«Шеф, всё пропало, у нас serial на мегатаблице почти закончился!» — а это значит, что либо вы его неаккуратно накрутили сами, либо у вас действительно данных столько, что разрядности integer-столбца уже не хватает для вашей большой и активной таблицы в PostgreSQL-базе.
Да и столбец этот не простой, а целый PRIMARY KEY, на который еще и ряд других немаленьких таблиц по FOREIGN KEY завязан. А еще и приложение останавливать совсем не хочется, ибо клиентам 24×7 обещано…
В общем, надо как-то с минимальными блокировками увеличить размер PK-поля в большой таблице, на которое многое завязано.

Организуем небольшой тестовый полигон:
CREATE TABLE tblpk( pk serial PRIMARY KEY , valx integer ); INSERT INTO tblpk(valx) SELECT generate_series(1, 1e6); CREATE TABLE tblfk( fk integer REFERENCES tblpk , valy integer ); INSERT INTO tblfk(fk, valy) SELECT (random() * (1e6 - 1))::integer + 1, generate_series(1, 1e6); -- не забываем, что для FK нужно создавать индекс "вручную" CREATE INDEX ON tblfk(fk);Подготовительные работы
Первую часть работы можно сделать без наложения каких-либо блокировок вообще.
Добавляем новое поле:
ALTER TABLE tblpk ADD COLUMN _pk bigint; ALTER TABLE tblfk ADD COLUMN _fk bigint;Универсальный копирующий триггер
Чтобы для всех добавляемых и изменяемых записей состояние нового и старого полей у нас не разбегалось, повесим на таблицу копирующий триггер — на вставку новой записи или изменение отслеживаемого поля:BEFORE INSERT OR UPDATE OF <PK-поле>.
Ровно такую же задачу нам придется решать и для таблицы tblfk, поэтому сразу напишем триггерную функцию, которую можно будет универсально применять на любой таблице, использовав немного SQL-магии:
CREATE OR REPLACE FUNCTION copy_fld() RETURNS trigger AS $$ DECLARE fld_src text := quote_ident(TG_ARGV[0]); -- имя исходного поля fld_dst text := quote_ident(TG_ARGV[1]); -- имя целевого поля BEGIN EXECUTE $q$ -- собираем тело запроса как текст SELECT ( json_populate_record( -- наполняем запись данными из JSON $1 -- NEW , json_build_object( -- {[fld_dst] : NEW[fld_src]}::json '$q$ || fld_dst || $q$' , $1.$q$ || fld_src || $q$::text ) ) ).* -- "разворачиваем" record по столбцам $q$ USING NEW -- используем NEW в качестве $1-аргумента INTO NEW; -- результат складываем обратно в NEW RETURN NEW; -- не забываем вернуть NEW, иначе изменения не применятся END $$ LANGUAGE plpgsql;Теперь мы можем передать синхронизируемые поля как аргументы триггера — разные для каждой из таблиц:
CREATE TRIGGER copy BEFORE INSERT OR UPDATE OF pk ON tblpk FOR EACH ROW EXECUTE PROCEDURE copy_fld('pk', '_pk'); -- откуда/куда CREATE TRIGGER copy BEFORE INSERT OR UPDATE OF fk ON tblfk FOR EACH ROW EXECUTE PROCEDURE copy_fld('fk', '_fk');Массовое обновление записей
Самый простой вариант — обновить значение добавленного поля во всех уже существующих записях за один запрос:
UPDATE tblpk SET _pk = pk WHERE _pk IS NULL; UPDATE tblfk SET _fk = fk WHERE _fk IS NULL;Он же — самый проблемный, поскольку повлечет за собой возникновение длительных блокировок всех запросов, которые тоже захотят что-то изменить в этих записях.
Лучше всего воспользоваться сегментным обновлением, как это описано в статье «PostgreSQL Antipatterns: обновляем большую таблицу под нагрузкой». В результате единый UPDATE превратится в серию быстрых запросов, которые отлично садятся на индекс первичного ключа:
UPDATE tblpk SET _pk = pk WHERE pk BETWEEN $1 AND $1 + 999 AND -- перебираем сегменты значений по 1K _pk IS NULL;Создаем новый индекс
В неблокирующем режиме создаем индекс, который будет выполнять роль нового первичного ключа:
CREATE UNIQUE INDEX CONCURRENTLY _pk ON tblpk(_pk); -- индекс под новый PK CREATE INDEX CONCURRENTLY _fk ON tblfk(_fk); -- индекс под новый FKВ принципе, индексы можно было создать и раньше, но тогда все наши UPDATE писали бы еще и в него, поэтому работали бы существенно дольше.
Быстрая неблокирующая* конвертация
Сначала поймем, как примерно должен выглядеть наш целевой результат в самом простом варианте:
-
снимаем все autovacuum/autoanalyze, которые блокируют наши таблицы
Эти процессы запустятся с очень большой вероятностью практически сразу, поскольку мы
UPDATE‘нули все записи в каждой из таблиц. Если мы не снимем их и накладываемые ими блокировки, все нашиALTER TABLEбудут ждать получения блокировки сами (Access Exclusive), а за ними будет копиться очередь всех остальных запросов, дажеSELECT(Access Share) по этим таблицам. -
блокируем таблицы в монопольном режиме
Если этого не сделать, какой-нибудь настырный
SELECTиз параллельного подключения вполне может вклиниться между нашимиALTER TABLE, что опять-таки приведет к длительным блокировкам.Пытаемся наложить блокировку в
NOWAIT-режиме, чтобы при наличии активногоSELECT-запроса (их-то мы не снимали) по любой из таблиц не висеть и ждать его, создавая за собой очередь, а отвалиться сразу. -
модифицируем последовательность: привязываем ее к новому столбцу (
OWNED BY) и снимаем ограничение на максимальное значение (NO MAXVALUE) -
модифицируем основную таблицу:
-
удаляем старый столбец каскадно, что заодно удалит и ненужный нам более copy-триггер, старый первичный ключ вместе с индексом и все смотрящие на него внешние ключи
-
переименовываем новый столбец в старый
-
назначаем DEFAULT для нового столбца именно здесь, поскольку назначение раньше могло бы привести к двойному выполнению выражения
-
создаем новый первичный ключ с использованием заранее подготовленного уникального индекса, что заодно этот индекс и переименует
-
-
аналогично модифицируем связанную таблицу в чуть другом порядке:
-
удаляем и переименовываем столбцы
-
восстанавливаем внешний ключ в
NOT VALID-режиме без фактической проверки уже содержащихся в таблице данных -
восстанавливаем имя индекса под внешним ключом
-
BEGIN; -- снимаем все процессы autovacuum/autoanalyze по нашим таблицам SELECT pg_terminate_backend(pid) FROM pg_stat_activity sa WHERE CASE WHEN backend_type = 'autovacuum worker' THEN EXISTS( SELECT NULL FROM pg_locks WHERE locktype = 'relation' AND relation = ANY(ARRAY['tblpk', 'tblfk']::regclass[]) ) END; -- сразу блокируем все таблицы, чтобы никто не влез LOCK TABLE tblpk, tblfk IN ACCESS EXCLUSIVE MODE NOWAIT; -- sequence ALTER SEQUENCE tblpk_pk_seq OWNED BY tblpk._pk; ALTER SEQUENCE tblpk_pk_seq NO MAXVALUE; -- tblpk ALTER TABLE tblpk DROP COLUMN pk CASCADE; -- сносит заодно copy-триггер, PK и все FK ALTER TABLE tblpk RENAME COLUMN _pk TO pk; ALTER TABLE tblpk ALTER COLUMN pk SET DEFAULT nextval('tblpk_pk_seq'); ALTER TABLE tblpk ADD CONSTRAINT tblpk_pkey PRIMARY KEY USING INDEX _pk; -- tblfk ALTER TABLE tblfk DROP COLUMN fk CASCADE; ALTER TABLE tblfk RENAME COLUMN _fk TO fk; ALTER TABLE tblfk ADD CONSTRAINT tblfk_fk_fkey FOREIGN KEY(fk) REFERENCES tblpk NOT VALID; -- без проверки ограничения по существующим данным ALTER INDEX _fk RENAME TO tblfk_fk_fkey; COMMIT;Все эти действия происходят единым куском под общей блокировкой, поэтому, благодаря транзакционности DDL в PostgreSQL, либо успешно выполнятся целиком, либо целиком же — нет. Однако, за счет того, что тут нет ни одной длительной операции, весь скрипт должен отработать за минимальное время.
При этом все внешние ключи будут пересозданы с признаком «невалидности», хотя все данные под ними заведомо корректны. Жить это не мешает ровно никак, но если очень хочется отвалидировать FK настолько сильно, что мы даже готовы на ExclusiveLock, что заблокирует даже чтение из таблицы, пока вся она будет перечитываться, то делаем так:
ALTER TABLE tblfk VALIDATE CONSTRAINT tblfk_fk_fkey;Что мы забыли?
Приведенный выше код вполне работает, но только в простейших случаях.
Связанные объекты
В базе достаточно просто увидеть, на кого ссылается сама таблица, но весьма сложно обнаружить, кто ссылается на нее. Чтобы ничего не пропустить, напишем запрос, который их все найдет и подготовит скрипт для дальнейшей замены полей.
Тут мы встречаем нескольких персонажей, чьи имена мы нигде ранее не упоминали, не задавали, и потому знать не можем:
-
tblpk_pkey— имя ограничения первичного ключа -
tblfk_fk_fkey— имя ограничения внешнего ключа -
tblpk_pk_seq— имя serial-последовательности
Собственно, их имена могли быть как присвоены автоматически самим PostgreSQL, так и заданы владельцами базы — поэтому достоверно ориентироваться на то, что они окажутся именно такими, мы не можем.
Сложные индексы
Аналогично, мы исходили из предположения, что индексы у нас самые простые, из единственного поля и без всяких условий. Но FK-индекс запросто может иметь вид tblfk(fk) WHERE fk IS NOT NULL, чтобы NULL-строки не замусоривали его, а PK включать в себя и другие поля, кроме serial.
Действия внешних ключей
Внешние ключи также могут быть определены существенно более сложно, чем в нашей модели — там может оказаться что-то вроде MATCH PARTIAL INITIALLY DEFERRED или ON DELETE SET NULL ON UPDATE RESTRICT.
Триггеры
Удалив каскадно старый столбец, мы снесли также и copy-триггер. А что если он был не один на этом поле?..
Имена и комментарии
Имя индекса внешнего ключа мы восстанавливали «по наитию», но нет абсолютно никакой гарантии, что оно совпадает с именем FK-ограничения.
А еще мы забыли восстановить комментарии объектов, которые могли быть наложены через COMMENT ON.
Скрипт миграции
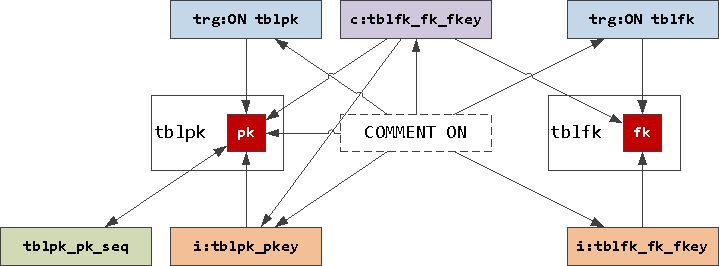
По этим причинам самый правильный вариант — использовать генерирующий запрос, который сформирует скрипт миграции для всех связанных таблиц. Чтобы понять, почему же он получается настолько сложным, представим связи наших объектов графически:
-
sequence ссылается на поле через
OWNED BY, а оно обратно черезDEFAULT -
индексы и триггеры ссылаются на поле напрямую
-
FK-constraint связывает поля пары таблиц и уникальный индекс на ведущей таблице
-
и все это может быть откомментировано
Создадим для теста максимально-проблемную для переноса ситуацию — сложные имена таблиц и полей, комментарии, триггеры и «хитрые» именованные FK:
CREATE TABLE "1st table"( "primary key col" serial PRIMARY KEY , valx integer ); COMMENT ON COLUMN "1st table"."primary key col" IS 'col-comment'; INSERT INTO "1st table"(valx) SELECT generate_series(1, 1e5); CREATE TABLE "2nd table"( fk integer CONSTRAINT "FK-name" REFERENCES "1st table" ON UPDATE SET NULL ON DELETE RESTRICT , valy integer ); COMMENT ON CONSTRAINT "FK-name" ON "2nd table" IS 'con-comment'; INSERT INTO "2nd table"(fk, valy) SELECT (random() * (1e5 - 1))::integer + 1, generate_series(1, 1e5); CREATE INDEX "FK-idx-name" ON "2nd table"(fk); COMMENT ON INDEX "FK-idx-name" IS 'idx-comment'; CREATE OR REPLACE FUNCTION tmp() RETURNS trigger AS $$ BEGIN RAISE NOTICE 'NEW : %', NEW::text; END $$ LANGUAGE plpgsql; CREATE TRIGGER tmp AFTER INSERT OR UPDATE OF "primary key col" ON "1st table" FOR EACH ROW EXECUTE PROCEDURE tmp(); COMMENT ON TRIGGER tmp ON "1st table" IS 'trg-comment';Ну, а теперь дело за малым! Вот наш скрипт:
Скрипт расширения serial -> bigserial
-- $1 : '"1st table"' - с кавычками! -- $2 : 'primary key col' - без кавычек! WITH src(rel, fld) AS ( VALUES($1::regclass, $2::name) ) , fld AS ( SELECT * FROM src JOIN pg_attribute at ON (at.attrelid, at.attname) = (src.rel, src.fld) ) , idx AS ( SELECT idx.* FROM fld JOIN pg_index idx ON indrelid = attrelid AND indkey::smallint[] && ARRAY[attnum] ) , con AS ( SELECT CASE contype WHEN 'p' THEN attnum WHEN 'f' THEN conkey[array_position(confkey, attnum)] END idkey , con.* FROM fld JOIN pg_constraint con ON (conrelid = attrelid AND conkey && ARRAY[attnum]) OR (confrelid = attrelid AND confkey && ARRAY[attnum]) ) -- столбцы, входящие в PK или FK , colkey AS ( SELECT * , attrelid::regclass::text _attrel , '_' || md5(attname) _attname , quote_ident(attname) _qiattname , replace(col_description(attrelid, attnum), '''', '''''') dsccol FROM con INNER JOIN pg_attribute at ON (attrelid, attnum) = (conrelid, idkey) WHERE atttypid <> 'bigint'::regtype ) , code_col AS ( SELECT string_agg( $$-- $$ || _attrel || $$ ALTER TABLE $$ || _attrel || $$ ADD COLUMN $$ || _attname || $$ bigint; $$ || CASE WHEN dsccol IS NOT NULL THEN $$COMMENT ON COLUMN $$ || _attrel || '.' || _attname || $$ IS '$$ || dsccol || $$'; $$ ELSE '' END || $$CREATE TRIGGER copy BEFORE INSERT OR UPDATE OF $$ || _qiattname || $$ ON $$ || _attrel || $$ FOR EACH ROW EXECUTE PROCEDURE copy_fld('$$ || attname || $$', '$$ || _attname || $$'); UPDATE $$ || _attrel || $$ SET $$ || _attname || $$ = $$ || _qiattname || $$ WHERE $$ || _attname || $$ IS NULL; -- лучше сегментно!!! $$ , '' ) code FROM colkey ) -- индексы , indkey AS ( SELECT * , quote_ident('_' || md5(sch || '.' || rel || '.' || idxname)) _idxname FROM ( SELECT pg_get_indexdef(indexrelid) def , cli.relnamespace::regnamespace::text sch , idx.indrelid::regclass::text rel , quote_ident(cli.relname) idxname , replace(obj_description(cli.oid, 'pg_class'), '''', '''''') dscidx , * FROM colkey JOIN pg_index idx ON indrelid = attrelid AND indkey::smallint[] && ARRAY[attnum] JOIN pg_class cli ON cli.oid = idx.indexrelid ) T ) , code_idx AS ( SELECT string_agg( E'-- ' || idxname || E'\n' || regexp_replace( regexp_replace( def , E'(CREATE(?: UNIQUE)? INDEX ).*?( ON ).*?( USING )' , E'\\1CONCURRENTLY ' || _idxname || E'\n ON ' || sch || '.' || rel || E'\n USING ' ) , E'(USING \\S+ \\(.*)' || _qiattname || E'(.*\\))' , E'\\1' || _attname || E'\\2' , 'g' ) || E';\n' || CASE WHEN dscidx IS NOT NULL THEN $$COMMENT ON INDEX $$ || _idxname || $$ IS '$$ || dscidx || $$'; $$ ELSE '' END , '' ) code FROM indkey ) -- тфблицы , code_rel AS ( SELECT $q$-- зачищаем мешающие autovacuum SELECT pg_terminate_backend(pid) FROM pg_stat_activity sa WHERE CASE WHEN backend_type = 'autovacuum worker' THEN EXISTS( SELECT NULL FROM pg_locks WHERE locktype = 'relation' AND relation = ANY('$q$ || array_agg(rel)::text || $q$'::regclass[]) ) END; -- блокируем все таблицы LOCK TABLE $q$ || string_agg(rel, ', ') || $q$ IN ACCESS EXCLUSIVE MODE NOWAIT; $q$ code FROM ( SELECT DISTINCT _attrel rel FROM colkey ) T ) -- последовательность , seqkey AS ( SELECT pg_get_serial_sequence(attrelid::regclass::text, attname) seq , * FROM colkey ) , code_seq AS ( SELECT $q$ALTER SEQUENCE $q$ || seq || $q$ OWNED BY $q$ || _attrel || '.' || _attname || $q$; ALTER SEQUENCE $q$ || seq || $q$ NO MAXVALUE; $q$ FROM seqkey WHERE seq IS NOT NULL ) -- столбцы , code_col_tx AS ( SELECT string_agg( $$-- $$ || _attrel || $$ ALTER TABLE $$ || _attrel || $$ DROP COLUMN $$ || _qiattname || $$ CASCADE; ALTER TABLE $$ || _attrel || $$ RENAME COLUMN $$ || _attname || $$ TO $$ || _qiattname || $$; $$ || CASE WHEN adsrc IS NOT NULL THEN $$ALTER TABLE $$ || _attrel || $$ ALTER COLUMN $$ || _qiattname || $$ SET DEFAULT $$ || adsrc || $$; $$ ELSE '' END , '' ) code FROM colkey LEFT JOIN pg_attrdef ad ON (adrelid, adnum) = (attrelid, attnum) ) -- индексы , code_idx_tx AS ( SELECT string_agg( $$ALTER INDEX $$ || _idxname || $$ RENAME TO $$ || idxname || $$; $$ , '') FROM indkey ) -- ключи , code_con_tx AS ( SELECT string_agg( ( SELECT string_agg( 'ALTER TABLE ' || conrelid::regclass::text || E'\n ADD ' || CASE con.contype WHEN 'p' THEN 'PRIMARY KEY USING INDEX ' || idxname WHEN 'u' THEN 'UNIQUE USING INDEX ' || idxname WHEN 'f' THEN 'CONSTRAINT ' || quote_ident(con.conname) || ' ' || pg_get_constraintdef(con.oid) || CASE WHEN pg_get_constraintdef(con.oid) !~* 'NOT VALID' THEN E'\n NOT VALID' ELSE '' END END || E';\n' || CASE WHEN obj_description(con.oid, 'pg_constraint') IS NOT NULL THEN $$COMMENT ON CONSTRAINT $$ || quote_ident(conname) || $$ ON $$ || conrelid::regclass::text || $$ IS '$$ || replace(obj_description(con.oid, 'pg_constraint'), '''', '''''') || $$'; $$ ELSE '' END , '' ORDER BY CASE con.contype WHEN 'p' THEN 0 WHEN 'u' THEN 1 WHEN 'f' THEN 2 END ) FROM pg_constraint con WHERE conindid = indexrelid ) , '' ) code FROM indkey ) -- триггеры , trgkey AS ( SELECT pg_get_triggerdef(trg.oid) def , replace(obj_description(trg.oid, 'pg_trigger'), '''', '''''') dsctrg , * FROM colkey JOIN pg_trigger trg ON tgrelid = attrelid AND tgattr::smallint[] && ARRAY[attnum] WHERE NOT tgisinternal ) , code_trg AS ( SELECT string_agg( def || E';\n' || CASE WHEN dsctrg IS NOT NULL THEN $$COMMENT ON TRIGGER $$ || quote_ident(tgname) || $$ ON $$ || _attrel || $$ IS '$$ || dsctrg || $$'; $$ ELSE '' END , '' ) code FROM trgkey ) SELECT E'-- столбцы\n' || (TABLE code_col) || E'\n-- индексы\n' || (TABLE code_idx) || E'\nBEGIN;\n' || regexp_replace( (TABLE code_rel) || E'\n-- последовательность\n' || (TABLE code_seq) || E'\n-- столбцы\n' || (TABLE code_col_tx) || E'\n-- индексы\n' || (TABLE code_idx_tx) || E'\n-- ключи\n' || (TABLE code_con_tx) || E'\n-- триггеры\n' || (TABLE code_trg) , E'^(.)' , E' \\1' , 'gm' ) || E'COMMIT;\n';Надеюсь, когда-то этот скрипт пригодится и вам.
ссылка на оригинал статьи https://habr.com/ru/company/tensor/blog/547740/
Добавить комментарий