Современный человек много чем занимается в интернете: ходит по магазинам, слушает музыку, читает новости. Все эти задачи подразумевают поиск и выбор того, что ему нужно. При этом важную роль тут играют рекомендательные системы. Они помогают людям не утонуть в многообразии вариантов и увидеть именно то, что им подойдёт, то, что иначе им сложно было бы найти. Предоставление пользователям качественных рекомендаций — это важнейшая часть обеспечения первоклассного уровня удовлетворения клиента. Это — один из самых эффективных способов взращивания лояльности клиентов и повышения ценности продукта или услуги в их глазах. Всё это так важно, что целые бизнес-модели некоторых компаний построены вокруг предоставления их клиентам наилучших рекомендаций, что делает рекомендательные системы важнейшими факторами, влияющими на прибыль подобных компаний! В результате неудивительно то, что клиенты проекта Microsoft CSE часто обращаются к нам с просьбами, касающимися реализации эталонных рекомендательных техник. Один из таких проектов был моим первым опытом в данной сфере.

Я хочу рассказать о том, как можно воспользоваться трансформерами для прогнозирования рейтингов фильмов на основе сведений о предыдущих действиях пользователя. Так же я сравню трансформеры с более широко известным подходом к решению подобных задач, который заключается в применение матричной факторизации. Применение трансформеров стало причиной значительных улучшений в сфере обработки естественных языков, в системах компьютерного зрения и в решении задач обработки временных рядов. Поэтому, похоже, настало время прихода этих нейросетевых архитектур в рекомендательные системы. Меня на это исследование вдохновила статья о применении трансформеров на платформе Alibaba. Я, правда, слегка доработал предлагаемый там подход, учтя особенности моей задачи и архитектуры разрабатываемой мной системы.

Для того чтобы свести к минимуму объём шаблонного кода, необходимый для решения моих задач, и чтобы не отвлекаться от работы над моделями, я, для обучения PyTorch-моделей, использую библиотеку pytorch-accelerated. Это позволяет запускать цикл обучения на нескольких GPU, не меняя код. Если вы не знакомы с этой библиотекой и хотели бы, прежде чем читать дальше, кое-что о ней узнать, можете посмотреть эту вводную статью о pytorch-accelerated или документацию к ней. Но библиотека это очень простая, поэтому если вы с ней и не знакомы, это не должно помешать вам понять то, о чём я тут буду рассказывать. Главная цель этой статьи — реализация и исследование разных подходов к созданию рекомендательных систем. Поэтому, хотя нам и придётся коснуться множества тем и методик, тут будет представлена лишь суть рассматриваемых вопросов, а подробности о них вы сможете узнать из дополнительных источников.
Те, кому не терпится увидеть всё это в деле, попробовать код, могут заглянуть на эту страницу, где собран весь код из статьи. В этой статье используются фрагменты кода, цель которых — в приятной глазу форме проиллюстрировать те или иные идеи. Если их напрямую скопировать в среду выполнения Python-кода, они могут и не запуститься. А код из Jupyter Notebook, ссылка на который приведена выше, точно заработает.
Вот перечень Python-пакетов, которые тут используются.

Загрузка и подготовка данных
Мы будем экспериментировать с набором данных MovieLens-1M. Это — коллекция из миллиона оценок, которые 6000 пользователей выставили 4000 фильмам. Этот набор данных собрала и поддерживает исследовательская группа GroupLens из Университета Миннесоты. Он увидел свет в 2003 году. MovieLens широко используется в сфере машинного обучения, он часто применяется для проведения стандартных тестов в научных публикациях.
Набор данных MovieLens состоит из трёх файлов: movies.dat (фильмы), users.dat (пользователи) и ratings.dat (оценки). Вот как выглядят эти данные.

Скомбинируем некоторые данные из этих таблиц в один датафрейм Pandas (объект DataFrame), что облегчит нашу дальнейшую работу.

Мы, задействуя возможности Pandas, можем вывести некоторые общие статистические сведения об этом наборе данных, что может нам пригодиться.

Эти сведения говорят нам о том, что все оценки представлены числами от 1 до 5, и о том, что каждый фильм был оценён, как минимум, один раз. Так как каждый пользователь оценил как минимум 20 фильмов, нам не нужно беспокоиться о том, как рекомендовать что-либо пользователю, о предпочтениях которого нам ничего не известно. Правда, в реальном мире часто приходится решать и такую задачу.
Разбиение исходных данных на обучающую и проверочную выборки
Прежде чем мы приступим к созданию моделей, нам надо разбить исходный набор данных на обучающую и проверочную выборки. Часто эту задачу решают путём выбора случайного набора строк. Это, в некоторых случаях, вполне оправдано. Но, так как мы собираемся обучить трансформерную модель на последовательностях оценок, нам это не подойдёт. Дело в том, что если мы просто исключим из обучающих данных набор случайных строк, это не даст нам хорошего представления системы, которую мы пытаемся смоделировать. Вполне возможно то, что для некоторых пользователей оценки из середины последовательности попадут в проверочную выборку. Для того чтобы понять то, почему это способно привести к проблемам, рассмотрим небольшой пример.
Представим себе, что пользователь смотрит фильмы из следующего списка и ставит им оценки. Мы, взглянув на обучающую выборку, хотим спрогнозировать оценку, которую он поставит фильму «Rocky». Делать мы это будем в ходе валидации модели на проверочной выборке.

Учитывая то, что мы знаем, что пользователю понравился фильм «Rocky 2», который имеется в обучающей выборке, вероятно то, что ему понравится и фильм «Rocky». Поэтому мы можем спрогнозировать то, что пользователь поставит этому фильму высокую оценку. Но, так как пользователь посмотрел «Rocky 2» после «Rocky», в реальности у нас не было бы доступа к этим сведениям в тот момент, когда пользователь ставил оценку «Rocky». Наличие сведений об оценках, сделанных после оценки «Rocky», позволяет нам в данном случае «мошенничать» при решении задачи. Эта проблема известна как «утечка данных». Она может проявиться в искусственном улучшении показателей качества модели, но это не показательно для тех данных, которые, скорее всего, будут в нашем распоряжении при реальном использовании системы. Для того чтобы этого избежать, мы можем воспользоваться различными подходами.
Один из них заключается в том, чтобы формировать проверочную выборку, отбирая пользователей. То есть — случайным образом отбирают пользователей и обеспечивают попадание всех их оценок в проверочную выборку. Хотя это и рабочий подход, модель, в ходе обучения, ничего не узнает об этих пользователях. Поэтому каждый элемент проверочной выборки мы будем воспринимать так, как будто он представляет собой оценки, сделанные новым пользователем системы. В результате единственный способ, которым модель может предсказать оценки этих пользователей, будет основан на предпочтениях других, похожих на них пользователей. Конечно, проверка работы с новыми пользователями должна проводиться в ходе широкомасштабной проверки модели (движка рекомендательной системы) идущей в продакшн. Но такой подход даст неоптимальное представление о том, может ли исследуемая модель изучить предлагаемые ей данные.
Альтернативный подход может заключаться в применении стратегии, известной как валидация, выполняемая по принципу «исключение по одному». Тут мы, для каждого пользователя, выбираем последнюю по времени оценку, с учётом того, что эти пользователи уже оценили некоторое количество фильмов, превышающее определённое пороговое значение. Это даёт нам хорошее представление того процесса, который мы собираемся смоделировать. Именно этот подход нам и стоит использовать. Определим функцию, которая будет получать n оценок для каждого пользователя:
def get_last_n_ratings_by_user( df, n, min_ratings_per_user=1, user_colname="user_id", timestamp_colname="unix_timestamp" ): return ( df.groupby(user_colname) .filter(lambda x: len(x) >= min_ratings_per_user) .sort_values(timestamp_colname) .groupby(user_colname) .tail(n) .sort_values(user_colname) )Теперь эту функцию можно использовать для определения другой функции, которая будет помечать n оценок на пользователя так, чтобы они попадали бы в проверочную выборку. Делается это с использованием столбца is_valid:
def mark_last_n_ratings_as_validation_set( df, n, min_ratings=1, user_colname="user_id", timestamp_colname="unix_timestamp" ): """ Отмечает n последних по времени оценок, что включает их в проверочную выборку. Делается это путём добавления дополнительного столбца 'is_valid' в df. :param df: объект DataFrame, содержащий оценки, данные пользователем :param n: количество оценок, которые надо включить в проверочную выборку :param min_ratings: включать лишь пользователей, имеющих более этого количества оценок :param user_id_colname: имя столбца, содержащего идентификатор пользователя :param timestamp_colname: имя столбца, содержащего отметку времени :return: тот же df, в который добавлен дополнительный столбец 'is_valid' """ df["is_valid"] = False df.loc[ get_last_n_ratings_by_user( df, n, min_ratings, user_colname=user_colname, timestamp_colname=timestamp_colname, ).index, "is_valid", ] = True return dfПрименив эту функцию к нашему датафрейму, мы увидим, что теперь у нас имеется проверочная выборка, содержащая 6040 строк. То есть — по одной строке для каждого пользователя.

Даже в том случае, когда модель, ради проведения адекватных сравнений, проверяют на данных из того же набора, который использовался при её обучении, важно понимать то, как данные разбивают на обучающую и проверочную выборки. Подходы, выбранные для проверки модели, кроме того, важно использовать последовательно.
Критерии оценки качества моделей рекомендательных систем
Оценка рекомендательных систем — это очень сложная задача, описание которой, в основном, выходит за рамки данного материала. Правда, есть много публикаций, всесторонне исследующих эту задачу. Тут мы оценим модель по трём метрикам, и, так как идеи, лежащие в их основе, хорошо раскрыты в других местах, здесь мы приведём лишь их краткие описания:
-
Средняя абсолютная ошибка (Mean Absolute Error, MAE) — среднее значение абсолютных значений отклонений между реальными и спрогнозированными значениями.
-
Средняя квадратичная ошибка (Mean Squared Error, MSE) — среднее значение квадратов абсолютных значений отклонений между реальными и спрогнозированными значениями.
-
Корень из средней квадратичной ошибки (Root Mean Squared Error, RMSE) — квадратный корень из MSE, то есть, значение того же порядка, что и MAE.
О том, наилучший ли это подход к оценке подобных моделей, можно поспорить, но это — широко распространённый метод оценки рекомендательных моделей, он часто применяется и в научных публикациях, и в реальных системах. Лично я в первую очередь смотрю на показатель MAE, как на общую характеристику качества модели, так как этот показатель отличается понятностью и предсказуемостью его интерпретации. Это отличает его от RMSE, который имеет тенденцию к более сильному выделению больших ошибок. Подробнее этот вопрос обсуждается здесь.
Создание базовой модели
Приступая к решению новой задачи моделирования, часто полезно создать очень простую модель, известную как «базовая модель», то есть — решить задачу простым и понятным способом, приложив к этому минимум усилий. Затем показатели качества этой модели можно использовать для сравнения с показателями более сложных моделей, созданных позже. Если сложная модель показывает результаты, которые хуже результатов базовой модели — это плохой знак.
Мы, для построения базовой модели, можем просто прогнозировать среднюю оценку по каждому фильму, не обращая внимания на контекст. Так как среднее значение может подвергаться значительному влиянию показателей, сильно отличающихся от обычных, используем для построения модели медиану значений. Вычислить медианный рейтинг несложно:

Затем можно воспользоваться этим показателем в виде прогноза для каждой оценки в проверочной выборке и посчитать показатели качества модели:

Сами по себе эти числа довольно-таки бессмысленны. Они пригодятся нам для сравнения с показателями моделей, построенных с использованием подходов, которые мы собираемся исследовать.
Матричная факторизация со смещением
Один из весьма популярных подходов к созданию рекомендательных систем, применяемый и в научных кругах, и в бизнесе, представлен методами матричной факторизации. Поговорим о смысле этих методов (более подробный их разбор можно найти здесь). В дополнение к представлению рекомендаций в виде таблицы, вроде нашего датафрейма, создают альтернативный вариант данных — матрицу, в которой содержатся оценки, данные пользователями. Фрагмент подобной матрицы показан ниже.

Так как не каждый из пользователей оценил все фильмы, можно видеть, что некоторые значения в этой матрице отсутствуют. В результате задачу прогнозирования оценок можно сформулировать так:
Как заполнить пустые места матрицы, чтобы при этом подставленные в неё значения согласовывались бы с уже имеющимися в ней оценками?
Один из способов решения этой задачи заключается в том, чтобы решить, что существуют две матрицы меньшего размера, умножение которых даёт нашу матрицу оценок. Вот как это может выглядеть:

Самое главное тут в том, что каждая строка матрицы признаков пользователя, U, представляет предпочтения отдельного пользователя, а столбец матрицы признаков фильма, M, представляет признаки конкретного фильма. Тут у вас может появиться вопрос о том, как именно мы вышли на эти матрицы. Есть аналитические способы это сделать, обычно требующие серьёзных вычислений. Но мы занимаемся тут машинным обучением, поэтому на подобный вопрос есть лишь один ответ: мы инициализируем их случайными значениями и используем некий вариант алгоритма градиентного спуска для обучения модели и настройки этих значений.
Суть тут в том, что каждая строка матрицы U представляет собой предпочтения отдельного пользователя, а столбец M — признаки конкретного фильма. Эта идея, в соответствии с которой имеются некие скрытые значения, представляющие отдельных пользователей и отдельные фильмы, аналогична использованию эмбеддингов в компьютерном зрении или в обработке естественных языков. Там особый вектор, после обучения модели, используется для представления признака изображения или слова.
Итак, у нас сейчас есть следующая формула:

Здесь произведение столбцов матрицы U со строками матрицы M соответствует предпочтениям пользователя относительно конкретного фильма.
Но, хотя это и рабочий подход, часто получить лучшие результаты можно, включив в подобную формулу член смещения:

Каждый член смещения представляет собой вектор, содержащий один признак, имеющий отношение, соответственно, к отдельному пользователю или фильму. Введение в формулу члена смещения для фильмов позволяет модели изучить признак, представляющий собой то, как оценивается этот фильм, в сравнении со средней оценкой по всем остальным фильмам. Аналогично, член смещения пользователя может быть изучен моделью для представления склонности конкретного пользователя давать более высокие или более низкие оценки, чем «средний» пользователь. Например, у раздражительного пользователя, который обычно ставит фильмам «единицы», член смещения будет содержать большие значения, которые могут быть добавлены к каждой оценке для вывода их на один уровень с оценками «среднего» пользователя.
Если сейчас всё это кажется вам довольно-таки запутанным — не беспокойтесь. Всё станет куда понятнее после того, как мы выразим это в коде.
Реализация в PyTorch
Прежде чем мы поразмыслим об обучении модели — сначала надо привести данные к правильному формату. Сейчас у нас имеется заголовок, представляющий фильм, являющийся строкой. Нам нужно преобразовать этот заголовок в целое число, что позволит передать его модели. Хотя у каждого из пользователей уже и есть идентификатор, ID, давайте создадим собственный код ещё и для пользователей. Обычно я нахожу полезным управление кодированием всех сущностей, имеющих отношение к процессам обучения моделей. Это лучше, чем полагаться на некие системы присвоения сущностям идентификаторов, неизвестно где реализованные. Вы удивитесь, узнав о том, как много подобных идентификаторов, от которых ожидается, что они являются иммутабельными и уникальными, в реальности таковыми не являются.
Здесь мы можем это сделать, просто воспользовавшись функцией enumerate, получив таким образом уникальные значения и их индексы для пользователей и фильмов. Потом можно создать поисковые таблицы для этих данных:

Теперь, когда мы можем закодировать признаки, мы, так как используем PyTorch, должны определить класс Dataset, который будет включать в себя наш DataFrame. Его метод getitem возвращает оценки, выставленные пользователями фильмам.
class UserItemRatingDataset(Dataset): def init(self, df, movie_lookup, user_lookup): self.df = df self.movie_lookup = movie_lookup self.user_lookup = user_lookup def getitem(self, index): row = self.df.iloc[index] user_id = self.user_lookup[row.user_id] movie_id = self.movie_lookup[row.title] rating = torch.tensor(row.rating, dtype=torch.float32) return (user_id, movie_id), rating def len(self): return len(self.df)Всё это теперь можно использовать для создания обучающей и проверочной выборок:

Определим модель:
import torch from torch import nn class MfDotBias(nn.Module): def init( self, n_factors, n_users, n_items, ratings_range=None, use_biases=True ): super().init() self.bias = use_biases self.y_range = ratings_range self.user_embedding = nn.Embedding(n_users+1, n_factors, padding_idx=0) self.item_embedding = nn.Embedding(n_items+1, n_factors, padding_idx=0) if use_biases: self.user_bias = nn.Embedding(n_users+1, 1, padding_idx=0) self.item_bias = nn.Embedding(n_items+1, 1, padding_idx=0) def forward(self, inputs): users, items = inputs dot = self.user_embedding(users) * self.item_embedding(items) result = dot.sum(1) if self.bias: result = ( result + self.user_bias(users).squeeze() + self.item_bias(items).squeeze() ) if self.y_range is None: return result else: return ( torch.sigmoid(result) * (self.y_range[1] - self.y_range[0]) + self.y_range[0] )Видно, что определение модели получилось очень простым. Слой эмбеддинга — это всего лишь поисковая таблица. Поэтому при указании размера слоя эмбеддинга необходимо сделать так, чтобы в нём присутствовали бы все значения, которые могут встретиться в процессе обучения и проверки модели. Из-за этого мы используем количество уникальных элементов, имеющихся в полном наборе данных, а не только в учебном наборе. Мы, кроме того, описали эмбеддинг padding, находящийся по индексу 0, который может использовать для каких-либо неизвестных значений. PyTorch поддерживает подобное, устанавливая эту запись в нулевой вектор, данные которого не обновляются при обучении модели.
В дополнение к этому, так как это — регрессионная задача, диапазон значений, которые могут стать результатом прогнозирования модели, потенциально неограничен. Хотя модель и способна научиться ограничению выходных значений диапазоном от 1 до 5, мы можем упростить модели жизнь, модифицировав её архитектуру так, чтобы ограничить этот диапазон ещё до начала обучения. Сделано это путём применения сигмоидной функции к выходным данным модели, что ограничило эти значения диапазоном от 0 до 1. Потом мы масштабировали то, что получилось, на необходимый нам диапазон значений.
Обычно на данном этапе работы приходит время запуска обучающего цикла. Мы применяем библиотеку pytorch-accelerated, поэтому система, по большей части, сделает всё сама. Но, так как pytorch-accelerated, по умолчанию, отслеживает лишь потери, возникающие при обучении и валидации модели, давайте создадим коллбэк, который позволит получить интересующие нас показатели качества модели, описанные выше. О том, как создавать коллбэки, можно почитать здесь.
Для вычисления показателей качества модели мы воспользуемся пакетом torchmetrics. Он поддерживает распределённые системы обучения моделей, поэтому нам, перед вычислением показателей, не надо самостоятельно собирать данные из различных процессов.
from pytorch_accelerated.callbacks import TrainerCallback import torchmetrics class RecommenderMetricsCallback(TrainerCallback): def init(self): self.metrics = torchmetrics.MetricCollection( { "mse": torchmetrics.MeanSquaredError(), "mae": torchmetrics.MeanAbsoluteError(), } ) def _move_to_device(self, trainer): self.metrics.to(trainer.device) def on_training_run_start(self, trainer, **kwargs): self._move_to_device(trainer) def on_evaluation_run_start(self, trainer, **kwargs): self._move_to_device(trainer) def on_eval_step_end(self, trainer, batch, batch_output, **kwargs): preds = batch_output["model_outputs"] self.metrics.update(preds, batch[1]) def on_eval_epoch_end(self, trainer, **kwargs): metrics = self.metrics.compute() mse = metrics["mse"].cpu() trainer.run_history.update_metric("mae", metrics["mae"].cpu()) trainer.run_history.update_metric("mse", mse) trainer.run_history.update_metric("rmse", math.sqrt(mse)) self.metrics.reset()Теперь осталось лишь обучить модель. В библиотеке pytorch-accelerated имеется функция notebook_launcher, с помощью которой можно запустить процесс обучения на нескольких GPU из среды Jupyter Notebook. Для того чтобы воспользоваться этой возможностью — достаточно определить функцию обучения, которая создаёт экземпляр нашего объекта Trainer и вызывает его метод train.
Компоненты, такие, как модель и набор данных, могут быть определены в любом месте Jupyter Notebook, но важно, чтобы экземпляр объекта Trainer создавался бы только в пределах обучающей функции. Если вы предпочитаете создавать обучающие скрипты и вызывать их из командной строки, здесь можно найти сведения о том, как сделать это при использовании pytorch-accelerated.
В качестве функции потерь мы выбрали MSE, в качестве оптимизатора — AdamW, скорость обучения задаём с помощью OneCycle. Это приводит нас к такой обучающей функции:
def train_mf_model(): model = MfDotBias( 120, len(user_lookup), len(movie_lookup), ratings_range=[0.5, 5.5] ) loss_func = torch.nn.MSELoss() optimizer = torch.optim.AdamW(model.parameters(), lr=0.01) create_sched_fn = partial( torch.optim.lr_scheduler.OneCycleLR, max_lr=0.01, epochs=TrainerPlaceholderValues.NUM_EPOCHS, steps_per_epoch=TrainerPlaceholderValues.NUM_UPDATE_STEPS_PER_EPOCH, ) trainer = Trainer( model=model, loss_func=loss_func, optimizer=optimizer, callbacks=( RecommenderMetricsCallback, *DEFAULT_CALLBACKS, SaveBestModelCallback(watch_metric="mae"), EarlyStoppingCallback( early_stopping_patience=2, early_stopping_threshold=0.001, watch_metric="mae", ), ), ) trainer.train( train_dataset=train_dataset, eval_dataset=valid_dataset, num_epochs=30, per_device_batch_size=512, create_scheduler_fn=create_sched_fn, )Теперь можно запустить обучение, передав эту функцию функции notebook_launcher:

После 21 эпохи обучения получаются следующие показатели качества модели:

Они лучше, чем показатели базовой модели.
Использование трансформеров для выдачи прогнозов, основанных на последовательностях оценок
При использовании матричной факторизации мы рассматриваем каждую оценку, данную пользователем фильму, как не зависящую от окружающих её оценок. Но использование сведений о других фильмах, которые недавно оценил пользователь, может дать дополнительные данные, способные повысить качество модели. Например, представим, что пользователь смотрит трилогию. Если первым двум фильмам из трилогии он дал высокую оценку, вероятно, что так же он оценит и финальный фильм.
Один из подходов к реализации такой схемы работы заключается в использовании трансформера — особой нейросетевой архитектуры. Особенно это важно для той части модели, которая представляет собой энкодер. Это позволяет закодировать дополнительные контекстные сведения для каждого фильма в эмбеддингах. После этого для прогнозирования оценок можно воспользоваться полносвязной нейросетью.
Трансформеры способны помочь нам в решении этой задачи преимущественно из-за наличия у них механизма внутреннего внимания, благодаря которому вычисляется показатель внимания для каждого из фильмов в последовательности. Подробнее о механизме внутреннего внимания, да и о трансформерах тоже, можно почитать здесь и здесь. Показатель внимания вычисляется для каждого фильма с учётом всех остальных фильмов. Он представляет собой значимость различных элементов последовательности по отношению друг к другу. Если эмбеддинги пары фильмов связаны друг с другом, показатель внимания должен быть выше, чем для другой пары фильмов, которые, по видимому, друг с другом не связаны. Конечно, изначально у модели нет знаний о том, какие фильмы связаны друг с другом. Поэтому эмбеддинги фильмов, вместе с другими внутренними параметрами трансформера, нужно обучить, что позволит им продемонстрировать вышеописанное поведение.
Рассмотрим, на концептуальном уровне, пример того, как всё это работает. Предположим, пользователь посмотрел и оценил следующую последовательность фильмов

Фильмы о Гарри Поттере относятся к одной франшизе, поэтому они сильно связаны друг с другом. У них один и тот же режиссёр, стиль, одна и та же целевая аудитория. Поэтому нам хотелось бы, чтобы эмбеддинги для этих фильмов выдавали бы высокий показатель внутреннего внимания. А, в отличие от них, «Змеи-убийцы» — это фильм ужасов об огромной змее, которая ест людей. Это — совсем не такой фильм, как «Гарри Поттер и философский камень». Поэтому показатель внутреннего внимания тут должен быть очень низким. Но, так как в фильме «Гарри Поттер и Тайная комната» тоже есть здоровенная змея, у него имеется незначительное сходство с фильмом «Змеи-убийцы». В результате тут может получиться немного более высокий показатель внутреннего внимания, чем для фильмов «Змеи-убийцы» и «Гарри Поттер и философский камень».
Конечно, некоторые из этих взаимоотношений могут быть весьма незначительными. Именно поэтому трансформерам обычно необходимы огромные объёмы данных для выдачи приемлемых результатов. В нашем случае мы исходим из предположения о том, что можем узнать эти сведения, обрабатывая последовательности фильмов, просмотренных множеством различных пользователей. Вполне вероятно то, что некоторое подмножество пользователей посмотрело оба фильма о Гарри Поттере. Но для того чтобы модель выявила бы признак «в фильме есть змея-убийца», понадобилось бы наличие в выборке небольшого подмножества пользователей, которые устроили марафон по просмотру фильмов о змеях-убийцах, но это, наверное, уже будет перебор.
С концептуальной точки зрения трансформер, после нахождения показателей внутреннего внимания, использует их для выдачи матрицы, определяющей вклад оценки каждого фильма в оценку другого фильма. Например — это может быть такая матрица:
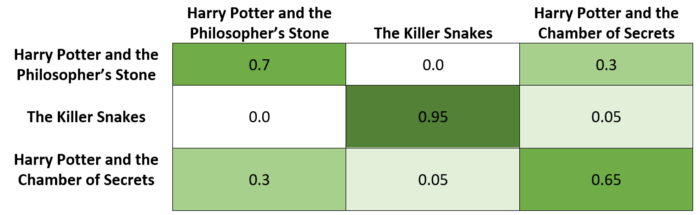
Затем матрица может быть использована для кодирования этих контекстуальных сведений в эмбеддинги фильмов. Эту операцию можно представить себе как замену эмбеддинга для фильма «Гарри Поттер и философский камень» на 0,7*(эмбеддинг для «Гарри Поттер и философский камень») + 0,3*(эмбеддинг для «Гарри Поттер и Тайная комната»).
Обратите внимание на то, что это — лишь упрощённое представление того, как работают трансформеры. Тут опущено множество тонкостей. Для того чтобы понять то, как на самом деле работают трансформеры, обратитесь к материалам, ссылки на которые приведены выше, или к публикации, с которой началась история трансформеров.
Предварительная обработка данных
Теперь, когда у нас есть общее (очень общее!) понимание того, почему применение трансформера может помочь нам в решении нашей задачи, переходим к первому шагу работы — к обработке данных. Нам нужно, для каждого пользователя, сформировать отсортированные по времени списки оценок фильмов. Начнём с группировки оценок по пользователю:

Теперь, сгруппировав оценки по пользователям, разделим их на небольшие последовательности данных. Для того чтобы выжать из этого материала всё что можно, нужно дать модели возможность прогнозировать оценку для каждого фильма из учебного набора. Чтобы это сделать — зададим длину последовательности s и используем s-1 предыдущих оценок в виде истории оценок пользователя.
Так как модель ожидает, что каждая из последовательностей будет иметь фиксированную длину, заполним пустые пространства вспомогательным токеном, в результате последовательности можно будет представить в виде пакетов и передать модели. Создадим функцию, которая решает эти задачи:
def create_sequences(values, sequence_length): sequences = [] for i, v in enumerate(values): seq = values[:i+1] if len(seq) > sequence_length: seq = seq[i-sequence_length+1:i+1] elif len(seq) < sequence_length: seq =(*(['[PAD]'] * (sequence_length - len(seq))), *seq) sequences.append(seq) return sequencesДля того чтобы получить представление о том, как работает эта функция, применим её, установив длину последовательности в значение 3, к первым 10 фильмам, оценённым первым пользователем. Вот эти фильмы:

Вот что получится после применение нашей функции:

Видно, что тут имеется 10 последовательностей длины 3, а последний фильм в последней последовательности остался тем же, что был в исходном списке.
Теперь применим эту функцию ко всем признакам в нашем DataFrame. Тут мы, без особой на то причины, выбрали длину последовательности 10.
Сейчас у нас имеется одна строка, содержащая все последовательности для конкретного пользователя. Но при обучении модели нам хотелось бы сформировать пакеты данных, состоящие из последовательностей, относящихся к множеству различных пользователей. Для того чтобы это сделать, надо преобразовать данные таким образом, чтобы каждая последовательность располагалась бы в собственной строке, но, в то же время, сохраняла бы связь с ID пользователя. Тут, для каждого признака, можно использовать функцию Pandas explode, а затем агрегировать полученные объекты DataFrame.

Теперь каждая последовательность располагается в собственной строке. Но, в случае столбца is_valid, нам не важна вся последовательность. Нам нужно лишь последнее значение, так как это будет фильм, для которого мы попытаемся спрогнозировать оценку. Создадим функцию для извлечения этого значения и применим её к этим столбцам.

Ещё, чтобы облегчить доступ к оценке, которую мы пытаемся спрогнозировать, выделим её в отдельный столбец:

Чтобы модель, при вычислении показателей внутреннего внимания, не использовала бы вспомогательные токены, мы можем предоставить трансформеру маску для механизма внутреннего внимания. Маска должна содержать значение True для вспомогательного токена, а для других данных — False. Построим маску для каждой из строк, а так же создадим столбец, содержащий сведения о количестве вспомогательных токенов:

Посмотрим на данные после их преобразования:
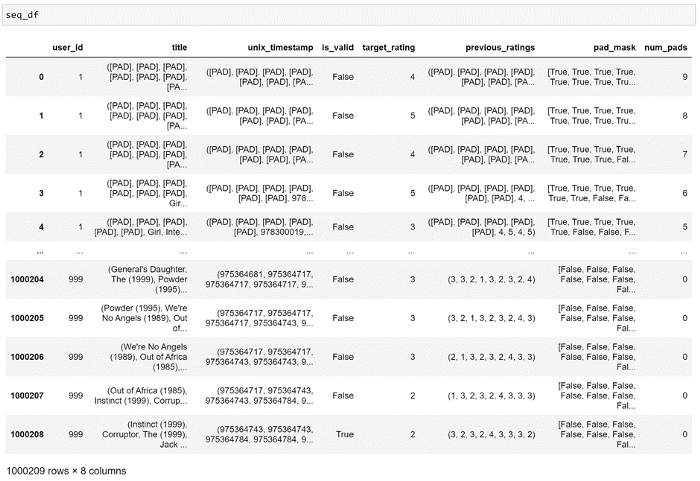
Всё выглядит так, как надо! Разделим эти данные на обучающую и проверочную выборки:

Теперь данные представлены в том формате, который нужен модели-трансформеру.
Обучение модели
Как мы уже видели, прежде чем мы сможем передать эти данные модели, нужно создать поисковую таблицу для кодирования сведений о пользователях и фильмах. Но в этот раз, при создании поисковой таблицы фильмов, нам нужно учесть наличие в данных вспомогательного токена:

Теперь мы работаем с последовательностями оценок, а не с отдельными оценками. Поэтому нужно создать новый класс Dataset, содержащий обработанный DataFrame:
class MovieSequenceDataset(Dataset): def init(self, df, movie_lookup, user_lookup): super().init() self.df = df self.movie_lookup = movie_lookup self.user_lookup = user_lookup def len(self): return len(self.df) def getitem(self, index): data = self.df.iloc[index] user_id = self.user_lookup[str(data.user_id)] movie_ids = torch.tensor([self.movie_lookup[title] for title in data.title]) previous_ratings = torch.tensor( [rating if rating != "[PAD]" else 0 for rating in data.previous_ratings] ) attention_mask = torch.tensor(data.pad_mask) target_rating = data.target_rating encoded_features = { "user_id": user_id, "movie_ids": movie_ids, "ratings": previous_ratings, } return (encoded_features, attention_mask), torch.tensor( target_rating, dtype=torch.float32 )Его можно использовать для создания обучающей и проверочной выборок:

Опишем модель, основанную на трансформере. Для начала, учитывая то, что модель матричной факторизации способна достичь хороших результатов, используя лишь идентификаторы пользователя и фильма, пока включим сюда лишь эти данные:
class BstTransformer(nn.Module): def init( self, movies_num_unique, users_num_unique, sequence_length=10, embedding_size=120, num_transformer_layers=1, ratings_range=(0.5, 5.5), ): super().init() self.sequence_length = sequence_length self.y_range = ratings_range self.movies_embeddings = nn.Embedding( movies_num_unique + 1, embedding_size, padding_idx=0 ) self.user_embeddings = nn.Embedding(users_num_unique + 1, embedding_size) self.position_embeddings = nn.Embedding(sequence_length, embedding_size) self.encoder = nn.TransformerEncoder( encoder_layer=nn.TransformerEncoderLayer( d_model=embedding_size, nhead=12, dropout=0.1, batch_first=True, activation="gelu", ), num_layers=num_transformer_layers, ) self.linear = nn.Sequential( nn.Linear( embedding_size + (embedding_size * sequence_length), 1024, ), nn.BatchNorm1d(1024), nn.Mish(), nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.Mish(), nn.Dropout(0.2), nn.Linear(512, 256), nn.BatchNorm1d(256), nn.Mish(), nn.Linear(256, 1), nn.Sigmoid(), ) def forward(self, inputs): features, mask = inputs encoded_user_id = self.user_embeddings(features["user_id"]) user_features = encoded_user_id encoded_movies = self.movies_embeddings(features["movie_ids"]) positions = torch.arange( 0, self.sequence_length, 1, dtype=int, device=features["movie_ids"].device ) positions = self.position_embeddings(positions) transformer_features = encoded_movies + positions transformer_output = self.encoder( transformer_features, src_key_padding_mask=mask ) transformer_output = torch.flatten(transformer_output, start_dim=1) combined_output = torch.cat((transformer_output, user_features), dim=1) rating = self.linear(combined_output) rating = rating.squeeze() if self.y_range is None: return rating else: return rating * (self.y_range[1] - self.y_range[0]) + self.y_range[0]Видно, что, по умолчанию, мы передаём модели последовательность эмбеддингов фильмов в единственный слой трансформера. Делается это до объединения выходных данных с признаками пользователей (здесь — это лишь ID пользователя). Эти данные мы используем в качестве входных данных полносвязной сети. В данном случае мы применяем простое позиционное кодирование, модель учится представлять последовательность, в которой оцениваются фильмы. Использование подходов, основанных на синусе или косинусе, не дало в моих экспериментах никаких преимуществ, но, если интересно — можете это попробовать.
И, как и прежде, определим обучающую функцию для этой модели. Она, за исключением инициализации моделей, идентична той, что мы применяли при обучении модели матричной факторизации.
def train_seq_model(): model = BstTransformer( len(movie_lookup), len(user_lookup), sequence_length, embedding_size=120 ) loss_func = torch.nn.MSELoss() optimizer = torch.optim.AdamW(model.parameters(), lr=0.01) create_sched_fn = partial( torch.optim.lr_scheduler.OneCycleLR, max_lr=0.01, epochs=TrainerPlaceholderValues.NUM_EPOCHS, steps_per_epoch=TrainerPlaceholderValues.NUM_UPDATE_STEPS_PER_EPOCH, ) trainer = Trainer( model=model, loss_func=loss_func, optimizer=optimizer, callbacks=( RecommenderMetricsCallback, *DEFAULT_CALLBACKS, SaveBestModelCallback(watch_metric="mae"), EarlyStoppingCallback( early_stopping_patience=2, early_stopping_threshold=0.001, watch_metric="mae", ), ), ) trainer.train( train_dataset=train_dataset, eval_dataset=valid_dataset, num_epochs=10, per_device_batch_size=512, create_scheduler_fn=create_sched_fn, )Для запуска обучения модели можем воспользоваться функцией notebook_launcher:

После шести эпох обучения мы получили следующие результаты:

Тут видно значительное преимущество трансформеров перед матричной факторизацией.
Так как начало проявляться переобучение модели, коллбэк остановил обучение довольно рано и загрузил веса, с которыми модель показала наилучшие результаты.
Добавление дополнительных данных
До сих пор мы прогнозировали оценку, принимая во внимание лишь идентификатор пользователя и последовательность идентификаторов фильмов. Кажется вполне вероятным то, что учёт информации о предыдущих оценках, выставленных пользователем, может повысить качество модели. К счастью, учёт этой информации организовать несложно, наш набор данных уже способен возвращать нужные данные. Подстроим архитектуру модели под новые условия:
class BstTransformer(nn.Module): def init( self, movies_num_unique, users_num_unique, sequence_length=10, embedding_size=120, num_transformer_layers=1, ratings_range=(0.5, 5.5), ): super().init() self.sequence_length = sequence_length self.y_range = ratings_range self.movies_embeddings = nn.Embedding( movies_num_unique + 1, embedding_size, padding_idx=0 ) self.user_embeddings = nn.Embedding(users_num_unique + 1, embedding_size) self.ratings_embeddings = nn.Embedding(6, embedding_size, padding_idx=0) self.position_embeddings = nn.Embedding(sequence_length, embedding_size) self.encoder = nn.TransformerEncoder( encoder_layer=nn.TransformerEncoderLayer( d_model=embedding_size, nhead=12, dropout=0.1, batch_first=True, activation="gelu", ), num_layers=num_transformer_layers, ) self.linear = nn.Sequential( nn.Linear( embedding_size + (embedding_size * sequence_length), 1024, ), nn.BatchNorm1d(1024), nn.Mish(), nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.Mish(), nn.Dropout(0.2), nn.Linear(512, 256), nn.BatchNorm1d(256), nn.Mish(), nn.Linear(256, 1), nn.Sigmoid(), ) def forward(self, inputs): features, mask = inputs encoded_user_id = self.user_embeddings(features["user_id"]) user_features = encoded_user_id movie_history = features["movie_ids"][:, :-1] target_movie = features["movie_ids"][:, -1] ratings = self.ratings_embeddings(features["ratings"]) encoded_movies = self.movies_embeddings(movie_history) encoded_target_movie = self.movies_embeddings(target_movie) positions = torch.arange( 0, self.sequence_length - 1, 1, dtype=int, device=features["movie_ids"].device, ) positions = self.position_embeddings(positions) encoded_sequence_movies_with_position_and_rating = ( encoded_movies + ratings + positions ) encoded_target_movie = encoded_target_movie.unsqueeze(1) transformer_features = torch.cat( (encoded_sequence_movies_with_position_and_rating, encoded_target_movie), dim=1, ) transformer_output = self.encoder( transformer_features, src_key_padding_mask=mask ) transformer_output = torch.flatten(transformer_output, start_dim=1) combined_output = torch.cat((transformer_output, user_features), dim=1) rating = self.linear(combined_output) rating = rating.squeeze() if self.y_range is None: return rating else: return rating * (self.y_range[1] - self.y_range[0]) + self.y_range[0] Для использования данных об оценках мы добавили дополнительный слой эмбеддинга. Затем, для каждого ранее оценённого фильма, мы складываем эмбеддинг фильма, позиционную кодировку и эмбеддинг оценки, после чего передаём соответствующую последовательность трансформеру. Ещё данные по оценке могут быть конкатенированы с эмбеддингом фильма, их можно и умножить друг на друга, но их сложение дало лучший результат из всех испытанных мной подходов.
Так как Jupyter, в интерактивном режиме, поддерживает определения классов в актуальном состоянии, нам не надо обновлять функцию обучения. При запуске обучения будет использован новый класс:

После восьми эпох обучения получен следующий результат:

Получается, что применение в модели данных об оценках немного улучшило качество модели.
Добавление признаков пользователей
В дополнение к данным об оценках, у нас ещё есть некоторые дополнительные данные о пользователях, которые мы тоже можем добавить в модель. Для того чтобы вспомнить что к чему — взглянем на таблицу с данными о пользователях:
Попытаемся добавить в модель категориальные переменные, представляющие пол (sex), возрастную группу (age_group) и род деятельности пользователя (occupation). Посмотрим, даст ли это какие-нибудь улучшения. Столбец occupation уже, похоже, представлен в виде последовательно расположенных чисел, то же самое надо сделать для столбцов sex и age_group. Тут можно воспользоваться функцией LabelEncoder из scikit-learn. Перекодированные столбцы присоединим к нашему объекту DataFrame:

Теперь все необходимые признаки закодированы. Присоединим признаки пользователей к объекту DataFrame с последовательностями данных, после чего приведём в актуальное состояние обучающую и проверочную выборки.

Включим эти признаки в наш класс Dataset:
class MovieSequenceDataset(Dataset): def init(self, df, movie_lookup, user_lookup): super().init() self.df = df self.movie_lookup = movie_lookup self.user_lookup = user_lookup def len(self): return len(self.df) def getitem(self, index): data = self.df.iloc[index] user_id = self.user_lookup[str(data.user_id)] movie_ids = torch.tensor([self.movie_lookup[title] for title in data.title]) previous_ratings = torch.tensor( [rating if rating != "[PAD]" else 0 for rating in data.previous_ratings] ) attention_mask = torch.tensor(data.pad_mask) target_rating = data.target_rating encoded_features = { "user_id": user_id, "movie_ids": movie_ids, "ratings": previous_ratings, "age_group": data["age_group_encoded"], "sex": data["sex_encoded"], "occupation": data["occupation"], } return (encoded_features, attention_mask), torch.tensor( target_rating, dtype=torch.float32 )
Модифицируем архиртектуру модели, включив в неё эмбеддинги для этих признаков и конкатенировав эти эмбеддинги с выходом трансформера. Потом передадим их в сеть прямого распространения.
class BstTransformer(nn.Module): def init( self, movies_num_unique, users_num_unique, sequence_length=10, embedding_size=120, num_transformer_layers=1, ratings_range=(0.5, 5.5), ): super().init() self.sequence_length = sequence_length self.y_range = ratings_range self.movies_embeddings = nn.Embedding( movies_num_unique + 1, embedding_size, padding_idx=0 ) self.user_embeddings = nn.Embedding(users_num_unique + 1, embedding_size) self.ratings_embeddings = nn.Embedding(6, embedding_size, padding_idx=0) self.position_embeddings = nn.Embedding(sequence_length, embedding_size) self.sex_embeddings = nn.Embedding( 3, 2, ) self.occupation_embeddings = nn.Embedding( 22, 11, ) self.age_group_embeddings = nn.Embedding( 8, 4, ) self.encoder = nn.TransformerEncoder( encoder_layer=nn.TransformerEncoderLayer( d_model=embedding_size, nhead=12, dropout=0.1, batch_first=True, activation="gelu", ), num_layers=num_transformer_layers, ) self.linear = nn.Sequential( nn.Linear( embedding_size + (embedding_size * sequence_length) + 4 + 11 + 2, 1024, ), nn.BatchNorm1d(1024), nn.Mish(), nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.Mish(), nn.Dropout(0.2), nn.Linear(512, 256), nn.BatchNorm1d(256), nn.Mish(), nn.Linear(256, 1), nn.Sigmoid(), ) def forward(self, inputs): features, mask = inputs user_id = self.user_embeddings(features["user_id"]) age_group = self.age_group_embeddings(features["age_group"]) sex = self.sex_embeddings(features["sex"]) occupation = self.occupation_embeddings(features["occupation"]) user_features = user_features = torch.cat( (user_id, sex, age_group, occupation), 1 ) movie_history = features["movie_ids"][:, :-1] target_movie = features["movie_ids"][:, -1] ratings = self.ratings_embeddings(features["ratings"]) encoded_movies = self.movies_embeddings(movie_history) encoded_target_movie = self.movies_embeddings(target_movie) positions = torch.arange( 0, self.sequence_length - 1, 1, dtype=int, device=features["movie_ids"].device, ) positions = self.position_embeddings(positions) encoded_sequence_movies_with_position_and_rating = ( encoded_movies + ratings + positions ) encoded_target_movie = encoded_target_movie.unsqueeze(1) transformer_features = torch.cat( (encoded_sequence_movies_with_position_and_rating, encoded_target_movie), dim=1, ) transformer_output = self.encoder( transformer_features, src_key_padding_mask=mask ) transformer_output = torch.flatten(transformer_output, start_dim=1) combined_output = torch.cat((transformer_output, user_features), dim=1) rating = self.linear(combined_output) rating = rating.squeeze() if self.y_range is None: return rating else: return rating * (self.y_range[1] - self.y_range[0]) + self.y_range[0]Запустим обучение модели, в ходе которого теперь используются новые признаки. Через семь эпох мы получили следующие результаты:
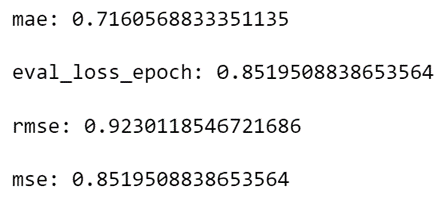
Здесь видно небольшое уменьшение показателя MAE, но при этом MSE и RMSE немного выросли. Похоже, что включение новых признаков в модель незначительно влияет на её качество.
Итоги
Сведём в таблицу результаты работы всех моделей.
|
Модель |
MAE |
MSE |
RMSE |
|
Базовая |
0,912 |
1,530 |
1,237 |
|
Матричная факторизация |
0,890 |
1,316 |
1,147 |
|
Трансформер |
0,726 |
0,862 |
0,928 |
|
Трансформер (со сведениями об оценках) |
0,718 |
0,851 |
0,922 |
|
Трансформер (со сведениями об оценках и с признаками пользователей) |
0,716 |
0,852 |
0,923 |
Главной моей целью при написании этой статьи было испытание этих подходов и показ того, как ими можно пользоваться. Поэтому я выбрал гиперпараметры, в каком-то смысле, случайным образом. Вполне вероятно то, что некоторая подстройка гиперпараметров и применение других комбинаций признаков могут привести к улучшению качества моделей.
Надеюсь, мой материал стал для вас хорошим введением в тему использования матричной факторизации и трансформеров в PyTorch, а так же — в тему ускорения обучения различных моделей с помощью pytorch-accelerated.
Напомню, что код к этому материалу можно найти здесь.
О, а приходите к нам работать? ?
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
ссылка на оригинал статьи https://habr.com/ru/company/wunderfund/blog/645921/
Добавить комментарий