Наверное, каждый программист рано или поздно начинает задумываться о качестве своего кода. И, скорее всего, я не ошибусь, если скажу, что добрая половина разработчиков им вечно недовольна. Мне мой код тоже нравился редко: функции, казалось, можно было бы делать и покороче, лишние вложенности было бы неплохо тоже убирать. Было бы здорово писать тесты и документацию, но на них времени не оставалось почти что никогда.
Естественно, что я потратил кучу времени на чтение книг и всевозможных статей, пытаясь понять, как же сделать свой код лучше. Но картинка не складывалась. То ли рекомендации в книгах или статьях были через чур общими и местами противоречивыми, то ли дело было во мне, но, несмотря на усилия, результата было мало.
Кардинальным образом ситуация изменилась после того, как я прошел курс HowToCode[ссылка удалена модератором, т.к. нарушает правила]. В курсе описан системный и, как всё гениальное, простой и красивый подход к разработке, который сводит воедино анализ, проектирование, документацию, тестирование и разработку кода. Весь курс построен на использовании функциональной парадигмы и языка Scheme (диалекта Lisp), тем не менее, рекомендации вполне применимы и для других языков, а для JavaScript и TypeScript, к которым я постарался их адаптировать, так и вообще подходят отлично.
Результаты мне очень понравились:
-
Во-первых, наконец-то мой код стал читаемым, появилась внятная документация и тесты
-
Во-вторых, заработал подход TDD, к которому я делал несколько подходов, но никак не мог начать ему следовать
-
В-третьих, я практически избавился от отладки: того самого процесса, когда код уже написан, но ещё не работает или работает не так как надо, чем дико раздражает
-
Ну и ещё одно очень приятное наблюдение: я не боюсь что-то забыть или пропустить, потому что в каждый момент времени я работаю над одной конкретной небольшой задачей, а все остальные задачки — записаны
-
Да, и, предвидя вопросы, скажу — по ощущениям время разработки если и замедлилось, то не сильно, даже с учётом написания тестов и документации. А экономия на поддержке кода — просто колоссальная.
Но давайте уже перейдём к сути и посмотрим, как этот подход устроен.
Общая идея
Чтобы понять, в чём заключается общий смысл подхода, достаточно рассматривать процесс разработки приложения как проектирование — процесс превращения плохо сформулированной проблемы в хорошо структурированное решение.
Все действия подхода нацелены на постепенное уточнение задачи, движение от абстрактного к конкретному, причем каждый следующий шаг опирается на результаты предыдущего.
Этапы проектирования
Подход включает 3 этапа:
-
Анализ задачи и предметной области
-
Проектирование структур данных
-
Проектирование функций
Анализ задачи и предметной области
Анализ задачи необходим для того, чтобы понять, что мы, собственно, будем делать.
Входными данными для этого этапа является постановка задачи. Она может выглядеть как угодно: устная формулировка, пара предложений в тикете Jira или полноценное ТЗ на десятки страниц. На самом деле это не так уж и важно.
Действительно важен тот факт, что есть 2 стороны: заказчик и исполнитель. И в голове заказчика уже есть некоторое представление о желаемом результате, а в голове исполнителя — его нет. И лучшее, что мы можем сделать на этом этапе — это воспроизвести у себя картинку, максимально близкую к изображению в голове заказчика и убедиться в том, что мы сделали это правильно.
Процедура анализа задачи
Для того, чтобы быстро и качественно проанализировать задачу, воспользуемся специальным алгоритмом. Для его выполнения нам потребуются только карандаш и бумага.
Алгоритм
В общем виде алгоритм выглядит так:
Шаг 1. Представить задачу в динамике
Шаг 2. Выделить константы, переменные и события.
Шаг 1. Представить задачу в динамике
Чтобы представить задачу в динамике достаточно набросать несколько схематичных иллюстраций того, как программа будет выглядеть:
-
в исходном состоянии
-
в различных промежуточных состояниях: возможно, появляется загрузка, или раскрываются какие-то списки или открываются какие-то окна
-
при окончании работы
Иллюстраций должно быть достаточно для того, чтобы отобразить на них все основные элементы. Если есть макеты от дизайнера — прекрасно, возможно, и рисовать ничего не придётся, но вникнуть в логику переходов между экранами, понять все ли состояния указаны на макете или что-то пропущено, обязательно стоит.
Пример
Допустим, первоначальная постановка задачи звучала как: «Реализовать для web-портала раскрывающийся список, который бы показывал перечень сотрудников, входящих в учебную группу. Для каждого сотрудника должно быть указано ФИО и дата его рождения.»
Звучит неплохо, но что делать, пока ещё непонятно. Берем карандаш, бумагу и, если есть возможность, самого заказчика и начинаем рисовать (Ну а я буду рисовать в редакторе).
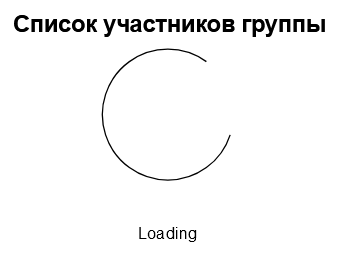
Начальное состояни
Изначально наше приложение пустое, данные о составе группы с сервера ещё не получены, значит надо предусмотреть какой-то индикатор загрузки. Пусть на данном этапе оно будет выглядеть так:
Промежуточные состояния
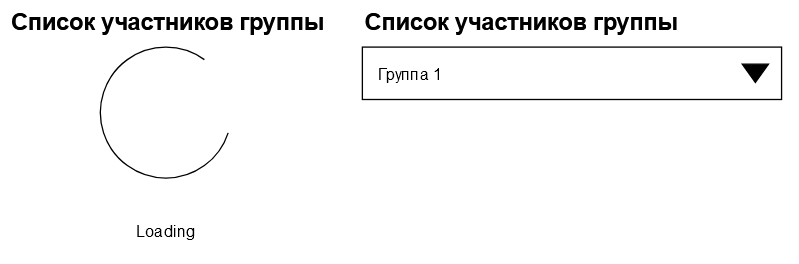
Когда данные загружены, то на экране, наверное, должен появиться закрытый список с названием группы и индикатором состояния списка. Пусть это будет выглядеть так:
Когда список открывается, мы должны показать список сотрудников, входящих в группу, и изменить состояние индикатора. Скорее всего, выглядеть наше приложение станет как-то так:
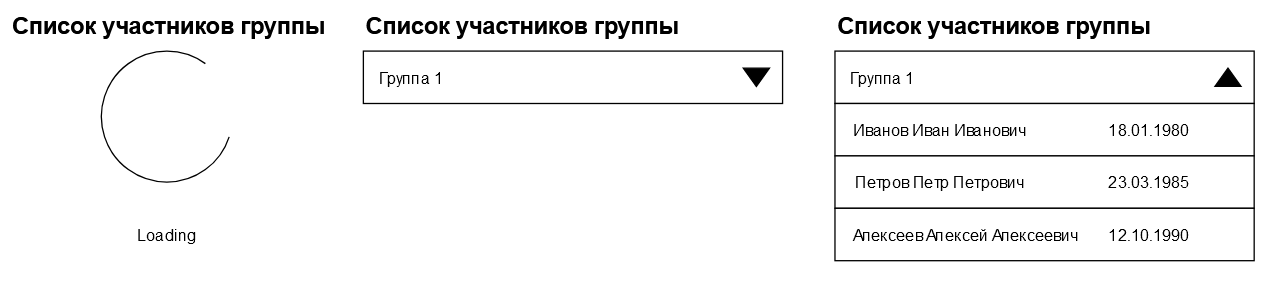
Ну и, если мы закроем список, то должны вернуться к его закрытому состоянию без каких-либо изменений.

Шаг 2. Выделить константы, переменные и события
Теперь давайте пойдём дальше: выделим 3 группы параметров, которые лежат в основе описания приложения на языке компьютера: константы, переменные и события.
Константы
Константы — это данные приложения, которые во время его выполнения не изменяются. Как правило, к ним можно отнести различные настройки, например:
-
оформление: цвета, шрифты, расстояния, логотипы и иконки, размеры сетки и экрана и т.д.
-
сетевые данные, например, адреса серверов,
-
строковые константы: названия, заголовки и т.п.
Пример выделения констант
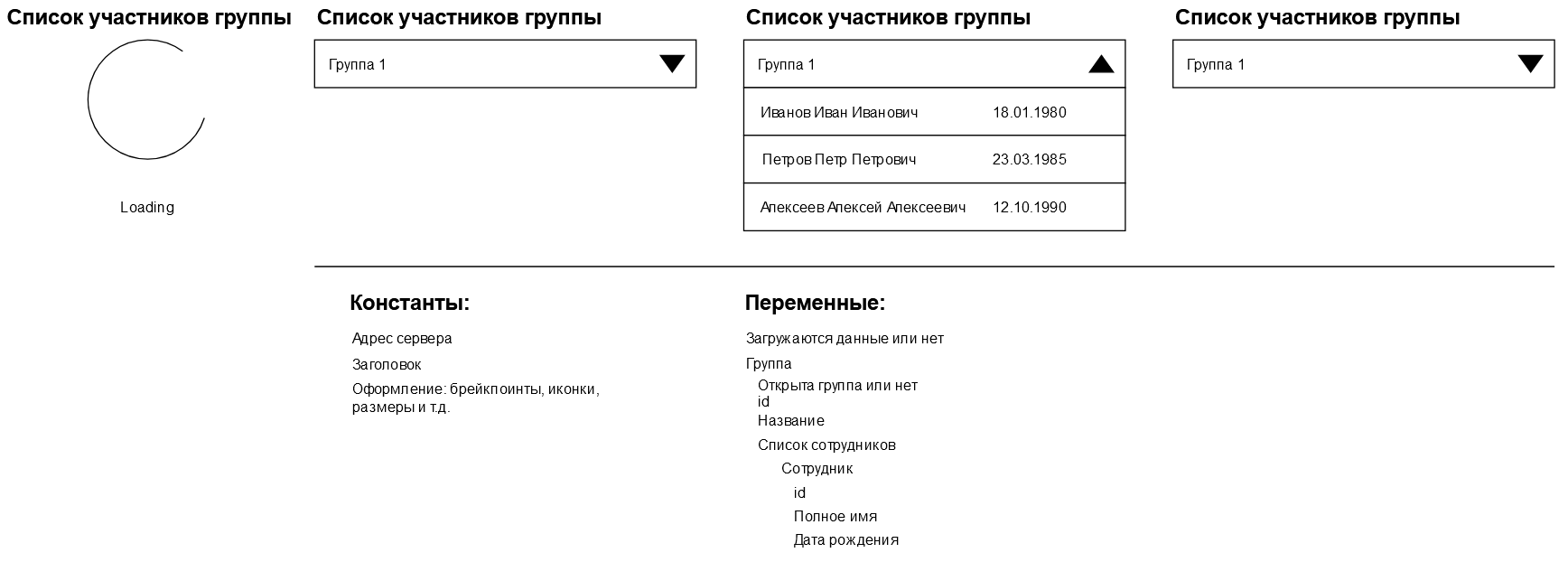
Давайте внимательно посмотрим на схемы и выделим то, что у нас в приложении постоянно. У меня получился следующий список:
-
Адрес сервера, с которым работает наше приложение
-
Название приложения, которое отображается в виде заголовка
-
Оформление
Получившийся список мы записываем под схемами приложения, отдельной колонкой, чтобы всё было рядышком и охватывалось одним взглядом:

Переменные
Следующий пункт нашего небольшого анализа — это выявление переменных. Переменные, в противоположность константам — это то, что в приложении меняется в зависимости от разных условий. Это могут быть:
-
координаты объектов
-
значения таймера
-
различные переменные, отражающие состояние элементов интерфейса и т.д.
Пример выделения переменных
Вернёмся к нашим схемам и ещё раз внимательно на них поглядим: какие элементы приложения меняются от схемы к схеме? В общем, ищем всё, что появляется и исчезает, меняет размеры, форму, цвета или ещё каким-то образом вносит изменения в приложение.
У меня получился следующий список:
-
Состояние загрузки приложения: загружается или данные уже загружены
-
Группа, для описания которой нам, скорее всего, понадобится её идентификатор, название, статус открытия списка группы
-
Список участников группы, который, наверняка, в будущем будет являться свойством группы
-
Ну и каждый участник группы тоже будет являться переменной, и описываться при помощи идентификатора, полного имени и даты рождения.
Переменные, как и константы мы записываем отдельной колонкой под схемами:
События
Последний тип параметров, которые нас интересуют — это события, влияющие на поведение программы. То есть то, что меняет переменные, которые мы определили на прошлом шаге.
Событиями могут быть:
-
Изменения этапов жизненного цикла приложения или его отдельных компонентов: инициализация, обновление, удаление, и т.п.
-
Пользовательский ввод: события мыши или клавиатуры
-
Таймер
-
Получение данных с сервера и т.д.
Ну а в нашем приложении такими событиями, на мой взгляд, будут:
-
загрузка данных приложения и
-
открытие и закрытие списка сотрудников по клику мыши на шапку группы
Как и раньше, список событий мы записываем отдельной колонкой под схемами приложения.

Теперь мы уже существенно продвинулись вперед:
-
Во-первых, мы уже покрутили задачу в голове и более или менее её поняли
-
Во-вторых, мы сделали её куда как более конкретной, свели все возможные варианты реализации списков к одному
-
В-третьих, мы получили наглядное представление нашего решения, которое уже можем обсуждать, править и согласовывать. А правки на этом этапе, как вы знаете, самые ценные, потому что практически бесплатные.
Не торопитесь переходить к следующему шагу, пока не обсудите и не утвердите результаты вашего анализа с заказчиком. Правьте, проясняйте и уточняйте, пока не убедитесь, что вы оба понимаете задачу одинаково.
Проектирование структуры данных
Теперь мы можем переходить ко второму этапу нашего алгоритма — проектированию структур данных.
На этом этапе мы берем константы, переменные и события, которые выявили в ходе анализа и думаем, каким образом нам представить их в программе.
Назначение
Для чего нам это надо?
-
Во-первых, мы формируем единый словарь для общения внутри проекта. Все разработчики должны понимать, какие данные и сущности есть в приложении, как они представлены и как взаимосвязаны между собой. Это, в свою очередь, позволяет безболезненно разделять работу между несколькими людьми и подключать в проект новых участников.
-
Во-вторых, эти структуры станут основой для типов TypeScript, которые мы будем дальше использовать в клиентской части приложения.
-
И в-третьих, если структуры данных описать полностью и с примерами, как рекомендует алгоритм, то примеры становятся очень неплохим подспорьем для unit-тестов.
Алгоритм
Структуры мы описываем в следующем порядке:
-
Фиксируем название структуры
-
Описываем её тип
-
Пишем интерпретацию структуры — описание того, как преобразовать реальные данные в указанный тип.
-
Придумываем один — два примера заполненной структуры.
На этом этапе уже начинают играть роль используемые технологии. В нашем случае появляются TypeScript и JSDoc, но для других языков и платформ вполне может использоваться и что-то другое. Ну а раз мы говорим о веб-разработке и библиотеке React JS, то надо сразу отметить, что мы дальше будем использоваться понятия свойств (props) и состояний (state), характерных для React. Ничего страшного, если вы с этими понятиями не знакомы, думаю, что всё будет и так понятно.
Примечание: В курсе HowToCode приводится ещё один, дополнительный шаг описания структуры — написание шаблона функции с одним аргументом, которая будет работать со структурой данного типа. Но мы сейчас этот шаг пропустим, для его изложения потребуется как минимум отдельная статья, если не целая серия.
Пример
Давайте попробуем определить структуру данных для тех констант и переменных, которые мы получили в ходе анализа.
Для хранения констант мы создадим интерфейс, который будем считать состоянием главного компонента, ну или состоянием хранилища Redux, если вы его используете.
Фиксируем название структуры. Название должно отражать суть структуры. В нашем случае, назовём её AppState — состояние приложения:
export interface AppState {}Описываем тип структуры. Для этого мы возвращаемся к нашим переменным, константам и событиям, внимательно смотрим на них и думаем, какие из этих данных нам бы следовало разместить на верхнем уровне нашего приложения. У меня получилась вот такая комбинация:
|
Описание |
Название переменной |
Источник |
Тип данных |
Обязательность |
Комментарий |
|
Название приложения |
title |
Константы |
Строка |
+ |
|
|
Адрес сервера |
backendAddress |
Константы |
Строка |
+ |
|
|
Флаг загрузки данных |
isLoading |
Переменные |
Логическое значение |
+ |
true — данные загружаются false — данные загружены |
|
Данные об отображаемой группе |
group |
Переменные |
Объект типа Group |
— |
На момент загрузки данные о группе не определены |
|
Метод загрузки данных |
loadData |
События |
Функция |
+ |
Фиксируем это в коде:
export interface AppState { title: string; backendAddress: string; isLoading: boolean; group?: Group; loadData: Function; }Пишем интерпретацию структуры
TypeScript дает отличное представление того, что из себя структура представляет, но всё же, часть информации теряется. Поэтому, давайте сразу зафиксируем, что подразумевается под каждым из полей структуры и каким образом мы можем представить информацию из реального мира в виде такой структуры. Для этого нам пригодится ещё один инструмент из мира JavaScript — JSDoc.
/** * Общее состояние приложения * @prop title - заголовок приложения * @prop backendAddress - адрес сервера * @prop isLoading - флаг загрузки данных (true - загружаются, false - загружены) * @prop group - данные об отображаемой группе. На момент загрузки данных group не определена * @method loadData - метод загрузки данных */ export interface AppState { title: string; backendAddress: string; isLoading: boolean; group?: Group; loadData: Function; }Внимательный читатель может заметить появление в описании AppState некой ранее не описанной структуры Group. И действительно, в процессе работы над AppState стало понятно, что данные о группе — это тоже, в свою очередь, сложный тип данных. При этом мы ни в коем случае не бросаемся сейчас же его описывать. Рекомендуется сделать для новой структуры заглушку, после чего вернуться и закончить текущую задачу. Это позволяет всегда концентрироваться только на одном конкретном деле и не распылять своего внимания.
Для заглушки достаточно правильно указать имя новой структуры, описать, что она будет собой представлять и поставить отметку TODO — как правило IDE автоматически распознают отметки TODO и формируют из них удобные списки задач
/** * Общее состояние приложения * @prop title - заголовок приложения * @prop backendAddress - адрес сервера * @prop isLoading - флаг загрузки данных (true - загружаются, false - загружены) * @prop group - данные об отображаемой группе. На момент загрузки данных group не определена * @method loadData - метод загрузки данных */ export interface AppState { title: string; backendAddress: string; isLoading: boolean; group?: Group; loadData: Function; } /** * Данные об отображаемой группе */ //TODO export interface Group { }Придумываем пару примеров того, как может выглядеть эта структура в заполненном виде.
Делать это мне всегда тяжело, потому что кажется, что примеры — это пустая трата времени. И каждый раз, когда я дохожу до написания unit-тестов, я радуюсь тому, что я всё-таки их написал. В примерах вместо методов я указываю заглушки и вместо содержания вложенных структур, в нашем случае group — ссылки на переменные нужного типа, для которых временно тоже делаю заглушки. Получается что-то вроде:
/** * Общее состояние приложения * @prop title - заголовок приложения * @prop backendAddress - адрес сервера * @prop isLoading - флаг загрузки данных (true - загружаются, false - загружены) * @prop group - данные об отображаемой группе. На момент загрузки данных group не определена * @method loadData - метод загрузки данных */ export interface AppState { title: string; backendAddress: string; isLoading: boolean; group?: Group; loadData: Function; } //Пример 1 const appState1: AppState = { title: "Заголовок 1", backendAddress: "/view_doc.html", isLoading: true, group: undefined, loadData: () => {} } //Пример 2 const appState2: AppState = { title: "Заголовок 2", backendAddress: "/view_doc_2.html", isLoading: false, group: group1, //Заглушка для вложенной структуры loadData: () => {} } /** * Данные об отображаемой группе */ //TODO export interface Group { } //TODO const group1 = {}Итак, первая структура у нас готова, она хорошо описана, поэтому разобраться в ней — проще простого. Можно сделать перерыв, налить чаю, размять спину, а после — взять и описать следующую структуру, отмеченную у нас «тудушкой».
Когда у нас закончатся все TODO и константы, переменные и события, описанные в ходе анализа, мы получим документ с подробным описанием большинства данных, циркулирующих по нашей системе.
Можно сделать ещё один шаг и описать простой контракт между клиентом и сервером нашего приложения. Для этого достаточно выделить из описанных структур те данные, которыми приложение обмениваемся с сервером, и сформировать, например, описание класса — сервиса:
export default abstract class AbstractService { /** * Метод загрузки данных о группе с сервера * @fires get_group_data - имя действия, вызываемого на сервере * @returns данные о группе */ abstract getGroupData(): Promise<Group>; }На клиенте останется только реализовать этот класс, а на сервере — реализовать нужные действия и отдавать данные, которые сервис ожидает, формат их уже для всех ясен.
Теперь наше приложение уже достаточно обросло деталями, чтобы можно было приступать к реализации.
Проектирование функций
Только теперь мы, наконец, переходим к разработке.
Как и для других этапов, для проектирования функций у нас есть свой рецепт — алгоритм:
Алгоритм первоначального проектирования функций
-
Создаем заглушку. Заглушка — это определение функции, которое:
-
отражает правильное название функции
-
принимает правильное количество и типы параметров
-
возвращает произвольный результат, но корректного типа
-
-
Описываем входные, выходные данные и назначение функции
-
Пишем тесты. Тесты должны иллюстрировать поведение функции и проверять корректность выходных данных при разных входных данных.
-
Пишем тело функции.
-
Если в процессе написания функции необходимо обращаться к другой функции, то мы:
-
сразу описываем функцию и добавляем заглушку
-
добавляем отметку (TODO), помечающую нашу функцию как объект списка задач
-
Алгоритм повторяется до тех пор, пока не будут реализованы все задачи в списке задач
Пример проектирования функции
В нашем конкретном случае мы будем понимать под функциями как отдельные React — компоненты с их методами жизненного цикла, так и отдельные дополнительные методы внутри компонентов.
Двигаться, как всегда, мы будем сверху вниз — начиная с самых общих компонентов и постепенно уточняя их, шаг за шагом реализуя вложенные компоненты.
Шаг 1 — Создаем заглушку
Заглушка функции — это минимальное работоспособное её описание, в котором есть:
-
правильное название функции,
-
правильное количество и тип параметров и
-
возвращаемое значение, произвольное по содержанию, но правильного типа.
Для простой функции на TypeScript будет вполне достаточно написать что-то вроде:
export const getWorkDuration = (worktimeFrom: string, worktimeTo: string): string => { return "6ч 18мин"; }где:
-
getWorkDuration — правильное название фукнции, то есть то, которое мы и дальше будем использовать
-
worktimeFrom: string, worktimeTo: string — два строковых параметра. Именно столько параметров и такого типа функция должна принимать
-
: string после закрывающей круглой скобки — тип возвращаемого значения
-
return «6ч 18мин» — возврат произвольного значения, но правильного типа из функции
Несмотря на то, что такая функция ещё ничего не делает, у неё всё же есть одно очень важное свойство — она уже может выполняться в unit — тестах, что нам и требуется.
В случае с реактом у нас появляются ещё 2 вида заглушек: для функциональных компонентов и компонентов — классов. Выглядят они следующим образом:
Для функциональных компонентов:
const componentName = (props: PropsType) => { return <h1>componentName</h1> }Для компонентов классов:
class componentName extends React.Component<PropsType, StateType>{ state = { //произвольные значения для всех обязательных свойств состояния } render() { return <h1>componentName</h1> } }где:
-
PropsType — это описание типа передаваемых свойств
-
StateType — описание типа состояния компонента
Ну и реакт-компоненты возвращают нам заголовки с именами этих компонентов, чтобы мы сразу видели в браузере, что они отрисовываются на странице.
В нашем приложении с выпадающим списком сотрудников, самым верхним компонентом является компонент App. У него, как мы поняли из описания типов, есть состояние, значит это будет компонент-класс. Заглушка для него будет выглядеть следующим образом:
interface AppProps {} export default class App extends Component<AppProps, AppState> { state = { title: "Отображение списка групп", backendAddress: "", isLoading: true, loadData: this.loadData.bind(this) } /** * Метод загрузки данных с сервера */ //TODO loadData() { } render() { return <h1>App</h1> } }Надо отметить пару особенностей этой реализации:
-
В компонент App не передаётся никаких свойств «сверху», поэтому интерфейс AppProps пустой
-
Тип состояния компонента AppState мы импортируем напрямую из описания типов, которое мы создали, когда проектировали структуры
-
Состояние предусматривает метод loadData, поэтому мы тут же делаем заглушку для этого метода, отмечаем её маркером TODO, чтобы позже к ней вернуться
Шаг 2 — Описываем входные и выходные данные
После того, как заглушка готова, самое время начать думать, что и как функция должна делать. Размышления об этом мы поместим над её сигнатурой в формате JSDoc, чтобы и самим не забыть и для коллег, которые будут работать с этим кодом после нас, всё было предельно ясно.
Для обычных функций мы сначала описываем входные параметры, потом выходные, а потом, глядя на них, пытаемся придумать лаконичную формулировку, которая бы описывала, что функция делает. Тут же мы можем дать краткие пояснения к функционалу, если это необходимо:
/** * Рассчитывает количество часов и минут между указанным начальным и конечным временем * Если время начала работы больше времени конца, то считается, что конечное время - это время следующих суток * @param worktimeFrom - время начала работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @param worktimeTo - время конца работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @return количество часов и минут между переданным временем в формате Хч Y?мин, например 6ч 18мин или 5ч, если количество часов полное */ //TODO export const getWorkDuration = (worktimeFrom: string, worktimeTo: string): string => { return "6ч 18мин"; }И обязательно отмечаем нашу функцию маркером TODO, чтобы сразу бросалось в глаза, что функция не закончена.
Для реакт-компонентов я, как правило, такое описание не делаю, потому что входные и выходные параметры у всех компонентов одинаковые, да и назначение понятно. Но для всех нестандартных методов компонента и вспомогательных функций, которые не относятся к методам жизненного цикла или хукам реакта, я стараюсь писать документацию, аналогичную приведенной выше, — занимает пару минут, а экономит — часы.
Шаг 3. Тестирование
После того, как назначение и входные и выходные данные определены, можно начать продумывать поведение функции. Лучшее средство для этого — unit-тесты. Есть пара рекомендаций о том, как лучше их писать:
-
unit-тесты должны, как минимум, один раз проходить по каждой ветке внутри функции — то есть проверять все ветвления, если они есть
-
начинать писать и запускать unit-тесты надо с самых простых сценариев, например при которых выполнение функции сразу прерывается. Если даже эти тесты не проходят, то нет смысла тратить время и ресурсы на проверку более сложных вариантов
-
количество и содержание тестов определяются типов данных, с которыми они работают.
Последний пункт надо пояснить отдельно. Для этого давайте посмотрим, как это работает в функциональном программировании.
Зависимость содержания функций и тестов от типов данных в функциональном программировании
В функциональном программировании есть понятие «шаблона функции» — абстрактной схемы внутреннего устройства функции, которая зависит только от типа входных данных.
Допустим, у нас есть структура данных, описывающая состояние светофора. Эта структура называется «перечисление» или enum. То есть переменная этого типа может находиться в нескольких дискретных значениях:
type TrafficLights = "красный" | "желтый" | "зеленый";Это значит, что любая чистая функция, которая на вход получает один параметр типа TrafficLights будет построена по одной и той же схеме: в ней будет выполняться проверка на текущее значение параметра и, в зависимости от текущего значения, будет выполняться какая-то операция:
function trafficLightsFunction (trafficLights: TrafficLights) { switch (trafficLights) { case "красный": ... case "желтый": ... case "зеленый": ... } }Это и есть шаблон. Если нам понадобится написать очередную чистую функцию, в которой входным параметром будет структура типа TrafficLights — мы можем скопировать шаблон, заменить название функции, подставить нужные операции вместо «…» и вуаля, функция готова.
А раз функции имеют один и тот же шаблон, то и тестировать их нужно похожим образом. В данном случае, чтобы тесты проходили по всем веткам функции, они должны, как минимум, включать 3 сценария со всеми возможными значениями параметра. В зависимости от конкретной функции будут меняться только ожидаемые значения.
Получается, что тип входных данных определяет и внутреннюю структуру функции — шаблон, и сценарии тестирования.
Но такое утверждение полностью справедливо только для чистых функций, в то время как далеко не все функции у нас — чистые. Многие имеют побочные эффекты, на сервере — это запросы к БД или логирование, на клиенте — сетевые запросы или компоненты с состояниями. А в этом случае использовать подход с шаблонами «в лоб» не получается. Но, тем не менее, свою стратегию тестирования можно формировать с оглядкой на то, как это устроено для чистых функций, внося поправки на побочные эффекты. Что мы и будем делать.
Но сначала давайте посмотрим на взаимосвязь между типами данных и тестами для чистых функций:
|
№ |
Тип данных |
Описание |
Пример данных |
Правила тестирования |
|
1 |
Атомарные данные |
Данные, которые не могут быть разбиты на более мелкие части. При этом они независимы от других и сами не накладывают на другие данные ограничений |
Строка Логическое значение Число |
Для строк допустим 1 сценарий тестирования для логических значений — 2 (true / false) Для чисел — 1 сценарий, но может потребоваться дополнительный сценарий для значения 0 |
|
2 |
Перечисления |
Данные, которые могут принимать одно из нескольких состояний. |
Цвета светофора Пятибальная шкала оценок Размеры одежды и т.д. |
Для тестирования нужно, как минимум, столько сценариев, сколько классов значений в перечислении. Поэтому, если вам нужно протестировать 100-бальную шкалу оценок, но при этом вы понимаете, что значения группируются в 4 класса: 1 — 25, 26 — 50, 51 — 75, 76 — 100 То вам понадобится только 4 сценария. |
|
3 |
Интервалы |
Числа в определённом диапазоне |
Скорость автомобиля (0 — 300] Температура воздуха и т.д. |
Необходимо протестировать: значение внутри диапазона граничные значения |
|
4 |
Детализация |
Данные, состоящие из двух или более частей, по крайней мере одна из которых зависима от другой |
Подразделение расформировано или нет? Если расформировано, то какова дата расформирования В данном случае дата расформирования — атрибут, который зависит от признака, расформировано подразделение или нет. Если подразделение активно, то этой даты просто не существует Тестовый вопрос. В зависимости от типа вопроса может быть указана разная структура вариантов ответа. Если тип вопроса «множественный выбор» — есть массив вариантов ответа с признаками правильности. Если тип вопроса — ввод числа, то есть только один правильный ответ, без вариантов. |
Должно быть, как минимум, столько тест-кейсов, сколько комбинаций подклассов может быть. Для примера с подразделением должно быть минимум 2 сценария: подразделение нерасформировано и подразделение расформировано и указана дата расформирования А для примера с типами вопросов — как минимум, по одному для каждого типа. |
|
5 |
Сложный тип (объект) |
Данные, состоящие из нескольких независимых частей |
Объект «Сотрудник» имеющий поля: id ФИО Дата рождения Пол и т.д. |
Как минимум 2 сценария. При этом надо изменять значения всех полей |
|
6 |
Массив |
Набор данных, объем которых может изменяться |
Список сотрудников Массив учебных курсов, назначенных сотруднику |
Как правило, несколько сценариев: один, проверяющий работу функции при пустом массиве один, проверяющий работу функции при массиве с одним элементом один или несколько, проверяющих работу функции, когда элементов в массиве 2 и больше |
Примеры тестов
Давайте вернемся к нашим функциям и посмотрим, какие наборы тестовых кейсов нам стоило бы для них написать.
/** * Рассчитывает количество часов и минут между указанным начальным и конечным временем * Если время начала работы больше времени конца, то считается, что конечное время - это время следующих суток * @param worktimeFrom - время начала работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @param worktimeTo - время конца работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @return количество часов и минут между переданным временем в формате Хч Y?мин, например 6ч 18мин или 5ч, если количество часов полное */ //TODO export const getWorkDuration = (worktimeFrom: string, worktimeTo: string): string => { return "6ч 18мин"; }Итак, функция расчёта рабочего времени. Пусть вас не смущает тип string у параметров, каждый из параметров — это время, представленное в виде строки ЧЧ:ММ, то есть не атомарный тип, а интервал от 00:00 до 23:59. Согласно таблице, для интервалов надо проверить граничные значения и значения внутри диапазона. А так как параметра два, то это справедливо для каждого из них. Для этого нам потребуется 3 тест-кейса:
-
Первый параметр выходит за граничное значение, а второй нет
-
Второй параметр выходит за граничное значение, а первый — нет
-
Оба параметра — в пределах нормальных значений
И ещё в документации есть отметка о том, что рабочее время считается по разному в зависимости от соотношения значений. Вместо одного тест-кейса, где параметры находятся в пределах нормы, напишем 3 кейса, где первый параметр меньше, больше и равен второму, итого 5
|
№ |
Название |
worktimeFrom |
worktimeTo |
Ожидаемое значение |
|
1 |
Проверка корректности worktimeFrom |
Граничное значение, не входящее в диапазон, например «24:00» |
Нормальное значение, например «18:00» |
Исключение |
|
2 |
Проверка корректности worktimeFrom |
Нормальное значение, например «18:00» |
Граничное значение, не входящее в диапазон, например «24:00» |
Исключение |
|
3 |
Нормальная работа, worktimeFrom < worktimeTo |
Нормальное значение, меньшее чем worktimeTo, например «00:00» |
Нормальное значение, большее чем worktimeFrom, например, «23:59» |
23ч 59мин |
|
4 |
Нормальная работа, worktimeFrom > worktimeTo |
Нормальное значение, большее чем worktimeTo, например «18:49» |
Нормальное значение, меньшее чем worktimeFrom, например, «10:49» |
16ч |
|
5 |
Нормальная работа worktimeFrom = worktimeTo |
Нормальное значение, например, «01:32» |
Нормальное значение, например, «01:32» |
0ч |
Тест-кейсы мы к тому же составили так, чтобы одновременно проверялись выводимые значения: с минутами и без. Остается только написать сами тесты. Я их пишу при помощи Jest и Enzyme — стандартной комбинации для React JS. В самом написании тестов особых премудростей нет, поэтому приведу только один пример:
describe('Тестирование расчёта времени между началом и концом работы', () => { it('Когда начало и конец смены совпадают, функция возвращает 0ч', ()=>{ const result = getWorkDuration("01:32", "01:32"); expect(result).toBe("0ч"); }); //Подобным образом описываем все сценарии ... });Тестирование реакт-компонентов практически не отличается от тестирования обычных функций: поведение функциональных компонентов точно так же определяется входными параметрами, как и у чистых функций, поэтому и тестируются они точно так же. А вот поведение компонентов-классов, определяется помимо входных параметров собственным состоянием компонентов, и методами жизненного цикла, поэтому для их тестирования нам требуется специализированный инструмент — библиотека enzyme.
Давайте протестируем компонент App. Заглушка для него выглядела следующим образом:
interface AppProps {} export default class App extends Component<AppProps, AppState> { state = { title: "Отображение списка групп", backendAddress: "", isLoading: true, loadData: this.loadData.bind(this) } /** * Метод загрузки данных с сервера */ //TODO loadData() { } render() { return <h1>App</h1> } }Данные в этот компонент не передаются, а его поведение полностью определяется его состоянием, структуру которого мы определили ранее как:
/** * Общее состояние приложения * @prop title - заголовок приложения * @prop backendAddress - адрес сервера * @prop isLoading - флаг загрузки данных (true - загружаются, false - загружены) * @prop group - данные об отображаемой группе. На момент загрузки данных group не определена * @method loadData - метод загрузки данных */ export interface AppState { title: string; backendAddress: string; isLoading: boolean; group?: Group; loadData: Function; }Для начала определимся, к какому типу данных относится эта структура:
-
Во-первых, это сложная структура, состоящая из нескольких полей и членов.
-
Во-вторых, среди полей есть зависимые. Так, наличие поля group зависит от состояния загрузки, пока данные не загружены, данных о группе — нет. Если есть зависимые данные, то можно смело относить эти данные к типу «Детализация».
Если обратиться к нашей таблице с типами данных, то мы увидим, что:
-
для сложных типов (объектов) нужно написать как минимум 2 теста, изменяя при этом значения полей
-
для детализации надо написать как минимум столько тестов, сколько классов значений может быть. В нашем случае, классов значений два: когда данные загружаются и когда они загружены.
Таким образом, нам следует написать 4 отдельных теста:
-
2 — изменяя значения всех полей, чтобы проверить, что в нашем компоненте ничего жестко не «зашито» и он, действительно, реагирует на изменения значений
-
2 — изменяя статус загруженности и соответствующие данные, чтобы проверить, правильность поведения компонента в этом случае
Но в данном случае, меняя одновременно и значения полей и данные загрузки, мы можем 2 тестами закрыть все нужные сценарии.
И у нас остался ещё метод loadData — если вернуться назад к результатам анализа приложения, то мы увидим, что этот метод у нас появился из-за того, что мы хотели реагировать на конкретное событие в нашем приложении — загрузку данных сразу после появления приложения. Поэтому, желательно, в тесты добавить проверку, что событие, действительно, обрабатывается.
Начнём с простого — с вызова метода loadData при загрузке компонента:
import React from 'react'; import Enzyme, { mount, shallow } from 'enzyme'; import Adapter from 'enzyme-adapter-react-16'; Enzyme.configure({ adapter: new Adapter() }); import App from './App'; describe('App', () => { test('Когда компонент App смонтирован, вызывается функция loadData', () => { //Добавляем слушателя к функции loadData const loadData = jest.spyOn(App.prototype, 'loadData'); //Монтируем компонент const wrapper = mount(<App></App>); //Проверяем количество вызовов функции loadData expect(loadData.mock.calls.length).toBe(1); }); }Здесь мы подключили enzyme к нашему файлу с тестами, импортировали сам компонент и написали первый тест. Внутри теста мы:
-
добавили слушателя к функции loadData внутри компонента,
-
смонтировали компонент в тестовой среде (то есть сымитировали его появление в приложении) и
-
проверили, что компонент в ходе монтирования вызвал нашу функцию загрузки данных
Теперь реализуем следующий сценарий — отображение компонента во время загрузки данных.
test('Когда данные загружаются, отображаются только заголовок и спиннер', () => { //Монтируем компонент const wrapper = mount(<App></App>); //Подменяем состояние компонента на нужное для тестирования wrapper.setState({ title: "Заголовок 1", backendAddress: "/view_doc.html", isLoading: true, group: undefined, loadData: () => {} }) //Проверяем правильность отображения компонента //Проверяем наличие и содержание заголовка expect(wrapper.find('h1').length).toBe(1); expect(wrapper.find('h1').text()).toBe("Заголовок 1"); //Заглушка, отображающаяся в процессе загрузки expect(wrapper.find(Spinner).length).toBe(1); //Компонент, отображающий группу отображаться не должен expect(wrapper.find(Group).length).toBe(0); });Этот сценарий мы реализуем по следующей схеме:
-
Монтируем компонент
-
Подменяем его состояние на нужное нам. Тут как раз понадобятся примеры, которые мы писали в описании структуры данных. Нужные нам состояния можно не придумывать заново, а копировать подходящие значения оттуда
-
Проверяем правильность отображения компонента
Пока мы писали тест, стало понятно, что для нашего приложения потребуются ещё 2 компонента, которые мы пока не реализовывали:
-
заглушка для отображения в процессе загрузки — спиннер и
-
компонент для отображения данных о группе. Согласно нашей структуре, данные о группе выделены в отдельный объект, а значит обрабатываться должны отдельным компонентом.
В этом случае, как и прежде, мы сразу создаём для них заглушки и на время забываем о них.
Реализуем третий сценарий по аналогичной схеме:
test('Когда данные загружены, отображается заголовок и группа. Спиннер не отображается', () => { const wrapper = mount(<App></App>); wrapper.setState({ title: "Заголовок 2", backendAddress: "/view_doc_2.html", isLoading: false, group: { id: "1", name: "Группа 1", listOfCollaborators: [] }, loadData: () => {} }) expect(wrapper.find('h1').length).toBe(1); expect(wrapper.find('h1').text()).toBe("Заголовок 2"); expect(wrapper.find(Spinner).length).toBe(0); expect(wrapper.find(Group).length).toBe(1); });После написания тестов их обязательно надо запустить и убедиться, что они провалились и провалились не по причине синтаксических ошибок в них, а потому, что компонент пока работает не так, как нам нужно. Это будет означать, что тесты, действительно, готовы к работе.
После реализации теста, мы уже предельно точно понимаем, какие ситуации функция или компонент должны обрабатывать и какое поведение от них в этих ситуациях ждать. Значит, самое время написать тело функции.
Шаги 4 и 5. Реализация функций и формирование списка задач
После написания тестов, реализация функции становится делом тривиальным. То есть мы, как бы, перенесли всю сложность обдумывания функции на тесты, а теперь остаётся самая простая часть. Тем не менее, и для реализации найдется пара рекомендаций:
-
во-первых, старайтесь писать более высокоуровневый код,
-
во-вторых, избегайте коварной ошибки, которая называется Knowledge Shift (сдвиг области знаний).
Высокоуровневый код
Не торопитесь сразу приступать к реализации. Для начала подумайте не о том, как реализовать алгоритм, а о том, какие крупные шаги в нем могут быть и что вы хотите получить на каждом из этих шагов. Подумайте, можно ли без ущерба вынести каждый такой шаг в отдельную функцию, и если это сделать можно — смело выносите.
В качестве примера мы возьмём реализацию функции расчёта времени между началом и концом рабочей смены, которую мы тестировали ранее. Заглушка этой функции выглядела так:
/** * Рассчитывает количество часов и минут между указанным начальным и конечным временем * Если время начала работы больше времени конца, то считается, что конечное время - это время следующих суток * @param worktimeFrom - время начала работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @param worktimeTo - время конца работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @return количество часов и минут между переданным временем в формате Хч Y?мин, например 6ч 18мин или 5ч, если количество часов полное */ //TODO export const getWorkDuration = (worktimeFrom: string, worktimeTo: string): string => { return "6ч 18мин"; }Очевидно, что для того, чтобы получить разницу во времени между двумя параметрами, каждый из которых представляет собой строку в формате «ЧЧ:ММ», и вернуть эту разницу тоже в строковом формате, нам надо выполнить несколько действий:
-
Привести параметры к числовым значениям, например, минутам, прошедшим с 00:00
-
Вычислить разницу между ними, с учетом того, находятся они в одних сутках или в разных
-
Привести получившуюся разницу к формату Xч Y?мин, который и вернуть из функции
И тут мы могли бы пойти двумя путями:
-
сразу начать делить параметры на части по разделителю «:», проверяя входные значения и умножая часы на минуты и т.д. или
-
выделить каждый шаг в отдельную функцию.
В результате мы бы получили такую картину:
/** * Рассчитывает количество часов и минут между указанным начальным и конечным временем * Если время начала работы больше времени конца, то считается, что конечное время - это время следующих суток * @param worktimeFrom - время начала работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @param worktimeTo - время конца работы в формате ЧЧ:ММ (от 00:00 до 23:59) * @return количество часов и минут между переданным временем в формате Хч Y?мин, например 6ч 18мин или 5ч, если количество часов полное */ export const getWorkDuration = (worktimeFrom: string, worktimeTo: string): string => { const worktimeFromInMinutes = getWorktimeToMinutes(worktimeFrom); const worktimeToInMinutes = getWorktimeToMinutes(worktimeTo); const minutesDiff = calcDiffBetweenWorktime(worktimeFromInMinutes, worktimeToInMinutes); return convertDiffToString(minutesDiff); } /** * Вычиcляет количество минут, прошедших с начала суток * @param worktimeFrom - время в формате ЧЧ:ММ (от 00:00 до 23:59) * @returns количество минут, прошедших с 00ч 00минут */ //TODO export const getWorktimeToMinutes = (worktime: string): number => { return 0; } /** * Вычисляет количество минут между началом и концом рабочего дня с учётом суток * @param worktimeFrom - время начала рабочего дня в виде количества минут, прошедших с начала суток * @param worktimeTo - время конца рабочего дня в виде количества минут, прошедших с начала суток * @returns количество минут между началом и концом рабочего дня с учётом суток */ //TODO export const calcDiffBetweenWorktime = (worktimeFrom: number, worktimeTo: number): number => { return 0; } /** * Преобразовывает количество минут во время в формате Хч Y?мин * @param minutes - количество минут * @returns время в формате Хч Y?мин, например 6ч 18мин или 5ч */ //TODO export const convertDiffToString = (minutes: number): string => { return "6ч 18мин"; }Основная функция здесь распадается на несколько вложенных, определяя, по сути, только верхнеуровневый алгоритм преобразования. Сами же детали реализации алгоритма вынесены в отдельные функции. Согласно нашей технологии, для каждой новой функции сразу пишется только заглушка и маркер TODO, который формирует наш список задач. Сами функции будут реализовываться позже. Вложенные функции, в свою очередь, могут дробиться на ещё более мелкие по тем же принципам.
В итоге мы получим большое количество маленьких универсальных функций, комбинируя которые мы сможем решать совершенно разные задачи. А учитывая, что вложенные функции, если соблюдать технологию, сами собой получаются нормально документированными и тестированными, они вполне могут составить какую-то отдельную библиотеку функционала, которая будет переиспользоваться в других проектах.
Knowledge Shift
Говоря о проектировании функций, конечно же, нельзя обойти стороной такую ошибку как Knowledge Shift.
Чтобы понять, что это за ошибка, мы снова обратимся к чистым функциям, которые, как вы знаете, работает только с теми структурами данных, которые передаются ей в качестве параметров — эти структуры составляют её область знаний (домен) . Но часто случается так, что структуры, поступающие на вход функции сами являются сложными, то есть содержат внутри себя вложенные объекты или массивы.
В этом случае, мы рискуем столкнуться с ситуацией, когда функция начинает выполнять какие-то операции над входными структурами, а затем переключается на работу с вложенными, как бы сдвигая фокус с родителя на дочерний объект. Это и есть Knowledge Domain Shift или просто Knowledge Shift.
В результате мы получаем разбухшую, трудно тестируемую и поддерживаемую функцию, которая, вопреки требованию единой ответственности, отвечает сразу за несколько структур.
Чтобы этого избежать, рекомендуется передавать обработку внутренних сложных структур в отдельные функции, как мы сделали это при реализации нашего реакт-компонента App:
export default class App extends Component<AppProps, AppState> { state = { title: "Отображение списка групп", backendAddress: "", isLoading: true, group: undefined, loadData: this.loadData.bind(this) } /** * Метод загрузки данных с сервера */ //TODO loadData() {} componentDidMount() { //Вызываем метод loadData при загрузке приложения this.loadData(); } render() { const {isLoading, group, title} = this.state; return ( <div className="container"> <h1>{title}</h1> { isLoading ? <Spinner/> //Структуру типа Group передаем на обработку отдельному компоненту : <Group group={group}></Group> } </div> ); } }Мы добавили в компонент реализацию метода жизненного цикла componentDidMount, который вызовет наш метод загрузки данных при отображении компонента. Но основной функционал у нас содержится в методе render. В нем мы выводим заголовок и, в зависимости от статуса загрузки, рисуем либо заглушку — спиннер, либо компонент Group.
Обратите внимание, что мы напрямую используем только простые данные, относящиеся к структуре cостояния компонента. Сложную вложенную структуру group мы просто передаем в отдельный компонент, потому что не хотим, чтобы компонент App знал о ней что-то кроме того, что она вообще есть. Таким образом, структуры данных определяют, по сути, не только реализацию конкретного компонента, но и, частично, структуру приложения и его разбиение на компоненты.
Теперь, нам остаётся только удостовериться, что все написанные нами тесты проходят. После чего, мы берем следующую задачку, отмеченную маркером TODO и реализовываем её по точно такой же схеме: тесты + реализация функции. И так мы продолжаем до тех пор, пока ни одной TODO в нашем списке не останется.
Когда наступит этот чудный момент вы просто запустите приложение и насладитесь тем, как оно просто работает. Не валится из-за пропущенных ошибок или забытого и нереализованного сценария, а просто работает.
Вот в общем-то и весь подход. Он не сложен, но требует привычки и дисциплины. Как и в любом сложном деле, самая большая проблема — начать и не поддаваться желанию бросить его на первых парах. Если это удастся, то через некоторое время вы и думать не захотите о том, чтобы писать код по старинке: без тестов, документации и с длинными непонятными функциями. Успехов!
ссылка на оригинал статьи https://habr.com/ru/post/545852/
Добавить комментарий