
Привет, Хабр! Компьютерное зрение и искусственный интеллект — одни из самых востребованных направлений в современном IT. Поэтому мы выбрали именно их для учебного «Межгалактического Хакатона 2021» который организовали НИТУ МИСиС и Zavtra.Online (подразделение SkillFactory по работе с университетами).
В хакатоне были представлены 5 кейсов от разных компаний, и одним из них был кейс от компании IntelliVision — кластеризация изображений транспортных средств. Его и выбрала команда финалистов, описав реализацию подобного проекта от А до Я.
Начало работы
Целью любого кластерного анализа является поиск существующих структур. Так и в нашей задаче были даны изображения, которые нужно разбить на кластеры и интерпретировать каждый из них. В качестве исходных данных нам предоставили изображения транспортных средств разных типов, цветов, ракурсов и деталей. Исходные изображения были загружены в нейронную сеть, которая определила паттерны и построила модель, и эта модель отображается в виде вектора (дескриптора), полученного на промежуточном (скрытом) слое нейронной сети. Варианты дескрипторов, полученные с помощью глубокого обучения, были исходными данными для дальнейшей кластеризации: color_model, osnet, efficientnet-b7, type_model.
Для всех вариантов дескрипторов нужно было применить несколько алгоритмов кластеризации и сравнить полученные результаты. Сравнивать можно по метрикам и по тому, насколько хорошо кластеры интерпретируются.
Дополнительным плюсом было то, что среди изображений могли быть выделены выбросы (изображения плохого качества, изображения, на которых нет транспортных средств, и т. д).
Особенности выполнения задания
Не сразу удалось оценить всю сложность этого кейса. Казалось бы, набор данных есть, дополнительные фичи делать не нужно, вызываем всевозможные алгоритмы, и решение готово. Одними из главных вызовов этого задания были обработка больших массивов данных и проведение большого количества экспериментов в ограниченный срок.
Сначала проводилась работа по понижению размерности данных для увеличения скорости обучения моделей, но PCA давал малоинформативные результаты, а t-SNE из библиотеки scikit-learn имел низкую производительность. И тут на помощь пришёл Rapids — бесплатный open-source фреймворк для ускорения обработки данных от NVIDIA, в котором есть библиотека машинного обучения cuML. Задача была решена в Jupyter Notebook в Google Colab, так как в эту среду легко установить Rapids, а также использовать его совместно с GPU Tesla K80 с 13 Гб видеопамяти на борту.
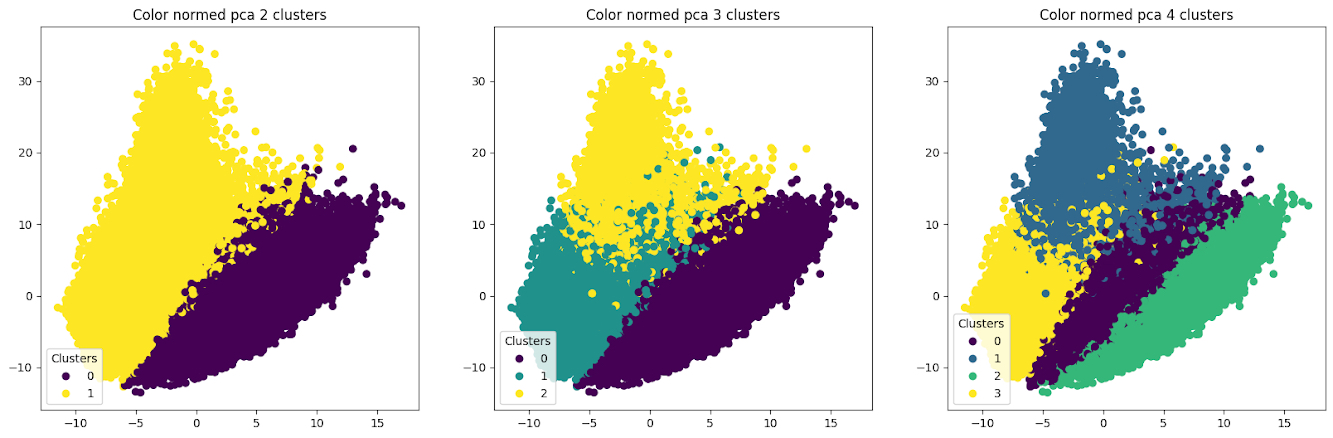
Исследование набора данных color_model
Этот набор данных в виде csv файла из 416314 строк и 128 столбцов был получен при помощи модели регрессии для определения цвета транспортных средств в формате RGB. Это единственный набор, который было возможно использовать для проведения экспериментов без понижения размерности.
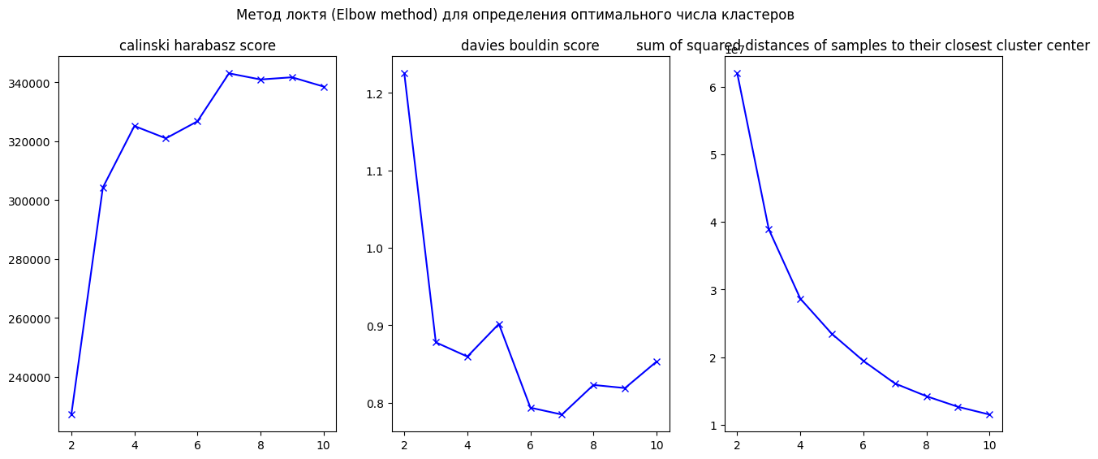
Кандидатами в лучшее число кластеров на основе «метода локтя» оказались 3 и 4.
По визуализации результатов кластеризации (кандидаты в лучшие кластеры) для стандартизированных и нормированных данных видно, что предобработка данных повлияла на результат кластеризации. Разделение на 2 и 3 кластера — почти одинаковое вне зависимости от способа обработки данных, но есть разница в разбиении на 4 кластера.
Это увеличенные результаты кластеризации на данных, размерность которых была понижена при помощи t-SNE. Видно, что алгоритм пытается выделять кластеры и один из них — синий — отделил успешно, но в целом чёткой границы нет.

По итогам экспериментов мы визуализировали случайные картинки для каждого из результатов разбиения на 2, 3, 4 кластера.


Видно, что в зависимости от потребностей при 2-х, 3-х и 4-х кластерах вне зависимости от типа обработки можно получить кластеры:
[Светлый-Тёмный],
[Светлый-Тёмный-Цветной],
[Светлый-Серый-Тёмный-Цветной]
А что же другие алгоритмы? Мы попробовали также DBSCAN, и у него получилось выделить отдельно выбросы — фото низкого качества. Это фото с включёнными фарами, вблизи и сзади. Интересный эффект — кластер жёлтых автомобилей.


Видно, что, комбинируя K-means и DBSCAN, можно в зависимости от потребностей получить разбивку на цветовые кластеры с различной детализацией, а также выделить выбросы.
Исследование набора данных osnet
Следующим набором дескрипторов, на котором мы провели исследования, стал osnet.
Из условий задачи нам было известно, что для построения дескрипторов osnet использовалась нейронная сеть, обученная для повторной идентификации людей, животных и машин (reID). В отличие от type_model и color_model эта модель не обучалась на исходном датасете veriwild.
В связи с этим мы предположили, что модель, обученная на наборе дескрипторов osnet, должна объединять в кластеры объекты не только по цвету и типу транспортных средств, но и по другим признакам (например, ракурсу съёмки).
В связи большим размером данных osnet (csv файл из 416314 строк и 512 столбцов) и ограниченности имеющихся вычислительных мощностей и сроков все эксперименты проводились на предобработанных данных с пониженной при помощи t-SNE размерностью.
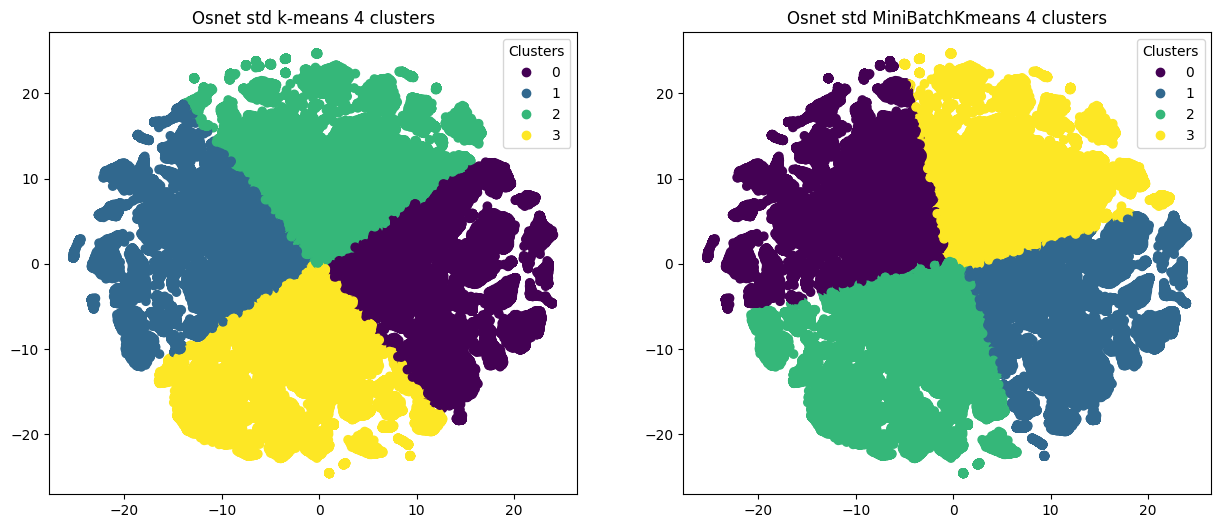
Помимо простого алгоритма k-Means мы решили проверить Mini-Banch k-Means. Как и ожидалось, Mini-Banch k-Means справился быстрее, но качество кластеризации, показанное простым k-Means, оказалось лучше.

Как и на других наборах данных, оптимальное число кластеров определяли с помощью «метода локтя». Оптимальными кандидатами являются 3-й и 4-й кластеры.
После стандартизации данных на диаграмме визуально определялось более чёткое разбиение на кластеры, но друг от друга кластеры не были изолированы.
В завершение эксперимента мы пытались визуально оценить и интерпретировать результаты разбиения с помощью случайной выборки из 9 фотографий для каждого кластера.



В результате мы увидели, что при увеличении количества кластеров модель старается разделить выборку одновременно по цвету автомобиля и ракурсу съёмки.

Также мы увидели, что модель не разделила транспортные средства на отдельные кластеры в зависимости от типа: седан/джип/грузовик/автобус. Можно предположить, что другие параметры кластеризации позволят улучшить качество такого разбиения.
Особый интерес представляет способность модели выделять нестандартные кластеры. К примеру, нам показалось, что в одном из экспериментов модель выделила в отдельный кластер объекты с бликами и пятнами:

Исследование набора данных efficientnet-b7
Следующим этапом исследования было исследование работы модели на дескрипторе Efficientnet-b7. Этот дескриптор был самым большим по размеру (416314, 2560), данная модель классификации изображений обучена на Imagenet и до этой работы данных из veriwild не видела.
Было решено уменьшить размерность модели, чтобы была возможность в разумные сроки сделать кластеризацию на доступных компьютерах. Для этого применён метод t-SNE, как показавший ранее большую точность итоговых сжатых данных.
Далее модель была стандартизирована и нормализована. Построенная после этого двухмерная визуализация, не разделённая на кластеры, выявила небольшие различия:
Затем кластеризовали данные на 2, 3, 4, 20 кластеров методом k-Means, как показавшим лучшие результаты на предыдущих моделях, описанных выше.
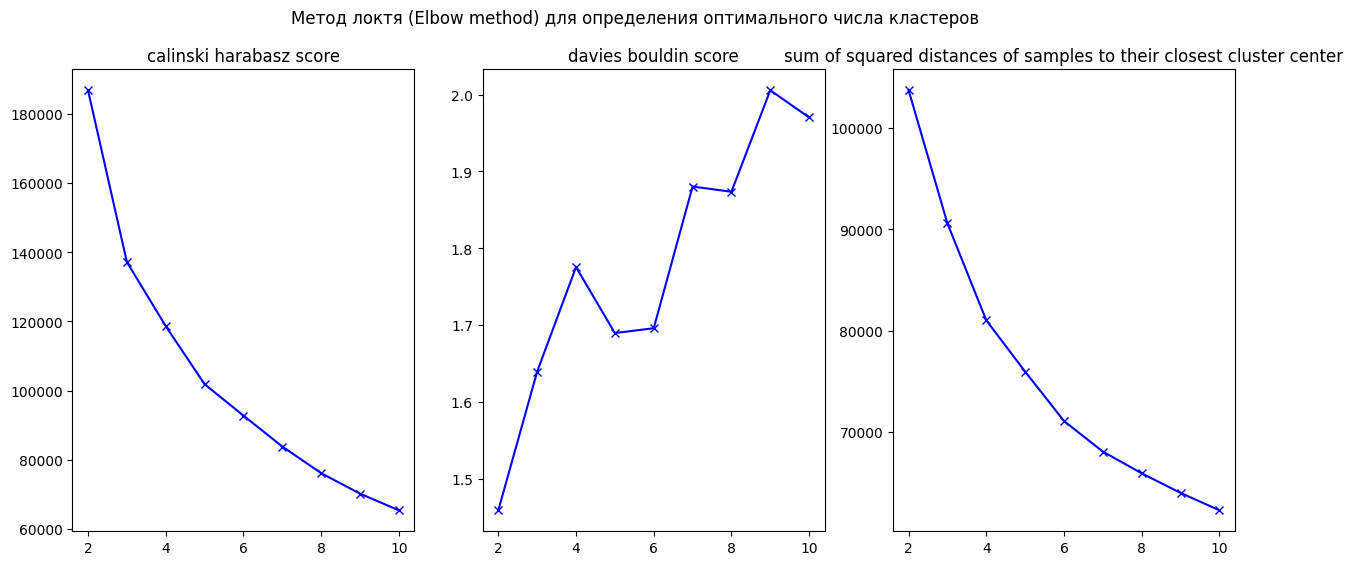
Аналогично описанию выше было определено исследуемое количество кластеров с помощью Elbow method clistering («метод локтя»):
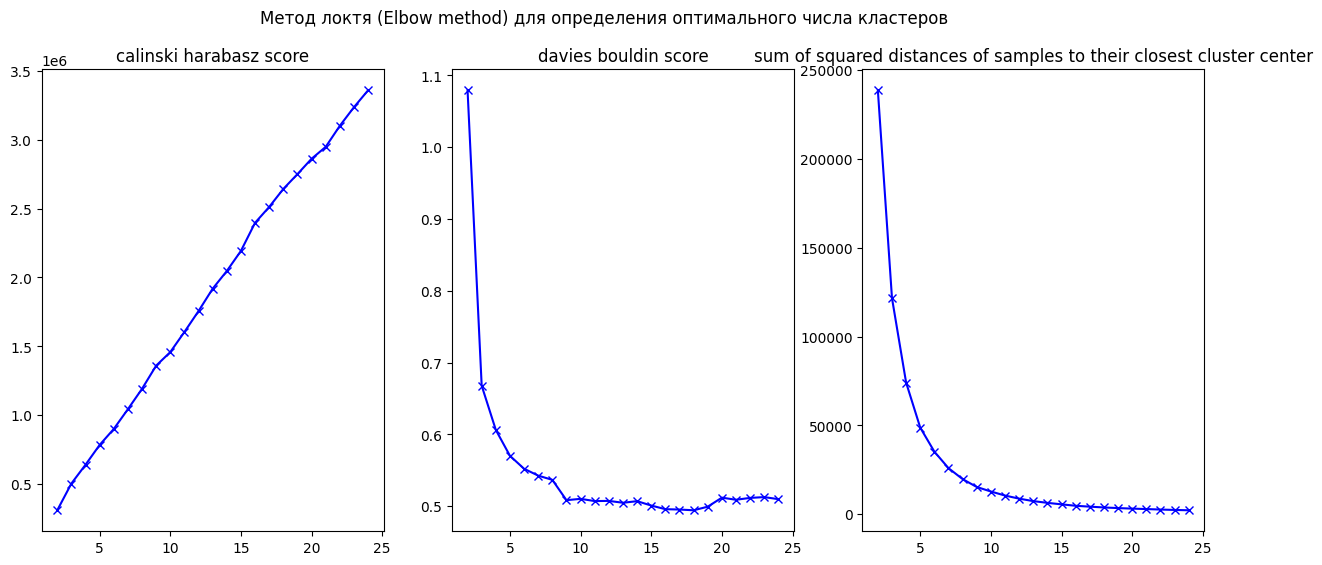
В силу схожей природы индекса Дэвиса — Болдуина (ДБ) и «метода локтя» в данном исследовании взят индекс ДБ с его «локтями» в точках 9 и 20. Для того чтобы компенсировать недостаток данного индекса, заключающийся во влиянии масштаба данных на значение индекса, применена нормализация данных перед исследованием (craftappmobile.com).
Визуализация для нормализованной модели:
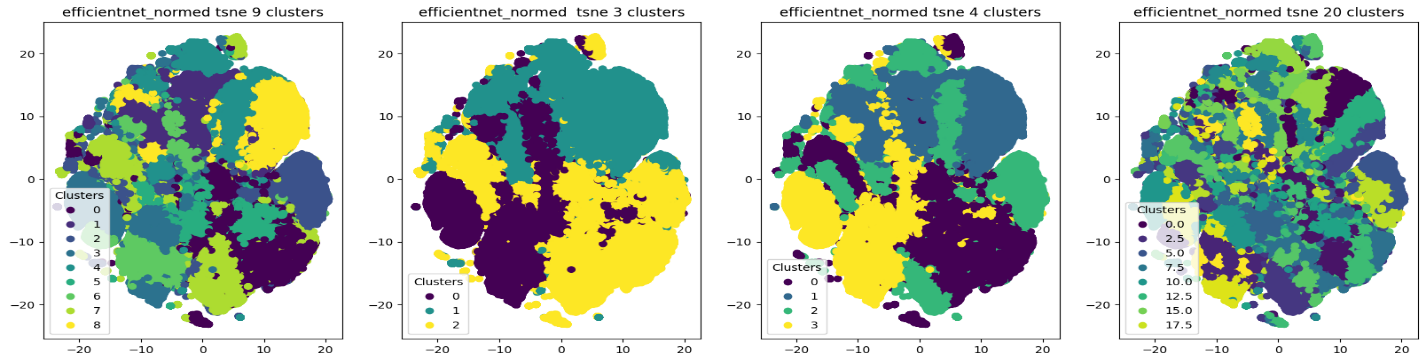
Результаты кластеризации (в виду большого числа картинок, все под спойлерами):
3 кластера



4 кластера — попытка разделить на светлые/тёмные — зад/перед




9 кластеров — попытка разделить на светлые/тёмные — зад/перед — ракурс — тип кузова — по цвету
 — много выбросов.")


 — много выбросов.")

.")



20 кластеров — разделение по цвету — зад/перед — ракурс — тип кузова




















Выводы:
-
Модель кластеризации с 20 кластерами, определёнными «методом локтя» с помощью индекса Дэвиса — Болдуина показала себя лучше, чем модели с меньшим количеством кластеров, и в целом достаточно информативно.
-
После кластеризации стало заметно, что стандартизированная модель кластеризует заметно с большим количеством ошибок, чем нормализованная.
-
Ошибок в кластере не более 33 % (3 из 9), но чаще 22 % (2 из 9), при этом всего кластеров с ошибками 40 % (8 из 20).
-
Следует отметить, что модель плохо различает данные (фотографии), когда фары и машина одного цвета: происходит больше ошибок.
-
Для упрощения работы с моделью можно применять методы уменьшения размерности, в частности, t_SNE показал лучший результат уменьшив размерность с (416314, 2560) до (416314, 2), что позволило использовать значительно меньшие мощности вычисления и получить вполне интерпретируемый результат.
-
Более подробного анализа выбросов в данном разделе не производилось.
Исследование набора данных type_model
Набор данных в виде csv файла, имеющего 416314 и 512 столбцов, был получен при помощи модели определения типа, и в целом работа с ним была аналогична работе с набором color.
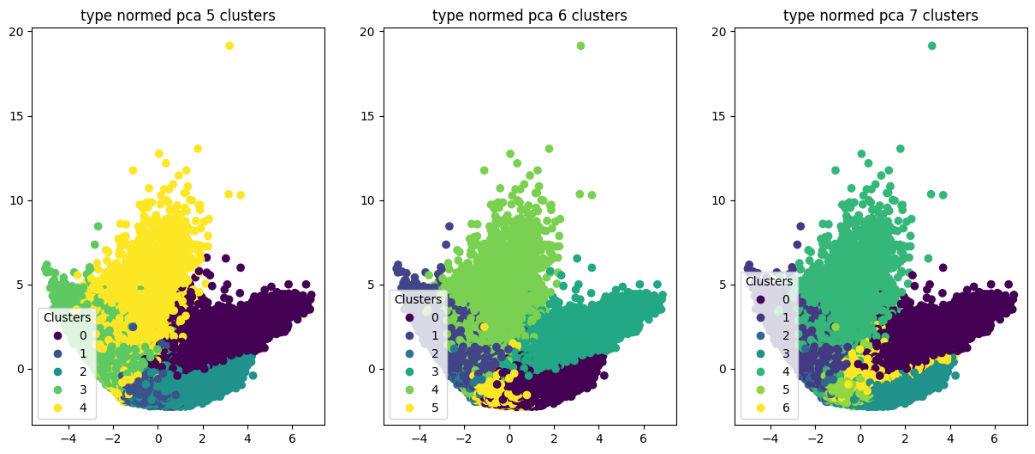
Кандидатами в лучшее число кластеров на основе «метода локтя» оказался случай с 6 кластерами. При этом расчёты и визуализации также осуществлялись для большего и меньшего числа кластеров
Кластеризация проводилась как на стандартных, так и на нормированных данных.
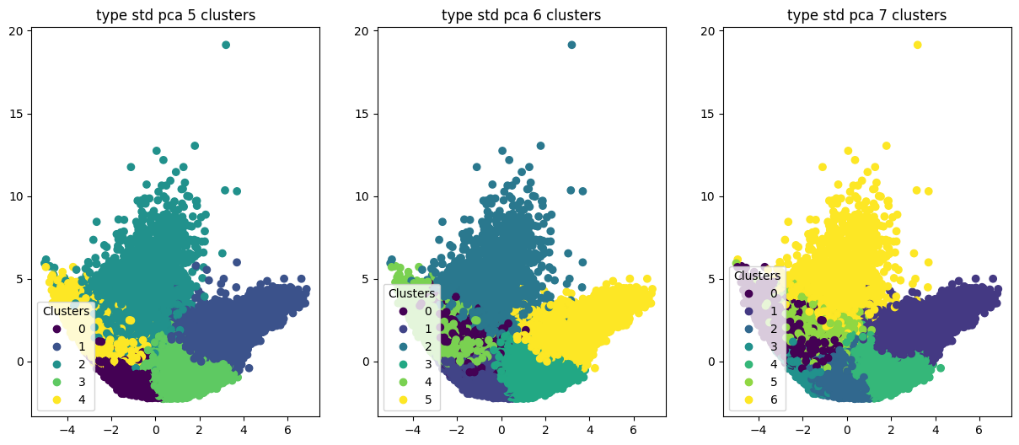
Как и в случае с набором данных color, результаты кластеризации на данных, размерность которых была понижена при помощи t-SNE, целом не дают чёткого деления на кластеры.
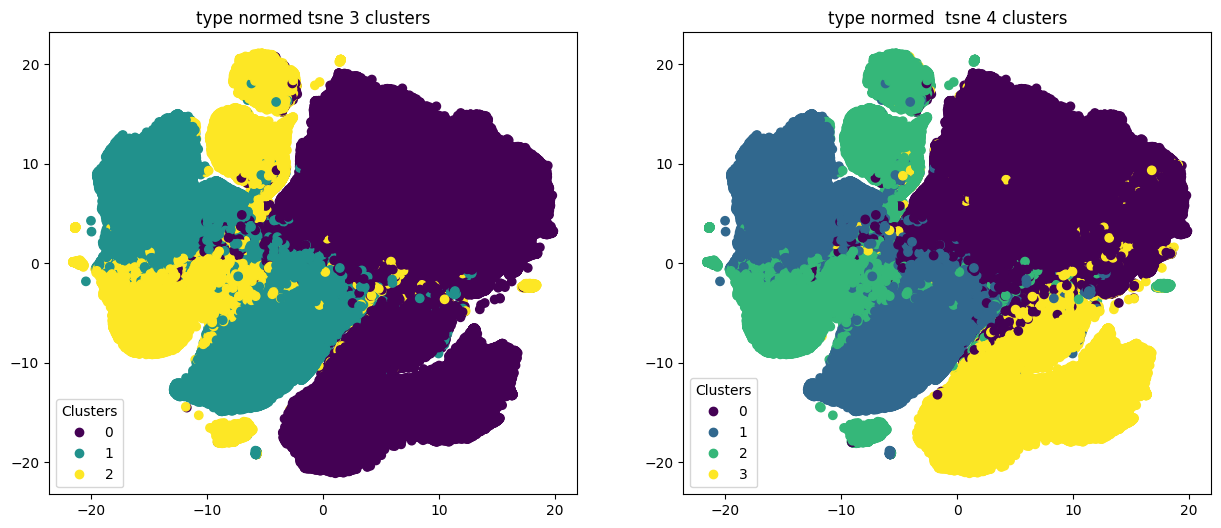
По итогам экспериментов мы визуализировали случайные картинки для каждого из результатов разбиения на 3–7 кластеров.
В случае с 3 кластерами, несмотря на относительно чёткое разделение, значимой кластеризации добиться не удалось. Нормированные данные дают некоторое разделение по размеру автомобилей.
Кластер 0 — седаны (небольшие авто),
Кластер 1 — кроссоверы (джипы),
Кластер 2 — микроавтобусы, автобусы (крупные авто).

В случае с 6 кластерами их условно можно идентифицировать следующим образом:
Кластер 0 — седаны (вид спереди).
Кластер 1 — джипы, хэтчбеки.
Кластер 2 — мини-вэны.
Кластер 3 — седаны (вид сзади).
Кластер 4 — грузовики.
Кластер 5 — хэтчбеки.

Ожидаемая кластеризация по типу кузова транспортного средства на основе подхода K-MEANS не была достаточно уверенной, однако подход для всех кластеров стабильно показывает кластеризацию по виду (спереди, сзади), например, седаны по виду спереди и сзади. Существует кластер для пикапов и мини-вэнов (кластеризация по размерам), хэтчбеки и джипы в остальных кластерах выделяются плохо. Автобусы появляются в 7 кластерах в группе с мини-вэнами с шумом от предыдущей кластеризации. Возможным решением является разделение отдельных кластеров на подкластеры.
Заключение
Несмотря на крайне сжатые сроки, поставленная задача была выполнена, и были получены интерпретируемые результаты, которые можно использовать в дальнейшей работе. У кого будут добавления — смело делитесь ими в комментариях. Прилагаем ссылку на репозиторий в GitHub, а итоговый файл с разметкой кластеров расположен в репозитории и доступен по ссылке.
Участники команды Cloud_9:
-
Екатерина Лушпина — Team Leader / презентация / коммуникация / статья;
-
Анастасия Сухоносенко — Product Manager / план исследования / код-фреймворк / презентация / статья;
-
Александр Кудрявцев — Speaker, Team Member / исследование / презентация / спикер / статья;
-
Наталья Авдеева — Team Member / исследование / презентация / статья;
-
Павел Озернов — Team Member / исследование / техническая поддержка / презентация / статья.
Мы хотели бы выразить благодарность кураторам, преподавателям и экспертам за организацию Хакатона. Это был отличный опыт и возможность проявить себя в решении практических задач, а также получить оценку от профессионалов в своей сфере.
Примечание редактора
Если в вашей компании есть кейcы по Data Science, которые вы бы хотели решить в рамках хакатона или стать ментором — пишите в личные сообщения skillfactory_school. Также мы будем рады индустриальным партнёрам для наших программ и можем предложить им разные виды сотрудничества: членство в наблюдательном совете, экспертиза для создания курсов, стажировки в ваших компаниях для студентов и другие виды партнёрства. Давайте развивать Data Science вместе!
Узнать больше про нашу магистратуру можно на сайте data.misis.ru и в Telegram-канале.
Ну, и, конечно, не магистратурой единой!.. Хотите узнать больше про Data Science, машинное и глубокое обучение — заглядывайте к нам на соответствующие курсы; будет непросто, но увлекательно.

Узнайте, как прокачаться в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
ссылка на оригинал статьи https://habr.com/ru/company/skillfactory/blog/549754/
Добавить комментарий