В этой статье я расскажу о своем опыте внедрения Agile на DS проекте с нуля. Я расскажу по шагам что мы с командой пробовали использовать, к чему это привело, какие ошибки допускали и как мы в итоге пришли к стабильному, простому и понятному процессу разработки.
Контекст проекта и немного введения
Проект, с которым мне пришлось работать связан с определением объектов по камерам наблюдения на физических объектах (ресторанах). Нашей основной задачей было создание системы определения объектов и вывода необходимой информации на дашборде, а также мы осуществляли развертывание системы на объектах (более 1500) и поддержку пользователей.
Наша команда состояла из Data Science и Computer Vision специалистов, было несколько QA, один Frontend Developer и один Backend Developer. Я выступал в роли Project Manager.
Когда я только приступил к работе над проектом, там не было никакой документации, плана, отчетности и т.д. Все делалось на словах, что-то немного трекалось в Trello, это был тот еще хаос.
В этой статье я расскажу больше о процессе разработки. На проекте также был очень сложный процесс развертывания и поддержки пользователей. Этих процессов касаться в этой статье я не буду.
Этап 1. Начало внедрения Agile.
В самом начале моей основной целью было понять что вообще необходимо сделать, к какому сроку, кто чем занимается и что вообще есть сейчас.
В интернете я наткнулся на целую кучу различных статей о том, как выстраивать процессы в DS, но у всех были разные мнения: кто-то советовал Kanban, кто-то Scrum, кто-то описывал свои методики, но ничего общего я не нашел, не было ничего, что можно применить к любому проекту такого рода. Однако, самым ценным было знакомство с концепцией CRISP-DM
CRISP-DM.Концепция легко гуглится, но основная мысль понятна из графикеской схемы:

Как вы видите, из-за возможности возврата к предыдущим этапам, а также по причине того, что итоговый результат может оказаться все еще недостаточно хорошим мы не можем выдать заказчику точных сроков, что делает крайне сложным какое-либо планирование.
Вот какие задачи я поставил себе на самом первом этапе:
-
Определение всех требований к проекту
-
Определение текущего результата
-
Постановка конкретных задач команде
-
Оценка задач и формирование плана
-
Выбор процесса разработки
Вот что конкретно было предпринято на первом этапе:
-
Мы начали использовать Jira. Пришлось обучать команду, так как никто не работал ранее с этой системой
-
Мы создали Kanban доску со стандартными этапами, как To Do, In Progress, Test, Done
-
Я описал все требования команде и совместно с командой мы поставили первые задачи, сформировали бэклог продукта. Пришлось все уточнять у команды, так как было совершенно не понятно что уже реализовано и как конкретно реализуется то или иное требование инструментами DS и CV
-
Оценили с командой задачи в днях и согласовали со стейкхолдерами дедлайны
-
Сделали совместные чаты и т.д., чтобы коммуникация наконец-то было централизована.
-
Начали проводить общие митинги каждый понедельник и синхронизироваться.
-
Все же решили попробовать использование Scrum, после чего я отправился настраивать доску и подготавливать тренинг для команды.
С какими основными проблемами мы столкнулись:
-
Постановка задачи в виде User Story или просто описания бизнес-требования плохо понятна команде, вызывает неправильные ожидания у заказчика и внутри задачи было сложно учесть какую-то смежную работу, как сбор и разметка данных и т.д.
-
Команда очень слабо работала с Jira. Всегда приходилось двигать таски и актуализировать доску насильственно…
-
Цикл выполнения задачи был очень большой из-за очень общей задачи и мог занимать до 3 месяцев
-
Спустя месяц работы над задачей команда могла понять, что не успеет в сроки, так как модель плохо обучена или данные были не те и т.д. и всегда приходилось сильно двигать сроки, так как еще одна итерация могла занимать до 2 месяцев
-
Деплой проекта на объекты был крайне хаотичен, делался по требованию и постоянно возникали проблемы
Мы проанализировали эти проблемы и решили попробовать Scrum (как ни странно, тогда это звучало логично)
Этап 2. Scrum
Перед тем, как начать разработку по Scrum, я внимательно пересобрал общий бэклог проекта, описал его в формате обычных Tasks и User story, приоритезировал его.
На самом старте в нашей Scrum доске были все те же колонки To Do, In Progress, Test, Done
Мы с командой провели первый планинг в ходе которого обсудили бэклог и еще раз проговорили принцип работы по Scrum. В ходе планирования у нас получилось следующее:
-
Обсудили процесс CI/CD и решили добавить UAT окружение.
-
Добавили соответствующий статус на доске — UAT
-
Оценили задачи в story points
-
Поставили задач на спринт
-
Проговорили правила работы и ответственность
После завершения нескольких спринтов оказалось, что мы каждый спринт закрываем совершенно разное количество SP: 26, 62, 28 (например)
После очередной ретроспективы мы решили начать разбивать текущие задачи на гораздо более мелкие, так как многие задачи требовали более 2 недель на полноценное решение.
После этого мы провели еще спринта 3. Мы пытались формулировать эти задачи иначе, разбивать на связанные задачи и т.д.
В результате нам удалось добиться какой-то стабильности, но выполненные задачи не несли какой-то конечной ценности и в результате спринта мы не получали релиз, мы получали просто набор выполненных задач.
Мы решили предпринять еще одну попытку и просто увеличить продолжительность спринта до 1 месяца, но ситуация изменилась не сильно + начали приходить срочные задачи, которые не могли ждать 1 месяц и нам приходилось нарушать наш план.
И мы собрались для полноценного анализа ситуации в ожидании найти какое-то радикальное решение, которое нам поможет.
Мы увидели, что нам невозможно в принципе закрывать задачи спринтами, так как работа над, например, новой моделью для определения факта оплаты клиентом может занять до 3 месяцев, при этом потом нам все равно придется вернуться к этой задаче, переобучить модель и т.д. Запихнуть это в спринт невозможно.
В результате мы решили перейти к Kanban и попробовать эту практику
3. Kanban
Итак, Канбан! За основу построения процесса разработки мы взяли LeanDS
Ссылку на книгу вы можете найти в интернете.
Я сделал новую доску и указал там следующие этапы:
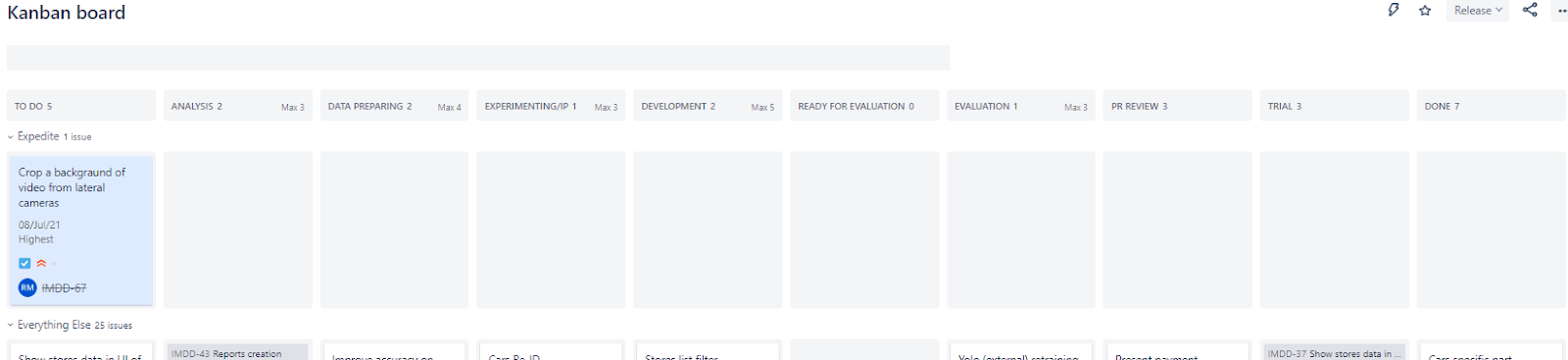
To Do, Analysis, Data Preparing, Experimenting, Development, Ready for Evaluation, Evaluation, PR review, Trial, Done
Я установил на каждом этапе ограничения (WIS), которые указал в соответствии с количеством членов команды, задействованных на том или ином этапе
Также я пересмотрел бэклог и разбил работу над моделями на гипотезы, другие задачи остались по прежнему в User stories. Бэклог еще раз приоритезировали.
Пример Гипотезы:
Мы полагаем, что решим проблему появления машин-призраков на всех объектах. Для этого мы будем определять местонахождение каждой реальной машины в текущий момент времени. Мы окажемся правы, если в ситуациях, вызывающих появление гост каров сейчас, они не будут появляться и если количество обращений с ресторанов об этой проблеме снизится хотя бы на 50%
После всех приготовлений мы с командой провели Kanban планирование и договорились работать в соответствии с правилами и идеологией Kanban. Выбрали первые задачи и начали работу
Результат колоссально отличался от того, что было раньше и это стало выглядеть многообещающе:
-
Мы могли брать супер срочные задачи и выполнять сразу же
-
Мы сразу смогли увидеть на каком этапе у нас застревают задачи
-
Мы стали понимать как лучше распределить ресурсы
-
Задачи стали активнее переходить по воронке, так как команда смогла лучше сконцентрироваться на конкретных задачах и стала больше помогать друг другу
-
Мы стали выпускать фичи сразу же после готовности и это еще больше устраивало заказчика, а нам позволяла упростить развертывание (как минимум процесс согласования) и анализировать влияние тех или иных фич независимо друг от друга.
Прошло еще около 2-3 недель, процесс стабилизировался, мы стали замечать как и где можно расширить узкие горлышки в процессе. Начали применять решения и постепенно еще больше ускорять разработку.
Например, решили централизовать сбор данных, выделить для этого отдельную группу и заготавливать некоторые типы данных на постоянной основе, чтобы всегда были свежие датасеты для переобучения старых или обучения новых моделей.
Таким образом мы пришли к идеальному формату работу для нашей команды.
Я постарался кратко изложить саму суть, без описания лишних деталей и воды, а также показать почему мы принимали те или иные решения и к чему это привело. Надеюсь, эта статья будет вам полезна и поможет в вашей практике.
P.S. очень рекомендую прочитать книгу LeanDS менеджерам или Data Science инженерам, так как это сильно прокачает как минимум какие-то аспекты ваших процессов.
ссылка на оригинал статьи https://habr.com/ru/post/567888/
Добавить комментарий