В какой-то момент у нас стало много хотфиксов — стабильно больше половины деплоев на проде были хотфиксы или откаты. Мы решили анализировать каждый хотфикс, чтобы понять причины, найти системные закономерности и устранить их, не допуская два раза одних и тех же ошибок. Как говорил Джейсон Стейтем (Стэтхэм? Стэтэм?): «Не страшно ошибаться, страшно повторять одну ошибку 2 раза». Ну и мы решили не повторяться. В статье расскажу как мы анализируем хотфиксы и другие критичные проблемы, что у нас получается, а что нет, с какими сложностями столкнулись и как их решали.
Как было раньше
Раньше на проде случались хотфиксы-откаты из-за критичных багов. Мы в QA понимали что нам нужно проводить какую-то ретроспективу по пропущенным багам на прод. Поэтому после каких-то очень проблемных релизов:
-
собирались и обсуждали проблему;
-
звали разработчиков, участвующих в этом релизе;
-
принимали решения (некоторые работают до сих пор).
Основная проблема при таком подходе, что ты не разбираешь каждый хотфикс или откат детально. Ты обращаешь внимание только на очень критичные проблемы. Такая активность не системная.
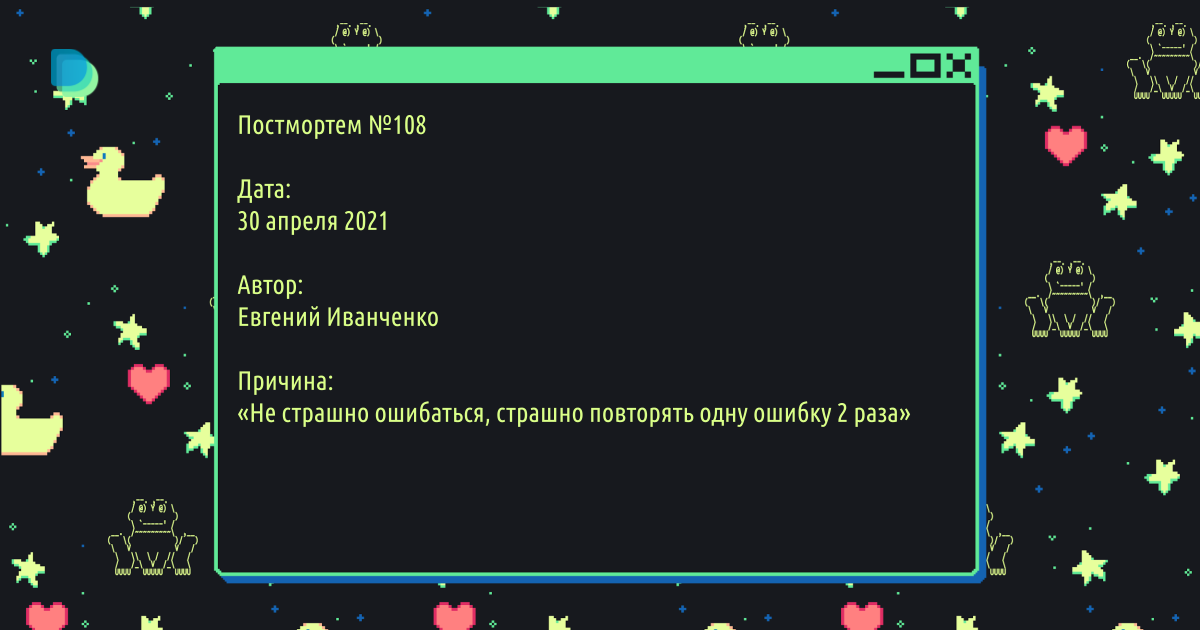
Когда хотфиксов стало много (примерно половина всех выкладок на прод были хотфиксы) поняли, что этого недостаточно — нужно что-то менять. Мы решили попробовать практику написания постмортемов на хотфиксы и откаты.
Что такое постмортем?
Вообще, постмортем — это посмертная фотография родственников.

Мы узнали об этой практике у нашей команды Платформы. Они уже с 2018 года ведут постмортемы по всем инцидентам в системе.

Наши люди даже выступали с этими темами на конференциях.
В этом подходе детально разбирается каждый инцидент, вырабатываются экшен айтемы (action items) для устранения и недопущения проблем. Мне этот инструмент показался черезвычайно полезным и мы решили попробовать адаптировать его под наши нужды.
Как начали вести
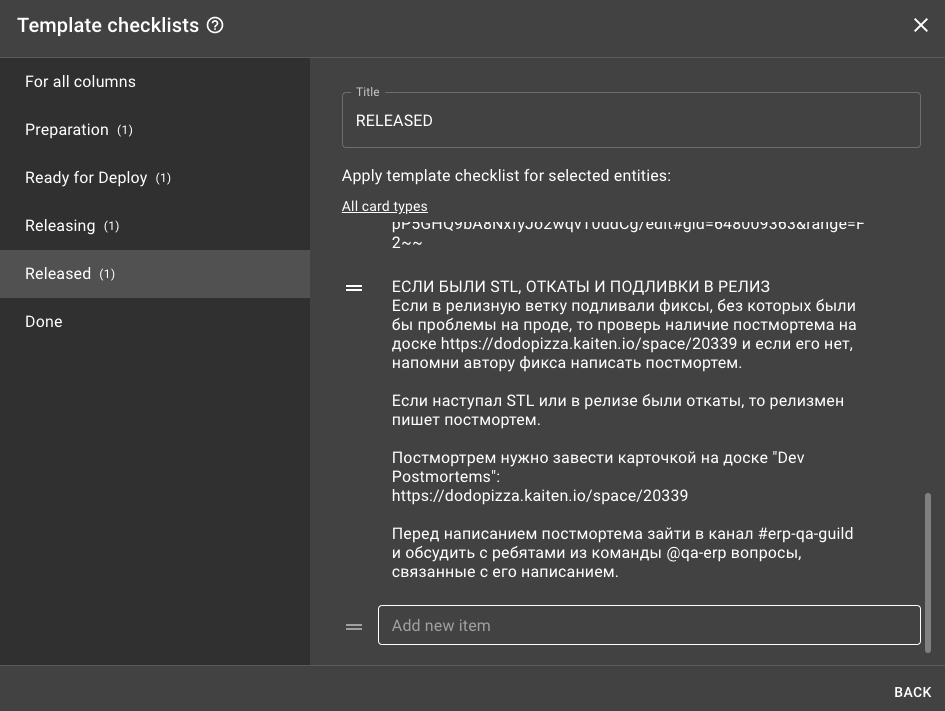
Мы почитали о практике ведения постмортемов, чтобы не допустить критичных ошибок при их написании. Пошли в репозиторий с постмортемами от команды Платформы, почитали их постмортемы и на основании их шаблона сделали свой (шаблон будет в конце статьи).
Вначале мы вели постмортемы в Nuclino. Но в нём сложно трекать статус каждого постмортема, выполняемость решений и т.д. и т.п. А вот в Kaiten наглядно видно текущий статус постмортема, какие из них без решений, можно строить какие-то отчеты. Поэтому наши постмортемы логично переехали туда.

Чуть поработали и поняли, что у нас есть несколько типов критичных проблем и под каждый из типов создали свой шаблон: некоторые вопросы были актуальны для одного типа, но неактуальны для другого. В итоге получилось 4 типа постмортемов:
-
По хотфиксам на проде.
-
По откатам релизов.
-
По «подливкам» в релиз — когда в релизную ветку подливают фиксы. Иногда на этапе прогона тестов находятся критичные баги. Если бы они попали на прод был бы хотфикс, иначе их бы пофиксили стандартным флоу в следующем релизе.
-
По STL (Stop the Line). Подробнее что это такое можно почитать в статье «Stop the line или прокачай свой pipeline, йоу»

Структура и способ ведения
В этом разделе расскажу о структуре шаблона на примере постмортема для хотфиксов. Возьмем один из недавних постмортемов, когда мы делали хотфикс.
Пишем дату хотфикса. Не всегда карточки создаются в тот же день, что и постмортем, поэтому решили проставлять дату случившегося события. Трекинг длительности исправления задач делает Kaiten и выдает нам в отчете. Кроме этого по дате инцидента можно сделать более глубокий анализ, посмотреть частотность по темам, выявить закономерности.

Авторы постмортема. Знаем к кому идти за подробностями инцидента или с уточняющими вопросами по решению. Наличие авторов постмортема не противоречит принципу написания постмортемов «blameless culture». Мы не обвиняем никого в доведении до проблемы, а хотим лишь отобразить участников разбора.

Причины. В этом блоке описываем причину которая привела к хотфиксу, что с технической точки зрения произошло. Стараемся выяснить корневые причины случившегося.

Проблемы. Пишем о том, с какими проблемами могли столкнуться наши пользователи. Какую функциональность мы задели, какие непотребства видели наши пользователи. Или что видели мы, если мы заметили проблему раньше пользователей (алерты, подскочившие графики в Grafana).

Потери. В этом блоке пишем влияние на бизнес, сколько задето пиццерий или пользователей, сколько потеряли в деньгах или во времени (это импакт на пользователей).

Что делать, чтобы ситуация не повторилась. В этом блоке пишем, что можно сделать чтобы не допустить эту проблему в будущем — решения, которые позволят на ранних стадиях заметить проблему или вообще устранить.

Разное. Это поле добавили как свободный ответ в анкетах, вдруг какая-то важная мысль не уложится в заданный нами шаблон. Иногда его заполняют, иногда нет.

Шаблон
Здесь оставлю пример шаблона наших постмортемов без моих комментариев.
## Дата
## Автор
## Проблемы
## Причина
## Последствия для бизнеса
## Предложения по недопущению в будущем
## Как можно было избежать проблемы (представь что у тебя есть машина времени и ты вернулся к моменту, когда ты еще не написал этот код, что можно было сделать, чтобы не было хотфикса)
**Создать картохи на написание _автотеста_ по этой проблеме в своем бэклоге и прикрепи их сюда как дочерние**
**Создать картохи по _недопущению хотфикса_ в будущем в своем бэклоге или бэклоге владельцев компонента и прикрепи их сюда как дочерние**
## Что ещё хочется добавить
**Не забудь поставить теги компонента в котором случилась проблема**
Берите себе, адаптируйте и пользуйтесь.
Сложности и как их решали
С «нахрапа» не получилось ввести постмортемы и вести их идеально. Вот наш список проблем.
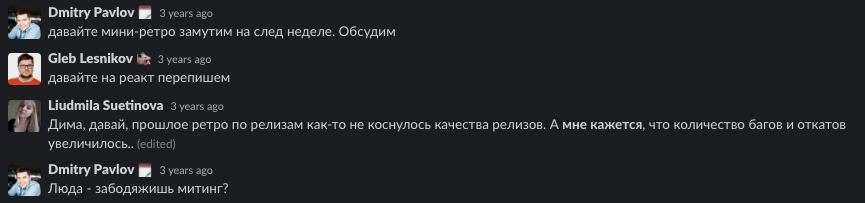
Не заполняли постмортемы. Банально — да: поначалу люди ответственные за релиз забывали заполнять постмортемы…
Решили проблему добавив в чек-лист «релизмена» пункт о необходимости заполнения постмортема. «Релизмен» — разработчик отвечающий за выкатку релиза, ротируется после каждого релиза.
И проблема решилась. Остались единичные случаи, когда постмортем не заполняется. В таком случае в ручном режиме «тыкаем» ответственного и просим его заполнить. Владелец и хранитель процесса — QA-гильдия.
Не предлагали решений или предлагали слабые решения. Сейчас основная проблема в том, что почти в половине постмортемов нет решений или они очень общие типа «распилить монолит», «тестировать перед мержом в дев», «писать код без багов, а с багами не писать».



Проблему решили припиской в чек-листе, что когда QA пишет постмортем, он должен позвать другого QA. Мы прямо в процессе написания постмортема можем дать обратную связь о слабом решении или вообще о его отсутствии. Либо после написания постмортема нам отправляют его на ревью и мы так же даем обратную связь только уже асинхронно.

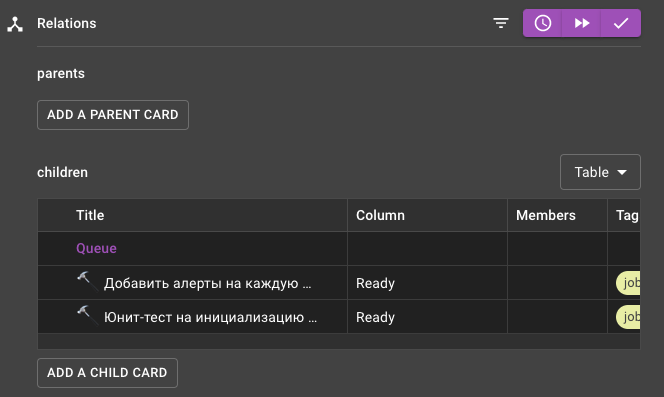
Не создавали карточки на решение проблем. Мы используем Kaiten и настроили доски так:
-
прикреплённая дочерняя карточка с устранением проблемы берется в работу;
-
постмортем автоматически переезжает в «In progress»;
-
когда задачу завершают — завершается и постмортем.
Это помогает не мониторить исполнение постмортемов.
Поначалу карточки не создавались, а даже если создавались, то не прикреплялись как дочерние и постмортемы не двигались. Решили тоже просто добавив в шаблон пометку о том, что нужно создать карточку и прикрепить её как дочернюю.
Решения долго берут в работу. Мы все понимаем, что бэклогом владеет продакт и у него есть приоритеты. Мы понимаем, что когда команда берёт техзадачи в спринт, это зависит от множества факторов: понимания продактом важности этих технических задач и последствий (если их не решить), от зрелости самой команды, критичности сервиса и проблемы. Но проблема всё равно болезненная.
Мы провели небольшую аналитику по среднему времени ожидания постмортема до момента когда над ним начали работу. Получилось, что медианное время ожидания постмортема до взятия в работу меньше месяца — 21 календарный день. По результатам навесили на колонку напоминание: когда карточка висит в ToDo дольше, она начинает привлекать к себе внимание.
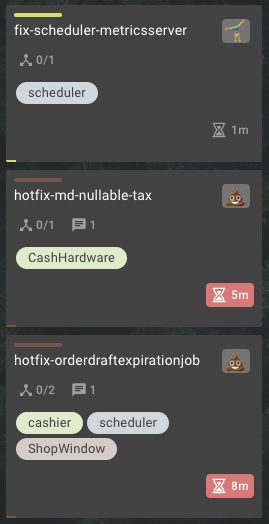
Когда появляется сигнал мы идем к команде, которая должна решить эту проблему и спрашиваем о судьбе этой карточки. Иногда они становятся неактуальными, это тоже нормально.
Случаются повторные ошибки. У нас была ситуация, когда невыполненное решение одного из постмортемов привело к другому постмортему. Одним из решений когда-то было написать и прогонять нагрузочные тесты на роль Менеджер смены. Команда нагрузочного тестирования не успела взять её в работу и мы словили критичный баг на проде, который можно было бы обнаружить на нагрузочных тестах.
Результаты в цифрах
Мы проанализировали постмортемы за пол года, и вот какая картина получается.
-
Треть наших постмортемов не имеют конкретных решений на доработку и недопущение проблем в будущем.
-
Половина наших постмортемов в которых есть конкретные решения ещё не выполнена.
-
49 дней — медианное время жизни постмортема от появления на доске до выполнения (из тех что выполнили и в которых были решения), а среднее — 82 дня. Такие различия обусловлены большим разбросом значений. Критичные решения или очень простые решаются достаточно быстро, сложные и не критичные могут долго провисеть в ожидании.
Ситуация не радужная, но благодаря ведению этих постмортемов мы знаем о проблеме и можем предпринимать действия по её улучшению.
Выводы
Наше следующее направление по работе с постмортемами после обсуждения на гильдии — сфокусироваться на том, чтобы повысить процент постмортемов, в которых было какое-либо решение.
Мы решили сконцентрироваться на постмортемах без экшен айтемов. Моя первая мысль была: «Не лучше ли фокусироваться на выполнении постмортемов?». Однако, после некоторого обсуждения на комьюнити, мы пришли к выводу, что если пишется постмортем — то должен быть экшен айтем, иначе это «бесполезная работа». Поэтому мы решили увеличить этот процент, а после его увеличения взяться за повышение исполняемости этих постмортемов.
Ведение постмортемов по критичным функциональным багам на проде мне кажется полезной практикой. Мы явно проговариваем и анализируем каждую проблему, которую не хотим больше повторять. Мы получаем конкретные решения каждой проблемы. И в целом наша система становится лучше и меньше подвержена ошибкам.
Что ещё почитать.
— «Stop the line или прокачай свой pipeline, йоу»
— «Будущее интерактивного дизайна в руках»
— «История Open Source кратко: от калькулятора до миллиардных сделок»
— «Как выйти на китайский рынок с mini-app для WeChat, чтобы не прогореть»
— «Как мы «разогнали» команду QA, и что из этого получилось»
— «История архитектуры Dodo IS: ранний монолит»
Подписывайтесь на чат Dodo Engineering, если хотите обсудить эту и другие наши статьи и подходы, а также на канал Dodo Engineering, где мы постим всё, что с нами интересного происходит. А ещё есть группа в ВК (ну мало ли).
ссылка на оригинал статьи https://habr.com/ru/company/dododev/blog/554612/
Добавить комментарий