
Продолжая тему использования Asciidoc (и других аналогичных форматов) для организации процессов непрерывного документирования, хочу рассмотреть тему автоматический генерации технической документации.
Автоматическая генерация документации — распространенный, но очень расплывчатый термин. Я понимаю под этим термином извлечение для представления в удобном виде информации, содержащейся в исходном коде и настройках документируемой программы (информационной системы).
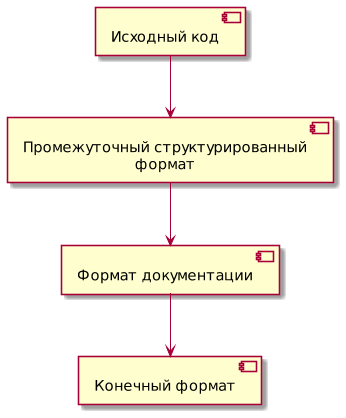
Общая схема автоматической генерации документации
Если рассматривать процесс автоматической генерации как чёрный ящик, то на входе имеем исходный код, а на выходе — документацию или её фрагмент. Однако в реальности при автоматической генерации документации целесообразны еще два промежуточных звена.
- преобразование исходного кода в структурированный формат. Шаг обусловлен тем, что для получения документов используются шаблонизаторы. Все современные технологии, связанные с генерацией человеко-читаемых документов, пользовательских интерфейсов, программного кода, активно используют шаблонизаторы, подключаемые в виде библиотек или реализованные внутри программного кода. Вход для шаблонизатора — структура данных, которую легко получить из файлов в форматах JSON/YAML или XML;
- преобразование структурированного формата в один из форматов документации (обычно Asciidoc, DITA, Docbook, Markdown, reStructuredText).
За исключением самых простых случаев документация готовится в различных выходных форматах (html, docx, odt, pdf и т.п.) и собирается из разных источников (в том числе не автоматически генерируемых) поэтому целесообразно использовать специальные форматы, для подготовки документации. Предположим, необходимо подготовить документацию по стандартам ЕСКД? Эта проблема, описана в предыдущей статье. При решении проблем автоматической генерации хватает проблем и без требований ГОСТ.
Общая схема генерации документации выглядит следующим образом:
Рассмотрим практические приёмы, которые можно использовать при реализации ИТ-проектов. Для примеров будем использовать Asciidoc, однако приёмы применимы к любым языкам разметки текста(reStructuredText, Markdown), и текстовым маркапам для построения диаграмм (рекомендую проект kroki, который позволяет быстро ознакомиться и внедрить наиболее популярные средства построения диаграмм).
Преобразование исходного кода в структурированный формат
Единых подходов к превращению исходного кода в структурированный формат не существует. Рассмотрим наиболее частые варианты.
Информация для документации извлекается из структуры исходного кода
Как правило, используются дополнительные средства языка, обычно комментарии в специальном формате (комментарии Javadoc, ReST и т.п.) и аннотации.
Средств, обеспечивающих преобразование исходного кода в документацию, причём очень зрелых, много. Можно смело брать и использовать подходящие для конкретного проекта. Разработка собственных средств затратна. Мы пошли указанным путём только раз, разрабатывая проект для миграции структуры базы данных. Целесообразность определялась использованием средства во всех наших проектах и желанием попробовать свои силы.
Следующие подходы более гибки с точки зрения настройки автоматической генерации документации в реализуемых проектах.
Структурированный формат получается как один из результатов исполнения исходного кода
При данном подходе считывается и сохраняется в структурированный формат состояния объектов (например, структуры базы данных, конфигурации развернутой среды информационной системы и т.п.), создаваемых в результате работы приложения.
Отдельно отметим использование для документирвоания логов. Типовой пример — тесты. Например, большинство инструментов для тестирования выдают результаты в формате Junit xml report. Это, позволяет сделать универсальные инструменты генерации отчётности по тестам, самый известный, наверное — Allure Framework.
В этой статье показано, как используют JSON-файлы, которые генерирует при работе Cucumber, как документация строится на основе логов, создаваемых в результате работы тестов.
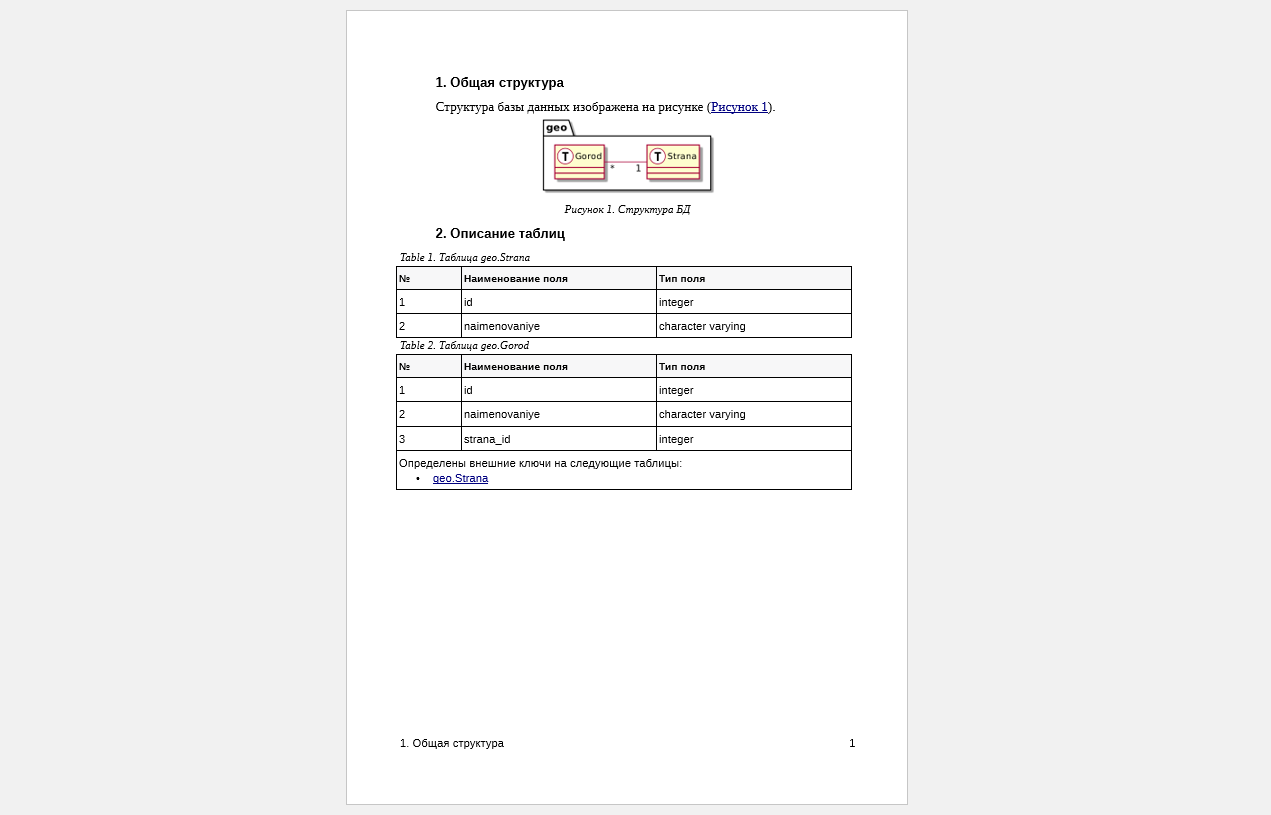
Типовой пример создания документации на основе считывания состояния объектов, создаваемых в результате работы приложения, — документирование структуры БД. В конце раздела приведен пример, иллюстрирующий данный подход.
Исходный код сразу представляет собой структурированный формат
Многие языки уже реализованы в структурированном формате (например, xsd-схемы, OpenAPI, различные DSL для описания предметной области, файлы настроек).
Иногда проводят предварительную обработку этих форматов, например, объединение спецификации в единую иерархическую структуру (так называемая операция «flatten»).
Частным (и частым) случаем является ситуация, когда настройки содержатся в базе данных.
Пример — генерация документации по структуре базы данных
Пример иллюстрирует достаточно частую ситуацию, когда информация для документации хранится в таблицах СУБД.
Создаём скрипт, описывающий структуру БД. Этот скрипт не выглядит как исходник для поддержания структуры БД, однако, как это не парадоксально, таковым является, подробности в документации к уже упомянутому проекту. Это также может быть миграционный скрипт в любой системе контроля версии базы данных.
create table geo.Strana ( id int , naimenovaniye varchar(255) , primary key (id) ); create table geo.Gorod ( id int , naimenovaniye varchar(255) , strana_id int , constraint strana_gorod foreign key (strana_id) references geo.Strana(id) );
Применим скрипт к базе данных и воспользуемся двумя инструментами СУБД (пример приведён для PostgreSQL): динамическими представлениями для извлечения сведений о структуре и возможностью создавать JSON-файлы на основе результатов сохранения запросов.
drop table if exists fk; select x.table_schema as table_schema , x.table_name , y.table_schema as foreign_table_schema , y.table_name as foreign_table_name into temp fk from information_schema.referential_constraints rc join information_schema.key_column_usage x on x.constraint_name = rc.constraint_name join information_schema.key_column_usage y on y.ordinal_position = x.position_in_unique_constraint and y.constraint_name = rc.unique_constraint_name;
select json_agg(json_build_object( 'name', t.table_schema || '.' || t.table_name , 'columns' , (select json_agg(json_build_object ( 'name', column_name ,'type', data_type )) from information_schema.columns as c where c.table_name = t.table_name and c.table_schema = t.table_schema ) , 'fk' , (select json_agg(json_build_object ( 'fk_table' , fk.foreign_table_schema || '.' || fk.foreign_table_name )) from fk where fk.table_name = t.table_name and fk.table_schema = t.table_schema ) )) from information_schema.tables as t where table_schema = 'geo';
В результате получим JSON-файл:
[{ "name": "geo.Strana", "columns": [{ "name": "id", "type": "integer" }, { "name": "naimenovaniye", "type": "character varying" } ], "fk": null }, { "name": "geo.Gorod", "columns": [{ "name": "id", "type": "integer" }, { "name": "naimenovaniye", "type": "character varying" }, { "name": "strana_id", "type": "integer" } ], "fk": [{ "fk_table": "geo.Strana" } ] } ]
В следующем разделе будет показано, как этот файл превратить в документ.
Использование шаблонизаторов
Для превращения структурированного файла в документ используют специальный тип языков,
шаблонизаторы. Шаблонизатор позволяет задать правила обхода иерархической структуры данных и правила, по которым элементы иерархии исходного документа преобразуют в выходной документ.
Формат этих правил достаточно простой, они безопасны с точки зрения исполнения, поэтому часто шаблонизаторы используются для настройки различных аспектов работы приложений непосредственно пользователями.
Самым известным языком обработки шаблонов (но далеко не самым простым) является XSLT. Самым минималистичным — Mustache.
Свой язык написания шаблонов и шаблонизатор также создать довольно просто. Например, для создания системы генерации отчётов в форматах Excel и ods мы пошли этим путём.
Можно вообще обойтись без шаблонизатора, просто структурировать код определенным образом, в этой старой статье 2003 года Мартин Фаулер признается в нелюбви к XSLT и заодно объясняет, как его заменить кодом, написанным на языке Ruby. За 18 лет оказалось, что и статические языки также можно прекрасно использовать для этих целей, и XSLT прекрасно себя чувствует, и предложенный в статье подход оказался очень хорош.
В примерах будет использоваться Liquid для работы с JSON и XSLT для работы с XML. В обоих случаях будет использоваться реализация в Ruby, потому что (1) Наиболее распространенный в настоящий момент процессор Asciidoc — Asciidoctor — написан на Ruby (2) Ruby-скрипты отлично работают в java и javascript, что часто позволяет не плодить цирк технологий.
Пример генерации документа из JSON-файла
Рассмотрим простой пример по генерации документа на основе полученного выше JSON-файла.
Генерация диаграммы в формате PlantUML:
{% assign bl = "\n" %} {%- for table in data -%} class {{ table.name }}{{ bl }} {%- for fk in table.fk -%} {{ table.name }} "*" -- "1" {{ fk.fk_table }}{{ bl }} {%- endfor -%} {%- endfor -%}
В примере шаблонизатор обходит все узлы, определяющие таблицы. Для каждой таблицы создается строка PlantUML для отрисовки классов class [Наименование класса]. Далее внутри каждой таблицы проверяется наличие внешних ключей и создается соединительная линия с соответствующими классами.
На выходе получаем следующий текст диаграммы:
class geo.Strana class geo.Gorod geo.Gorod "*" -- "1" geo.Strana
Аналогично сгенерируем документ в формате Asciidoc:
{% assign bl = "\n" %}{% assign bbl = "\n\n" %} {%- for table in data -%} [[{{ table.name }}]]{{- bl -}} .Таблица {{ table.name }}{{- bl -}} [cols="1,3,3", options="header"]{{- bl -}} |==={{- bl -}} |№ |Наименование поля |Тип поля{{ bl }} {%- for column in table.columns -%} |{counter:{{ table.name }}} |{{ column.name }} |{{ column.type }}{{- bl -}} {%- endfor -%} {%- if table.fk -%} 3+a|Определены внешние ключи на следующие таблицы:{{- bbl -}} {%- for fk in table.fk -%} * <<{{fk.fk_table}}, {{fk.fk_table}}>>{{- bl -}} {%- endfor -%} {%- endif -%} |==={{- bbl -}} {%- endfor -%}
Для объединения обоих кусков в один документ воспользуемся директивой include:
= Структура БД :lang: ru :figure-caption: Рисунок :xrefstyle: short :sectnums: == Общая структура Структура базы данных изображена на рисунке (<<struktura>>). [[struktura]] .Структура БД [plantuml, struktura, png, fitrect="170x240mm", srcdpi=300, width="50%"] .... skinparam dpi 300 left to right direction include::pu_sql.pu[] .... == Описание таблиц include::adoc_sql.adoc[]
Синтаксис Asciidoc рассмотрен в статье Asciidoc для ЕСКД. Подробнее структурирование документации в Asciidoc планирую описать в отдельной статье. Здесь лишь хотелось бы отметить, что при вставке диаграммы мы указываем параметры её отображения. В разных документах одну и ту же диаграмму мы можем отобразить по-разному (в разных цветах, с разным разрешением, в разной ориентации и т.п.).
Результаты превращаем в файл в формате Microsoft Word с помощью проекта, о котором рассказано в предыдущей статье.
Ключевые техники, используемые при генерации документации
Для рассмотрения ключевых техник приведём пример с преобразованием XML-файла.
Для примера возьмем выписку из ЕГРЮЛ от Федеральной налоговой службы. Не совсем документация, но удобно для демонстрации основных приёмов преобразования структурированных данных в документацию.
Исходные данные (схема xsd и пример сообщения) взяты на сайте СМЭВ 3 — https://smev3.gosuslugi.ru/portal/inquirytype_one.jsp?id=41108&zone=fed. Для примера приведём небольшую часть выписки из ЕГРЮЛ:
<ns1:СвНаимЮЛ НаимЮЛПолн="НАИМЕНОВАНИЕ 5087746429843" НаимЮЛСокр="СОКРАЩЕННОЕ НАИМЕНОВАНИЕ 5087746429843"> <ns1:ГРНДата ГРН="5087746429843" ДатаЗаписи="2008-11-18"/> </ns1:СвНаимЮЛ> <ns1:СвАдресЮЛ> <ns1:АдресРФ КодРегион="77" КодАдрКладр="770000000002990" Дом="7" Корпус="6"> <fnst:Регион ТипРегион="ГОРОД" НаимРегион="МОСКВА"/> <fnst:Улица ТипУлица="УЛИЦА" НаимУлица="ФИЛЕВСКАЯ 2-Я"/> <fnst:ГРНДата ГРН="5087746429843" ДатаЗаписи="2008-11-18"/> </ns1:АдресРФ> </ns1:СвАдресЮЛ>
Как видно, названия тэгов и атрибутов вполне говорящие, но мы возьмем полные названия параметров из схемы xsd.
Преобразование выписки из ЕГРЮЛ в формат Asciidoc выглядит следующим образом:
<stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform" xmlns:ep="uri:asciidoc:doc:automation" extension-element-prefixes="ep"> <output method="text" /><strip-space elements="*"/> <template match="/"><apply-templates/></template> <template match="*[count(@*|*) > 0 and count(ancestor::*) > 0]"> <value-of select="'\n='"/> <for-each select="ancestor::*"><value-of select="'='"/></for-each> <value-of select="' '"/> <value-of select="concat('{',local-name(),'}')"/><text>\n\n</text> <text>|===\n</text> <for-each select="(@*)|(*[./text()])"> <text>|</text><value-of select="concat('{',local-name(),'}')"/> <text>|</text><value-of select="ep:iformat(current())"/> <text>\n</text> </for-each> <text>|===\n</text> <apply-templates/> </template> <template match="text()"/> </stylesheet>
В примере шаблонизатор обходит все узлы файла с данными ЕГРЮЛ. Тэги, в которых есть атрибуты или дополнительные тэги трансформируются в заголовок с нужным уровнем иерархии. Атрибуты и текстовые тэги — в строки таблицы. Обратите внимание, что в Asciidoc реализован очень компактный способ задания ячейки таблицы через символ |.
Наименования тэгов и атрибутов XML-документа обёрнуты в фигурные скобки — специальный синтаксис для отображения значений атрибутов Asciidoc. Значения атрибутов легко извлекаем из xsd-схемы с помощью следующего преобразования:
<?xml version="1.0" encoding="UTF-8"?> <stylesheet version="1.0" xmlns="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <output method="text" /> <strip-space elements="*"/> <template match="*[@name]"> <value-of select="concat(':', @name, ': ')"/> <value-of select="normalize-space(xs:annotation/xs:documentation)"/> <text>\n</text> <apply-templates/> </template> <template match="*[not(@name)]"> <apply-templates/> </template> <template match="text()"></template> </stylesheet>
Объединим полученные значения атрибутов Asciidoc (два файла, т.к. описание сервиса по выдаче ЕГРЮЛ состоит из двух схем xsd) и файл с содержанием выписки:
:sectnums: include::adoc_egrul_xsd.adoc[] include::adoc_egrul_xsd2.adoc[] include::adoc_egrul.adoc[]
На выходе Microsoft Word даёт следующую картинку:

Борьба с пробельными символами
Поскольку конечным форматом преобразования является текстовая разметка, вопрос пробелов крайне важен: текст, смещенный на несколько пробелов, может быть воспринят как блок с моноширинным текстом.
Пробелы могут влиять на эстетику, читаемость и обрабатываемость выходного документа. Например, после каждого абзаца в Asciidoc должно быть два переноса строки. Их может быть и три, но читается файл хуже. Во многих автоматически сгенерированных документах количество переносов строк абсолютно не предсказуемо. Особенно это неудобно при сравнении версий файла. При наличии на выходе файла в формате XML или JSON можно было бы применить утилиты, создающие красивый выходной файл. Для текстовых маркапов, насколько я знаю, таких утилит не существует.
С другой стороны, крайне важно, чтобы сам шаблон был красивым и удобным для чтения и редактирования, чтобы, как минимум, были отступы в циклах и условных операторах.
Поработав со многими шаблонизаторами, пришёл к выводу, что единственный практически универсальный вариант — указать шаблонизатору, чтобы он вырезал все пробелы и переносы, а переносы указывать вручную в шаблоне. В приведенном примере есть опция <strip-space elements="*"/> и после каждой выводимой строчки помещена команда <text>\n</text>. Некоторые шаблонизаторы воспринимают \n как символ переноса. Если нет, необходимо провести пост-обработку выходного файла и самостоятельно заменять данную комбинацию на перенос строки.
В примере для Liquid применен аналогичный подход, только для наглядности символ переноса присвоен переменной bl.
Рекурсия
Рекурсия обеспечивает наглядный способ обхода узлов структурированного документа с большим количеством единообразных уровней иерархии, как в приведённой выписке из ЕГРЮЛ.
Рекурсию поддерживает большинство шаблонизаторов. Например, XSLT поддерживает рекурсию директивой apply-templates. В примере основной шаблон (template) обеспечивает обработку иерархического узла выписки из ЕГРЮЛ и далее вызывает себя для каждого узла ниже по иерархии.
Экранирование и другие операции со вставляемыми данными
Данные для вставки в Asciidoc файл могут вступить в конфликт с разметкой Asciidoc. Например, вы хотите взять текст из Open API спецификации и добавить символ «;». Однако разработчик мог при описании сам поставить тот же символ. В результате в выходной файл попадёт два символа «;;» и Asciidoc будет воспринимать текст как терминологический список, и хорошо ещё, если мы быстро поймём, почему на выходе текст отформатирован странно.
Чтобы этого избежать, можно оборачивать вставляемый текст собственными функциями, которые экранируют и производят требуемые преобразования значений. В примере — это функция iformat. Она добавляет в начале и в конце значения символ нулевого пробела (zero space) и переводит значения типа даты в формат DD.MM.YYYY.
AsciidocDocAutomation = Class.new do def iformat(node) value = node.to_s re = /^([0-9]{4})-([0-9]{2})-([0-9]{2})$/ vm = value.match(re) value = "#{vm[3]}.#{vm[2]}.#{vm[1]}" if !!(value =~ re) "​#​" end end
Для полного отключения синтаксиса Asciidoc во вставляемых значениях, достаточно их просто экранировать.
Выводы
- Технологии автоматической генерации документации отработаны и их могут быть эффективно использованы в ИТ-проектах любого уровня сложности.
- Язык разметки Asciidoc технологичен для применения в задачах автоматической генерации документации.
И анонс: следующая статья будет посвящена вопросам обеспечения качества документации в формате Asciidoc.
ссылка на оригинал статьи https://habr.com/ru/post/562108/
Добавить комментарий