Привет Хабр! Давно не писал! Сегодня определим позы нескольких людей с Mediapipe.
Существует множество доступных программ для оценки позы, таких как OpenPose , MediaPipe , PoseNet и т. Д. Хотя OpenPose и PoseNet могут поддерживать оценку позы нескольких человек в реальном времени, Mediapipe может поддерживать оценку позы только одного человека.
Современные подходы в основном опираются на мощные среды рабочего стола для вывода, в то время как метод Mediapipe способен обеспечить производительность в реальном времени на большинстве современных мобильных телефонов, настольных компьютеров и в Интернете(javascript).
Кое-что об оценке позы Mediapipe
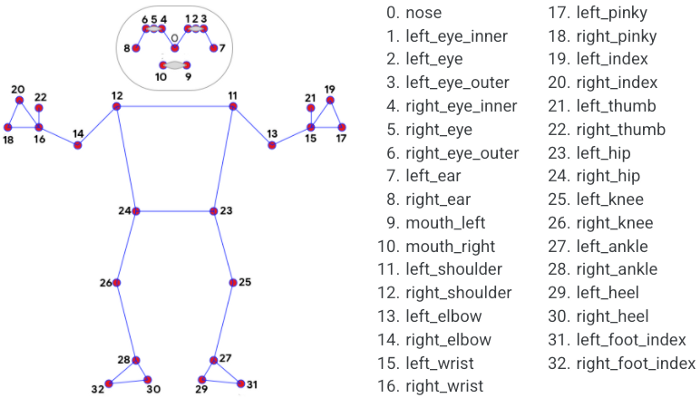
Функция MediaPipe Pose Landmark может извлекать 33 ключевые точки ориентира, как показано выше. Результатом является список ориентиров позы, и каждый ориентир состоит из координат ориентира x и y, нормализованных [0.0, 1.0]по ширине и высоте изображения соответственно.
Образец кода
import cv2 import mediapipe as mp mp_drawing = mp.solutions.drawing_utils mp_holistic = mp.solutions.holistic # For static images: IMAGE_FILES = [] with mp_holistic.Holistic( static_image_mode=True, model_complexity=2) as holistic: for idx, file in enumerate(IMAGE_FILES): image = cv2.imread(file) image_height, image_width, _ = image.shape # Convert the BGR image to RGB before processing. results = holistic.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) if results.pose_landmarks: print( f'Nose coordinates: (' f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x * image_width}, ' f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].y * image_height})' ) # Draw pose, left and right hands, and face landmarks on the image. annotated_image = image.copy() mp_drawing.draw_landmarks( annotated_image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS) mp_drawing.draw_landmarks( annotated_image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( annotated_image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( annotated_image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS) cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image) # Plot pose world landmarks. mp_drawing.plot_landmarks( results.pose_world_landmarks, mp_holistic.POSE_CONNECTIONS) # For webcam input: cap = cv2.VideoCapture(0) with mp_holistic.Holistic( min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic: while cap.isOpened(): success, image = cap.read() if not success: print("Ignoring empty camera frame.") # If loading a video, use 'break' instead of 'continue'. continue # Flip the image horizontally for a later selfie-view display, and convert # the BGR image to RGB. image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB) # To improve performance, optionally mark the image as not writeable to # pass by reference. image.flags.writeable = False results = holistic.process(image) # Draw landmark annotation on the image. image.flags.writeable = True image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) mp_drawing.draw_landmarks( image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS) mp_drawing.draw_landmarks( image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS) cv2.imshow('MediaPipe Holistic', image) if cv2.waitKey(5) & 0xFF == 27: break cap.release()Если мы намереваемся определить позы двух человек на фотографии или на видео, одним из возможных подходов было определение граничной рамки человека, наложить маску на картинку(как на нижнем рисунке), кроме граничной рамки человека, повторить это действие для других найденных людей, и по очереди дать картинку в mediapipe.

Обнаружение людей через YOLO v4
YOLO — это современная система обнаружения объектов в реальном времени. Что то еще надо дописать. Поскольку YOLO доказал свою высокую скорость и точность, его можно использовать для обнаружения объекта-человека. Реализацию YOLOv4 взял от сюда. И добавил в демонстрационный файл несколько строчек кода и вызывал эту функцию после детекции объектов:
# MediaPipe init. import mediapipe as mp mp_drawing = mp.solutions.drawing_utils mp_holistic = mp.solutions.holistic holistic = mp_holistic.Holistic(static_image_mode=True) def mdp_holistic(original_image, image): ''' MediaPipe Pose recognition. ''' results = holistic.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # cv2.imwrite('holistic_input.jpg', image) if results.pose_landmarks: # Draw pose, left and right hands, and face landmarks on the image. mp_drawing.draw_landmarks( original_image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS) mp_drawing.draw_landmarks( original_image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( original_image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS) mp_drawing.draw_landmarks( original_image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS) return original_image
Другое решение этой проблемы
Выше, для обнаружения людей, мы использовали нейронную сеть YOLO v4, которая не самая простая и легкая. Мы еще по экспериментировали с mediapipe, и нашли выход одновременно обнаружить несколько поз людей, используя только mediapipe. Она реализована на рекурсии и не использует сторонние нейронные сети, так что она легкая и простая.
Логика здесь такая, делаем копию входного изображения, находим позу первого человека, определяем максимум и минимум точки и закрашиваем этот прямоугольник, дальше ищем позу второго человека и т.д. В конце рисуем на оригинальной картинке.
import cv2 import time import mediapipe as mp import datetime mp_holistic = mp.solutions.holistic holistic = mp_holistic.Holistic(static_image_mode=True) mp_draw = mp.solutions.drawing_utils def holistic_recursive(origin_image, image, padding = 20, recursion_depth = 20): results = holistic.process(image) X , Y = [], [] h, w = image.shape[:2] person_detected = False if results.pose_landmarks: mp_draw.draw_landmarks(origin_image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS) for i in range(len(results.pose_landmarks.landmark)): X.append(results.pose_landmarks.landmark[i].x) Y.append(results.pose_landmarks.landmark[i].y) person_detected = True if results.face_landmarks: mp_draw.draw_landmarks(origin_image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS) for i in range(len(results.face_landmarks.landmark)): X.append(results.face_landmarks.landmark[i].x) Y.append(results.face_landmarks.landmark[i].y) person_detected = True if results.left_hand_landmarks: mp_draw.draw_landmarks(origin_image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS) for i in range(len(results.left_hand_landmarks.landmark)): X.append(results.left_hand_landmarks.landmark[i].x) Y.append(results.left_hand_landmarks.landmark[i].y) person_detected = True if results.right_hand_landmarks: mp_draw.draw_landmarks(origin_image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS) for i in range(len(results.right_hand_landmarks.landmark)): X.append(results.right_hand_landmarks.landmark[i].x) Y.append(results.right_hand_landmarks.landmark[i].y) person_detected = True if person_detected and recursion_depth > 0: # create bbox x1 = int(min(X) * w) y1 = int(min(Y) * h) x2 = int(max(X) * w) y2 = int(max(Y) * h) # Add padding x1 = x1 - padding if x1 - padding > 0 else 0 y1 = y1 - padding if y1 - padding > 0 else 0 x2 = x2 + padding if x2 + padding < w else w y2 = y2 + padding if y2 + padding < h else h # zero bbox image[y1:y2, x1:x2] = 0 # cv2.imwrite('crop.jpg', image) holistic_recursive(origin_image, image, recursion_depth - 1) cap = cv2.VideoCapture(0) # cap = cv2.VideoCapture('smeny-etsn-brigadoy-tkrs_Pxv28bmL_N5en.mp4') # Write video # w = int(cap.get(3)) # h = int(cap.get(4)) # fourcc = cv2.VideoWriter_fourcc(*'MP4V') # out = cv2.VideoWriter('output_recursive.mp4', fourcc, 10.0, (w, h)) start_time = time.time() frame_count = 0 fps = 0 while True: _, img = cap.read() img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # Recursive run detection image = img_rgb.copy() holistic_recursive(img, image) frame_count += 1 if frame_count > 20: fps = frame_count / (time.time() - start_time) start_time = time.time() frame_count = 0 cv2.putText(img, f'FPS: {int(fps)}', (10, 30), cv2.FONT_HERSHEY_PLAIN, 2, (255, 0, 0), 2) cv2.imshow("cam", img) # out.write(img) k = cv2.waitKey(1) if k == 27: # close on ESC key break # cap.release() # out.release() cv2.destroyAllWindows()


В этой реализации с помощью Mediapipe мы достигли позы с несколькими людьми. Надеюсь, вы найдете это полезным для работы или учебы.
Оценка позы человека из видео применяется в различных приложениях, таких как распознавание языка жестов и управление жестами всего тела. Существуют также применения в классификации последовательности движений при физической активности, такой как йога, упражнения и танцы, что позволяет количественно определять движения с помощью определения ориентиров на теле.
ссылка на оригинал статьи https://habr.com/ru/post/567534/
Добавить комментарий