу, где уверенные в себе молодые люди могут публично проверить свои навыки беседы и получать максимально честную обратную связь от девушек без возможности соврать.
Это был крайне ненадежный сценарий, и я объясню почему.
Есть известный принцип 1%: в каждом интернет-коммьюнити есть 90% потребителей контента, 9% контрибьюторов и всего 1% тех, кто сам создает контент. Это не научное знание, но я в него верю: в моей практике оно часто подтверждалось.
Риск того, что девушки будут сидеть и ждать звонка, а эфир станет тягомотным ожиданием, был слишком велик. Так мы переработали концепт и решили, что каждая девушка, за отведенный ей час, должна рассказать короткую историю своей жизни. Структуру рассказа определяли заранее заготовленные вопросы, которые в общих чертах рисуют ее образ, как человека: как она относится к карьере, любви, смерти, сексу, дружбе, какие решения принимает, чего боится, за что готова бороться.
Мы хотели добиться максимальной вовлеченности от зрителя и истории должны были быть интересными — так, чтобы включил и залип надолго. Это значило подойти к задаче как фильм-мейкеры: учесть правила построения сюжета, выбрать актрис с навыками рассказчиков, создать законченные истории с завязкой, серединой и концом. В историях не должно было быть провисаний: в мире, полном контента, любую скучную историю закрывают быстро.
Как мы проводили кастинг девушек
Для начала надо было правильно выбрать рассказчиков, которых подключат к полиграфу.
Мы искали открытых и эмоциональных девушек, таких экспрессивных экстравертов, которые готовы и посмеяться, и расплакаться, и не боятся камеры. Последний пункт был особенно важен — чтобы девушки не смущались показывать свои эмоции и лишний стресс не влиял на результаты полиграфа. Сделали кастинг среди студенток актерских ВУЗов из 120 претенденток выбрали всего 6. Мы искали разные типажи экспрессивных девушек — милых, и напористых, немного стеснительных, в общем, чтобы истории в кадре были быть разными.
6 девушек, потому что игра должна была продлиться 7 часов, а любой человек за 60 минут на детекторе лжи успокаивается, привыкает и его показатели смазываются.
Дальше надо было каким-то образом срежиссировать истории, которые девушки будут рассказывать. За 60 минут каждая девушка должна была стать «родной» зрителю, как персонажи сериалов, которым симпатизируешь.
Как срежиссировать историю, сюжет которой не знаешь
Мы не могли заранее обсудить с девушками истории из их жизни и узнать, где лежит клад. Как мы уже рассказывали в статье про работу полиграфа, он показывает не правду или ложь, а всего лишь реакцию на стресс. Если вопросы не являются неожиданностью, показатели девушки во время стрима будут просто ровной линией и игры не получится.
Второй нюанс был в том, что вопросы на детекторе лжи подразумевают ответы «да» или «нет», без рассуждений. Это легко решалось четкой инструкцией актрисам: сначала однозначно ответить на вопрос, затем рассказать краткую историю, связанную с этой темой.
Так как же структурировать историю, которой ты не знаешь?
Нам был доступен только один инструмент: вопросы. Надо было каким-то образом придумать и в правильном порядке расположить 70 вопросов, каждый из которых начинал какой-то маленький эпизод общего рассказа.
Мы не стали изобретать велосипед и обратились к проверенным механикам из учебников для сценаристов, в частности, к классическому труду Memo. Секреты создания структуры и персонажей в сценарии Маккенна и Воглера. Горячо советую эту книгу, если вам интересна работа сценариста и вы любите рассказывать истории (даже друзьям за ужином), это настоящий альманах сторителлера.

Если кратко, то чтобы зритель «вошел в шкуру» персонажа и начал ему сопереживать (то есть не выключил кино), надо раскрывать героя в 4 этапа.
- Дать немного узнать человека: к какому базовому характеру он принадлежит
- Рассказать о нем что-то хорошее, что вызовет симпатию, Воглер называет это «дать, за что полюбить»
- Поставить героя в непреодолимую ситуацию, которая вызывает у него стресс. Тут зритель начинает сочувствовать, если все сделано правильно
- Дать ему решить ситуацию, изменив себя к лучшему, и закончить историю
Так мы и поступили. Написали порядка 200 вопросов, сразу вычистили скучные и оставили 100 «горячих». Затем разделили их на категории и сделали предположение, какой, скорее всего, будет на него история: например, если спросить про самый стыдный эпизод жизни – это один эмоциональный окрас и уровень напряжения. Если спросить про страхи — другой. Если про первую любовь — третий.
В начале были вопросы, ответы на которые дают базовые характеристики, потом хардкорные (те самые, которые не принято задавать в приличном обществе — про деньги, страхи, секс и тд) и завершили милыми историями.
Мы не смогли все сделать идеально, но результат был хорошим: эта была самая вовлекающая игра за всю нашу историю спецпроектов. Показатель удержания был высоким: люди подключались и оставались на несколько часов, сам ntsaplin пропустил обед в этот день 🙂
Давайте перейдем к технической части, там тоже было много интересного.
Техническая часть проекта: Kotlin, война за синхронизацию и реверс-инжиниринг полиграфа
Из каких частей состоял проект
Всего в игре было 5 частей:
- Интерфейс игрока — основной сайт игры, где велась трансляция и можно было сыграть
- Интерфейс полиграфолога — веб-страничка, на которой полиграфолог отмечал свой вердикт. Именно с ним и соотносились ответы игроков
- Интерфейс девопса — специальный образ в маркетплейсе c Ubuntu. Подключившись к нему по SSH можно было задать вопрос девушке
- Интерфейс модератора — страничка, где модератор пропускали или отклонял вопросы от зрителей. Вопрос можно было отредактировать (например, поправить грамматику и орфографию
- Сервер, принимающий вопросы от девопсов и передающий их в интерфейс полиграфолога
Трансляция велась отдельно через Open Broadcaster Software (OBS) и YouTube.
Как все это было связано
Вся наша система состояла из сервера и кучи клиентов. Одна группа была многочисленной — много клиентов девопсов, один клиент — веб страничка модератора, веб-страничка полиграфолога и много веб-страничек игроков.
Был еще один отдельный клиент системы — программа написанная на Котлине и работающая на компьютере полиграфолога. Всей игрой управлял именно он, обычный стационарный компьютер на Windows. ОС была принципиальной — программа Sheriff 7, в которой работал наш полиграфолог Миша есть только под Windows.
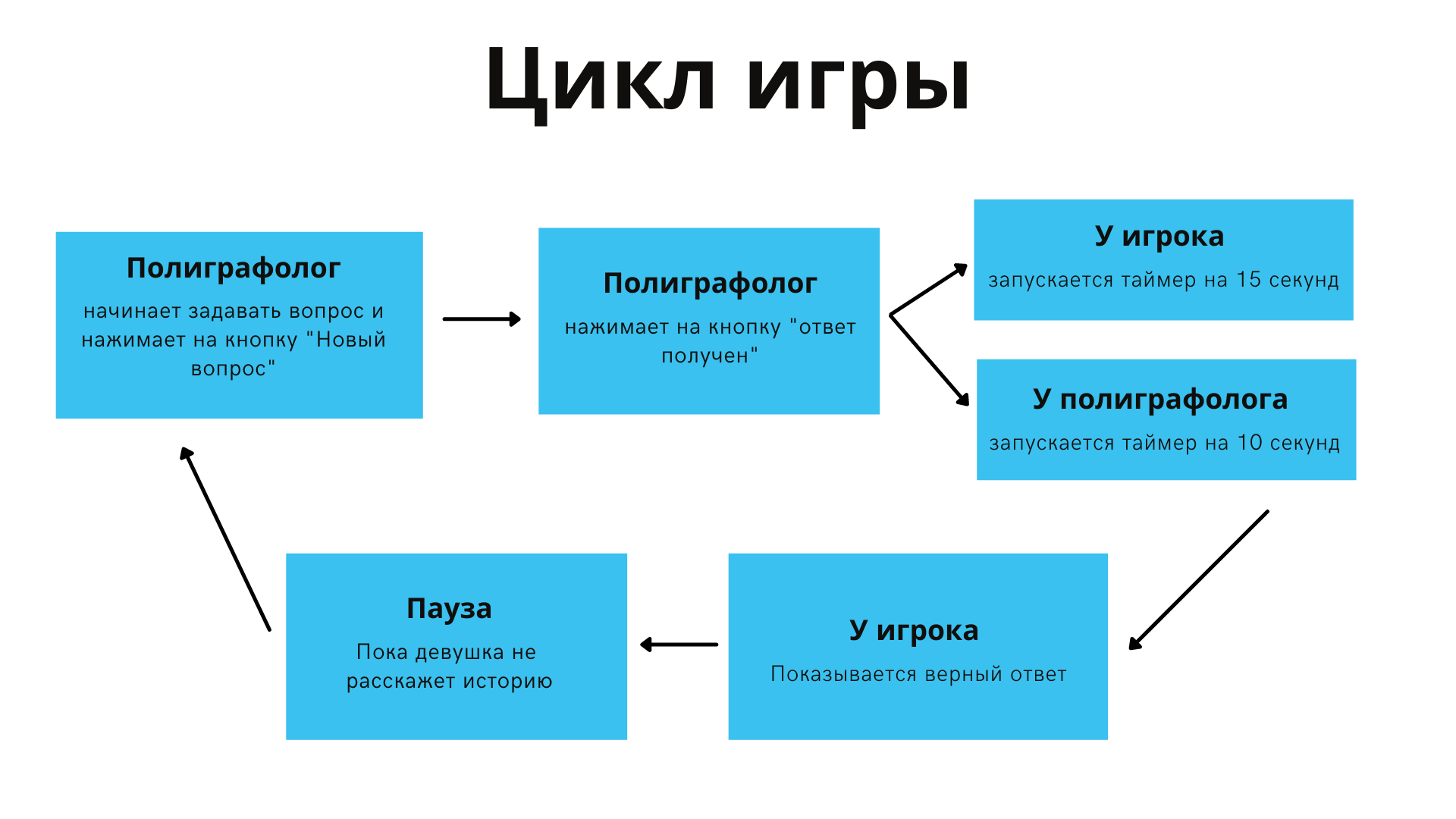
Игра состояла из циклов: свежий вопрос, ответ девушки, вердикт полиграфолога, вердикт игроков. Циклы контролировались событиями, которые отмечал в своем интерфейсе полиграфолог: начал задавать вопрос и получил ответ.
Для доставки этих событий мы использовали протокол mqtt. В нем есть брокеры (обычно один, подобие сервера), и есть клиенты. Клиенты умеют отправлять “сообщения” и подписываться на них, а брокер (сервер mqtt) просто экранирует сообщения всем клиентам, которые пожелали на них подписаться. Сообщения могут отправляться в разные топики, и клиенты могут подписываться не на все. Из контекста будет понятно, какие сообщения для кого в нашей системе, это главное.
Обычно клиентами выступают библиотеки с открытым исходным кодом, а брокерами — готовые программы или SaaS. В этой статье я буду называть клиентами в более широком смысле все сущности игры кроме сервера. Клиенты mqtt содержали все сущности, некоторые и не по одной.
Брокером в нашей системе выступил Mosquitto. Возможно многим читателям знакомы более популярные в энтерпрайз сфере другие MQ-протоколы — AMQP, RabbitMQ, ActiveMQ.
MQTT более легковесен, по умолчанию используется с одним брокером, имеет хорошую поддержку в js через websocket, есть удобные утилиты для ручной отправки и мониторинга сообщений из командной строки.
Всего у нас были две глобальные задачи: научиться расшифровывать графики в приложении Sheriff, чтобы отрисовывать их у игроков и решить проблему синхронизации времени на видео и в игре. Начнем с самого сложного — времени.
Синхронизация событий в игре: как мы сразились со временем и выиграли
Одной из ключевых и самых важных вещей в игре было время. Нам было критически важно, чтобы активация кнопок в интерфейсе игрока и момент на трансляции конкретного зрителя строго (насколько это возможно) совпадали друг с другом.
Например, 15-секундный таймер у игрока должен был запуститься ровно в тот момент, когда девушка на его трансляции закончила отвечать на вопрос. Кнопки «правда» и «ложь» должны были активироваться только на время таймера и деактивироваться, когда отвечать было уже нельзя.
Для синхронизации видео и игрового процесса нужна была общая шкала времени. За ее нулевую координату мы взяли время начала видеотрансляции.
Все “игровые события” содержали в себе указание времени на этой шкале. Давайте называть его относительным временем (оно относительно начала трансляции). Каждое игровое событие содержит в себе относительное время, когда интерфейсу нужно его “воспроизвести”. Чтобы засекать время, даже относительное, нужны часы, то есть функция времени.
- В интерфейсе полиграфолога это системное время ПК через Date.now()
- В клиенте, читающем графики — System.currentTimeMillis()
- В интерфейсе игроков — YoutubeIFrameAPI.getDuration(), которое согласно своей документации, возвращает длительность в секундах воспроизводимого видео. Если видео, как в нашем случае, является прямой трансляций, то функция вернет время прошедшее с момента начала стрима
Самой важной и является последняя функция — она помогает синхронизировать видео и кнопки интерфейса у зрителя.
Как она работает:
Видеозапись от стартового пистолета до фотофиниша, на которой Усейн Болт ставит мировой рекорд на 100 м длится точно 9.58 секунд. Ожидается, что и функция getDuration() для прямой трансляции будет возвращать приемлемо точное время с начала трансляции. Она монотонна, непрерывна и даже линейна. Последнее математически не требуется, но без учета всяких СТО Эйнштейна является и свойством обычного времени тоже.
Как мы использовали эту функцию у игрока?
На страничке игрока есть iframe c плеером YouTube внутри — там отвечает на вопросы девушка. У плеера есть API, один из методов которого — упомянутый ранее getDuration(). Полученное событие нужно воспроизвести через
event.relativeTime - iframeAPI.getDuration()
Федор, наш разработчик, сделал простенький шедулер, который этим и занимался — получал игровые события и откладывал их обработку через setTimeout.
Вердикт полиграфолога (правду сказала девушка или ложь) — одно из множества сообщений, предназначенных для страницы игрока. Это не событие, а просто сообщение, в котором записан идентификатор вопроса и ответ — правда или ложь. Страница игрока сохраняла ответ и использовала его по идентификатору. Когда у игрока истекало 15 секунд, фронтенд сообщал ему, верно ли он угадал.
Тут очень приятно (нет) было пользоваться типом boolean. В игре есть ответ девушки — true/false, есть ответ игрока true/false, есть ответ полиграфолога true/false и угадал игрок ответ или нет — true/false. Не так уж сложно писать условия, но вот устно объяснять этот момент было непросто.
Следующий цикл игры начинается не по истечении 15 секунд, а только когда девушка перестанет рассказывать историю и полиграфолог отметит начало нового цикла событием pgSpeaks.
Логике игрока нужно было вовремя использовать сообщения об игре, полученные через mqtt: например, отрисовывать графики, которые приходили ему в виде комплектов по 6 чисел и сгруппированные в чанки длиной в физическую секунду.
Расшифровка и отрисовывание графиков
Нашей задачей было перехватывать данные, которые выдает полиграф и рисовать их самостоятельно на сайте красивыми графиками.
Как Федор вынул графики из полиграфа
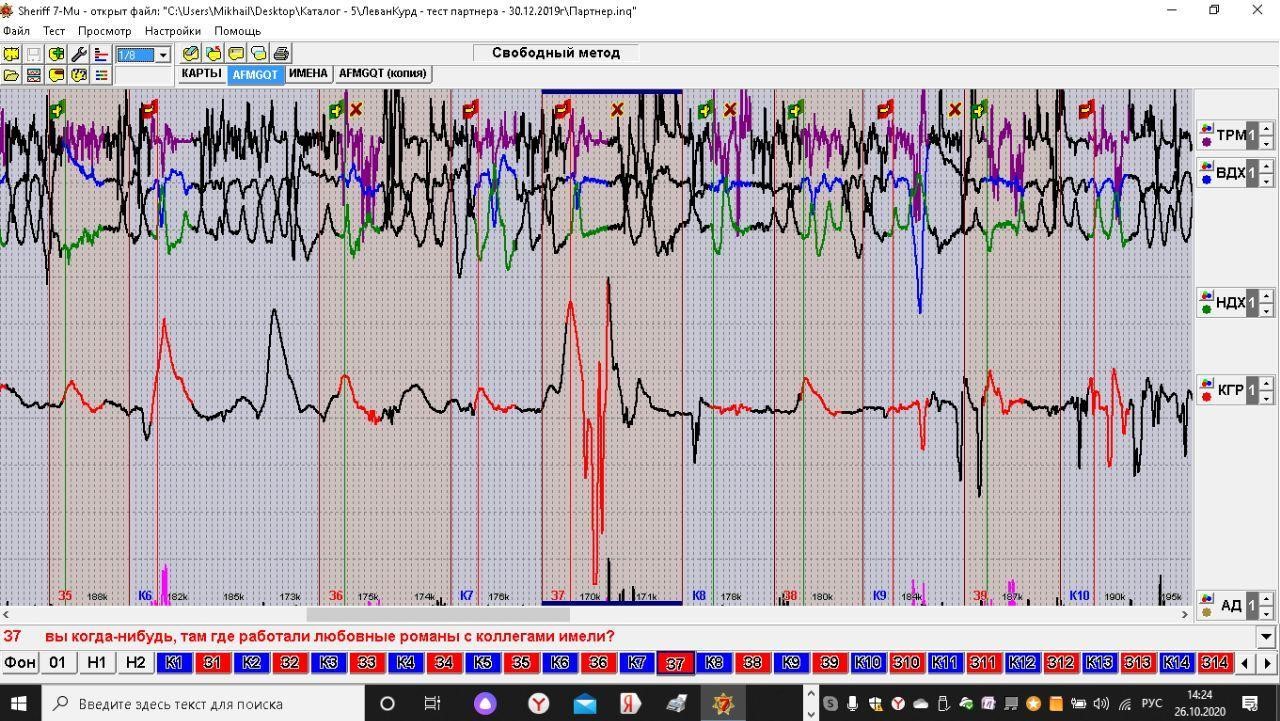
Полиграф КРИС, с точки зрения компьютера — абстрактное COM-USB устройство. Что в этом было хорошего, так это то, что для работы он подключается компьютеру.
А вот то, что работать с ним умеет только допотопная программа Шериф 7, документация к которой только пользовательская и официально поставляется она вместе с бинарником в вот таком виде:
Как же получить данные о дыхании, сердцебиении и прочем?
Федор думал о двух вариантах:
- Перехватить коммуникацию через COM-порт и посмотреть, что же там передаётся
- Попробовать декомпилировать Шериф, который сделан на ископаемых, но простых технологиях и использовать его код для получения чисел.
Первое кажется самым фундаментально верным, второе сэкономило бы время на получении чисел и их можно было бы сразу передавать.
И оба решения нам не подошли, потому что:
- нет безлимитного доступа к устройству на время разработки — полиграфологи не расстаются со своими устройствами, прямо как парикмахеры никому не дают в руки свои ножницы
- у Федора не было навыков работы с ним
- сложно оценить время, которое потребуется на реверс-инжиниринг. Через COM можно передавать данные в каком угодно виде (сам прибор вообще явно аналоговый), насколько легко будет идти реверс-инжениринг самого Шерифа тоже неясно
Тем более, работает Шериф на Windows, а Федор привык к Linux или, на крайний случай, MacOS.
Так Федор решил пойти в лоб: записать скринкаст монитора полиграфолога на обычном допросе и использовать его, чтобы наладить чтение графика с экрана. На одном мониторе он запускал зацикленный скринкаст, а на другом писал код и иногда его запускал, направленным на второй монитор, и сразу наслаждался тем, как именно он не работает.
Федор находился в Питере (а вся остальная команда проекта в Москве, включая полиграфолога Мишу), так что он нашел полиграфолога на Авито, прихватил с собой жертву, посадил ее на ровный такой же полиграф и записал скринкаст допроса. В сыром виде без сжатия и цветовых манипуляций, последовательность bmp-файлов получилось только в 30 fps. Если кому интересно, 2.5 минуты 1920х156 заняли 1Гб, который очень приятно сжимался до 30 Мб с помощью 7z.
Алгоритм расшифровки графиков
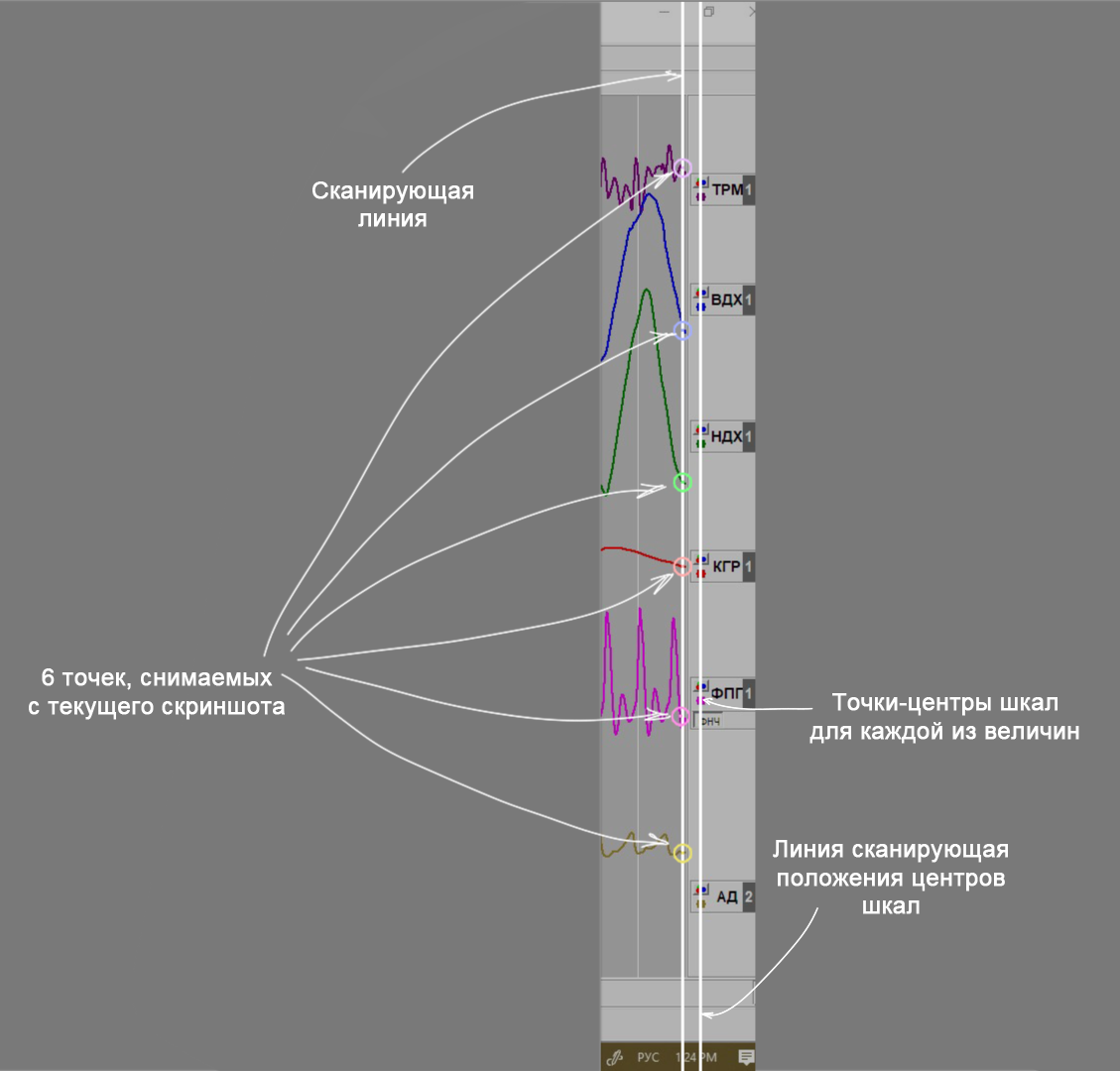
Он достаточно примитивен:
Делаем скриншот, проходим getPixel-ем один столбец в правом краю полотна и получаем 6 чисел — 6 точек на графике. Проходим другой столбец — по меткам в правом краю полотна и получаем вторые 6 чисел — центры шкал каждой из 6 величин.
В шерифе их можно двигать, увеличивать и уменьшать так, чтобы в зависимости от амплитуды, все показания попали в полотно. Попарные разности и есть наши 6 величин в неких условных единицах, которые нам совершенно неважны — важно только их изменение. Их подготавливаем к отправке вместе со временем скриншота.
Федор выбрал Kotlin/JVM и занимался разработкой распознавателя графиков под линуксом. Метод java.aw.Robot.createScreenshot показал впечатляющую производительность: больше 1000 fps на частичных скриншотах (ему не весь экран был нужен, а только краешек), пришлось еще отсеять повторяющиеся скрины.
В качестве отладочного вывода Федор рисовал в файлик 1920х1080 участок кривых соответствующей длины так, как они прочитались. Получилось так
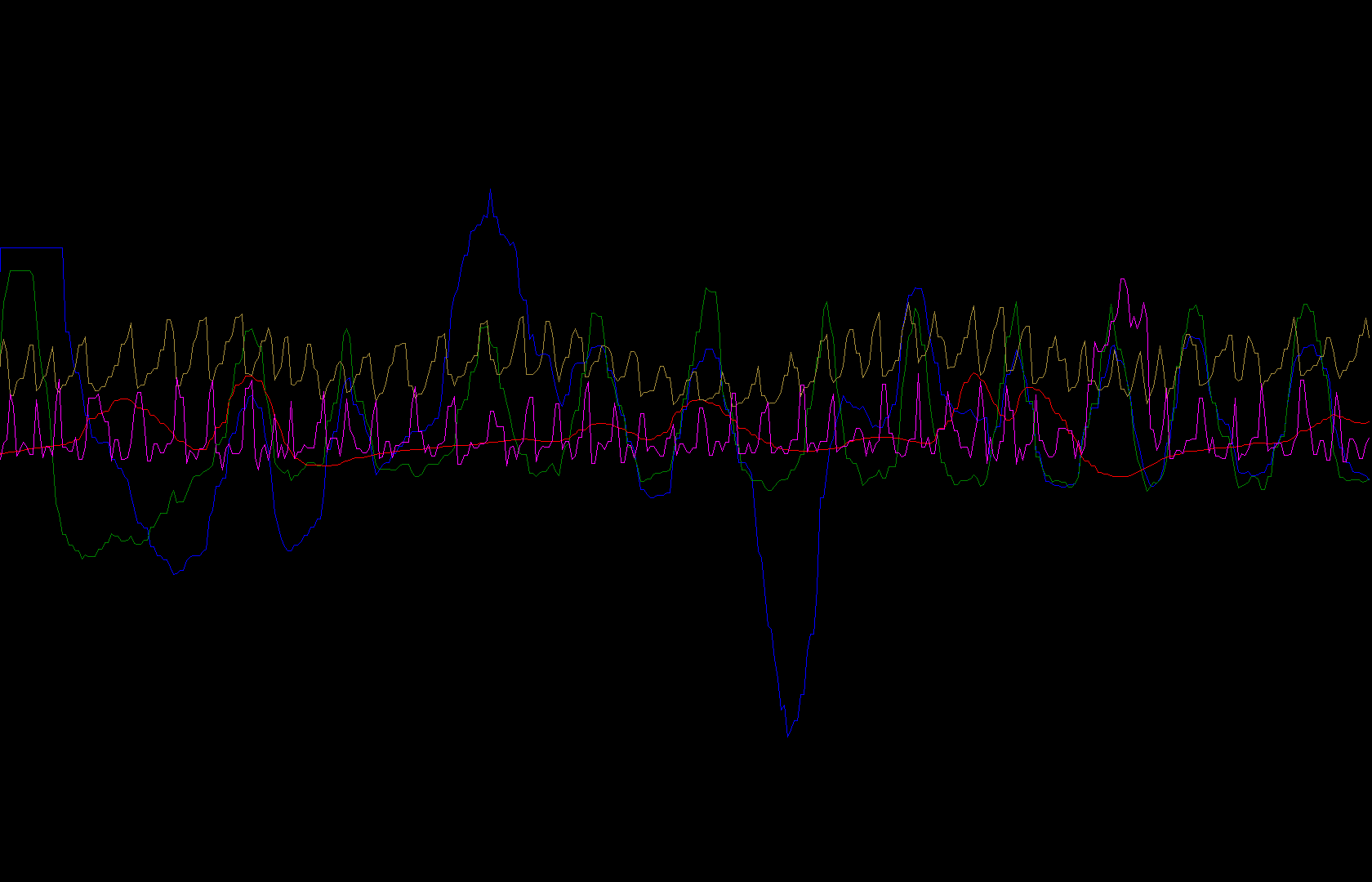
Учитывая, что Федор работал со скринкастом в 30 fps, на живом Шерифе точно должно получиться хорошо, но… Не получилось.
График во фронтенде оказался нечитаемо ломаным, даже хуже чем в отладочной картинке.
Выяснилось, что Windows заботливо ограничивает частоту работы native методов позади Robot.createScreenshot 30-ю снимками в секунду. Стало ясно, почему скринкаст не получилось сделать больше 30…
Возможно, он заметил бы это раньше, если бы вышел из зоны комфорта, пересев на время написания читалки графиков с линукса на Windows, но вышло, как вышло. Всё равно у него не было материала больше 30 fps (на этом моменте рассказа, Федор промакивает глаза салфеткой, прим. интервьюера)
Но решение нашлось: расширить зону захвата и с одного скрина снимать 6 точек не по одной координате, а сразу по нескольким крайним. Точнее по ровно стольким, сколько новых появилось с последнего скриншота. Тут нужно было как-то ориентироваться, насколько полотно в Шерифе сдвинулось с момента прошлого кадра — помогли вертикальные белые линии сетки.
Федор сделал область захвата такой, чтобы попадала хотя бы одна, по ее перемещению и вычислялось, сколько пиксельных столбцов нужно пройти после очередного кадра. Проверить до прогона с полиграфологом эту модификацию он не смог — даже под виндой у него все еще был только 30 fps скринкаст. Однако отладочный вывод на нём выглядел идеально:
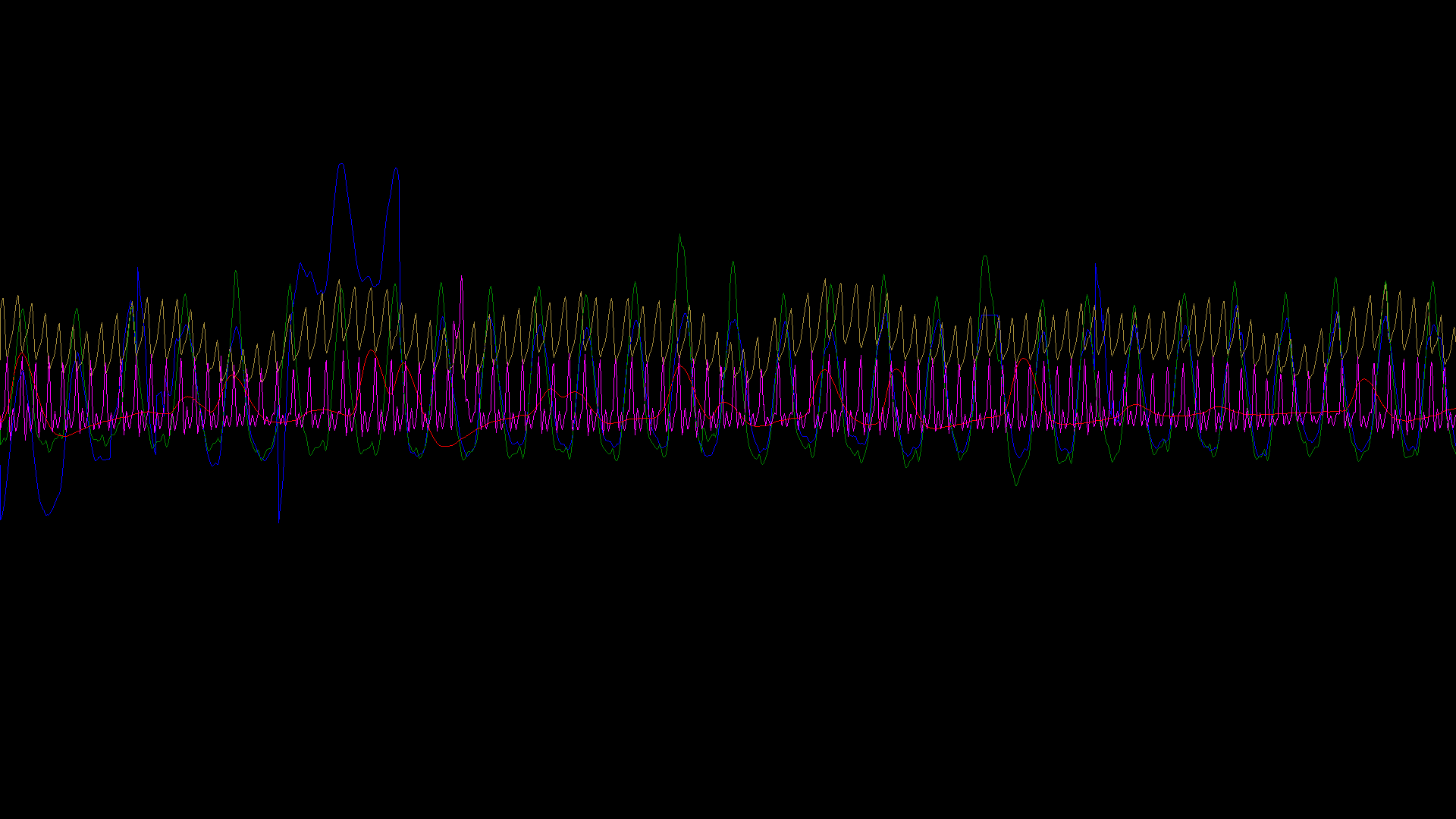
Но на прогоне графики с первого раза заработали идеально и непосредственно с ними проблем больше не было.
Как мы передавали данные для графиков игроку
Веб-странички игроков получают графики так же через mqtt, событиями. В каждом событии относительное время и 6 чисел (дыхание, сердцебиение, потоотделение и так далее) — величины записанные в этот момент.
События с величинами складывались в чанки по несколько штук в mqtt-сообщение — столько, сколько снялось за секунду, около 50 штук. Они складывались в очередь на отрисовку в соответствующие TimeChart-ы. Библиотека отрисовки сама двигает плоскость графика и ставит точки на нужном расстоянии друг от друга по оси времени (гарантий строгой периодичности, к сожалению, не было).
Как и чем отрисовывали графики
Одна из технических сложностей — рисовать 6 графиков величин от реального времени (едущих слева-направо), в масштабе ~20 секунд и с высокой плотностью точек.
Удобный и красивый ApexCharts.js и близко не подошел по производительности — fps порядка единиц и огромная загрузка ЦП. Альтернативы тоже не радовали: по запросу “high performance realtime charts” ничего интересного не находилось.
Спас чат Саматика @ctodaily, куда Федор написал и посоветовался насчет библиотек. Так стало понятно, что почти все либы рисуют графики svg, стало быть, нам надо было искать “webGL charts”.
Из быстро нашедшихся webgl-plot, lightningcharts и TimeChart, Федор выбрал последний. С производительностью же у всех было хорошо, в результате получилось обновлять графики с частотой около 50 fps, как раз с такой частотой полиграф и отдавал значения.
Войны за синхронизацию

Помните идею синхронизации через функцию getDuration ютьюба? Звучит просто, если бы не небольшая тонкость.
Чтобы видео и игровой интерфейс игрока были синхронными, было недостаточно просто взять и нажать на кнопку начала трансляции на компьютере полиграфолога в непосредственный момент ее начала.
Дело вовсе не в миллисекундах человеческой реакции между нажатием кнопки «начать трансляцию» и нажатием кнопки Start streaming в OBS. Если бы дело было лишь в этом, мы могли бы воспользоваться API OBS.
Перед отображением у игрока первый кадр видео проходит долгий путь:
- кодирование,
- доставка ютьюбу
- и обработка ютьюбом записи у себя
Все это, в особенности доставка, занимает неопределенное время, обычно от 2 до 8 секунд. Эту величину мы решили однократно подбирать для каждой трансляции и добавлять вручную перед началом игры. Чтобы высчитать время, поставили монитор полиграфолога так, чтобы видеть его на трансляции.
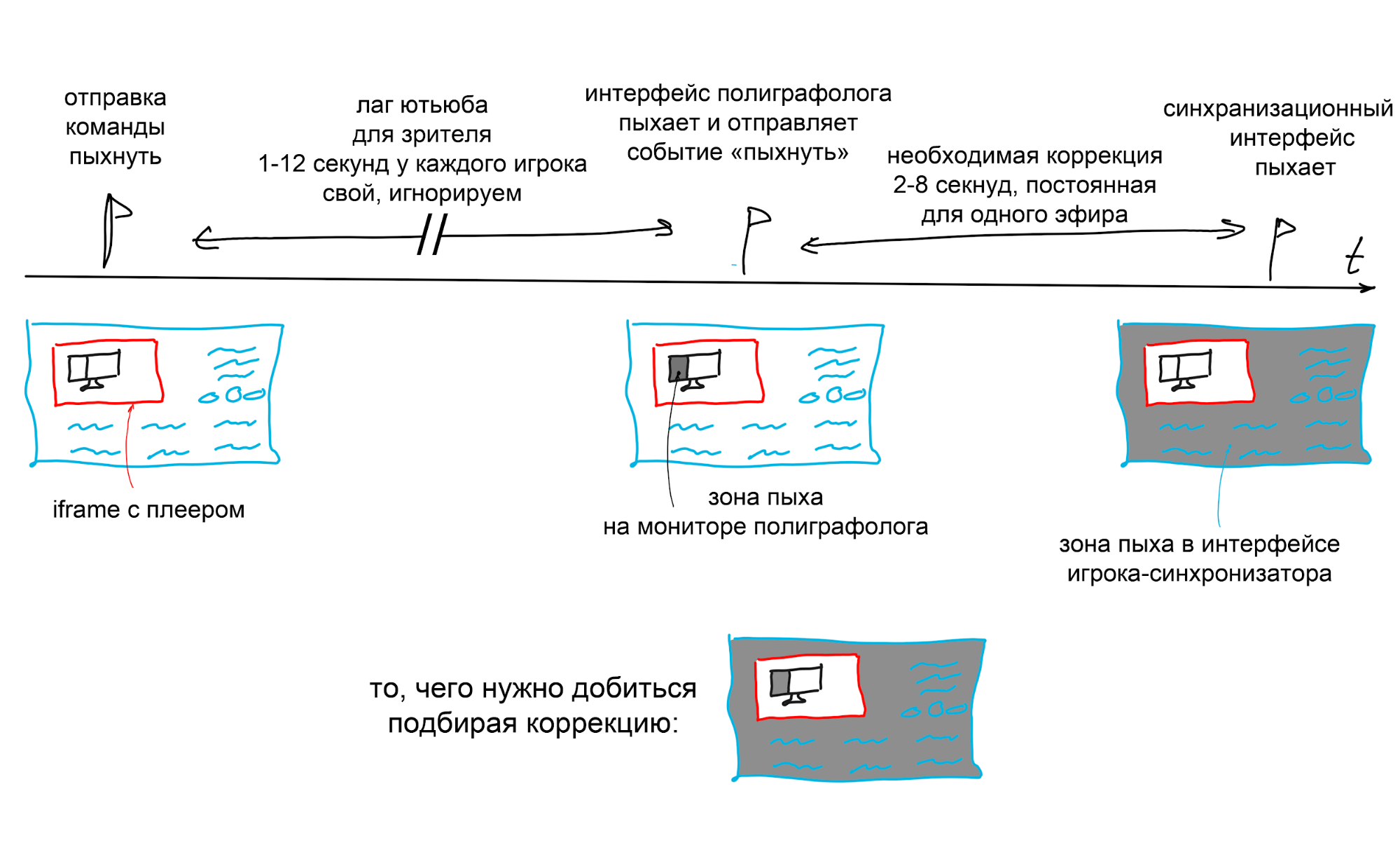
В интерфейсе игрока создали отдельный “режим синхронизации”. Федор подключался к нему и делал следующее:
- Менял величину коррекции, и она сразу передавалась всем игрокам.
- Нажимал кнопку проверки — тогда страница синхронизации посылала специальное указание “пыхнуть” (то есть, менял фон на черный и обратно за 100мс) интерфейсу полиграфолога.
- Тот, получив сигнал, пыхал и сразу же отправлял обратно странице синхронизации просьбу пыхнуть в ответ, но на этот раз в виде события, что принципиально.
По идее, страница игрока-синхронизатора пыхнет не сразу, а в то же относительное время, что пыхал монитор полиграфолога, и с учетом коррекции. Если коррекция ноль, то временной интервал между пыхом ПГ и пыхом фона синхронизатора и есть коррекция.
Как мы проводили первоначальную синхронизацию перед игрой:
- Ставили монитор полиграфолога в кадр
- Слали ему сигнал пыхнуть
- Засекали примерное время между пыхами
- Устанавливали его в качестве коррекции
- Продолжали пыхать и подправлять коррекцию до тех пор, пока пыхи в трансляции и в интерфейсе игрока-синхронизатора не станут одновременными
Принципиально важный момент: нужно было мерить не лаг трансляции с youtube между отправкой команды и пыхом, а время между пыхом полиграфолога и ответным пыхом на него в относительно времени. То есть мы измеряли величину отставания относительного getDuration-времени от относительного времени, которое нам хотелось бы иметь — с нулем точно в начале трансляции, а не на 2-8 секунд раньше.
Таким образом, один цикл ручной синхронизации занимал 1-12 секунд лага youtube для игрока, плюс 2-8 секунд лага между OBS и сервером youtube.
Когда Фёдор тестировал решение в окружении разработки, оно сработало идеально. На первом прогоне на съемочной площадке тоже.
Но через 20 минут на съемочной площадке просело подключение к Интернету — до 1.5 МБ/с, пинга 100 и какого-то сумасшедшего трёхзначного джиттера и тогда синхронизация сбилась.
Даже у игрока на трансляции появились артефакты. Выяснилось, что какие бы ты настройки в OBS не выставлял, при проседании интернета происходит буферизация кадров, которые не успели отправиться, а на сервере youtube в свою очередь перерыв в видеостриме.
На время этого перерыва, видеофайл, передаваемый пользователю, не прерывался и getDuration-время продолжало расти. При таких условиях зритель будет видеть установку 9,58-секундного рекорда в течение 12 секунд. Не слишком логично, что getDuration считает время наблюдателя, а не время события согласно документации.
Дальнейшие эксперименты показали, что линейность времени события нарушается скачками, да еще и с завидной регулярностью.
Каждый раз передвигать монитор полиграфолога в кадр, чтобы синхронизироваться по-старинке, вручную было нельзя — портился тщательно выставленный кадр. Времени до запуска проекта оставалось мало и Федя просто добавил полиграфологу второй монитор — маячок, который бы отвечал только за синхронизацию и всегда находился в кадре.
Также, он написал автоматический синхронизатор, который автоматически выполнял синхронизацию, которую Федя делал обычно вручную.
Синхронизатор слал команду синхронизации, ждал пыха в трансляции, снимая скриншоты со страницы игрока-синхронизатора с линуксовой скоростью больше 1000 fps и засекал время до ответного пыха. Пыхи на мониторе-маячке мы сделали разных оттенков серого, чтобы зритель их не замечал на трансляции.
Чтобы протестировать синхронизатор, мы сделали стресс-тест: запустили трансляцию через 3G, раздаваемый c телефона на компьютер с OBS.
За 6 часов непрерывной трансляции удалось поймать два скачка времени, которые хорошо обработались. Через какое-то время вылез еще один рассинхрон и из логов стало ясно, что время не просто нелинейно, оно НЕ МОНОТОННО.
Оказалось, Youtube делает скачки в своей записи не только вперед, но и назад. Иногда на время, на которое был скачок вперед, иногда меньшее. Почему, а главное зачем он это делает осталось для нас загадкой. По всей видимости, функцию getDuration по назначению никто до нас не использовал…
Но по крайней мере, учесть скачки в другую сторону на этом этапе было уже просто.
Happy end
Мы запустили проект 1 декабря и игра шла 7 часов. Всего в нее поиграли почти 9000 человек. Охват был не такой широкий, как в проекте с уничтожением сервера, но это с лихвой возместил коэффициент удержания. Вот запись игры
До новых спецпроектов в Новом Году! И спасибо, что дочитали лонгрид.


ссылка на оригинал статьи https://habr.com/ru/company/ruvds/blog/535398/
Добавить комментарий