
Краткое введение
Sony знала, что разработка для 3D-оборудования может становиться очень сложной. Поэтому в дизайне своей первой консоли она стремилась к простоте и практичности… Однако всё имеет свою цену!
CPU
В этом разделе мы проанализируем Sony CXD8530BQ — один из двух больших чипов, содержащихся в консоли. Сегодня мы бы назвали его «System-on-Chip».
Происхождение
Сюжет о создании процессора в виде «X спроектирован компанией Y на основе Z при поддержке W» сложно будет рассказать в нескольких предложениях, поэтому почему бы начать с исторического контекста?
Модели

Оригинальная PlayStation. Выпущена 03.12.1994 в Японии, 09.09.1995 в Северной Америке, 29.09.1995 в Европе.

PS One (slim-версия). Выпущена 07.07.2000 в Японии, 19.09.2000 в Северной Америке, 29.09.2000 в Европе. Вот что можно получить, засунув кучу специализированных интегральных схем в одну.
Материнские платы

Материнская плата модели «SCPH-1000». Остальные чипы расположены на обратной стороне. В более поздних моделях вместо VRAM использовалась SG-RAM и были убраны многие внешние разъёмы ввода-вывода и вывода видео.

Важные части материнской платы
Схема
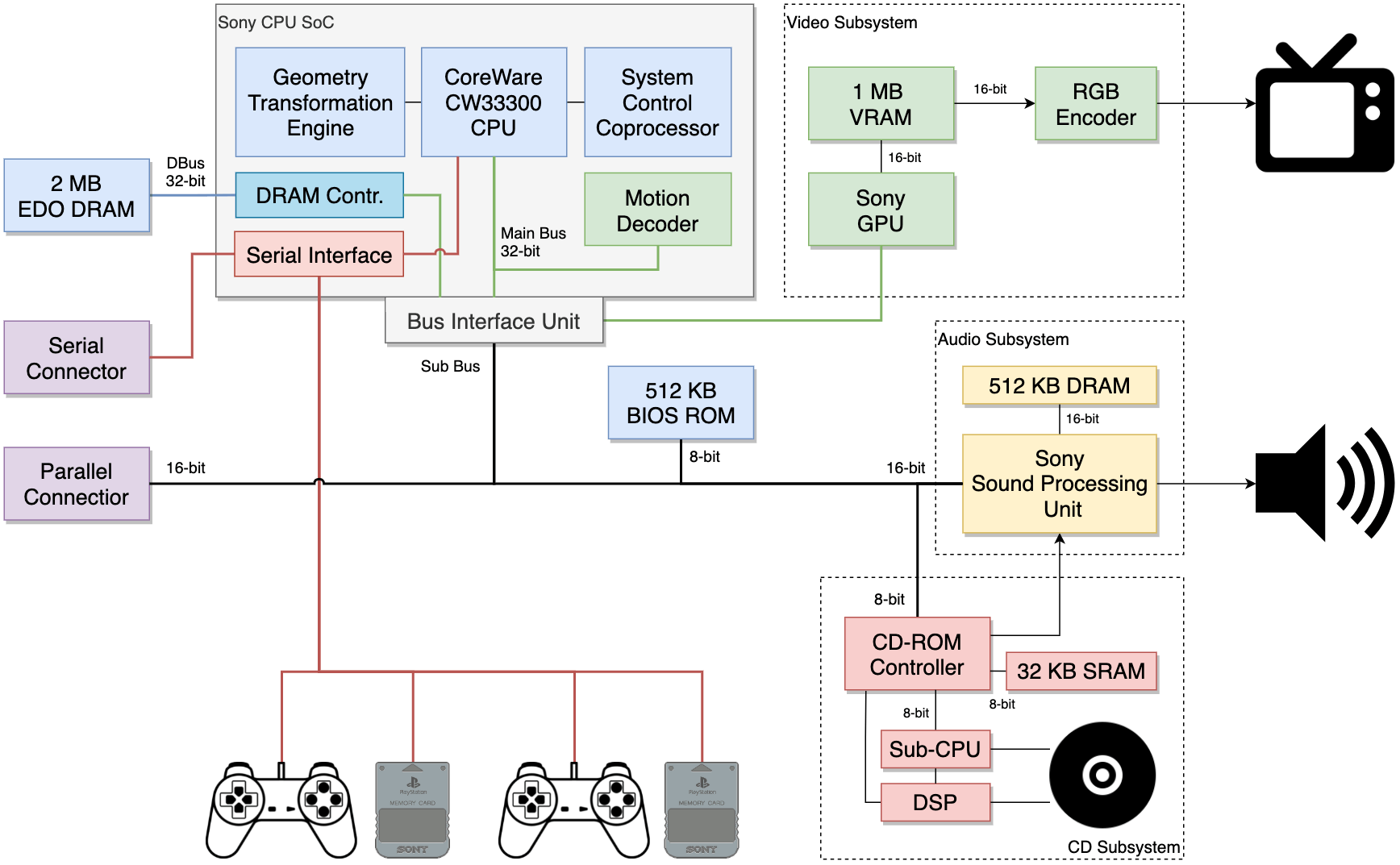
Схема основной архитектуры. Блок шинного интерфейса (Bus Interface Unit) также подключен к специальным портам GPU и SPU.
Немного истории
Начало девяностых ознаменовалось сменой судьбы многих популярных CPU. Когда-то бывшие ведущими 8-битные процессоры, например, Z80 и 6502, уже ушли из света рамп, а знаменитый 68000 компании Motorola, наряду с другими 16-битными архитектурами, купавшимися в успехе в конце 80-х, стали кандидатами на выбывание. В те времена в журнале PC World Таненбаум в своём знаменитом споре с Торвальдсом даже давал архитектуре x86 компании Intel всего пять лет, прежде чем она покинет рынок домашних систем.
Поначалу может показаться, что технологическое развитие в тот момент зашло в тупик. Но в реальности возникла новая волна относительно неизвестных CPU, пробивающих себе дорогу в мейнстримные устройства. Многие из этих архитектур вышли из научных кругов, то есть существовали только в качестве доказательства жизнеспособности неких архитектурных идей. В то время примерами CPU нового поколения были следующие архитектуры:
- MIPS: использовалась Silicon Graphics Incorporated (в графических рабочих станциях).
- PowerPC: использовалась Apple (в области компьютерной вёрстки).
- SPARC: создана Sun Microsystems (предназначена для серверов и рабочих станций бизнес-класса).
- ARM: создана Acorn (предназначена для потребительского рынка и рабочих станций).
Все эти процессоры имели нечто общее: все они использовали схему Reduced Instruction Set Computer (RISC), что радикально меняло способ их проектирования и программирования. Одно из правил процессоров RISC гласило, что одна команда не может смешивать память с операциями с регистрами, что позволяло проектировщикам оборудования упростить выполняющие команды электрические схемы и дополнить их техниками параллельной обработки.
MIPS и Sony
В конце 80-х, после того, как Silicon Graphics Incorporated (SGI) начала использовать процессоры MIPS в своём оборудовании, они стали темой активного обсуждения. SGI была влиятельным инноватором на рынке компьютерной графики, особенно благодаря разработке конвейеров обработки вершин с аппаратным ускорением, задачу которых изначально выполняло ПО (внутри CPU).
На момент разработки PlayStation компания MIPS продавала серию процессоров R3000A. Это были 32-битные машины из недорогого класса продукции компании. То есть R3000A не были частью флагманской линейки (в отличие от R4000, который позже выберут другие производители), но являлись привлекательной инвестицией с точки зрения цены.
Свои звуковой и графический чипы Sony проектировала самостоятельно, но ей всё равно нужен был ведущий чип, способный управлять этими двумя. Выбранный CPU должен быть стать достаточно мощным, чтобы продемонстрировать впечатляющие возможности чипов Sony, но в то же время доступным по цене, чтобы сохранить конкурентоспособность консоли.
LSI и контракт на производство
В то же время производитель полупроводниковых устройств LSI Logic предлагал бизнесам программу «создай свой собственный CPU». Эта услуга называлась CoreWare, она позволяла клиентам собирать собственные комплекты CPU из набора строительных блоков. В библиотеку CoreWare входил и блок CW33300 — ядро CPU на основе LSI LR33300 (чипа CPU, продававшегося компанией серийно).
К чему же я всё это рассказываю? Оказалось, что LSI LR33300 и CW33300 являются двоично совместимыми версиями семейства MIPS R3000A. Их архитектуры в определённых аспектах отличались, но интерфейс программирования (MIPS I ISA) оставался тем же.
В конечном итоге, Sony поручила LSI создать комплект CPU. Компания выбрала CW33000, изменила некоторые его части и скомбинировала с другими блоками, создав чип, который мы можем увидеть на материнской плате PlayStation.
Предложение
Получившееся ядро CPU работает с частотой 33,87 МГц и обладает следующими особенностями:
- MIPS I ISA (архитектура набора команд): первая версия набора команд MIPS. Среди прочих аспектов архитектуры 32-битная длина слова и наличие в наборе команд умножения и деления.
- 32 регистра общего назначения и 2 регистра умножения/деления: они тоже являются 32-битными. Один регистр общего назначения всегда имеет нулевое значение (R0), что стандартно для процессоров RISC.
- 32-битная шина данных: в PS1 шина данных разветвляется на две шины.
- Основная шина (Main Bus) (32-битная) → соединяется с основным ОЗУ, MDEC и GPU.
- Подчинённая шина (Sub Bus) (16/8-битная) → соединяется с остальными чипами и вводом-выводом. Эта шина образует мост с Bus Interface Unit, что также обеспечивает доступ к специальным портам GPU и SPU.
- 32-битная адресная шина: возможна адресация до 4 ГБ физической памяти (например, ОЗУ, ввод-вывод с отображением в память и т. п.).
- 5-этапный конвейер: одновременное выполнение до пяти команд (подробное объяснение можно найти в предыдущей статье).
- 4 КБ кэша команд: его тоже можно «изолировать», что позволяет непосредственно манипулировать кэшем команд.
- Как ни странно, кэша данных нет. 1 КБ памяти, обычно используемый для кэша данных, отображён на фиксированный адрес. Эта область также называется Scratchpad (быстрая SRAM).
Чтобы обеспечить достаточные ресурсы, Sony выделила для общего использования 2 МБ ОЗУ. Любопытно, что компания установила на материнскую плату чипы Extended Data Out (EDO). Они чуть более эффективнее обычной DRAM и обеспечивают меньшие задержки.
Перехват управления у CPU
В определённые моменты одной из подсистем (графика, звук или CD) могут с высокой частотой требоваться большие блоки данных. Однако CPU не всегда способен справиться с такими запросами.
По этой причине контроллер CD-ROM, MDEC, GPU, SPU и параллельный порт при необходимости имеют доступ к DMA-контроллеру. DMA берёт на себя управление основной шиной и выполняет передачу данных. Получающаяся частота передачи намного выше, чем при использовании CPU, однако последний всё равно необходим для подготовки DMA-передачи.
Также стоит помнить о том, что при срабатывании DMA процессор не может получить доступа к основной шине. Это значит, что CPU будет простаивать, если только для него нет работы в Scratchpad!
Дополнения к ядру
Как и другие CPU на основе MIPS R3000, CW33000 поддерживает конфигурации с четырьмя сопроцессорами. Sony решила использовать три:
System Control Coprocessor
System Control Coprocessor (сопроцессор управления системой), обозначенный как CP0, является стандартным блоком CPU MIPS. В системах на основе R3000 сопроцессор CP0 управляет реализацией кэша. То есть он обеспечивает прямой доступ к кэшу данных (имеющему форму «Scratchpad») и к кэшу команд (при помощи «изоляции кэша»). Управляющий сопроцессор также отвечает за обработку прерываний, исключений и контрольных точек (последнее полезно при отладке).
Постойте, но разве сопроцессоры не должны только расширять функции CPU? Почему CP0 так тесно связан с CPU?
И в самом деле, ядра R3000 применяют сопроцессор управления системой, чтобы иметь возможность использовать многие его компоненты, однако вопрос «законности» этого сводится к интерпретации слова «сопроцессор». По мнению MIPS, сопроцессор не является строго дополнительной частью CPU, он также может управлять окружением CPU (кэшем, прерываниями и т. п.). Следовательно, сопроцессор может быть неотъемлемой частью системы. Об этом стоит помнить, когда мы говорим о системах, связанных с MIPS.
Позже в системах на основе R4000 в этот блок были включены Memory Management Unit (MMU) и Translation Lookaside Buffer (TLB), что расширило его возможности и позволило выполнять новые роли.
Geometry Transformation Engine
CP2, или Geometry Transformation Engine (GTE) — это специальный математический сопроцессор, ускоряющий векторные и матричные вычисления.
Хоть сопроцессор и работает только с типами с фиксированной запятой, он обеспечивает полезные для 3D-графики операции:
- Матричное или векторное умножение и сложение; векторный квадрат.
- Перспективное преобразование (используется для 3D-проецирования).
- Внешнее произведение двух или трёх векторов (последнее используется для усечения).
- Множество функций интерполяции с использованием различных параметров.
- Depth Cueing и значение цвета от источника освещения (используются для операций с освещением и цветом).
- Среднее значение Z/глубины (подозреваю, что это нужно для «таблицы упорядочивания»; подробнее см. в разделе «Графика»).
Но вам не нужно это всё запоминать до конца статьи! Просто помните, что GTE занимается первыми этапами графического конвейера, например, 3D-проецированием, освещением и усечением. Это помогает в генерации данных, которые передаются GPU для рендеринга.
Motion Decoder
Motion Decoder, также называемый MDEC или Macroblock Decoder — это ещё один процессор, расположенный рядом с CPU. Он разжимает «макроблоки» в формат, понятный GPU. Макроблок (Macroblock) — это структура данных, содержащая изображение с похожим на JPEG кодированием.
За раз MDEC распаковывает битовые карты, состоящие из 8×8 пикселей с глубиной цвета 24 бита на пиксель. В руководстве по программированию Уокера утверждается, что MDEC может вычислить 9000 макроблоков в секунду. Это позволяет обеспечивать потоковую передачу full-motion video (FMV) в разрешении 320×240 с частотой 30 кадров в секунду.
Для передачи сжатых данных по пути CD-ROM → RAM → MDEC используется DMA. Тот же путь данные проделывают в обратном направлении, однако в этом случае пунктом назначения является VRAM.
Хотя этот компонент находится внутри SoC и использует ту же шину данных, это не сопроцессор MIPS, поэтому CPU/DMA получают к нему доступ через отображение в память (а не при помощи перехвата команд).
Более подробную информацию об устройстве MDEC я рекомендую поискать на ресурсах Сабина и Чекански (см. раздел «Источники»).
Пропавшие устройства?
Пока мы рассматривали CP0 и CP2, но где же CP1? Это обозначение зарезервировано для Floating Point Unit (FPU, сопроцессора для чисел с плавающей точкой), а Sony, к сожалению не использовала его. Это не значит, что CPU не может выполнять арифметические действия с десятичными числами, они просто выполняются не очень быстро (эмулируемый программно FPU) и точно (вычисления с фиксированной запятой).
Игровая логика (включающая в себя физику, распознавание коллизий и т. п.) может обойтись и вычислениями с фиксированной запятой. Кодирование с фиксированной запятой хранит десятичные числа с неизменным количеством десятичных разрядов. Это подразумевает потерю точности после некоторых операций, но стоит помнить, что это видеоигровая консоль, а не профессиональный лётный симулятор. Поэтому компромисс между точностью и производительностью вполне приемлем.
Кстати, иногда я путаю понятия «фиксированной запятой», «плавающей запятой», «десятичного» и «целочисленного» типа чисел (надеюсь, этого больше не повторится!). Если у вас та же проблема, то рекомендую изучить краткое объяснение Габриеля Иванческу (см. раздел «Источники»).
Куча задержек
Как мы видели ранее, CW33300 — это конвейерный процессор, то есть он объединяет множество команд в очередь и выполняет их параллельно на разных этапах. Это значительно повышает скорость обработки команд, но без должного контроля это может привести к конфликтам конвейера, вызывающим ошибки вычислений.
Архитектура MIPS I подвержена конфликтам управления и конфликтам данных, то есть команды могут выполняться не тогда, когда нужно, и оперировать с устаревшими данными до их обновления.

Команды из Spyro The Dragon, визуализированные в отладчике NO$PSX. Обратите внимание, что за командами LW (load word from memory), JAL (jump and link) и BAL (branch on not equal) следует слот задержки для предотвращения конфликтов. Красным отмечены заполнители (бесполезные команды). Синим отмечены существенные операции.
Следовательно, процессоры MIPS I демонстрируют следующее поведение:
- Любая команда после опкодов типа «ветвление» или «переход» выполняется безусловным образом: Поэтому после ветвления или перехода разработчики должны вручную заполнять конвейер бесполезными командами (например,
вычислить 0 плюс 0), чтобы устранить конфликты. Эти заполнители называются слотами задержек ветвления.
- Современные CPU превратили это явление в преимущество: прогнозирование ветвления. Благодаря добавлению дополнительных цепей для обнаружения конфликтов CPU отбрасывает новые вычисления, если условие ветвления/перехода не было соблюдено. Но если оно соблюдено, то CPU экономит немного времени.
- Команды типа «загрузка» не вызывают простой конвейер, пока не будут доступны полученные данные: второй этап конвейера (называемый RD, или Read and Decode) собирает операторы, которые будут использоваться для вычислений на третьем этапе (ALU, арифметическо-логическое устройство). Четвёртый этап (MEM, сокращение от «access MEMory», «доступ к памяти») ищет данные в памяти (т. е. в основной ОЗУ, CD-приводе и т. д.). Здесь возникает проблема: ко времени, когда команда
loadсоберёт данные снаружи, следующая команда уже получила операции. Это значит, что команда, зависящая от значений предыдущей командыload, требует между ними заполнителя, чтобы правильные операторы были получены вовремя.
Как мы видим из примера, некоторые слоты задержки заполнены полезными командами, выполняющими вычисления, на которые не влияет конфликт. Поэтому слоты задержки не всегда подразумевают потраченные впустую такты процессора.
В большинстве случаев компилятор или ассемблер автоматически изменяет порядок команд для заполнения слотов или, в крайнем случае, добавляет бесполезные заполнители. То есть, в целом, это явление имеет и плюсы, и минусы.
Источники
Общая информация
- Martin Korth, Nocash PSX Specifications.
- Википедия, модели PlayStation.
CPU
- MAMEdev,
исходный код эмулятора CPU PlayStation. - Jakub Czekański, Логи времени доступа к CPU.
- Integrated Device Technology, R30xx Family Software Reference Manual.
- LSI Logic, LR33300 User’s Manual.
- Raymond Chen, The MIPS R4000, part 8: Control transfer.
- Gabriel Ivancescu, Fixed Point Arithmetic and Tricks.
- Michael Sabin, The PlayStation 1 Video (STR Format).
- Jakub Czekański, encode.cpp (кодировщик MDEC на C++). Github.
ссылка на оригинал статьи https://habr.com/ru/post/599869/
Добавить комментарий