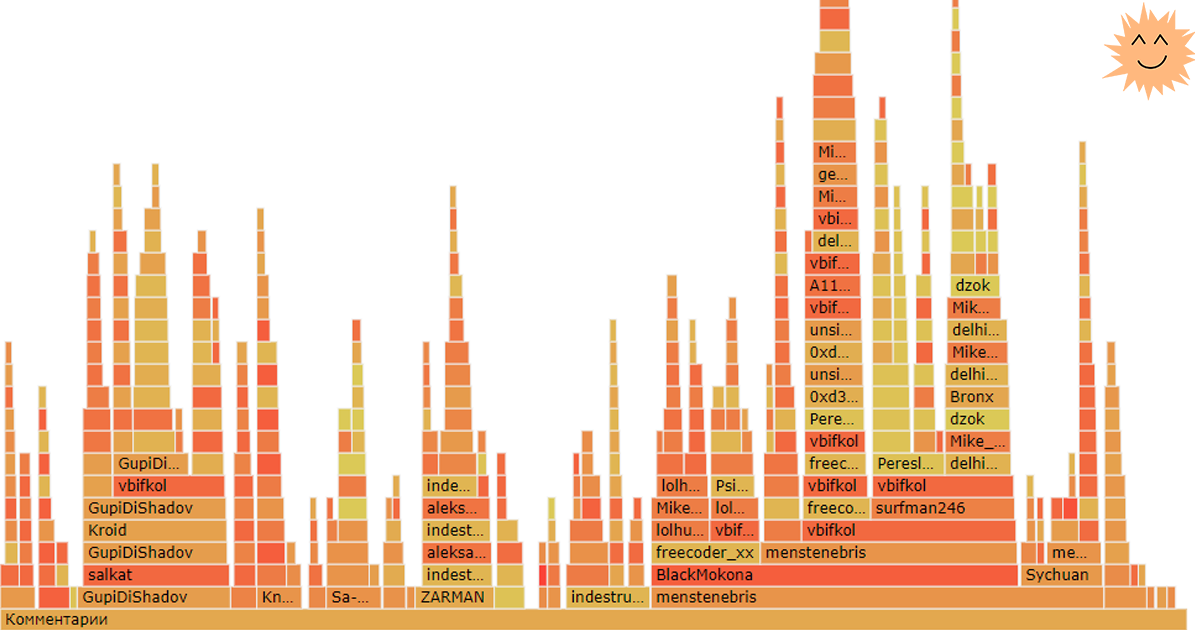
Давайте поговорим о больших тредах. Об этих больших, грузных засранцах, в которых разворачиваются самые интересные дискуссии и проходят самые жестокие кармовые войны. Как часто вы их читаете? А прочитав раз, возвращаетесь ли к ним? Под обычной статьёй можно обновить комментарии, прочитать ответы и свежие сообщения, но в мегатредах это делать неудобно из-за долгой загрузки. В результате, целый пласт интересного обсуждения остаётся непрочитанным, и это обидно. Написано несколько альтернативных клиентов Хабра с разными подходами к рендерингу комментариев (кое-кто даже таким образом продвигает свою разработку), а я попробовал другой подход — упростить навигацию по комментариям, представив их в виде графика.
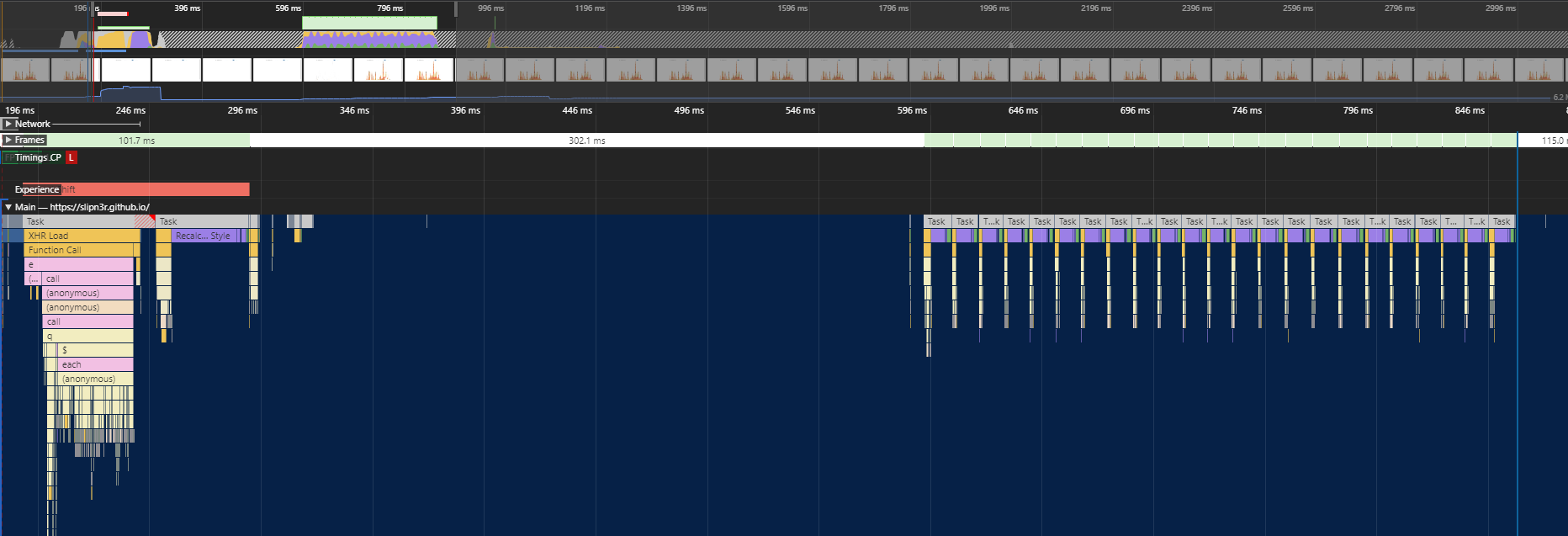
Для отображения большущих древ комментариев как нельзя лучше подходит flame graph — стандарт в отображении стека вызовов. Даже те, кому не приходилось профилировать свои приложения, могли видеть его в действии в DevTools:

Среди всех вариантов браузерной отрисовки победил d3-flame-graph — это часть мощной библиотеки D3 для разного рода визуализации данных, от простых графиков до сложных трёхмерных моделей. Реализация в других чарт-библиотеках либо копировала функционал D3 вплоть до цветовой палитры, либо просто выглядела хуже или начинала тормозить на больших объёмах данных.
d3-flame-graph использует json в формате d3-hierarchy с добавлением значения, отвечающего за ширину полоски на графике:
{ "name": "<name>", "value": <value>, "children": [ <Object> ] } Так как у Хабра нет открытого API, будем парсить страницу поста — неудобно, но других вариантов нет. Беглый осмотр страницы показывает, что блок комментариев начинается с , а следом за ним идёт . Каждый комментарий живёт в теге li с классом js-comment, будем использовать его как ключ при переборе строки с комментариями:
const axios = require('axios'); async function get(id) { axios.get(`https://habr.com/ru/post/${id}/`) .then(function (response) { // Проверим наличие комментариев на странице и обрежем по ним строку const begin = response.data.indexOf('<ul class="content-list content-list_comments" id="comments-list">'); const end = response.data.indexOf('<div class="js-form_placeholder">'); if ( response.data.indexOf('<ul class="content-list content-list_comments" id="comments-list">') && response.data.indexOf('<div class="js-form_placeholder">')) { // Разобьем на массив подстрок по ключу const commentsHTML = response.data.slice(begin, end).trim().split('<li class="content-list__item content-list__item_comment js-comment'); commentsHTML.shift(); ... } }) .catch(function (error) { console.log(error.message); }) } // для примера возьмём нашу статью на 2000 комментов: // https://habr.com/ru/company/vdsina/blog/528558/ const id = process.env.ID || 528558; get(id); Затем пройдёмся по массиву подстрок и вытащим id, автора, рейтинг коммента и его HTML, а также id его родителя:
let data = { name: 'Комментарии', value: 1, body: '', children: [] }; commentsHTML.forEach(c => { let cData = { id: parseInt(c.match(/(?<=(id="comment_))([0-9])+/g)[0]), parentId: parseInt(c.match(/(?<=(data-parent_id="))([0-9])+/g)[0]), name: '', rating: '', body: '', value: 1, children: [] }; try { cData.name = c.match(/(?<=(data-user-login="))([A-z0-9_-])+/g)[0] cData.rating = c.match(/(?<=(title="Всего голосов ))([0-9+–])+/g)[0] cData.body = JSON.stringify(c.slice(c.indexOf('<div class="comment__message'), c.indexOf('<div class="comment__footer">')).trim()) } catch { // обработаем удалённые сообщения cData.name = 'НЛО' cData.rating = '0' cData.body = JSON.stringify('<div class="comment__message comment__message_banned">НЛО прилетело и опубликовало эту надпись здесь</div>') } ... }); Теперь осталось разложить детей по родителям и можно запекать корневой объект data в json:
if (cData.parentId === 0) { // ищем родителя в корне data.children.push(cData) } else { // не нашли, ищем родителя рекурсивно addChild(cData, data.children) }
function addChild(cData, children) { let p = children.find(c => c.id === cData.parentId) if (p) { p.children.push(cData) p.value += 1 } else { children.forEach(c => { if (c.children.length) { addChild(cData, c.children) } }) } }
// добавив все комментарии в data, запишем json в файл const fs = require('fs'); ... fs.writeFileSync('data.json', JSON.stringify(data), 'utf-8'); Теперь у нас есть отформатированный файл data.json, готовый для импорта в D3. Осталось передать данные в d3-flame-graph и отрендерить его. Базовый пример выглядит так:
<head> <link rel="stylesheet" type="text/css" href="node_modules/d3-flame-graph/dist/d3-flamegraph.css"> </head> <body> <div id="chart"></div> <script type="text/javascript" src="node_modules/d3/d3.js"></script> <script type="text/javascript" src="node_modules/d3-flame-graph/dist/d3-flamegraph.js"></script> <script type="text/javascript"> const chart = flamegraph() .width(960); d3.json("data.json", function(error, data) { if (error) return console.warn(error); d3.select("#chart") .datum(data) .call(chart); }); </script> </body> На этой странице будет только голый график, использующий только name и не умеющий самостоятельно вычислять value. Допилим:
<head> <link rel="stylesheet" type="text/css" href="node_modules/d3-flame-graph/dist/d3-flamegraph.css"> </head> <body> <div id="chart"></div> <hr> <div id="details"></div> <!-- здесь будет отрисован комментарий --> <script type="text/javascript" src="node_modules/d3/d3.js"></script> <script type="text/javascript" src="node_modules/d3-flame-graph/dist/d3-flamegraph.js"></script> <script type="text/javascript"> const chart = flamegraph() .width(960) // добавим обработчик чтобы показывать комментарий .onClick(onClick) .selfValue(true); d3.json("data.json", function(error, data) { if (error) return console.warn(error); d3.select("#chart") .datum(data) .call(chart); }); function onClick(d) { const details = document.getElementById("details"); if (d.data.body) details.innerHTML = '<h4>' + d.data.name + ' (' + d.data.rating + ')</h4>' + JSON.parse(d.data.body); } </script> </body> Данные отображаются, комменты читаются. Форматирование страницы на 2000+ комментариев занимает около секунды, а отрисовка графика — 860 миллисекунд включая анимацию!
Библиотека предоставляет ещё уйму удобных фич (вот API), поэтому я ещё немного допилил график. Посмотреть можно здесь.
TODO:
- Допилить поиск по содержимому комментария
- Опционально отображать комментарии в ветке (всю ветку или только ближайшие?)
- Добавить атрибут is_author и перекрашивать полоски с комментариями автора и НЛО
- Вычислять json на сервере, чтобы можно было доделать основной сценарий использования — находясь на Хабре, переходить на страницу графика, построенного из location.hash
- Отрисовывать комментарии посимпатичнее, со стилями и аватарками
Stay tuned!
На правах рекламы
Арендуйте сервер любой конфигурации в течение минуты, с любой операционной системой (есть возможность установить ОС со своего образа). Используем только современное брендовое оборудование и лучшие ЦОД-ы. Эпичненько 🙂

ссылка на оригинал статьи https://habr.com/ru/company/vdsina/blog/538290/
Добавить комментарий