Рано или поздно аналитик сталкивается с проблемой организации данных. Их становится все больше, структура перестает быть прозрачной, а одни и те же SQL-запросы приходится переписывать по несколько раз. Решить эту проблему можно с помощью dbt – инструмента, который открывает новый подход к трансформации и моделированию данных. Под катом – перевод отличной статьи Дэвида Кревитта о том, что такое dbt, и как этот инструмент помогает аналитикам облегчить свою работу.
dbt (data build tool) — это фреймворк с открытым исходным кодом для выполнения, тестирования и документирования SQL-запросов, который позволяет привнести элемент программной инженерии в процесс анализа данных.
Это прекрасный образец в наборе «ленивых» инструментов, который помогает никогда не повторяться при анализе данных.
Замена сохраненного запроса
Каждый SQL-запрос заслуживает хорошего «дома». В dbt SQL-запросы структурированы и разложены по папкам проекта, поэтому все члены команды всегда знают, где их найти:

Каждый раз, когда нужно запустить запросы, вы используете команду dbt run.
Эта команда берет коллекцию SQL моделей в проекте dbt и обновляет их в хранилище данных.
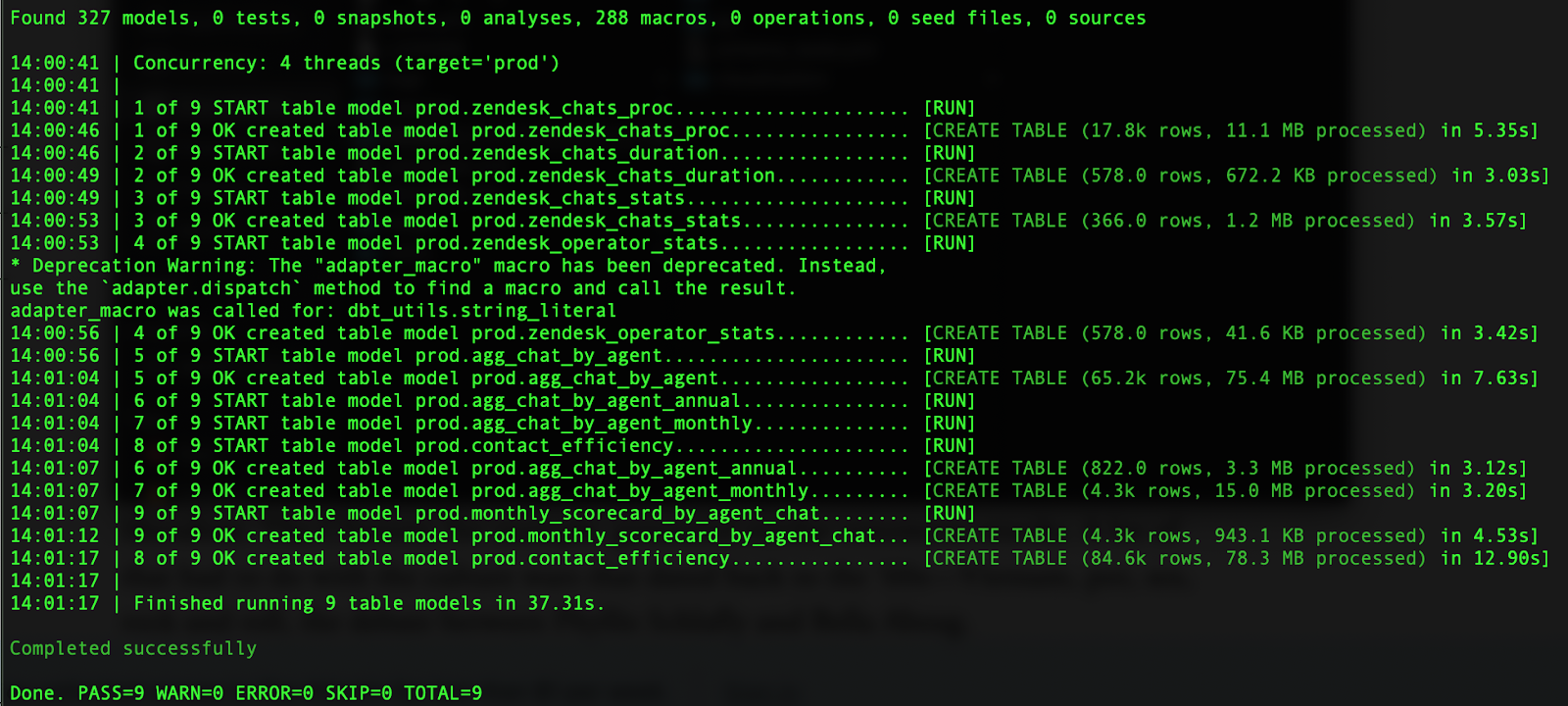
Просто, но эффективно.
Это значит, что больше не нужно сохранять фрагменты SQL-запросов на рабочем столе или где-нибудь еще, как сундук с сокровищами.
Рассредоточение и дезорганизация работы — вот что убивает проекты анализа данных. Из-за этого вам сложно вспомнить, как удалось прийти к решению в первый раз и приходится решать задачу повторно.
dbt дает вашей аналитической работе постоянный дом и формальную структуру — дисциплину, если хотите.
ref(‘ ‘) изменит вашу жизнь
dbt позволяет ссылаться на *другие запросы* в SQL-запросах, вызывая их через {{ ref(‘model name’) }}.
Это помогает сократить количество запросов:

Таким образом, каждый запрос выполняет отдельную задачу. Мы строим структуры проекта dbt как слоеный пирог, состоящий из множества взаимозависимых слоев, каждый из которых выполняет свою работу:

-
/admin модели хранят настройки нашего конвейера данных
-
/base модели для дедупликации и очистки сырых данных
-
/join модели для объединения нескольких/базовых таблиц
-
/math модели считают метрики (отток, удержание) и используются в любой сложной математике (прогнозирование и т. д.)
-
/visualization модели уточняют имена столбцов + получают данные в формате, готовом к презентации.
Это упрощает ответы на вопросы о том, как рассчитываются метрики.
«Как мы очищаем данные Google Analytics?»
Загляните в папку base -> google-analytics.
«Как мы рассчитываем коэффициент удержания когорт?»
Папка Math -> cohort-analysis.
Это упрощает навигацию по SQL-запросам. dbt — противоядие от Monster Queries™, которые может понять и объяснить только их автор.
SQL который пишет себя сам
dbt выводит написание SQL-запросов на новый уровень двумя способами: макросы + шаблоны JINJA.
Макросы
Создание SQL-запросов обычно предполагает много рутины.
Например, когда нужно повторить оператор CASE 15 раз для разных условий:
CASE WHEN x = y THEN z
WHEN 2x = 2y THEN 2z
Бла-бла-бла… Это может привести к синдрому запястного канала.
Еще один классический случай — объединение двух таблиц, при котором вам традиционно приходилось повторять поля каждой таблицы:

Благодаря dbt фрагменты SQL можно повторять с помощью макросов.
Команда dbt даже предлагает удобный список ключевых макросов в модуле dbt_utils, чтобы облегчить рутинную работу аналитиков.
Несколько макросов, которые команда CIFL использует каждый день:
Шаблоны JINJA
Программирование дает нам ключевые механизмы, позволяющие не повторяться: циклы FOR, операторы IF-THEN и т. д.
dbt значительно упрощает встраивание этой программной логики в ваши SQL-запросы, позволяя писать запросы в нотации JINJA.
Это означает, что вместо жесткого кодирования SQL-запросов вы можете создавать запросы, которые пишут себя сами.
Например, часто при создании конвейера обработки данных мы сохраняем список целей Google Analytics для клиентов агентства:
-
Клиент 1 использует цели №2 и №9.
-
Клиент 2 использует цели №4 и №11.
Задача заключается в том, чтобы создать один столбец «Достигнутые цели» для каждого клиента в рамках одного запроса.
До dbt мы писали эти запросы вручную:

С помощью dbt мы генерируем запрос динамически, используя шаблон JINJA:

Таким образом, вместо того, чтобы вручную обновлять запрос каждый раз при изменении числа переходов к цели клиента, мы просто записываем новое значение в таблицу, и запрос пишется сам. Истинная находка для «ленивого» аналитика.
dbt + Git
С dbt + Git вы можете анализировать данные как команда разработчиков программного обеспечения. Это означает проверку кода с помощью раздела «Pull Requests» и отслеживание ошибок с помощью «Issues». Больше не нужно редактировать SQL-запросы через длинные цепочки в Slack/Notion/email.

Это имеет несколько полезных эффектов:
-
Люди более серьезно относятся к SQL-запросам и дают им пространство и время, необходимое для разработки. Спешка и перерывы — два врага хорошей работы с данными.
-
Запросы пишутся один раз, а затем становятся доступны для использования другими членами команды. При правильном использовании это означает, что вы никогда не будете писать один и тот же запрос дважды.
-
Вы пишете SQL более высокого качества, потому что он будет повторно использоваться другими людьми.
Запуск SQL-запросов по расписанию
«Когда последний раз обновлялись эти данные?» – этот вопрос аналитики слышат постоянно.
С dbt ответ никогда не вызывает сомнений.
Fishtown Analytics (команда, стоящая за dbt) предлагает dbt Cloud, hosted платформу для запуска проектов dbt по расписанию.

dbt Cloud представляет из себя простой интерфейс для просмотра статуса выполнения различных моделей, результатов тестирования и программно созданной документации.
Регистрация для первого пользователя бесплатна, для каждого следующего — $50 в месяц.
«Ленивое» документирование данных
«Как рассчитывалась эта метрика?»
«Из какой таблицы с сырыми данными взято это поле?»
На эти вопросы никогда не нужно отвечать больше одного раза — вот почему существует документация. Но у документирования есть две ключевые проблемы:
Актуальность
Если вам приходится обновлять документацию вручную, она никогда не остается актуальной.
Любой, кто скажет вам, что его документация, написанная вручную, на 100% свежая, вероятно, также готов продать вам остров на Мальдивах.
Расположение
Документация обычно хранится не там, где вы используете свои данные — невозможно написать документацию без документа, но мы, как правило, не анализируем данные в документах.
Документация нужна нам там, где мы используем данные: например, в Google BigQuery или Google Data Studio.
dbt решает обе эти проблемы:
-
Команда `dbt docs` программно генерирует визуальный граф зависимостей из вашего набора моделей, что позволяет просматривать зависимости SQL модели на одной странице.
-
dbt позволяет добавлять описания на уровне таблицы + столбца из одного файла .yml в вашем проекте.
Эти описания передаются как непосредственно в консоль BigQuery:
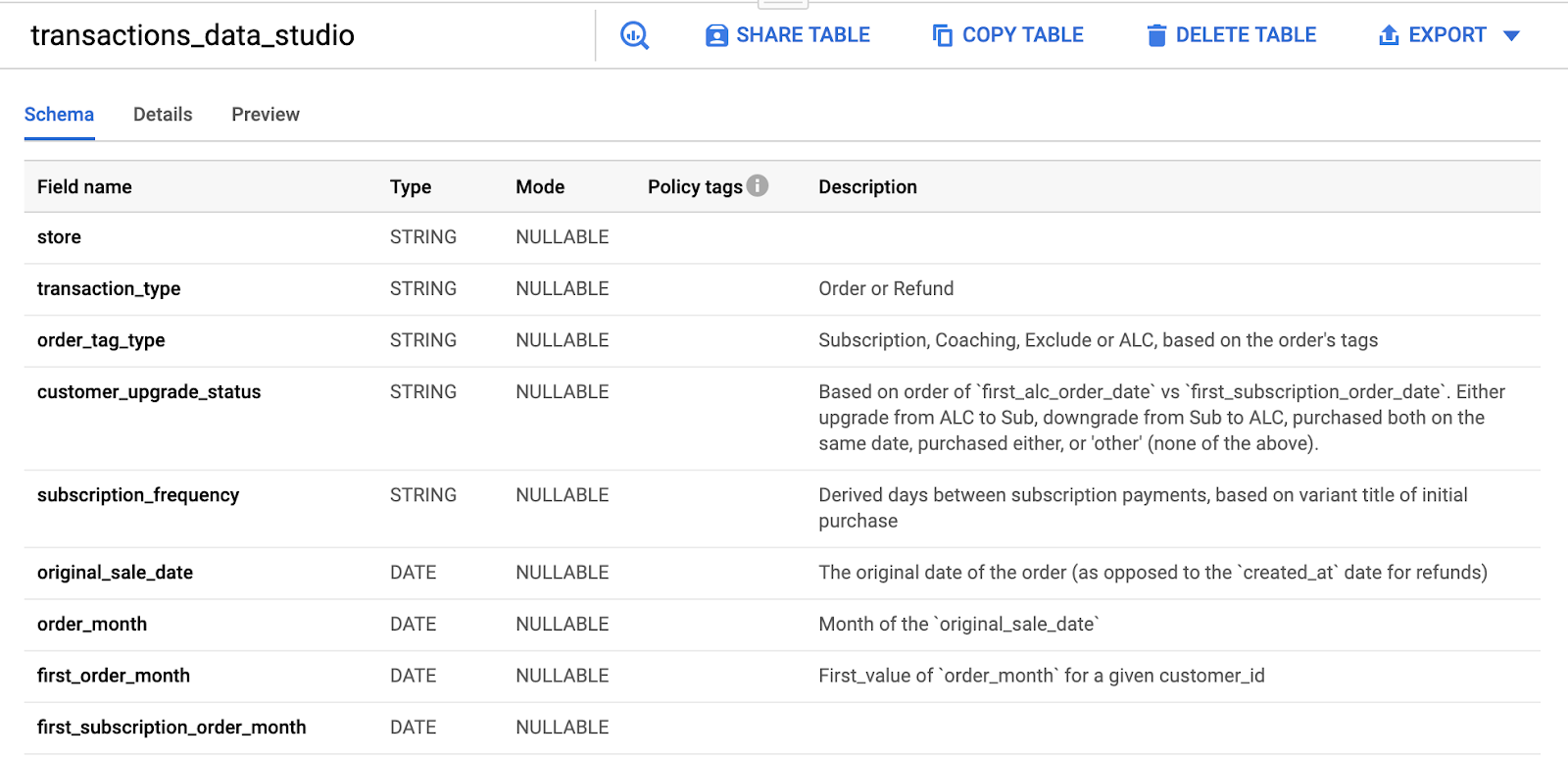
Так и в Data Studio:

Другие хранилища данных (Snowflake и т. д.) или инструменты визуализации данных (Looker и т. д.) получают описания этих таблиц и столбцов аналогичным образом. То есть вы можете написать определения полей один раз и запускать их, где угодно.
Как давно вы проходили тестирование?
Когда работа аналитика выполнена безупречно, она невидима для людей, которым помогает принимать решения. А тестирование помогает работе аналитика оставаться незаметной, позволяя избежать проблем с качеством данных, которые могут подорвать доверие к ней.
dbt прекрасно справляется с этой задачей благодаря автоматизированной схеме и тестированию данных.
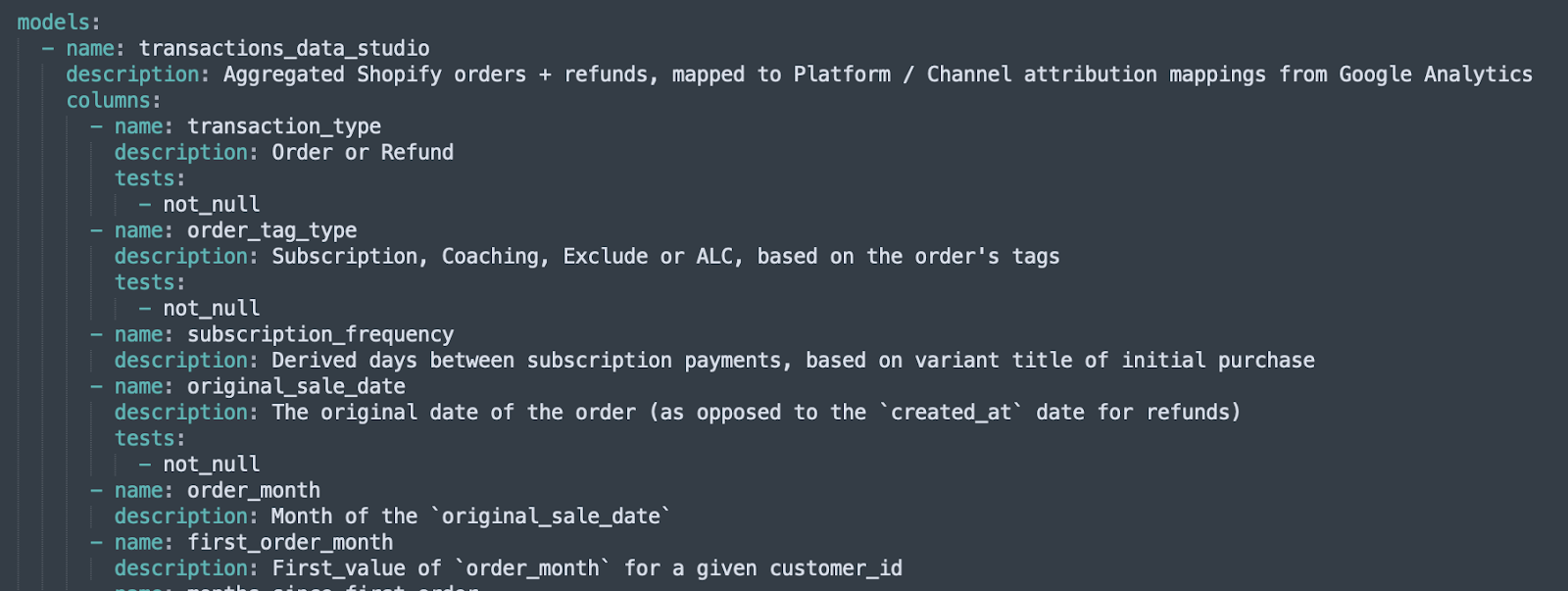
Если столбец никогда не должен быть нулевым, но каким-то образом был обнулен, тесты dbt отметят это за вас. Если ваш JOIN слишком щедрый и приводит к дублированию строк, тесты dbt отметят это за вас.
В принципе, вы можете написать любой SQL-запрос в качестве теста, и dbt выдаст вам предупреждение или ошибку.
Переход на другое хранилище данных
Любое хранилище данных — BigQuery, Snowflake или обычная PostgreSQL — имеет свой собственный, немного отличающийся синтаксис SQL. Если вы переходите с BigQuery на Snowflake или с Redshift на BigQuery, вам придется переписывать запросы SQL, чтобы учесть эти нюансы.
Но dbt позаботился об этой проблеме! Он содержит адаптеры для всех распространенных платформ хранения данных. Вы можете переносить свои модели dbt для работы в другом хранилище данных с минимальными модификациями. А поскольку dbt имеет открытый исходный код, вы можете добавлять свои собственные адаптеры (как это сделали, например, для MS SQL).
Нам в CIFL это существенно облегчило жизнь, поскольку мы можем работать с хранилищами данных, которые предпочитают наши клиенты, без серьезных изменений в рабочих процессах.
Как начать работу с dbt
Если вы готовы заняться внедрением dbt в своей команде, в этом могут помочь:
-
Бесплатный курс «Начало работы с BigQuery SQL», который включает введение в моделирование данных с помощью dbt.
-
Недавно запущенный курс «Постройте свое агентство данных» для более глубокого погружения в процесс анализа данных на основе dbt.
ссылка на оригинал статьи https://habr.com/ru/post/552542/
Добавить комментарий