
Очень часто использование в разработке готовых инструментов становится неоптимальным решением. Так получилось и у нас. Для управления пайплайнами данных мы решили разработать собственную систему – Wombat. Рассказываем, что из этого получилось, и что нам дал отказ от использования готового решения.
Почему мы разрабатываем собственную систему
Делать собственную систему управления пайплайнами данных – выбор неочевидный. Сегодня есть множество готовых решений, которые могут решить проблему: Airflow, MLflow, Kubeflow, Luigi и куча других. Мы экспериментировали со многими подобными системами и пришли к выводу, что ни одна из них нас не устраивает.
Для примера рассмотрим самое распространенное решение – Airflow. Оно объединяет шесть основных блоков: API для описания пайплайнов, сборщик woкflow, панель управления и интерфейсы, планировщик задач и оркестратор задач и, наконец, мониторинг компонентов Airflow. Но для того, чтобы управлять пайплайнами, такой функциональности в нашем случае было недостаточно.
Для нас были критичными такие возможности, как интеграция системы управления пайплайнами с системой сборки и CI, интеграция с Kubernetes, возможность управления артефактами и валидации данных.

Мы посчитали, во что нам обойдется наращивание функциональности готовой системы до необходимого уровня и поняли, что гораздо проще и быстрее будет разработать собственную систему. Назвали мы ее Wombat, – потому что зверек очень милый, а во-вторых, потому что его считают спасителем австралийской природы. А для нас система, которая позволила бы объединить разработку и все стадии работы с данными была бы тоже настоящим спасением.
Какие проблемы мы решали
Исторически в нашей команде разработки поддержку сервисов в продакшене ведут инженеры DevOps. И привыкли они работать с пайпланами, которые описываются не кодом, а конфигами в форматах, подобных yaml. Из-за этого несоответствия приходится либо разделять поддержку, либо обучать инженеров работе с неклассической системой непрерывной интеграции.
Все это было бы излишней и ненужной работой, потому что пайплайны в форме ориентированных ацикличных графов прекрасно описываются в формате, который используется в стандартных инструментах CI и DevOps.

Вторая проблема, которая стояла перед нами – хранение и версионирование артефактов. Работа с артефактами в системе управления пайплайнами данных позволяет получить две очень полезных возможности: заново использовать результаты работы с пайплайнами и воспроизводить эксперименты с данными, экономя время на организацию новых опытов.
Если организация хранения артефактов не автоматизирована, то рано или поздно новые артефакты начнут перезаписывать старые или на рабочих машинах начнет заканчиваться свободное пространство. Кроме того, в продакшене потребуется применять особенные требования по обеспечению надежности и отказоустойчивости хранилища, а это – еще один затратный процесс.
Поэтому мы и хотели получить решение, которое выполняло бы все задачи, связанные с управлением пайплайнами в фоновом режиме, при этом позволяло бы дата-специалистам работать с артефактами других проектов, и при этом не задумываться о стоимости хранения данных.
Третья проблема – типизация потоков данных. Да, Python позволяет с высокой скоростью разрабатывать прототипы и проверять различные гипотезы. Но при работе с данными приходится уделять вниманию типам, с которыми ты работаешь, если не хочешь неожиданных сюрпризов. Чтобы сократить количество таких проблем в продакшене, нам необходима поддержка описания схем данных, вплоть до описания схем дата-фреймов, причем типизация данных должна вестись отдельно для разработки и для продакшена.
Что получилось в итоге
Условно архитектуру Wombat можно представить вот так:

Эта схема отображает роль системы. Она – промежуточный слой между описанием пайплайнов и CI-системой, при помощи которой реализуется работа с ними в продакшене.
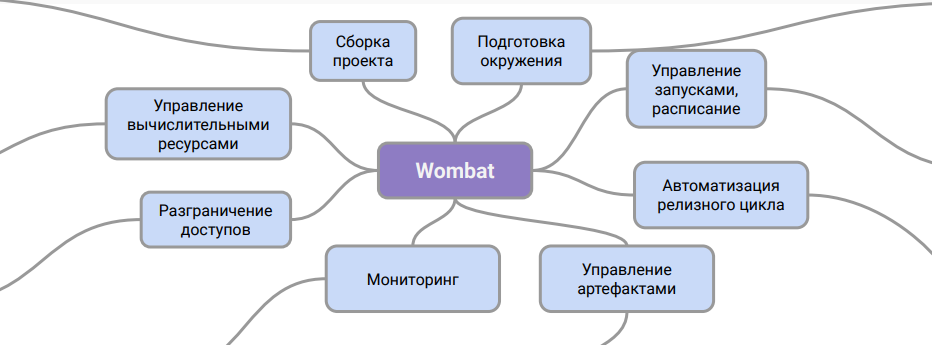
Благодаря такой схеме работы мы можем организовать поддержку пайплайнов в отделе DevOps без дополнительного обучения инженеров и без привлечения к этому процессу специалистов по работе с данными. Кроме того, решается проблема с хранением артефактов данных и их версионированием.
Сейчас мы занимаемся разработкой функциональности, которая позволит внедрить инструмент в ранний этап прототипирования и экспериментов в нативной для дата-саентистов форме, что позволит существенно ускорить вывод проектов в пилот и продакшн.
Мы готовимся выложить данный инструмент в open source в самое ближайшее время. Будем рады, если поделились своим мнением о нашем проекте и своим опытом работы с современными системами пайплайнов данных.
Также, понимая, что данная статья носит скорее информационный, нежели технический характер, в ближайшее время планируем подготовить более детальный, хардкорный текст. Пишите в комментариях, что бы вам в техническом плане хотелось там увидеть и узнать. Учтем, опишем и напишем. Спасибо за внимание!
P.S. Мы, по-прежнему, заинтересованы в талантливых программистах. Приходите, будет интересно!
ссылка на оригинал статьи https://habr.com/ru/company/mvideo/blog/552478/
Добавить комментарий