Итак, в 2021 год мы вступили со следующей архитектурой:
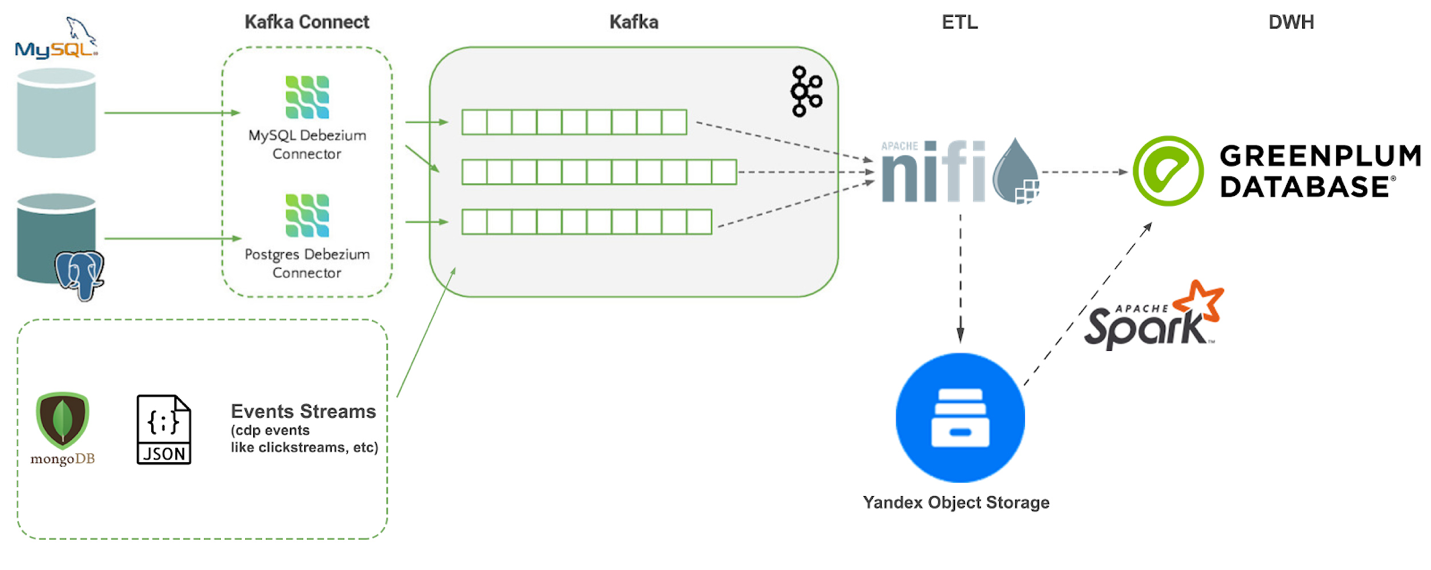
У нас есть DWH, в который мы различными путями укладываем CDC поток с большого количества источников, который обрабатываем с помощью процедур, запускаемых через Airflow и формируем DDS и витрины. Также у нас есть DataLake на S3, в котором лежит сырьё.
Мы добавили возможность работать с CDC нереляционных баз, таких как Mongo (тоже с помощью Debezium выгружали их в Kafka), начали обрабатывать канонические объекты – это, по сути, такие структурированные данные по строго принятым в компании схемам. Также мы добавили возможность работать с event streams, такими как clickstreams с онлайн-площадок, или эвентами CDP (customer data platform). После этого мы собирали их в формат parquet с помощью NiFi и выгружали в Yandex Object Storage, после этого с помощью Spark парсили и загружали в GreenPlum (через PXF).
Точки роста
Двигателем нашей платформы являются наши пользователи: дата-инженеры, аналитики и дата-сайентисты. Без них, вся наша польза для бизнеса имела бы отрицательную стоимость. Поэтому, в первую очередь, мы собрали от них фидбек о нашей работе.
Пользовательский опыт
-
Оперативные отчеты
Самая частая просьба пользователей – дать им возможность строить отчеты на основе оперативных данных. Данных за прошедший день уже было недостаточно для адекватной оценки бизнес-процессов, появился запрос на показатели, близкие к реальному времени.
-
Сложность интеграции
Боль пользователей была в необходимости создавать CDC на стороне источников, проливать данные в Kafka, коммитить в CI DDL GreenPlum’а, рисовать в NiFi ETL процессы. При этом, некоторые пользователи не умели даже работать с GIT’ом, не говоря уже о разработке в локальном докере, запуске тестов в пайплайнах, DAG’ах Airflow и прочем.
-
Время обработки запросов
«Вчера мой SQL запрос обрабатывался 30 секунд, а сегодня уже 10 минут» – с такими словами начали приходить пользователи. Причина была простая – несмотря на то что у GreenPlum есть разграничения ресурсов по ресурсным группам и очередям, пользовательские запросы все равно замедлялись под большой нагрузкой, когда на кластере работали тяжелые ETL-процессы.
-
Прямые запросы (DirectQuery)
Пользователи хотели получить возможность подключать свои BI-инструменты в режиме Direct Query. По сути, каждый дашборд может генерить свои запросы к источнику данных, а мы на GreenPlum ограничиваем количество подключений каждой учетки. В итоге их дашборды просто не прогружались. Можно было объяснять пользователям специфику работы GreenPlum, говорить, что это аналитическое хранилище, которое работает определенным образом. Но мы сами понимали, что платформе нужно развитие.
Административный опыт
Но не только у пользователей возникали проблемы — нам как владельцам платформы тоже было важно экономить свое время, находить точки роста и оптимизировать нашу работу.
-
Ресурсы
У нас получилось достаточно ресурсоемкое решение – кластеру порой приходилось обрабатывать порядка 150 млн CDC-событий за запуск процедуры, а это занимало иногда до 4 часов. Время деградировало из-за накопленной истории. Партиционирование, конечно, помогало до определенного момента, когда количество тяжелых источников в платформе не стало исчисляться несколькими десятками.
Также из-за того, что пользователи могли ходить в ODS-слои и рассчитывать на них дашборды, нагрузка на кластер все больше и больше росла. Решением могло стать создание большого количества витрин. Но мы за подход Data mesh во всем бизнесе, мы не хотим становиться единым центром компетенций, а хотим, чтобы вся компания трансформировалась и развивалась в направлении работы с данными. Но при этом свободных рук дата-инженеров во всех направлениях (доменах) компании постоянно не хватало.
-
Контроль
Пользователи наши друзья, и мы стараемся им во всем помогать. Но, не имея должного опыта работы с GreenPlum, не зная его специфики, невозможно написать оптимальный запрос. Поэтому в кластере бежало большое количество кривых запросов, нам же было тяжело их отлавливать, так как в минуту пробегало порядка 2 тысяч запросов. Плюс каждый пользователь подключался со своей локальной машины – кто из DBeaver, кто из PGAdmin, а кто своими питоновскими скриптами.
-
Платформенность
По нашим наблюдениям, GreenPlum в компании стал синонимом дата платформы. Если не работает он – ничего не работает: отчетность, дашборды, построенные на данных сервисы. Мы поняли, что нам нужно развивать наше решение и эволюционировать, не закупая новое железо под GreenPlum или заказывая виртуалки, а оптимизируя процессы загрузки и выгрузки данных, упрощая процедуры процессинга и работы с данными.
В итоге мы решили сфокусироваться на создании оперативной отчетности и контроле за действиями пользователей. Эти задачи мы решили с помощью 2х новых компонентов архитектуры.
Апдейты 2021
Операционная аналитика на Flink

В начале, чтобы удовлетворить самую большую потребность пользователей (в операционных данных), мы решили создать новый сервис, который назвали «Операционная аналитика». Построили мы его на базе Flink (фреймворк потоковой обработки данных). Начиная с версии 1.11 с июля 2020 года в нем появился функционал для работы с CDC потоками, как-раз генерируемых Debezium.

Также в версии 1.12 у Flink появилась возможность работать с CDC+Avro и со схемами, хранящимися в Confluent Schema Registry.
В результате выполнения простых запросов на потоке можно получать постоянно обновляющиеся counter’ы. Мы проверили этот формат работы, он показал прекрасные результаты, и то, что на GreenPlum считалось часами, мы могли уже считать на потоке с помощью Flink, еще и в режиме near-realtime. Кейс этот очень нужный, так как, например, показатели по товарообороту бизнес интересуют с минимальной задержкой.
При этом не все было так гладко. С какими трудностями мы столкнулись при работе Flink с построением операционной аналитики? Минусы операционной аналитики на Flink:
-
Один источник – один топик
У нас в Kafka данные хранятся таким образом: один источник – один топик. То есть по большому количеству таблиц в одном источнике используется один топик. И если нам необходимо в Flink посчитать данные только на одной таблице для одного источника, нам приходится читать весь поток по источнику.
-
Нет метаданных по Debezium
Следствие предыдущего минуса – в текущей версии Flink невозможно получить метаданные из полей Debezium. То есть невозможно сейчас точно определить имя таблицы, считав имя сообщения из Kafka CDC потока. Ждем фикс.
-
Ограничения генерации схем
Если вы работаете с данными в avro, но не используете schema registry, а храните схему в заголовках сообщений, на текущий момент Flink не может генерировать схему на основе этого заголовка – необходимо в таком случае схему задавать заранее.
Несмотря на эти недостатки, мы выявили для себя много плюсов операционной аналитики на Flink:
-
Near-realtime данные на CDC потоках
Скорость позволяет давать возможность пользователям производить обработку данных в режиме близкому к реальному времени.
-
Поддержка SQL
Пользователи могут считать каунтеры, написав запросы на FlinkSQL – им не нужно изучать ни Scala, ни Java, никакие другие языки программирования, кроме SQL.
-
Стабильность
Flink – решение, которое существует на рынке давно. Возможность его кластеризации и контейнеризации позволяют нам строить отказоустойчивые HA-решения при правильном использовании savepoint’ов и checkpoint’ов.
-
Настоящий стриминг
В отличии от Спарка – у флика т.н. “true”-streaming, а не микро батчи, что как раз и позволяет ему работать с потоками CDC.
-
Поддержка Avro Confluent schema registry
Из коробки можно подключится к Confluent Schema Registry и забирать схемы сообщений из него:
FlinkSQL
CREATE TABLE test1( `event_time` TIMESTAMP(3) METADATA FROM 'timestamp' VIRTUAL, `lSequenceNumber` INT, `Date` STRING, `RequestType` STRING, `TransactionDate` STRING, `TransactionTime` STRING, `Amount` DECIMAL(10, 4) ) WITH ( 'connector' = 'kafka', 'topic' = 'data.init.database.avro.test', 'properties.bootstrap.servers' = kafka0:9092,kafka1:9092,kafka2:9092, kafka3:9092,kafka4:9092', 'properties.group.id' = 'flink-group-test1', 'properties.security.protocol' = 'SASL_SSL', 'properties.sasl.mechanism' = 'SCRAM-SHA-256', 'properties.sasl.jaas.config' = 'org.apache.kafka.common.security.scram.ScramLoginModule required username="***" password="***";', 'properties.ssl.truststore.location' = '/home/client.truststore.jks', 'properties.ssl.truststore.password' = '***', 'scan.startup.mode' = 'earliest-offset', 'value.format' = 'debezium-avro-confluent', 'value.debezium-avro-confluent.schema-registry.url' = 'sr0:8081' );-
Удобный и подробный мониторинг
Для отслеживания состояния джоб флинк предоставляет подробный интерфейс мониторинга (кмк более простой в освоении, чем интерфейс спарка):

-
Большое число коннекторов.
За время существования Flink’а, для него было написано множество source и sink коннекторов, что позволяет реализовывать в своих ETL процессах интеграцию со множеством решений. Как пример можем привести clickhouse-sink коннектор, от коллег из ivi, который позволяет укладывать данные напрямую в CH.
Сравнивать Spark с Flink в контексте нашей задачи бессмысленно, т.к. killer-фичей для нас оказалась возможность работать с CDC потоками, чего не умеет делать спарк из коробки.
В итоге на данный момент мы имеем следующую структуру для near-realtime аналитики:
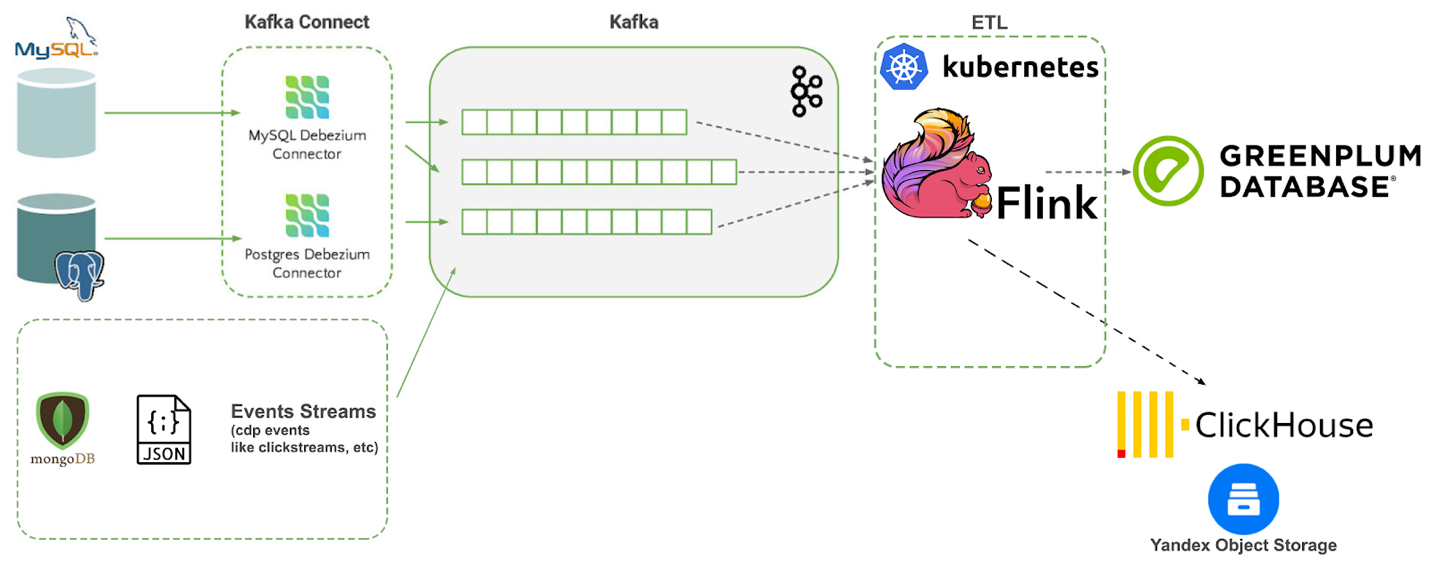
ETL для оперативных данных мы заменяем на Flink, развернув его в Kubernetes, данные по операционной аналитике мы загружаем в Yandex Object Storage с CH над ним.
Пользовательский опыт на Apache Superset

Мы внедрили Apache Superset – быстрый, легкий, интуитивно понятный веб-интерфейс для работы с данными и написания SQL-запросов. Он позволяет писать эти запросы к огромному количеству источников и визуализировать их в графиках и дашбордах.
Когда мы развернули его, мы нашли несколько недостатков:
-
Кодировка UTF-8
С кодировкой UTF-8 русские символы неправильно кодировались при выгрузке в CSV, и отображались т.н. краказябры. В текущей версии (1.2.0) это уже исправлено.
-
Неинтуитивные ограничения
Большое количество непонятных параметров в конфигах по ограничениям на количество обрабатываемых и выгружаемых строк. По данной проблеме заведен issue в github.
-
Сложность подключения проприетарных источников
Проприетарные источники (Oracle, DB2) не так легко подключить, нужно ставить драйвера и пакеты. Например для Oracle в requirements-extra.txt:
cx_Oracle==8.2.0
и в Dockerfile
ADD https://download.oracle.com/otn_software/linux/instantclient/1911000/instantclient-basic-linux.x64-19.11.0.0.0dbru.zip /lib/oracle_instantclient_basic.zip ADD https://download.oracle.com/otn_software/linux/instantclient/1911000/instantclient-sqlplus-linux.x64-19.11.0.0.0dbru.zip /lib/oracle_instantclient_sqlplus.zip ADD https://download.oracle.com/otn_software/linux/instantclient/1911000/instantclient-sdk-linux.x64-19.11.0.0.0dbru.zip /lib/oracle_instantclient_sdk.zip ENV LD_LIBRARY_PATH="/lib/instantclient_19_11:${LD_LIBRARY_PATH}" RUN export PATH=$PATH:/usr/local/instantclient/bin && \ unzip /lib/oracle_instantclient_basic.zip -d /lib/ && \ unzip /lib/oracle_instantclient_sqlplus.zip -d /lib/ && \ unzip /lib/oracle_instantclient_sdk.zip -d /lib/ && \ echo /lib/instantclient_19_11/ > /etc/ld.so.conf.d/oracle-instantclient.conf && \ ldconfig-
Требуются частые обновления
Продукт активно развивается, появляется новый функционал, приходится довольно часто его обновлять. Но мы уже несколько раз столкнулись с проблемой, когда при обновлении и добавлении новых фич, ломается старый функционал. Но это open source, приходится либо ждать исправления, либо править самим.
Но плюсы перекрыли все эти недостатки:
-
Единая точка входа
У нас появилась единая точка входа в платформу, появился контроль за пользователями и количеством их подключений, за написанными запросами. Нам в этом помог функционал user impersonation – когда пользователь заходит в Superset со своей LDAP учеткой, он, авторизовавшись однажды, получает доступ ко всем источникам под своим юзером.
-
Много источников
Нас интересовали в первую очередь GreenPlum, ClickHouse и Postgres. GP/PG работают из коробки, а для CH необходимо добавлять зависимости в requirements-extra.txt:
clickhouse-driver>=0.2.0
clickhouse-sqlalchemy>=0.1.6
и настроить свои URL подключения к CH в формате:
clickhouse+native://<user>:<password>@<host>:<port>/<database>[?options…]
Подробнее прочитать, как подключить Clickhouse к Supeset можно почитать тут. Но у него также есть коннекторы к Presto, Dremio, Druid, Hive, BigQuery, Vertica, Teradata, Exasol и прочим.
-
Удобная архитектура и интеграция с LDAP
Архитектура Superset нам оказалась понятной, масштабируемой, хорошо ложится k8s. LDAP подключается с добавлением в requirements-extra.txt
python-ldap==3.3.1
и в конфиг superset/config.py:
-AUTH_TYPE = AUTH_DB +AUTH_TYPE = AUTH_LDAP + +AUTH_USER_REGISTRATION = True +AUTH_USER_REGISTRATION_ROLE = "LDAP_ROLE" + +AUTH_LDAP_SERVER = "ldaps://ad.ldap.contoso.com:636" +AUTH_LDAP_SEARCH = "OU=contoso,DC=com" +AUTH_LDAP_SEARCH_FILTER = '' +AUTH_LDAP_BIND_USER = "CN=account,OU=Accounts,OU=Data_Platform,DC=contoso,DC=com" +AUTH_LDAP_BIND_PASSWORD = "PASSWD" +AUTH_LDAP_UID_FIELD = "sAMAccountName" +AUTH_LDAP_USE_TLS = False +AUTH_LDAP_ALLOW_SELF_SIGNED = False-
Множество визуализаций
Начиная с версии 1.0.0 superset переехал на Apache Echarts c D3, появилось большое количество новых визуализаций. А кому не хватает встроенных, есть возможность создавать свои Viz плагины.
-
Интеграция с DataHub
У DataHub есть интеграция автообновляемой меты с суперсетом — он может подтягивать список чартов и дашбордов.
-
Удобство использования
Вот так выглядит пользовательский интерфейс (SQL Lab) для написания запросов в Superset:

Он похож на обычные SQL IDE. Но, например, есть функционал для шаринга запроса, то есть пользователи могут сохранять запрос и делиться им с коллегами. Также есть выгрузка в csv, шедуллинг и множество других “плюшек”.
-
Админский интерфейс
В интерфейсе администратора мы видим запросы каждого пользователя, количество отгруженных строк, сам код запроса, время выполнения – в одном месте и по каждому пользователю:

-
Удобный API
Как вишенка на торте – API у Superset позволяет нам как инженерам автоматизировать все обслуживание и применять CI/CD для пайпланинга выкатки и работы с ролями, пользователями и группами, чартами и дашбордами и т.д.

Мы также провели сравнение с конкурентами по критичным для нас показателям:
|
Criterio |
|||||||||
|
Freeware |
Yes |
Partially |
Yes |
Yes |
No |
Yes |
Yes |
No |
No |
|
Cost |
— |
High |
— |
— |
Low |
— |
— |
High |
High |
|
Navigation |
Yes |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Open-Source |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
No |
No |
|
Customization |
Python |
Clojure |
Python/Django |
Java |
Python |
Golang |
JS |
No |
No |
|
Security integration |
Yes |
Yes (requires enterprise) |
Yes |
So-so |
Yes |
Yes |
So-so (require proxy) |
? |
Yes |
|
Supported datasources |
Multiple (ODBC) |
Multiple (ODBC) |
Multiple (JDBC) |
PostgreSQL-compatible |
|||||
|
Data visualization |
Yes (rich) |
Yes |
Yes |
Yes |
Yes |
No |
Yes |
Yes |
? |
|
Cache |
+ |
— |
— |
||||||
|
GP Stability |
OK |
only BI — |
OK |
— |
So-So |
OK, but very very slow |
— |
— |
— |
|
Github commits/releases |
5* |
5* |
3*, half year last release |
4*, half year last release |
2*, 2019 last release |
4* |
4* |
? |
? |
|
Contributors |
616 |
261 |
2 |
338 |
354 |
44 |
61 |
? |
? |
Главными критериями выбора в пользу SS для нас оказались — разработка на Python, активность развития, большое коммьюнити, свободные security фичи (интеграция с LDAP), скорость работы с Greenplum.
Итоговая архитектура изменений платформы:
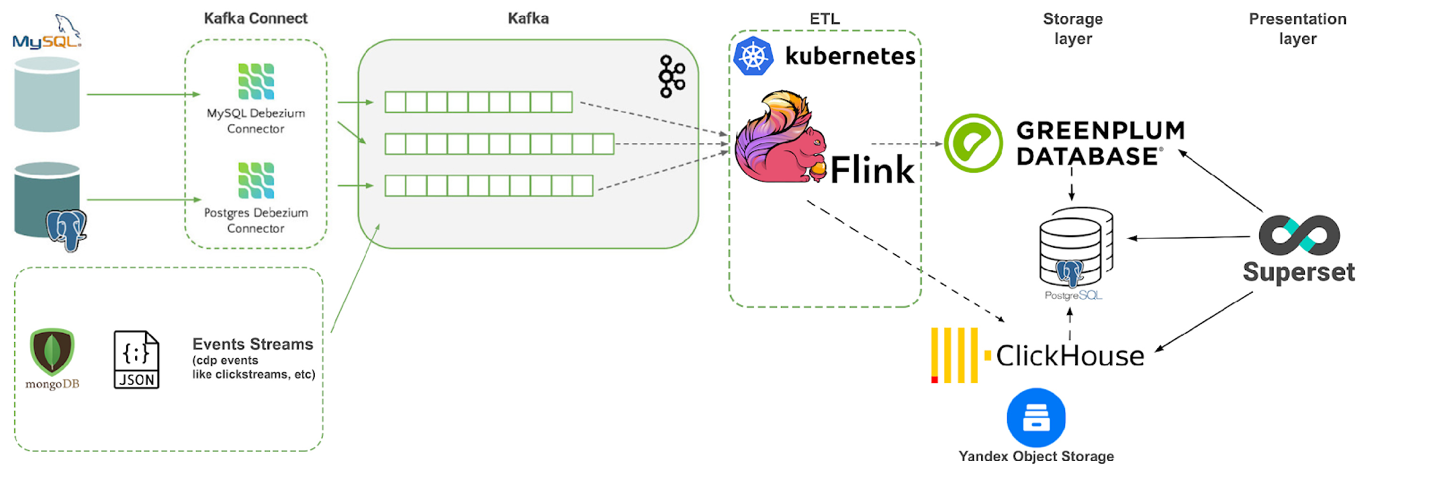
Появился презентационный слой – Superset (в k8s), слой хранения – GreenPlum (для аналитической отчетности) и ClickHouse (для операционной, с S3 Table Engine). Также мы в GreenPlum формируем витрины, выгружаем их в Postgres с помощью PXF и дополняем эти витрины оперативными данными. В Superset мы можем быстро получать данные и из Postgres и CH и строить на их основе оперативные дашборды.
Выводы
Если вы создали хорошую платформу, которая становится популярной и к которой подключается все больше и больше пользователей, но вы ее не будете развивать, есть вероятность, что через какое-то время (год-два) могут начаться проблемы с производительностью.
Во-вторых, на сегодняшний день хорошую, качественную и масштабируемую платформу можно строить на open source решениях в облаках. В open source есть большое количество продуктов, и необязательно сейчас покупать у вендоров шкафы железа за большие деньги.
Последняя мысль – сотрудники это самая большая ценность для компании, особенно той, которая хочет оставаться на передовой и внедрять технологии работы с данными. Грамотные специалисты могут провести RnD и запустить MVP буквально за пару недель.
В конце статьи хотелось бы анонсировать наше будущее выступление на Greenplum Community Meetup, которое пройдет 22 июля в 16:00 в формате онлайн:
https://cloud.yandex.ru/events/409
На нем мы расскажем про наш подход к observability и мониторингу Greenplum’а, про наши инструменты и инсайты, которые получаем от этого подхода. Записывайтесь, будет интересно!
В следующих статьях мы подробнее расскажем про опыт company-wide внедрения инструментов MLFlow, DVC и KubeFlow и опыт работы с ними.
ссылка на оригинал статьи https://habr.com/ru/company/leroy_merlin/blog/567874/
Добавить комментарий