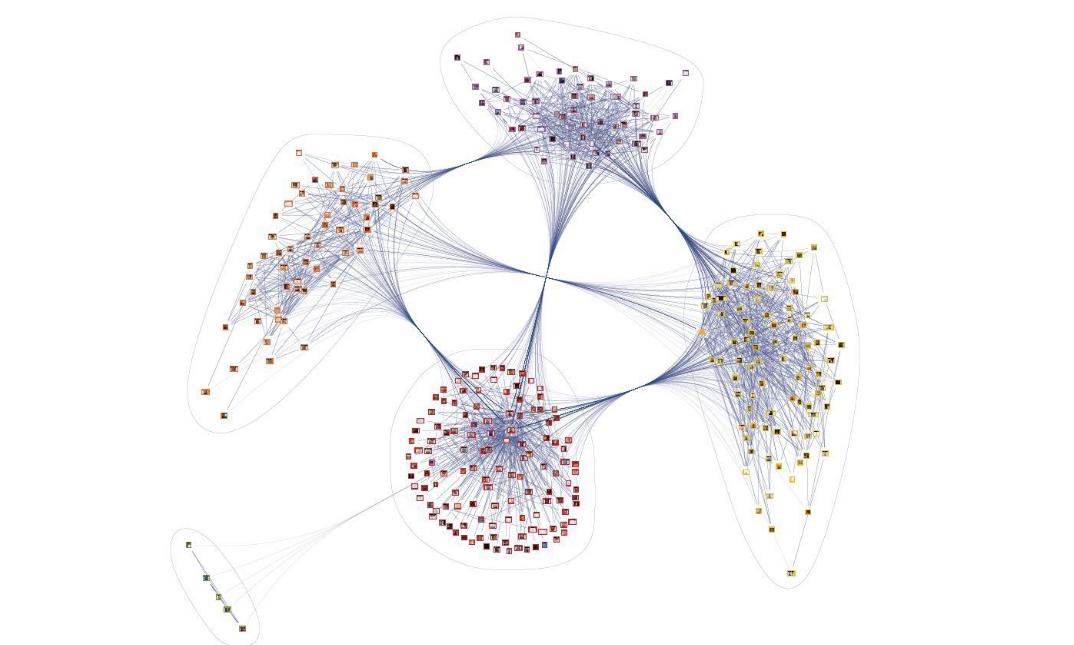
Сегодня на простом примере рассмотрим – как провести краткий обзор неструктурированных данных в виде графа знаний.
Для примера возьмем набор текстов из обращений с портала mos.ru. В данном случае, набор состоит из 90 тыс. обращений. Медианная длина обращений составляет 9 слов. В целом, тексты можно разбить на три основные темы: качество окружающей среды; качество городской среды; доля дорожной среды, соответствующей нормативам.
Для начала импортируем необходимые библиотеки:
import pandas as pd from tqdm import tqdm import stanza from nltk.tokenize import word_tokenize, sent_tokenizeБиблиотека Stanza позволяет работать над NLP задачами, такими как определение части речи, лемматизация, поиск именованных сущностей, а также определение синтаксической зависимости между словами в предложении. Библиотеку nltk используем для разбивки текстов на отдельные предложения. Stanza сама разбивает текст на предложения, а затем на отдельные слова, но для уменьшения времени обработки лучше предобработать текст.
Загрузим данные, для примера выберем отдельную категорию:
df = pd.read_excel('fill_info.xlsx') df_ml = df[df["CATEGORY"]=="Machine Learning"]Разобьём тексты на предложения и удалим короткие предложения:
full_corpus = df_ml["TEXT"].values sentences = [sent for corp in full_corpus for sent in sent_tokenize(corp, language="russian")] long_sents = [i for i in sentences if len(i) > 30]Инициализируем различные препроцессоры stanza с помощью метода Pipeline:
nlp = stanza.Pipeline(lang='ru', processors='tokenize,pos,lemma,ner,depparse')В данном случае, мы указали 5 препроцессоров, т.к. для определения синтаксической зависимости («depparse») обязательны 4 («tokenize, pos, lemma, ner») препроцессора. Однако, если необходимо определить только именованные сущности, то можно использовать только 2 препроцессора («tokenize, ner»), что увеличит скорость обработки данных. Стоит учесть, что использование Stanza – вычислительно-затратный процесс, на обработку 90 тыс. обращений может уйти много времени. Однако, Stanza позволяет обрабатывать данные на видеокартах с поддержкой CUDA. В моем случае, обработка 3000 предложений на CPU заняло 26 минут, в то время на видеокарте тот же объем обработан за 3 минуты. Для запуска вычислений на GPU необходимо установить соответствующие инструменты CUDA, при запуске Pipeline должно отобразиться «Use devise: gpu». В случае проблем с обнаружением видеокарты, посетить данную вебстраницу.
Для построения графа необходимо получить список ребер, в данном случае ребром будут два слова или словосочетания с зависимостью между ними. Как раз для поиска этой зависимости будет использоваться Stanza. С помощью «depparse» препроцессора можно определить более 30 различных зависимостей.
Основная сложность заключается в составлении правильной конструкции (Subject – relation — Object) — triplet, которая будет подходить для всех текстов в корпусе. Для примера будут использоваться 6 зависимостей (nsubj, nsubj:pass, obj, obl, nmod, nummod). Выбор зависимостей обусловлен тематикой и окраской текста, который Вы хотите извлечь из всего корпуса. Пример конструкции зависимостей в предложении представлен на рисунке ниже.
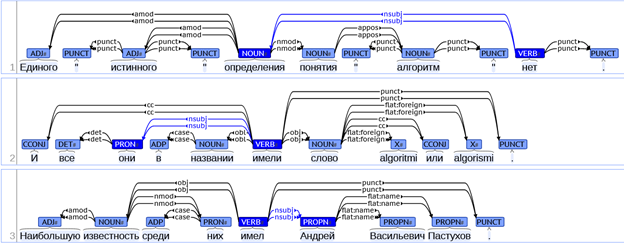
Как правило, Subject и Object являются существительными, а relation – глаголом. В 3-м примере можно заметить, что Subject – «Андрей», relation – «имел» и Object – «известность». Однако в большинстве случаев связь не так очевидна, как в примере выше и для полного понимания необходимо «навешивать» на Subject и Object дополнительные связи.
Далее единый код будет описываться частями для лучшего восприятия:
triplets = [] for s in tqdm(long_sents): doc = nlp(s) for sent in doc.sentences: entities = [ent.text for ent in sent.ents]Создаем список, в который будем записывать связи в предложении «Subject – relation – Object» (триплет). Далее для каждого предложения применяем препроцессоры и получаем переменную (doc), которая содержит в себе всю информацию для каждого слова. Далее извлекаем все именованные сущности из предложения в переменную entities.
res_d = dict() temp_d = dict() for word in sent.words: temp_d[word.text] = {"head": sent.words[word.head-1].text, "dep": word.deprel, "id": word.id}Далее создаем временный словарь temp_d и записываем в него слова, связи для них (head), а также тип этой связи (dep), например:
{"Андрей": {"head": "имел", "dep": "nsubj"}, .....}Также создаем словарь res_d, для записи триплетов конкретного предложения.
for k in temp_d.keys(): nmod_1 = "" nmod_2 = "" if (temp_d[k]["dep"] in ["nsubj", "nsubj:pass"]) & (k in entities): res_d[k] = {"head": temp_d[k]["head"]}Проводим поиск такого слово в temp_d, которое имеет тип связи «nsubj» или «nsubj:pass», а также проверяем, что это слово относится к именованной сущности. В res_d записываем слово, и слово-связь (head) для него. Также создадим переменные для сохранения дополнительных связей (nmod_1 и nmod_2).
for k_0 in temp_d.keys(): if (temp_d[k_0]["dep"] in ["obj", "obl"]) &\ (temp_d[k_0]["head"] == res_d[k]["head"]) &\ (temp_d[k_0]["id"] > temp_d[res_d[k]["head"]]["id"]): res_d[k]["obj"] = k_0 breakРаннее мы определили Subject и relation, осталось найти Object. Для этого мы находим слово в temp_d, которое имеет связь с relation, типа obj или obl. Также должны убедиться, что Object располагается в предложении после relation, т.к. такой тип связи может встречаться несколько раз в предложении. Таким образом получаем следующую запись:
{«Андрей»: {‘head’: имел, ‘obj’: «известность»}}
Далее найдем окраску нашему отношению, т.е. проверим наличие частицы «не», чтобы лучше понимать контекст:
for k_1 in temp_d.keys(): if (temp_d[k_1]["head"] == res_d[k]["head"]) & (k_1 == "не"): res_d[k]["head"] = "не "+res_d[k]["head"]Рассмотрим следующий пример. На вход подается предложение: «Ямы находятся на траектории движения во двор.»
Тогда результатом алгоритма будет: {«Ямы»: {«head»: «находятся», «obj»: «траектории»}}. Сложно определить, какой смысл несет данный триплет и правильно ли он составлен. Именно для этого необходимо «навешивать» дополнительные связи. Попробуем найти дополнительные связи для Object:
if "obj" in res_d[k].keys(): for k_4 in temp_d.keys(): if (temp_d[k_4]["dep"] =="nmod") &\ (temp_d[k_4]["head"] == res_d[k]["obj"]): nmod_1 = k_4 break for k_5 in temp_d.keys(): if (temp_d[k_5]["dep"] =="nummod") &\ (temp_d[k_5]["head"] == nmod_1): nmod_2 = k_5 break res_d[k]["obj"] = res_d[k]["obj"]+" "+nmod_2+" "+nmod_1Снова пробегаемся по нашему словарю и находим слово, которое имеет связь с Object, типа nmod. Далее повторим операцию, только на этот раз проводим поиск слова, которое имеет связь nummod со словом nmod_1. Таким образом, результат должен быть следующим: {«Ямы»: {«head»: «находятся», «obj»: «траектории движения»}}, что приобретает более глубокий смысл. Странно конечно, что Stanza относит «яму» к именованной сущности.
В итоге получаем низкопроизводительный код.)))
%%time triplets = [] for s in tqdm(long_sents): doc = nlp(s) for sent in doc.sentences: entities = [ent.text for ent in sent.ents] res_d = dict() temp_d = dict() for word in sent.words: temp_d[word.text] = {"head": sent.words[word.head-1].text, "dep": word.deprel, "id": word.id} for k in temp_d.keys(): nmod_1 = "" nmod_2 = "" if (temp_d[k]["dep"] in ["nsubj", "nsubj:pass"]) & (k in entities): res_d[k] = {"head": temp_d[k]["head"]} for k_0 in temp_d.keys(): if (temp_d[k_0]["dep"] in ["obj", "obl"]) &\ (temp_d[k_0]["head"] == res_d[k]["head"]) &\ (temp_d[k_0]["id"] > temp_d[res_d[k]["head"]]["id"]): res_d[k]["obj"] = k_0 break for k_1 in temp_d.keys(): if (temp_d[k_1]["head"] == res_d[k]["head"]) & (k_1 == "не"): res_d[k]["head"] = "не "+res_d[k]["head"] if "obj" in res_d[k].keys(): for k_4 in temp_d.keys(): if (temp_d[k_4]["dep"] =="nmod") &\ (temp_d[k_4]["head"] == res_d[k]["obj"]): nmod_1 = k_4 break for k_5 in temp_d.keys(): if (temp_d[k_5]["dep"] =="nummod") &\ (temp_d[k_5]["head"] == nmod_1): nmod_2 = k_5 break res_d[k]["obj"] = res_d[k]["obj"]+" "+nmod_2+" "+nmod_1 if len(res_d) > 0: triplets.append([s, res_d])В данной статье хотел донести основную концепцию поиска триплетов. Надеюсь, Ваша реализация получится намного лучше. Далее отфильтруем неполные триплеты, в которых отсутствует Object:
clear_triplets = [] for tr in triplets: for k in tr[1].keys(): if "obj" in tr[1][k].keys(): clear_triplets.append([tr[0], k, tr[1][k]['head'], tr[1][k]['obj']])В результате получаем список триплетов, а также предложения, из которых они получены.
[['Ямы находятся на траектории движения во двор.', 'Ямы', 'находятся', 'траектории движения'], ……]Осталось отрисовать результат удобным для Вас способом. Для этого можно воспользоваться такими инструментами, как NetworkX, Graphviz, Gephi и другие.
Я воспользуюсь инструментом визуализации Vis.js, т.к. на мой взгляд он является самым удобным для формирования интерактивных графов. Для удобства добавил небольшой функционал в Vis.js, который позволяет отображать полное предложение, при нажатии на ребро. Полный код, а также код для отрисовки представлен в notebook. Перед отрисовкой все слова приведены к начальной форме, что усложняет восприятие, однако данный процесс позволяет избавиться от повтора вершин на графе.
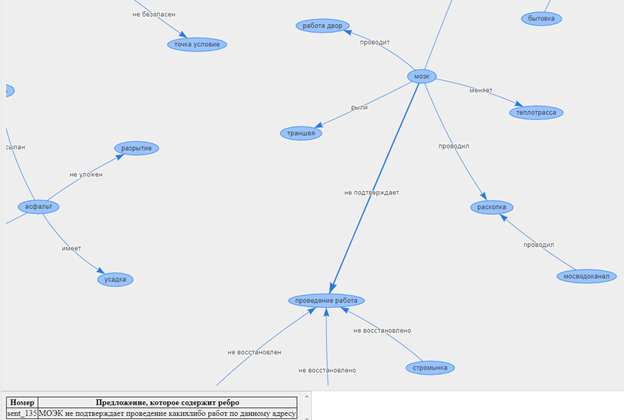
Таким образом, можем проанализировать текстовые данные и определить основное содержание жалоб и благодарностей, а также найти взаимосвязи между различными обращениями.
ссылка на оригинал статьи https://habr.com/ru/post/559110/
Добавить комментарий