Фиксация различных нарушений, контроль доступа, розыск и отслеживание автомобилей – лишь часть задач, для которых требуется по фотографии определить номер автомобиля (государственный регистрационный знак или ГРЗ).
В этой статье мы рассмотрим создание модели для распознавания с помощью Catalyst – одного из самых популярных высокоуровневых фреймворков для Pytorch. Он позволяет избавиться от большого количества повторяющегося из проекта в проект кода – цикла обучения, расчёта метрик, создания чек-поинтов моделей и другого – и сосредоточиться непосредственно на эксперименте.

Сделать модель для распознавания можно с помощью разных подходов, например, путем поиска и определения отдельных символов, или в виде задачи image-to-text. Мы рассмотрим модель с несколькими выходами (multihead-модель). В качестве датасета возьмём датасет с российскими номерами от проекта Nomeroff Net. Примеры изображений из датасета представлены на рис. 1.

Рис. 1. Примеры изображений из датасета
Общий подход к решению задачи
Необходимо разработать модель, которая на входе будет принимать изображение ГРЗ, а на выходе отдавать строку распознанных символов. Модель будет состоять из экстрактора фичей и нескольких классификационных “голов”. В датасете представлены ГРЗ из 8 и 9 символов, поэтому голов будет девять. Каждая голова будет предсказывать один символ из алфавита “1234567890ABEKMHOPCTYX”, плюс специальный символ “-” (дефис) для обозначения отсутствия девятого символа в восьмизначных ГРЗ. Архитектура схематично представлена на рис. 2.

Рис. 2. Архитектура модели
В качестве loss-функции возьмём стандартную кросс-энтропию. Будем применять её к каждой голове в отдельности, а затем просуммируем полученные значения для получения общего лосса модели. Оптимизатор – Adam. Используем также OneCycleLRWithWarmup как планировщик leraning rate. Размер батча – 128. Длительность обучения установим в 10 эпох.
В качестве предобработки входных изображений будем выполнять нормализацию и преобразование к единому размеру.
Кодирование
Далее рассмотрим основные моменты кода. Класс датасета (листинг 1) в общем обычный для CV-задач на Pytorch. Обратить внимание стоит лишь на то, как мы возвращаем список кодов символов в качестве таргета. В параметре label_encoder передаётся служебный класс, который умеет преобразовывать символы алфавита в их коды и обратно.
class NpOcrDataset(Dataset): def __init__(self, data_path, transform, label_encoder): super().__init__() self.data_path = data_path self.image_fnames = glob.glob(os.path.join(data_path, "img", "*.png")) self.transform = transform self.label_encoder = label_encoder def __len__(self): return len(self.image_fnames) def __getitem__(self, idx): img_fname = self.image_fnames[idx] img = cv2.imread(img_fname) if self.transform: transformed = self.transform(image=img) img = transformed["image"] img = img.transpose(2, 0, 1) label_fname = os.path.join(self.data_path, "ann", os.path.basename(img_fname).replace(".png", ".json")) with open(label_fname, "rt") as label_file: label_struct = json.load(label_file) label = label_struct["description"] label = self.label_encoder.encode(label) return img, [c for c in label]Листинг 1. Класс датасета
В классе модели (листинг 2) мы используем библиотеку PyTorch Image Models для создания экстрактора фичей. Каждую из классификационных голов модели мы добавляем в ModuleList, чтобы их параметры были доступны оптимизатору. Логиты с выхода каждой из голов возвращаются списком.
class MultiheadClassifier(nn.Module): def __init__(self, backbone_name, backbone_pretrained, input_size, num_heads, num_classes): super().__init__() self.backbone = timm.create_model(backbone_name, backbone_pretrained, num_classes=0) backbone_out_features_num = self.backbone(torch.randn(1, 3, input_size[1], input_size[0])).size(1) self.heads = nn.ModuleList([ nn.Linear(backbone_out_features_num, num_classes) for _ in range(num_heads) ]) def forward(self, x): features = self.backbone(x) logits = [head(features) for head in self.heads] return logitsЛистинг 2. Класс модели
Центральным звеном, связывающим все компоненты и обеспечивающим обучение модели, является Runner. Он представляет абстракцию над циклом обучения-валидации модели и отдельными его компонентами. В случае обучения multihead-модели нас будет интересовать реализация метода handle_batch и набор колбэков.
Метод handle_batch, как следует из названия, отвечает за обработку батча данных. Мы в нём будем только вызывать модель с данными батча, а обработку полученных результатов – расчёт лосса, метрик и т.д. – мы реализуем с помощью колбэков. Код метода представлен в листинге 3.
class MultiheadClassificationRunner(dl.Runner): def __init__(self, num_heads, *args, **kwargs): super().__init__(*args, **kwargs) self.num_heads = num_heads def handle_batch(self, batch): x, targets = batch logits = self.model(x) batch_dict = { "features": x } for i in range(self.num_heads): batch_dict[f"targets{i}"] = targets[i] for i in range(self.num_heads): batch_dict[f"logits{i}"] = logits[i] self.batch = batch_dictЛистинг 3. Реализация runner’а
Колбэки мы будем использовать следующие:
-
CriterionCallback – для расчёта лосса. Нам потребуется по отдельному экземпляру для каждой из голов модели.
-
MetricAggregationCallback – для агрегации лоссов отдельных голов в единый лосс модели.
-
OptimizerCallback – чтобы запускать оптимизатор и обновлять веса модели.
-
SchedulerCallback – для запуска LR Scheduler’а.
-
AccuracyCallback – чтобы иметь представление о точности классификации каждой из голов в ходе обучения модели.
-
CheckpointCallback – чтобы сохранять лучшие веса модели.
Код, формирующий список колбэков, представлен в листинге 4.
def get_runner_callbacks(num_heads, num_classes_per_head, class_names, logdir): cbs = [ *[ dl.CriterionCallback( metric_key=f"loss{i}", input_key=f"logits{i}", target_key=f"targets{i}" ) for i in range(num_heads) ], dl.MetricAggregationCallback( metric_key="loss", metrics=[f"loss{i}" for i in range(num_heads)], mode="mean" ), dl.OptimizerCallback(metric_key="loss"), dl.SchedulerCallback(), *[ dl.AccuracyCallback( input_key=f"logits{i}", target_key=f"targets{i}", num_classes=num_classes_per_head, suffix=f"{i}" ) for i in range(num_heads) ], dl.CheckpointCallback( logdir=os.path.join(logdir, "checkpoints"), loader_key="valid", metric_key="loss", minimize=True, save_n_best=1 ) ] return cbsЛистинг 4. Код получения колбэков
Остальные части кода являются тривиальными для Pytorch и Catalyst, поэтому мы не станем приводить их здесь. Полный код к статье доступен на GitHub.
Результаты эксперимента
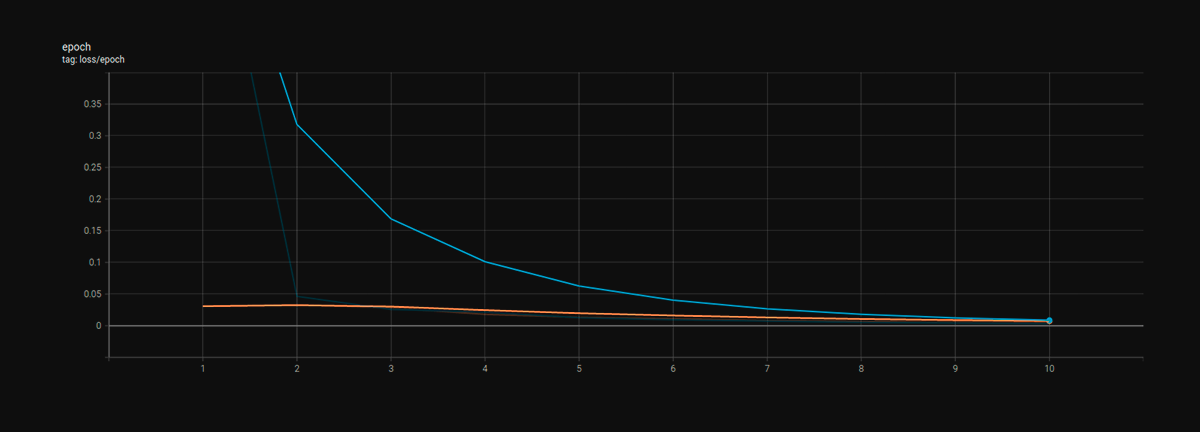
Рис. 3. График лосс-функции модели в процессе обучения. Оранжевая линия – train loss, синяя – valid loss
В списке ниже перечислены некоторые ошибки, которые модель допустила на тест-сете:
-
Incorrect prediction: T970XT23- instead of T970XO123
-
Incorrect prediction: X399KT161 instead of X359KT163
-
Incorrect prediction: E166EP133 instead of E166EP123
-
Incorrect prediction: X225YY96- instead of X222BY96-
-
Incorrect prediction: X125KX11- instead of X125KX14-
-
Incorrect prediction: X365PC17- instead of X365PC178
Здесь присутствуют все возможные типы: некорректно распознанные буквы и цифры основной части ГРЗ, некорректно распознанные цифры кода региона, лишняя цифра в коде региона, а также неверно предсказанное отсутствие последней цифры.
Заключение
В статье мы рассмотрели способ реализации multihead-модели для распознавания ГРЗ автомобилей с помощью фреймворка Catalyst. Основными компонентами явились собственно модель, а также раннер и набор колбэков для него. Модель успешно обучилась и показала высокую точность на тестовой выборке.
Спасибо за внимание! Надеемся, что наш опыт был вам полезен.
Больше наших статей по машинному обучению и обработке изображений:
ссылка на оригинал статьи https://habr.com/ru/company/simbirsoft/blog/561866/
Добавить комментарий