Введение
Изучение любого языка — очень долгий процесс, в ходе которого могут возникать ситуации, когда очевидные с виду вещи ведут себя странно. Даже спустя много лет изучения языка не все и не всегда могут с уверенностью сказать “да, я знаю этот на 100%, несите следующий”.
Python — один из самых популярных языков программирования на сегодняшний день, но и он имеет ряд своих нюансов, которые на протяжении многих лет изменялись, оптимизировались и теперь ведут себя немного не так, как это может показаться, глядя на строчки незамысловатого кода.
Немного строк
Метод is для сравнения строк
Рассмотрим несколько примеров, в которых работа со строками может быть не такой гладкой. Для начала необходимо создать файл (пусть будет test.py), и в нем реализовать функцию для тестирования работы строк:
def test_str(): # пример 1 a = "hello" b = "hello" print("Пример 1:", a is b) # пример 2 c = "hell" print("Пример 2:", c+"o" is a) # пример 3 a = "hello" b = "hello" print("Пример 3:", a + “!” is b + “!”) # пример 4 a, b = "hello!", "hello!" print("Пример 4:" ,a is b) # пример 5 a = "привет" b = "привет" print("Пример 5:", a is b) # пример 6 a = "!" b = "!" print("Пример 6:", a is b) test_str()После запуска кода вывод будет таким:
Пример 1: True Пример 2: False Пример 3: False Пример 4: True Пример 5: True Пример 6: TrueВ примере 1 вроде всё логично, есть 2 строки, мы проверяем, является ли одна строка другой при помощи метода is (а именно, ссылаются ли две переменные на одну строку). Так как значения обеих строки равны, то и они (по идеи) должны быть равны. Но в примере 2 видно, что сравниваются 2 одинаковые строки (ведь “hell” + “o” даст в итоге “hello”), но по итогу is вернул False.
Python оптимизирует работу со строками, используя метод интернирования, то есть для некоторых неизменяемых объектов python хранит только 1 экземпляр в памяти, как следствие, если в 2х переменных хранятся одинаковые строки, то они будут ссылаться на одну ячейку в памяти. Но это верно лишь отчасти.

При запуске программы интернирование происходит до момента её выполнения, именно поэтому в случае примера 2 строка, полученная при помощи конкатенации “hell” и “o” не была интернирована. Как следствие, во время выполнения программы строка “hello” (переменной a) и строка “hello” (полученная при помощи c + “o”) не будут ссылаться на один объект в памяти. Работу python можно проверить при помощи:
import dis def test_dis(): a = "hello" b = "hello" print("Пример 1:", a is b) c = "hello" d = "hell" print("Пример 2:", d+"o" is c) dis.dis(test_dis)Вывод:
38 0 LOAD_CONST 1 ('hello') 2 STORE_FAST 0 (a) 39 4 LOAD_CONST 1 ('hello') 6 STORE_FAST 1 (b) 40 8 LOAD_GLOBAL 0 (print) 10 LOAD_CONST 2 ('Пример 1:') 12 LOAD_FAST 0 (a) 14 LOAD_FAST 1 (b) 16 IS_OP 0 18 CALL_FUNCTION 2 20 POP_TOP 42 22 LOAD_CONST 1 ('hello') 24 STORE_FAST 2 (c) 43 26 LOAD_CONST 3 ('hell') 28 STORE_FAST 3 (d) 44 30 LOAD_GLOBAL 0 (print) 32 LOAD_CONST 4 ('Пример 2:') 34 LOAD_FAST 3 (d) 36 LOAD_CONST 5 ('o') 38 BINARY_ADD 40 LOAD_FAST 2 (c) 42 IS_OP 0 44 CALL_FUNCTION 2 46 POP_TOP 48 LOAD_CONST 0 (None) 50 RETURN_VALUEКак видно, в строке 0 и 4 в переменные a и b ссылаются на константные значения “hello”, а переменная d (в строке 26) ссылается на значение hell, после чего в 38 строке идет сложение значений из переменной d и строки “o”, и данное значение не берется из памяти (как в случае с переменными a и b), а получается новая строка с новым id.
Если же рассмотреть пример с вводом данных с клавиатуры (или из любого другого источника), то можно заметить следующий результат:
while True: a = input("Введите a: ") b = input("Введите b: ") print(a, b, a is b, id(a), id(b))Вывод:
Введите a: hello Введите b: hello hello hello False 2437519007408 2437519445104 Введите a: ! Введите b: ! ! ! True 2437486790320 2437486790320 Введите a: W Введите b: W W W True 2437484664176 2437484664176 Введите a: д Введите b: д д д False 2713563632704 2713563632624Все ASCII символы (ASCII строки длины 1 и 0) содержатся в python в единственном экземпляре изначально, поэтому вводя строку длиной 1 (или 0) можно быть уверенным, что это один тот же элемент в памяти, но для каждой не ASCII строки (либо строки с длиной больше 1) выделяется новое место в памяти в ходе выполнения программы.
Такая особенность хранения строк в Python позволяет экономить память, однако надо быть аккуратными при работе со строками, а именно, при сравнении строк при помощи метода is.
Конкатенация строк
Еще один пример. Конкатенирование строк в Python:
def test_str2(): import time s1 = "Привет" s2 = "Всем" s3 = "," s4 = "Кто" s5 = "Это" s6 = "Читает" t = time.time() for _ in range(1000000): s = s1 + " " + s2 + " " + s3 + " " + s4 + " " + s5 + " " + s6 r = time.time() - t print("Время на +: ", r) t = time.time() for _ in range(1000000): s = " ".join([s1, s2, s3, s4, s5, s6]) r = time.time() - t print("Время на join: ", r) t = time.time() for _ in range(1000000): s = "{} {} {} {} {} {}".format(s1, s2, s3, s4, s5, s6) r = time.time() - t print("Время на format: ", r) t = time.time() for _ in range(1000000): s = "%s %s %s %s %s %s" % (s1, s2, s3, s4, s5, s6) r = time.time() - t print("Время на %: ", r) t = time.time() for _ in range(1000000): s = f"{s1} {s2} {s3} {s4} {s5} {s6}" r = time.time() - t print("Время на f-string: ", r) test_str2()Вывод:
Время на +: 0.601959228515625 Время на join: 0.3228156566619873 Время на format: 0.6226434707641602 Время на %: 0.49173593521118164 Время на f-string: 0.28386688232421875F-string было введено в Python 3.6. Хотя существует несколько способов объединять строки, многие не задаются вопросов “зачем столько всякого?”, считая, что это всего лишь украшения языка для удобства пользования (ведь запись f”{s1} {s2}…” более понятна, чем s1 + “ ” + s2+ … + sn). Но разные методы работы со строкам расходуют разный объем памяти и времени, f-string был введен с целью ускорить работу со строками.
Проведя dis.dis() для данного метода, можно заметить, что разные методы конкатенации вызывают разные состояния, которые в свою очередь различаются по реализации.
Для “+” выполняются следующие действия:
140 52 LOAD_FAST 1 (s1) 54 LOAD_CONST 9 (' ') 56 BINARY_ADD 58 LOAD_FAST 2 (s2) 60 BINARY_ADD 62 LOAD_CONST 9 (' ') 64 BINARY_ADD 66 LOAD_FAST 3 (s3) 68 BINARY_ADD 70 LOAD_CONST 9 (' ') 72 BINARY_ADD 74 LOAD_FAST 4 (s4) 76 BINARY_ADD 78 LOAD_CONST 9 (' ') 80 BINARY_ADD 82 LOAD_FAST 5 (s5) 84 BINARY_ADD 86 LOAD_CONST 9 (' ') 88 BINARY_ADD 90 LOAD_FAST 6 (s6) 92 BINARY_ADD 94 STORE_FAST 9 (s)Как видно, каждый раз вызывается состояние BINARY_ADD (см. подробнее оф. гитхаб cpython: строка case TARGET(BINARY_ADD)). Для метода “”.join():
140 LOAD_CONST 9 (' ') 142 LOAD_METHOD 3 (join) 144 LOAD_FAST 1 (s1) 146 LOAD_FAST 2 (s2) 148 LOAD_FAST 3 (s3) 150 LOAD_FAST 4 (s4) 152 LOAD_FAST 5 (s5) 154 LOAD_FAST 6 (s6) 156 BUILD_LIST 6 158 CALL_METHOD 1 160 STORE_FAST 9 (s)Для format:
206 LOAD_CONST 12 ('{} {} {} {} {} {}') 208 LOAD_METHOD 4 (format) 210 LOAD_FAST 1 (s1) 212 LOAD_FAST 2 (s2) 214 LOAD_FAST 3 (s3) 216 LOAD_FAST 4 (s4) 218 LOAD_FAST 5 (s5) 220 LOAD_FAST 6 (s6) 222 CALL_METHOD 6 224 STORE_FAST 9 (s)Для %s:
270 LOAD_CONST 14 ('%s %s %s %s %s %s') 272 LOAD_FAST 1 (s1) 274 LOAD_FAST 2 (s2) 276 LOAD_FAST 3 (s3) 278 LOAD_FAST 4 (s4) 280 LOAD_FAST 5 (s5) 282 LOAD_FAST 6 (s6) 284 BUILD_TUPLE 6 286 BINARY_MODULO 288 STORE_FAST 9 (s) 290 EXTENDED_ARG 1Для f-string:
336 LOAD_FAST 1 (s1) 338 FORMAT_VALUE 0 340 LOAD_CONST 9 (' ') 342 LOAD_FAST 2 (s2) 344 FORMAT_VALUE 0 346 LOAD_CONST 9 (' ') 348 LOAD_FAST 3 (s3) 350 FORMAT_VALUE 0 352 LOAD_CONST 9 (' ') 354 LOAD_FAST 4 (s4) 356 FORMAT_VALUE 0 358 LOAD_CONST 9 (' ') 360 LOAD_FAST 5 (s5) 362 FORMAT_VALUE 0 364 LOAD_CONST 9 (' ') 366 LOAD_FAST 6 (s6) 368 FORMAT_VALUE 0 370 BUILD_STRING 11 372 STORE_FAST 9 (s) 374 EXTENDED_ARG 1Сравнение объектов
Рассмотрим небольшой пример сравнения двух экземпляров классов:
def test_class(): class my_class(): pass a, b = my_class(), my_class() print(a == b) print(a is b) print(id(a) == id(b)) print(hash(a) == hash(b)) test_class()Вывод:
False False False FalseВсё замечательно. Теперь посмотрим на другой пример:
def test_class2(): class my_class(): pass print(my_class() == my_class()) print(my_class() is my_class()) print(hash(my_class()) == hash(my_class())) print(id(my_class()) == id(my_class())) test_class()Вывод:
False False True TrueЧто-то пошло не так. Вроде так же создаются 2 экземпляра класса, но при этом вывод показывает, что hash и id этих экземпляров одинаковы, но is показывает, что это получаются разные объекты. Рассмотрим еще пример:
def test_class3(): class my_class(): pass print(my_class() == my_class()) print(my_class() is my_class()) print(hash(a:=my_class()) == hash(b:=my_class())) print(id(c:=my_class()) == id(d:=my_class())) test_class3()Вывод:
False False False FalseВсё опять встало на свои места. Дополним немного my_class во всех примерах:
class my_class(): def __init__(self): print("__init__") def __del__(self): print("__del__")Как это работает? Когда создается экземпляр класса, он получает свой уникальный id, но как только у него вызывается метод __del__, тот самый id уже перестает принадлежать этому объекту, и точно такой же id может быть присвоен другому объекту, например:
class my_class(): pass a = my_class() print(id(a)) >>> 2082631974720 del a b = my_class() print(id(b)) >>> 2082631974720Когда python создает объект класса, как в случае 1 (в методе test_class), то на этот объект ссылается переменная, следовательно, этот объект хранится в памяти до тех пор, пока на него что-то ссылается. В примере 3 аналогично, a := my_class() и b := my_class() — “моржовый” оператор := создает переменную a, которая во время выполнения функции print живёт и ссылается на объект, а переменная b ссылается уже на другой объект, так как у объекта в a:=my_class() не был вызван метод __del__.
Пример 2 самый интересный. Когда вызывается id(my_class()), то происходит следующее: создается экземпляр класса my_class, этот только что созданный объект передается функции id, которая берёт id объекта, затем объект уничтожается и вызывается часть id(my_class()), стоящая справа от ==. Опять создается my_class (который, как мы определили чуть выше, будет иметь такой же id, как был у предыдущего my_class(), который уже не существует), и правая функция id получается значение id этого объекта. Так получается, что id слева и справа от == получают идентификаторы своих объектов в то время, когда физически существует только один из этих объектов, следовательно id, полученное слева будет таким же, как id полученное справа.
Назревает вопрос: почему метод is в примере 2 выдает False, id объектов должны же быть одинаковы, значит, они ссылаются на один объект? Чуть выше был изменён класс my_class. Для наглядности можно запустить пример 2 еще раз. Получим такой результат:
__init__ __init__ __del__ __del__ False __init__ __init__ __del__ __del__ False __init__ __del__ __init__ __del__ True __init__ __del__ __init__ __del__ TrueКогда выполнялся print с hash или id, видно, что по отдельности сначала вызывается конструктор, потом деструктор одного объекта, а потом конструктор и деструктор другого объекта, именно после того, как функции hash или id завершали свои действия, вызывался метод __del__ и создавался новый объект. В примере с is видно, что сначала создались оба экземпляра класса, а только потом вызывался метод __del__ у каждого из них. Это дает понять, что метод is выполнялся таким образом, что сначала создавались оба объекта my_class(), потом они сравнивались, а только лишь после выполнения is они оба удалялись (т.е. два экземпляра my_class жили в одно время и физически не могли иметь 2 одинаковых id).
И еще немного
Изменение данных внутри кортежа
Создадим кортеж, который содержит в себе список, и попробуем расширить этот список, добавив новые элементы:
def test_list(): a = ([], 0) a[0].extend([1]) print("Применили extend: ", a) a[0].append(2) print("Применили append: ", a) a[0].insert(0,0) print("Применили insert: ", a) try: a[0] += [4] print("Применяем +=: ", a) except Exception as e: print(e) print("Итоговый кортеж:", a) test_list()Вывод:
Применили extend: ([1], 0) Применили append: ([1, 2], 0) Применили insert: ([0, 1, 2], 0) 'tuple' object does not support item assignment Итоговый кортеж: ([0, 1, 2, 4], 0)Очень забавная ситуация, кортеж выкинул ошибку, однако список все равно был расширен. Аналогично будет себя вести пример со словарями ( оператор |= — был добавлен в версии 3.9).
def test_dicts(): a = ({}, 0) a[0]["cat"] = 100 print("Изменяем словарь: ", a) a[0].update([("dog", 200)]) print("Применили update: ", a) a[0].update({"bird": 50}) print("Применили update: ", a) try: a[0] |= {"lion": 200} print("Применили |=: ", a) except Exception as e: print(e) print("Итоговый словарь: ", a) test_dicts()Вывод:
Изменяем словарь: ({'cat': 100}, 0) Применили update: ({'cat': 100, 'dog': 200}, 0) Применили update: ({'cat': 100, 'dog': 200, 'bird': 50}, 0) 'tuple' object does not support item assignment Итоговый словарь: ({'cat': 100, 'dog': 200, 'bird': 50, 'lion': 200}, 0)Создание таблицы
Допустим, необходимо создать таблицу (матрицу, двумерный массив) с данными и поменять в нём первый элемент:
def test_list_2(): row = ["_"] * 3 table = [row] * 3 print("Создали таблицу:\n",table ) table[0][0] = "X" print("Изменили первый элемент:\n",table ) test_list_2()Вывод:
Создали таблицу: [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']] Изменили первый элемент: [['X', '_', '_'], ['X', '_', '_'], ['X', '_', '_']]Поменялся не только самый первый элемент таблицы, но и первые элементы в каждой строке. Если использовать инициализацию таблицы путем умножения одного списка, то каждая строка таблицы будет содержать один и тот же список (ссылаться на один список row).
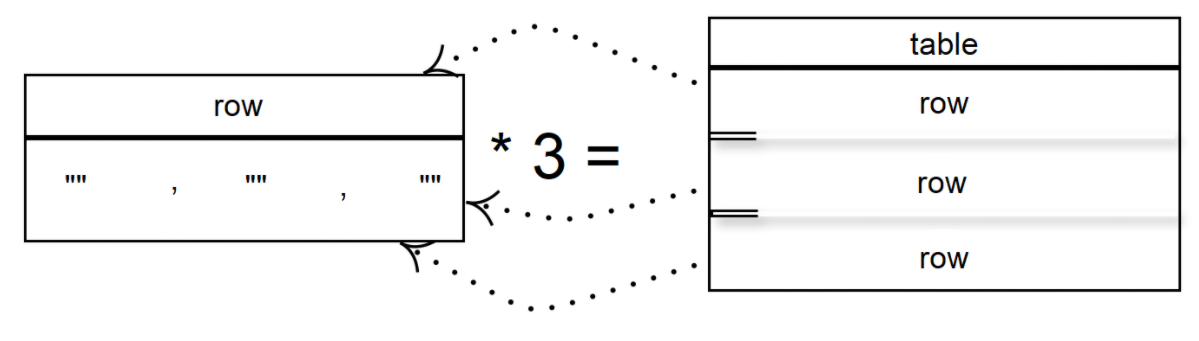
Убедиться в этом можно, выполнив следующий код:
for table_row in table: print(id(table_row))Вывод:
1707508645824 1707508645824 1707508645824Метод all
Немного о методе all:
def test_all(): print(all([])) print(all([[]])) print(all([[[]]])) print(all([[[[]]]])) test_all()Вывод:
True False True TrueПочему так? all([]) — по определению выдаст True. Ситуация с all([[]]) объясняется тем, что для каждый элемент во внешнем списке приводится к булевскому значению (как известно, к False приводятся: ноль, пустая строка, пустой список и др.), поэтому внешний список содержит [], который интерпретируется как False. В all([[[]]]), внешний список содержит список, в котором есть список, а список с 1 элементов уже интерпретируется, как True, то есть all не проверяет вложенность списков.
Вывод
Все эти примеры довольно очевидны для опытного программиста, но иногда могут вводить в ступор, особенно, если приходится читать чужой код и пытаться найти в нём ошибку. Такого рода ошибки порождают массу проблем, если плохо разбираться в нюансах работы языка. Поэтому иногда стоит читать и изучать чужой код, изучать статьи по языку и читать документацию к работе методов, чтобы видеть и понимать, какие сюрпризы может преподнести язык. И не стоит забывать, используя два разных языка и описав в них одинаковые конструкции, они могут вести себя совершенно по-разному, потому что внутренняя реализация у каждого языка своя.
P.s. всё тестировал на Python 3.9 в стандартной IDLE. Картинка — кликбейт.
ссылка на оригинал статьи https://habr.com/ru/post/564804/
Добавить комментарий