Привет! Продолжаем делиться интересными выступлениями с митапов наших гильдий. Вслед за фронтендерами приходит очередь архитекторов. Митап 9 декабря открыл наш коллега Дмитрий Зыков с рассказом об автоматизации управления. Дмитрий Бардин из Croc Code продолжил выступлением об оценке модернизации. И завершил основную часть Егор Слесаренко из Leroy Merlin, поделившись опытом перестройки магазинов в локдаун с помощью composable architecture. Основные тезисы всех выступлений — в этом посте.

Автоматизация процессов управления архитектурой
В своем докладе я расскажу об автоматизации процессов управления IT-архитектурой, не только корпоративной, но и архитектурой в целом, о том, как мы развивали ее в Росбанке последние три года. Автоматизация позволяет сократить участие человека в процессах, сделать их более управляемыми и менее трудоемкими.
Вообще, какие признаки показывают, что нам нужно автоматизировать процессы управления архитектурой?
-
Высокая сложность архитектуры.
-
Отсутствие или недостаточная оптимальность формализованных процессов. Бывает, что сложившиеся регламенты организации не успевают за принятыми на рынке практиками, и здесь тоже помогает автоматизация.
-
Высокая сложность IT-ландшафта организации. Когда, предположим, на 700 систем выделено 10 человек, мы получаем очень большую нагрузку на каждого и связанные процессы нужно автоматизировать.
-
Необходимость обеспечения повторяющихся процессов без участия человека.
Какие задачи с помощью автоматизации мы стремимся решить в Росбанке?
-
Увеличить скорость разработки и обоснованность архитектурных решений. В бизнесе очень важно сокращать TTM, и при переводе бизнес-инициатив в IT архитектор часто становится боттлнеком, на котором сходятся все инициативы для всех систем. Нужно упрощать ему работу.
-
Оповещение об изменении ключевой информации по системам. Десятки систем могут включать сотни объектов, которые постоянно меняются. Стоит систематизировать ключевые изменения и настроить автоматическое оповещение для всех заинтересованных.
-
Создание прозрачной архитектурной модели. На базе репозитория мы создаем такую модель, публикуем ее, рассказываем о ней. Так упрощается анализ систем, управление ими, улучшается планирование по задачам.
-
Увеличение точности планирования и соответствия стратегическим планам. Открытые репозитории упрощают планирование, сопровождение и контроль реализации стратегии.
Результаты работы архитекторов полезны в компании очень многим. Кто и зачем их может использовать:
-
топ-менеджеры — чтобы лучше обосновывать решения и планировать переход бизнес-идей в IT-инициативы;
-
проектные менеджеры — чтобы проще планировать проекты, в том числе по бюджетированию;
-
тимлиды и технические руководители — чтобы лучше планировать задачи для команд, согласовывать интеграции между системами и командами;
-
аналитики — чтобы лучше анализировать задачи и согласовывать структуры данных;
-
проектные менеджеры — чтобы лучше управлять проектами.
С чего мы начали автоматизацию? С анализа метрик:
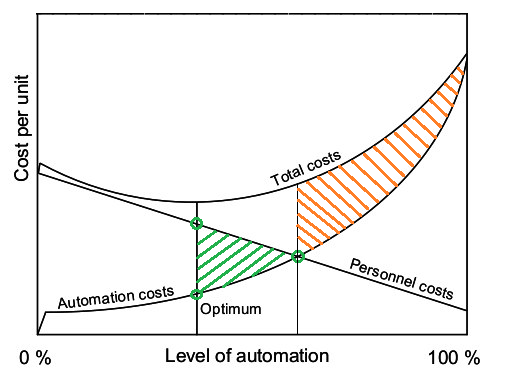
На графике выше показана зависимость стоимости автоматизации от ее уровня для разных направлений.
Как определить текущий уровень автоматизации? Мы взяли количество автоматизированных процессов в каждом направлении и разделили его на коэффициент сложности IT-ландшафта. Чтобы оценить ее, использовали принцип расчета цикломатической сложности по Маккейбу и метрики Чепина.
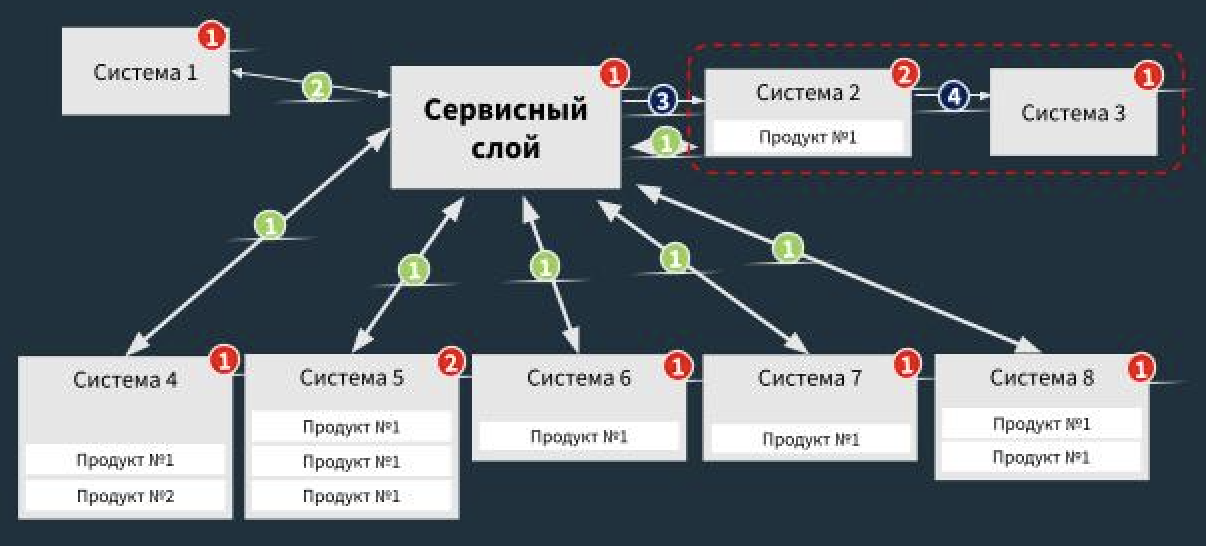
У Чепина каждый узел должен соответствовать определенной функции, а стрелки между узлами — параметрам результатов работы этих функций. В качестве узлов мы представили системы, а в виде стрелок представили интеграции. Каждый узел и связывающая стрелка имеет определенный вес, и через суммарный вес разных систем мы можем сопоставить их сложность.
Так мы оценили все наши системы — их примерно 800. Максимальный возможный вес всех систем приблизился к 1600 единицам. Среднее значение по банку — 754.
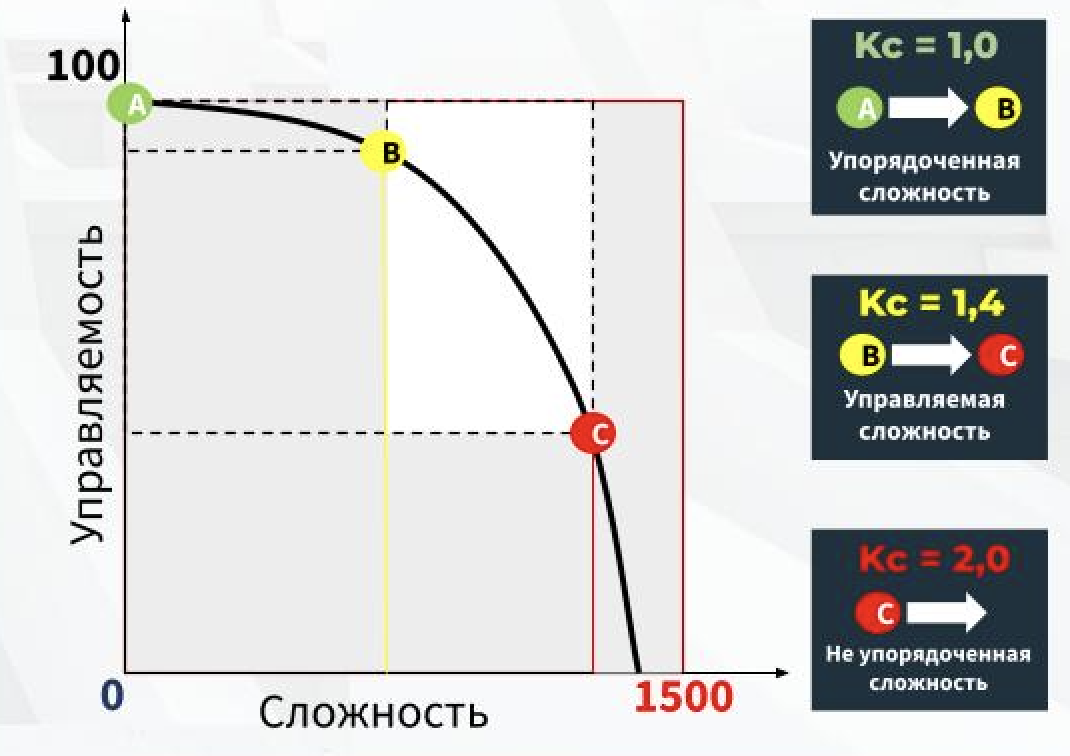
Оценив разброс значений сложности, мы построили общий график, на котором выделили три уровня сложности — упорядоченная, управляемая или неупорядоченная и неуправляемая. В целом наш IT-ландшафт находится на уровне управляемой сложности. Это значит, что нет необходимости все перестраивать, достаточно будет спланировать мероприятия по митигации рисков. Исходя из количества систем на каждом уровне сложности, по внутренней методике мы высчитали средний коэффициент сложности — 1,4.
Далее для расчета уровня автоматизации нам нужно вычислить Kpa — долю автоматизированных процессов в общем количестве процессов управления архитектурой банка. В целом мы абстрагировались до 22 процессов управления, и на старте было автоматизировано только 4 из них. Остальные требовали постоянного участия человека. Таким образом, Kpa составил 18,2%. Здесь есть референсная шкала ГОСТа от 0 до 100%, и в соответствии с ней наш уровень автоматизации был очень низкий (для примера, средний уровень автоматизации начинается от 35–40%). С учетом уровня сложности IT-архитектуры целевой Kpa мы обозначили на уровне 49%.

Далее мы проанализировали средства управления архитектурой. Выделили два базовых параметра и разложили по ним набор средств, в которых уже имели достаточный опыт. Идеальная для нас группа — с визуализацией и репозиторием, остальные комбинации мы исключили.
Затем мы оценили инструменты по стоимости. Пришли к выводу, что архитектурные инструменты достаточно дорогие и производить комплексную перестройку ландшафта в наших процессах для подтверждения гипотез не целесообразно. В итоге выбрали Adoit (Adonis) — он оказался самым доступным и при этом у нас уже использовался.
Сейчас мы занимаемся внедрением и интеграцией. Анализируем текущие процессы управления архитектурой, ищем места, где Adoit будет наиболее эффективен. Далее анализируем распределение артефактов по IT-ландшафту, согласуем изменения, мигрируем данные и разрабатываем механизмы реконсиляции. Системы иногда не могут работать с распределенными данными, и нам приходится копировать их в репозиторий, а затем синхронизировать с мастер-системами. Вот общая схема, которая решила все эти задачи:
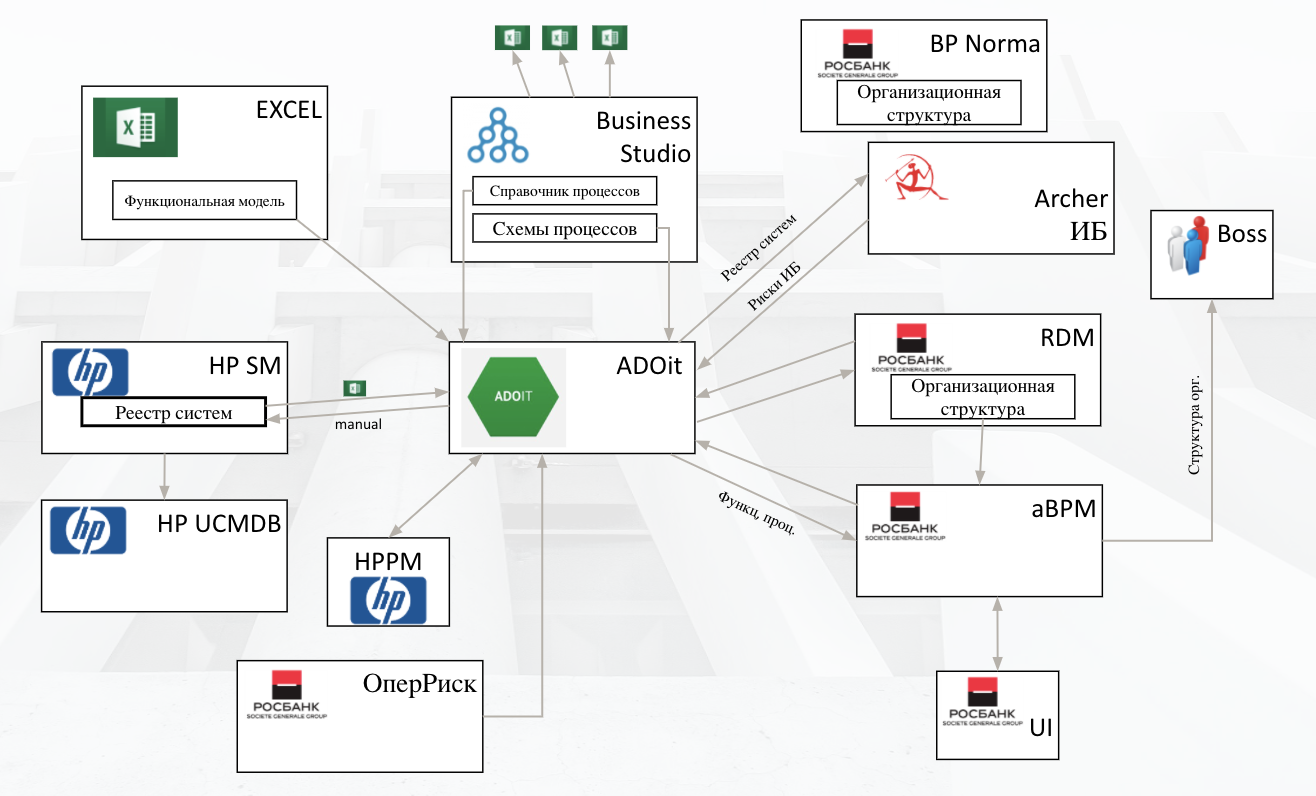
Такая реализация повысила полезность работы над архитектурой, снизила TTM (за счет сокращения времени выработки архитектурного решения), повысила удовлетворенность дата-бизнеса и позволила переиспользовать решения в репозитории, который взял функцию базы знаний. Также мы таким образом ускорили взаимодействие команд внутри банка. Коллеги активно заполняют архитектурный репозиторий, за 8 месяцев были описаны две трети процессов, примерно половина систем IT-ландшафта и интеграций, треть всех структур данных.
Перейдем к выводам:
-
Каждая автоматизация должна быть достаточно обоснована.
-
Уровень автоматизации — это измеримый и управляемый параметр. Эта метрика помогает оценить зрелость процессов и всей компании. Когда мы заполним весь архитектурный репозиторий, то сможем управлять всей архитектурой на уровне компаний, на основе базы знаний.
-
Автоматизация управления архитектурой ускоряет принятие решений и точность планирования. Время от генерации идеи до планирования проекта у нас сильно сократилось — и все за счет доступности и заполненности единого репозитория, куда под гостевым доступом может обратиться любой специалист.
А теперь — вопросы зрителей:
-
Говорят, сколько архитекторов, столько и архитектур. Как вы контролируете то, как они принимают у вас требуемые архитектурные решения? — Мы постоянно общаемся друг с другом и за счет этого приходим к единому пониманию, помимо того, что используем единый репозиторий.
-
Как контролируете контроль изменений архитектуры, когда их много? — Количество изменений отражено в стратегическом плане, их контроль является важнейшей задачей корпоративного архитектора, который управляет связанными рисками. Бесконтрольный поток изменений на уровне архитектуры допускать не стоит.
-
Кто принимает решения по стратегии развития IT-архитектуры? — У нас в компании это коллегиальное решение, мы собираем информацию со всех уровней в стратегический план и совместно принимаем решения, защищая их на уровня правления банка.
Сколько стоит второй шанс: как оценить модернизацию?
Все системы рано или поздно становятся легаси. Кому-то просто нужно переехать на новый фреймворк, а у кого-то в легаси попадает ядро всего бизнеса, будь то написанное в 90-х, 2000-х или вообще пару лет назад. Мой рассказ посвящен второй группе.
Сейчас практически у любого крупного, среднего бизнеса или государственной структуры есть системы, которые появились на заре автоматизации процессов в конкретном домене в конкретной организации. Постепенно они обрастали новыми функциями, подпирались костылями, чтобы соответствовать нормативке или чтобы успеть вывести новый продукт на рынок. Команды меняются, знания пропадают («ну а когда это все описывать»), техдолг растет. Сегодня рынок труда устроен так, что наем новых людей — это квест без гарантий результата.
IT-отдел постепенно становится слабым звеном, которое не закроешь совсем, но общаться лишний раз с ним никому не хочется. Доверия к своим уже нет, все понимают: пора. В этот момент либо зовут консультанта, либо нанимают свежую кровь и ставят задачу: «Придумай, как сделать, чтобы было хорошо и понятно, сколько это будет нам стоить».
Чтобы дойти до оценки, нужно пройти определенный путь. Я хочу рассказать один из возможных вариантов прохождения этого пути, разделив его на несколько блоков:
-
стоит ли что-то делать,
-
как делать,
-
как оценить,
-
что получим на выходе.
В итоге должна сложиться картинка: что получит бизнес в случае такого запроса к вам как к архитекторам и как вам пройти этот путь.

Представим типичный портрет проблемной системы — базу данных со множеством хранимых процедур, которые уже никто не помнит. Или интеграционное решение на хайповых технологиях 10-15-летней давности, которые сначала было обновлять некогда, а потом страшно. Это могут быть учетные системы, коробочные продукты, построенные на базе «открытых» технологий, с закрытым наглухо ядром 🙂 Для себя я вывел главный признак таких случаев: никто не понимает, что там, все боятся это трогать и тихо ненавидят. Нет adr, нет человека, который бьет по рукам и занимается развитием системы, нет ФС, хорошо, если остались какие-то ТЗ. В довесок имеем длинный техдолг в бэклоге.
Первый вариант развития — «большой взрыв». Все разрушить и сделать с нуля. Звучит здорово, и иногда только такой вариант возможен. Но с другой стороны, текущая система работает и приносит деньги. Если мы начнем пилить все с нуля, нет гарантий, что месяца через три финансирование с нашего биг бэнга не перенаправят на другой, более важный биг бэнг.
Более мягкий вариант — эволюция. Следует начать с as is, найти стейкхолдеров. Ведь если нет стейкхолдеров, то, может, нет и проблемы? 🙂 А далее понять риски, связанные с системой, посмотреть на IT-стратегию (если она есть), выписать боли (пока просто списком), узнать, как пытались решать проблемы и что не получилось. Обычно к моменту, когда зовут кого-то извне, свой IT-отдел потратил несколько миллионов рублей на эксперименты. Иногда в таких экспериментах уже был заложен правильный ход мыслей, но просто не хватило свежего взгляда и поддержки.
Неплохо здесь провести event storming и получить общее понимание от разных сторон, что и как «оно» умеет. Могут вскрыться «теневые» IT, когда системой по факту пользуются в самых крайних случаях. Или наоборот, у бизнеса окажется еще куча приемов «досчитать» то, что пока так и не осилила команда поддержки и развития.
На выходе должен получиться артефакт, понятный для бизнеса и технических специалистов. По этим данным систему можно отнести в какой-нибудь из квадрантов Гартнера в модели TIME:

Консультанты пригодятся, если система попадает в квадрант Eliminate (проще вывести из эксплуатации, чем поднимать) или в квадрант Migrate (критическая важность для бизнеса, но очень низкое техническое качество).
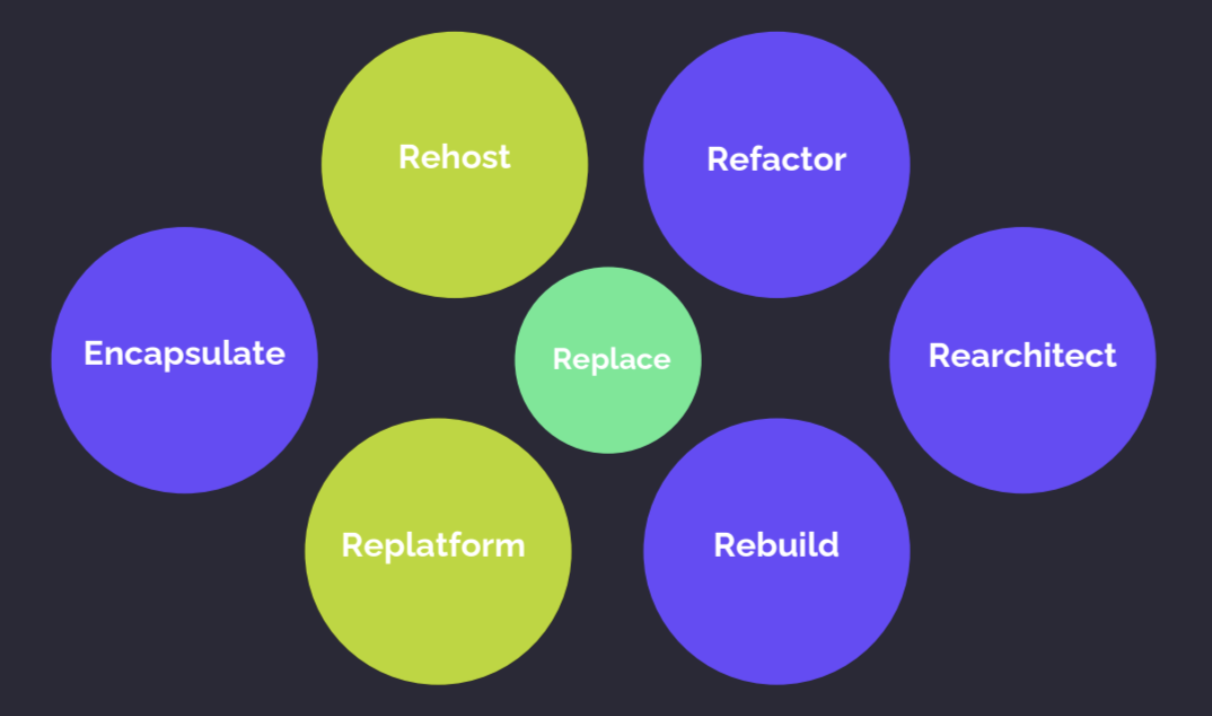
Теперь важно обосновать и зафиксировать дальнейший путь модернизации. Вариантов может быть много, я обычно использую вот эти семь:
-
Rehost, Replatform — обновляем инфраструктуру, обновляем техстек, насколько это возможно, делаем то, что не повлияет на кодовую базу.
-
Replace — ищем вендора, который решит нашу проблему своей системой.
-
Refactor — копаемся в системе и не трогаем контракты, чтобы никого не зацепить.
-
Rebuild — выкидываем все, кроме контрактов, воспроизводим функциональность заново.
-
Encapsulate — переносим решение в другую модель, например, сервисную.
-
Rearchitect — радикальный подход, меняем подход к архитектуре, например, пилим монолит.
Как выбрать решение? Нужно еще раз проанализировать информацию с предыдущего этапа, узнать ограничения по бюджетам, имеющиеся ресурсы. Сделать список критериев, весов и принять подходящий вариант.
Далее планируем, как пойдем по выбранному пути от as is к to be.

Вот, к примеру, анализ Replatform и близкого к нему Rehost. Как видно, это временное решение, но свои плюсы для бизнеса имеются. Для кейсов временных нагрузок типа черной пятницы — рабочий вариант.

Если идти по сценарию Replace, его недостаток в том, что решение тоже придется допиливать. К тому же всегда есть риск, что вендорское решение — это то же легаси, просто прикрытое более классной маркетинговой оберткой. Но вроде бы багов будет меньше, да и свои ресурсы разгрузим.

Наконец, рассмотрю Reachitect и Encapsulate, во многом схожие варианты. Первый — это по сути тот же большой взрыв, о котором говорили ранее. Encapsulate — более мягкий путь, здесь легаси может оставаться нетронутым годами, мы просто упаковываем его иначе, и он продолжает работать. Здесь также остаются риски с миграцией, со сроками и с дублированием данных. Но постепенно вы все равно сможете переехать на новые рельсы.
Затем начинаем оценивать реализацию. С Rehost и Replatform оценить несложно, работы здесь немного, считаем лицензии и умножаем. В Replace вообще считает сам вендор. Сложнее всего посчитать Rearchitect.

Вот общая схема расчета: берем ресурсы, факторы, влияющие на стоимость, пропускаем через Estimator и получаем готовые ресурсы. В случае с легаси важно дать нормальную оценку, бизнесу вряд ли понравится перспектива бесконечных спринтов или кругленькая сумма, взятая с потолка.
Чаще всего в оценках пользуются неалгоритмическими методами: собирают много экспертов и ждут от них вердикт. Недостаток здесь в том, что экспертная оценка на таких больших объемах работ бывает трудно воспроизводима, через некоторое время может быть сложно повторить ход мыслей экспертов. Кроме того, их оценка может кардинально измениться после просмотра выступления какого-нибудь другого эксперта.
Чтобы получить более уверенную оценку, неалгоритмические методы дополняют алгоритмическими. В качестве примера приведу метод Cocomo II, который появился еще в 80-х годах и проапгрейдился в нулевых. Создатель метода Барри Боуэн собрал большую статистику по проектам и посчитал коэффициенты, которые отражают разные стороны рабочих процессов.

Здесь для оценки конкретных уровней также можно приглашать экспертов, которые в соответствии с методологией считают все по строчкам кода.

Если выходит какая-то аномальная оценка, мы можем дополнительно воспользоваться методом функциональных точек, основанном на анализе ресурсов систем и их взаимодействии.
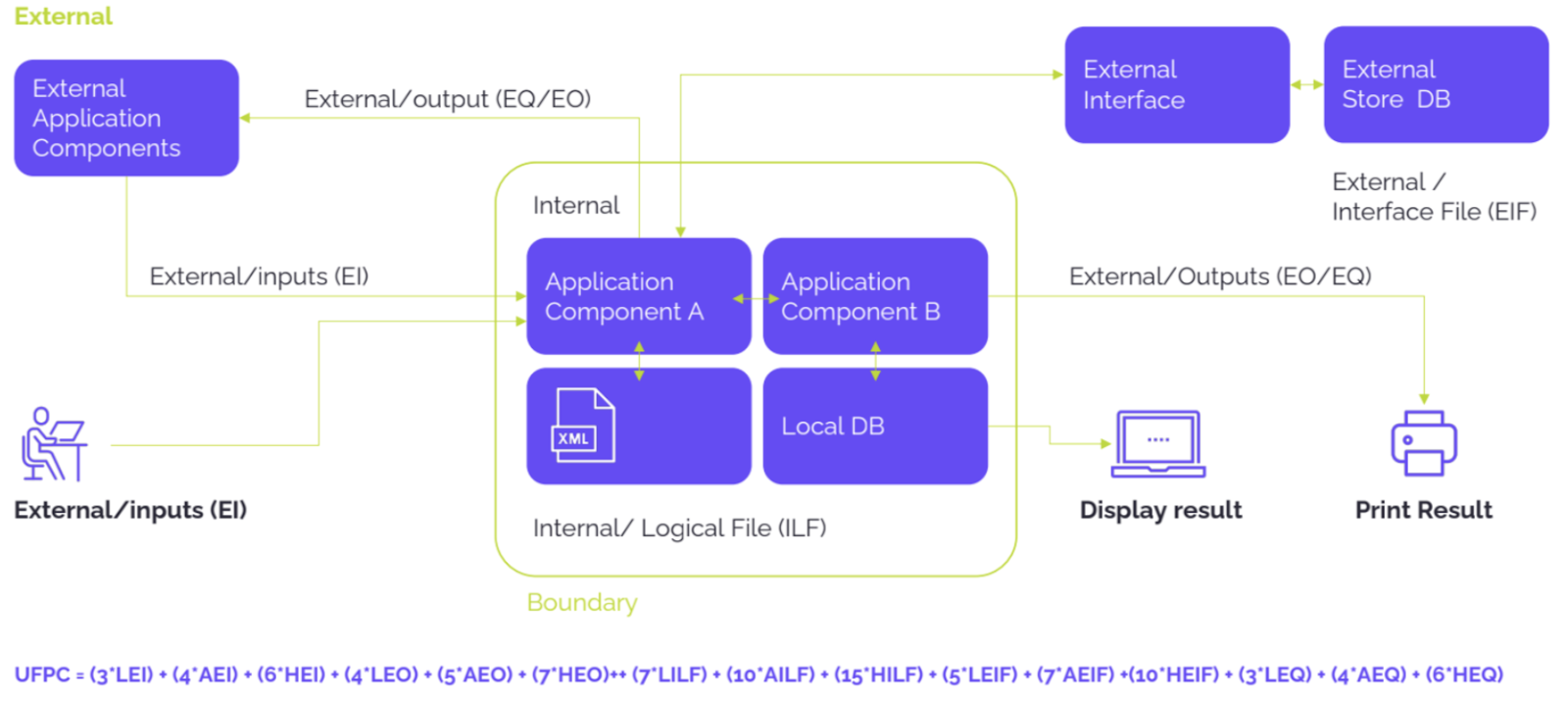
Полученное количество вы подставляете в калькулятор Cocomo II, который делает расчет в зависимости от того, какой язык программирования используется. Это дает более точную оценку, чем просто со строчками кода.

Далее мы фиксируем оценку и ее коэффициенты — на случай, если что-то захочется уточнить, поэкспериментировать, воспроизвести.
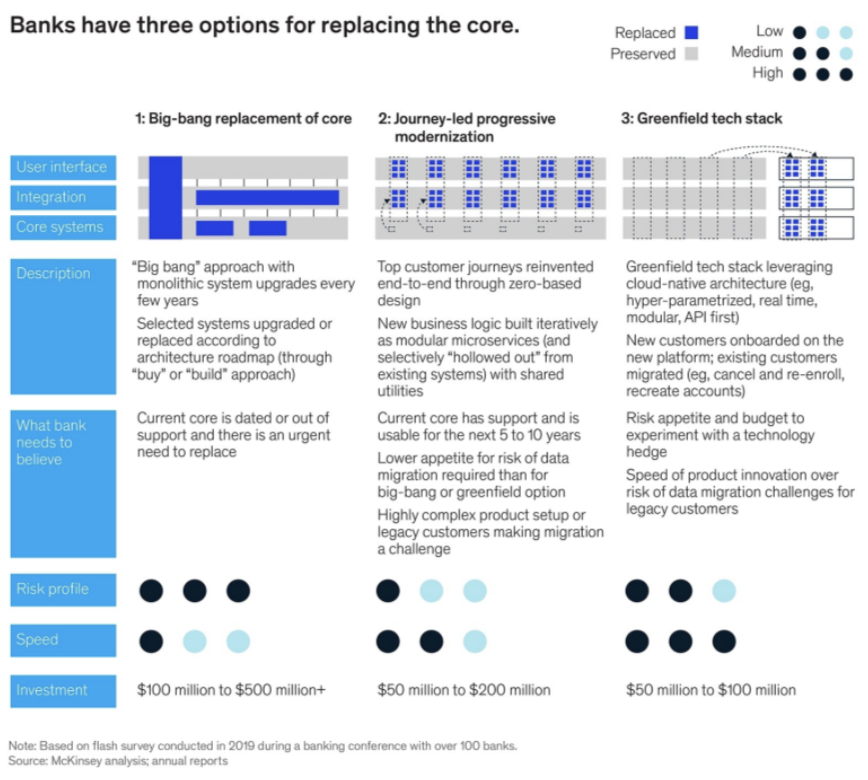
В финале мы представляем все в виде описания для бизнеса, оцениваем риски, скорость и затраты. На основе этого бизнесу может уже показывать возможные варианты. Мне нравится делать это по схеме McKinsey, как на иллюстрации выше.
Подведем итоги:
-
Не стоит слепо убивать легаси и начинать что-то новое. Новое можно и не успеть, а деньги все равно будут потрачены.
-
Информацию от стейкхолдеров и других нужно фильтровать и сопоставлять.
-
Оценки на больших объемах работ в чистом виде не работают
-
Главный посыл: не доводите системы до состояния, когда нужно звать археолога или патологоанатома.
Как архитектура помогла перенастроить магазины «Леруа Мерлен» в локдаун
Вот уже несколько лет «Леруа Мерлен» движется в сторону платформенной модели, то есть переходит от разрозненных контактов клиента с магазином для покупки отдельных материалов к непрерывному сопровождению на всех этапах ремонта или строительства. С точки зрения IT-систем это означает запуск множества сервисов, оркестрацию процессов, построение композитных сервисов и большой объем работ по интеграции с различными внутренними сущностями: мастер-данными, микросервисами, системами оркестрации бизнес-процессов, а также с окружающей компанию экосистемой. С приходом локдауна нам пришлось закрыть часть офлайн-магазинов, что повлекло снижение товарооборота компании.
Чтобы бизнес мог продолжать работу, требовалось быстро адаптировать процессы. Компания перефокусировалась на онлайн-бизнес, перенастроила работу магазинов в режим dark store, адаптировала процессы сборки заказов, запустила альтернативные каналы продаж через кол-центры. Как следствие, в период локдауна кратно вырос трафик на сайте и количество собираемых заказов в магазинах.
Что помогло нам в локдаун? Прежде всего, наша архитектура. Модель ритейл-бизнеса меняется каждый год, на рынке появляются новые конкуренты. Раньше можно было заниматься только продажами, делегировав IT на аутсорс. Конкурентный рынок требовал быстрых изменений и компания решила развивать собственные команды разработки. Мы построили продуктовые команды, чтобы самостоятельно быстро строить систему и оперативно решать задачи.
В «Леруа Мерлен» мы применяем три основных архитектурных правила:
-
Модульность — разделение процесса/системы на модули, которые можно рекомбинировать.
-
Связность — способность быстро и прозрачно интегрировать модули.
-
Рациональность — оптимизация использования ресурсов, исключение дублирования и максимальное переиспользование.
Эти правила и формируют так называемую composable architecture. Самая важная роль в этой модели отводится API, которые мы раскладываем в три слоя:

Нижний слой — объектные API, функции доступа к данным. Здесь находятся репозитории CRUD мастер-данных, унаследованные приложения, лицензионное коммерческое коробочное ПО и части глобальных IT-продуктов. С помощью инкапсуляции на этом уровне мы можем переиспользовать легаси-системы.
Средний слой — бизнес-процессы и оркестрация, где сосредоточена основная бизнес-логика.
Верхний слой содержит средства адаптации к конкретным прикладным задачам; сервисы класса Back-End-for-Front-End; ПО для мобильных и десктоп-приложений; функциональность композитных сервисов (mash-up); средства интеграции с партнерами, клиентами и окружающей компанию экосистемой; бизнес-логику приложений для конкретных видов бизнеса. Во многом это уже специфичные, более узкие инструменты.
Требования к скорости изменений и объем задач были настолько высокими, что имеющихся ресурсов было недостаточно. Необходимо было найти новые подходы. Однако ни одно из доступных на рынке интеграционных решений не закрывало все потребности. Так мы пришли к созданию своей корпоративной облачной платформы Platformeco. Она доступна продуктовым командам в режиме PaaS и позволяет разрабатывать микросервисы, формировать интеграционные потоки и API в графическом интерфейсе, а затем разворачивать их в облаке, получая функциональность непрерывной интеграции и непрерывной доставки (CI/CD), автомасштабирования, транспорта между средами, мониторинга и пр.
Platformeco, конечно, не панацея. Для сложных, нетривиальных сервисов привлекаются сильные разработчики, но широкий пул задач мы можем решать с помощью low-code. Про Platformeco можно делать отдельный доклад, продукт очень быстро развивается и имеет множество интересных фичей, так что вернемся к «Леруа Мерлен».
Модульность и наличие удобных инструментов помогли нам быстро перестроить процессы в локдаун и пересобрать бизнес-процессы с фокусом на новые реалии. За три дня мы смогли создать базовые элементы и итеративно их улучшать. Эти же принципы мы используем не только в IT, но и для построения организации в целом. Мы поделили всю компанию на домены, которые отвечают за разные аспекты работы — продажу, логистику и т.п. А внутри доменов мы сформировали отдельные команды со своими задачами и метриками, с операционными и IT-специалистами в составе. Они активно внедряют продуктовый подход к работе, что позволяет им лучше взаимодействовать друг с другом, глубже погружаться в контекст. Такая синергия дает отличный результат.
Подводя итог, могу сказать, что устойчивое развитие в нашем случае стало возможным благодаря описанным архитектурным принципам, использованию API, модульности и гибкой организации.
ссылка на оригинал статьи https://habr.com/ru/company/rosbank/blog/598887/
Добавить комментарий