
Массовый переход от монолитов к микросервисам решает ряд проблем:
-
раздельный деплой и рефакторинг;
-
удобное масштабирование частей системы;
-
прозрачное разграничение ответственности команд;
-
снижение бласт-радиуса;
-
снижение когнитивной нагрузки на разработчика.
При этом создает другие проблемы: взаимодействие сервисов существенно сложнее и дороже, чем взаимодействие объектов в памяти. Частично упростить его можно с помощью протокола gRPC.
gRPC дает возможность зафиксировать в репозитории контракты межсервисных вызовов, строгую типизацию, стриминг, кросс-платформенную кодогенерацию и множество других полезных для межсервисного общения вещей.
Из этой статьи вы узнаете, когда стоит применять gRPC, а когда лучше воздержаться, как решаются типичные задачи, включая конфигурирование, отладку, healthcheck, а также то, о чем умалчивает документация.
По материалам выступления на конференции DotNext:
Меня зовут Михаил Кузнецов, сейчас я senior engineering manager платформы автоматизации маркетинга Mindbox.
Основы gRPC: что это такое и какие проблемы решает
Что такое gRPC. gRPC — кросс-платформенный протокол удаленного вызова процедур от Google. Транспорт осуществляется по HTTP/2. Неплохо поддерживается в .NET Core, начиная с версии 3.1. В версии .NET 5.0 появилось много расширений и дополнительных настроек — всё стало еще лучше.
Какую проблему решает. В течение последних лет многие компании стараются уйти от монолитов к микросервисам. А в ответ получают много сетевых вызовов, у которых есть ряд недостатков:
-
Сложнее с точки зрения кода. Если экземпляр класса А вызывает экземпляр класса В, то это достаточно тривиально. Если это сетевой вызов, надо сериализовать пейлоад и получить ответ, в котором возможны сетевые ошибки. Этот пейлоад также нужно отправить в канал и получить из канала. В общем, требуется достаточно много действий.
-
Хуже перформанс. Вызвать function call намного дешевле, чем гонять параметры и результаты работы по сети.
-
Усложняется обработка ошибок. Появляется сразу несколько дополнительных слоев, где что-то может пойти не так. Например, сериализатор сериализовал не так (формат даты / числа с точкой вместо запятой / snake_Case вместо PascalCase), или «икнула» сеть, или сервис не отвечает, или сервис отвечает, но слишком долго.
В качестве альтернативы синхронного взаимодействия иногда возникает желание использовать шины данных, брокеры (Kafka, RabbitMQ и аналоги), потому что зачастую они уже есть в инфраструктуре и проблему кое-как решают. Этот подход не очень удобный: асинхронный eventual consistency-вариант вместо синхронного вызова — это костыль.
Чем gRPC лучше REST. У REST сразу несколько недостатков:
-
REST — не Contract First: сложно управлять контрактами и целостностью API. По сути целостность контрактов нельзя контролировать. Можно прикрутить Swagger, инструмент для генерации документации по коду. То есть у вас уже есть код и генерируется документация. А хотелось бы по понятным причинам наоборот: чтобы код генерировался по документации.
-
Много бойлерплейт-кода: создать HTTP-клиент, HTTP client factory, договориться о сериализации (JSON, XML или другие варианты), учесть различные форматы дат, чисел и так далее, кейсинг. Соответственно, много возможностей для возникновения ошибок — нужно писать DTO-классы специально для транспорта.
-
У REST не очень хороший перформанс в сравнении с gRPC.
-
Использовать REST не очень оптимально с точки зрения сети, потому что будет летать JSON или XML. Правда, этот момент можно улучшить: использовать msgPack или похожие средства оптимизации транспорта.
Что предлагает gRPC
Contract First. Сначала договариваемся о том, что и куда пересылаем, описываем это строго в protobuf-файле, кладем в репозиторий, и, по сути, с этого момента он зафиксирован. При желании от этого решения можно отказаться и пользоваться Code First. Но это применимо, только если у вас весь бэкенд на .NET: можно создать те самые DTO, повесить на них атрибуты привычным вам способом, как с тем же JSON или XML.
Строгая типизация. Если вы пишете на .NET, скорее всего, любите строгую типизацию — здесь она есть 🙂
Автогенерация клиентского и серверного кода. Описываете контракт, используя штатный инструмент во время билда, и у вас создается либо клиент, либо сервер, либо и то и другое — в зависимости от настройки.
Это дает сразу несколько преимуществ:
-
При кодогенерации не нужно писать код самому и поддерживать его.
-
Нельзя сбилдить проект, не поменяв клиент и сервер, если поменялся контракт.
Контракт может развалиться только в одном сценарии: у вас два сервиса (клиент и сервер), и у них разъехались версии, то есть один перебилдился, обновился и задеплоился, а второй — нет. Понятное дело, с этим сложно что-то сделать — только тестировать. Во всех остальных сценариях на билде перегенерируется весь соответствующий код — контракт не развалится.
-
Встроена сериализация из коробки.
Она достаточно эффективна и с точки зрения перформанса, и с точки зрения транспорта: пейлоад, который летает по сети, существенно компактней обычного JSON.
-
У gRPC достаточно лаконично сделана обработка ошибок. Какие-то вещи она маскирует и упрощает, но для практического применения ее вполне достаточно.
-
gRPC предлагает удобный стриминг, то есть возможность создать стрим в любую сторону: с сервера на клиент, с клиента на сервер и даже двунаправленный стрим — дуплекс.
Поддержка в .NET
Библиотека gRPC C#
Это достаточно тонкая обертка вокруг unmanaged-библиотеки. Есть основная библиотека на С++ и оболочка для вызовов на .NET. Она обладает максимальной функциональностью и минимальными удобствами.
Как в любой обертке, из нее торчат уши. Например, все настройки сделаны не в виде строго типизированных свойств с соответствующими ограничениями, а в виде строковых констант. То есть вы передаете строку с названием настройки и строку с ее значением. У вас также будет unmanaged-код, которого обычно хочется избежать: ошибки в unmanaged-коде вызваны как возможными багами самой библиотеки, так и неправильным использованием. Эти ошибки хуже отлавливаются, хуже дебажатся и так далее.
Использовать библиотеку я советую местами, не в продакшене, например писать эмуляторы того, что потом будет в продакшене, подключать для мокирования, для тестов. Стартануть на ней максимально просто, это делается буквально в одну строку.
Альтернативная библиотека gRPC for .NET
Это мейнстримное решение, поддерживаемое Microsoft, — оно подробно описано в документации. Тут быстрый старт немного сложнее, но есть и плюсы: она полностью управляемая. Всё, что вы настраиваете и конфигурируете, строго типизовано. Эта библиотека очень хорошо интегрируется в пайплайны ASP .NET Core, то есть в DI многие вещи получится сделать привычным образом. Дальше рассказывать я буду в основном о ней, потому что это мейнстримное решение.
Транспорт происходит по HTTP2 — не будет сюрпризом, что внутри gRPC-клиента сидит знакомый всем System.Net.Http.HttpClien. Многие настройки транспортного уровня находятся в привычных для всех полях и классах, которые составляют HTTP-клиент. Если эта настройка не выглядит gRPC-специфичной, то, скорее всего, вы найдете ее там же, где и раньше. Это различные таймауты, Keep Alive, авторизация и тому подобные вещи.
Многие серверные gRPC-настройки также настраиваются стандартным способом, как и настройки Kestrel. Если вы делаете gRPC-сервер с помощью gRPC for .NET в .NET-приложении, то конфигурацией Kestrel вы также управляете поведением gRPC-сервера.
Protobuf-контракты
Выглядит это примерно так:
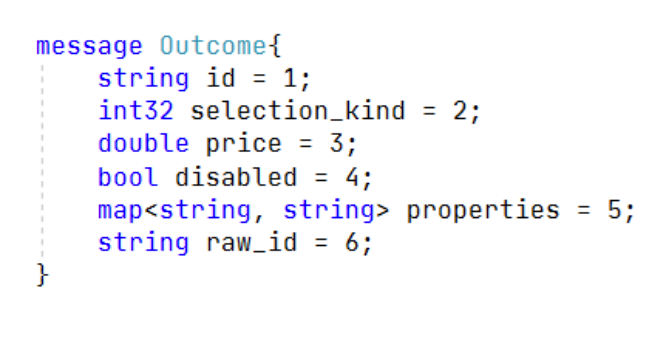
message Outcome{ string id = 1; int32 selection_kind = 2; double price = 3; bool disabled = 4; map<string, string> properties = 5; string raw_id = 6; }Контракт protobuf строго типизованный и строго определяет последовательность полей. Это нужно, например, по причинам совместимости старых и новых версий API. Он поддерживает nullable, коллекции, enum, дефолтные значения, вложенные типы.
Немного чисел: на официальном сайте Google заявляет, что контракт protobuf до 10 раз компактнее, до 100 раз быстрее JSON в сыром виде. Могу сказать, что это похоже на правду: по замерам он кратно компактнее и в 20–30 раз быстрее.
Информация для любителей MessagePack: по бенчмаркам скорость и компактность — на неразличимо близком уровне.
Кросс-платформенность и кодогенерация. Генерируются и клиент, и сервер, и сериализация, и десериализация, и DTO, то есть весь этот слой будет у вас готов — его не нужно писать.
Поддерживается несколько популярных платформ: C#, Go, Java, Python, Kotlin, PHP, Ruby. Поддерживается не только бэкенд — стандартные стеки, но и клиентские мобильные платформы.
Отдельно стоит отметить, что, по опыту, gRPC снимает проблемы с кейсингом, форматированием, опечатками в именах полей. Снимает также проблемы с форматами примитивных типов: дат, чисел и так далее. Это особенно актуально, если на бэкенде существуют разные технологические стеки. Естественно, все ошибки можно отловить на тестировании, но проще вообще не бороться с ними — кодогенерация одним инструментом решает эту проблему.
Код обоих сервисов: и клиента, и сервера будет синхронизирован с их контрактом. Это гарантируется компилятором. С вашей стороны нужно только гарантировать, что если вы поменяли контракт, на стенд выкатываются синхронизированные версии. Это можно обеспечить, например, интеграционными тестами. Все, что уровнем ниже, может быть проверено на compile time.
Альтернативы gRPC
Kafka. Основной минус — если есть topic, на который вы подписываетесь, то вы не можете фильтровать данные и сообщения, которые туда падают. Приходится читать все и разбирать на клиенте.
Приведу пример. Предположим, у нас есть клиент. Он знает ID пользователей и хочет получать информацию только по тем пользователям, которые сейчас онлайн. Очевидно, что онлайн у нас малое количество от всех пользователей, которые есть в базе.
Как это можно было бы сделать с помощью топиков? Сервер отслеживает, кто сейчас онлайн, и скидывает информацию о них в топик, отфильтровывая обновления данных по тем пользователям, которые офлайн.
При этом, если разные клиенты хотят читать про конкретных пользователей, то им всё равно нужно будет выбирать, либо дискардить кучу сообщений, либо заводить по топику на пользователя или по топику на хэш от ID пользователя. А это уже динамические топики, что достаточно сложно и дорого. Если вы пробовали делать тысячи партиций, а топик — это минимум одна партиция в Kafka, то, возможно, уже сталкивались с этой проблемой.
Кроме того, создать и удалить топик — достаточно ресурсоемкая операция, а подписаться на новый топик занимает несколько секунд. В итоге получается очень шаткая и непонятно зачем нужная конструкция. Как это выглядит со стримингом gRPC? Мы создаем стрим типа GetUserInfoById, передаем ID, в ответ получаем стрим по конкретному пользователю.
Если тот, кто кормит нас данными (продюсер), сломался и перестал обновляться, то в случае с Kafka нужны какие-то внешние инструменты, возможно, healthchecks продюсера. Их нужно отслеживать — получается достаточно сложная и хрупкая конструкция. В случае с gRPC все проще: разрывается соединение, клиент узнает об этом очевидным образом и может среагировать на проблему.
OpenAPI. Предлагает контракты: они не обязательны, но их можно использовать. Позволяет осуществлять кодогенерацию клиента, но так как это не gRPC, а сырой HTTP, у него несколько хуже перформанс, нагрузка на сеть несколько выше, а со стримингом все несколько сложнее. Например, там вообще нет дуплекса. В остальном OpenAPI во многом схож с gRPC.
HttpClient.GetStreamAsync. У него тоже есть стриминг, но единственное, что про него можно сказать, — им можно что-то стримить. Остальные потребности он не закрывает: остаются все те же проблемы с типизацией, с контрактами, сериализацией. Все нужно делать вручную, да и сам стрим тоже нужно обслуживать вручную. В общем, вариант достаточно спорный.
Подводные камни gRPC
Издалека все выглядит хорошо, а на деле возникают сложности. Ниже минусы в первом приближении:
Из-за бинарного формата пейлоад не читается человеком. Существуют инструменты, которые умеют читать пейлоад, но отладка немного усложняется.
Не интегрируется с браузерами. Эту проблему можно решить сторонними проектами, их уже два. Первый называется gRPC HTTP API — это, по сути, генерация HTTP end point и контроллера поверх gRPC endpointer. Второй проект называется HTTP Gateway — это отдельно стоящий сервис, который работает как прокси для gRPC-сервиса.
Несмотря на то что с браузерами gRPC не интегрируется, с другими клиентами, то есть с мобильными, он интегрируется и, судя по отзывам, достаточно хорошо.
Нет специальной поддержки бродкаста. В примере с получением информации о пользователе, который мы рассматривали выше, в ситуации «все хотят информацию по одному пользователю», потребовалось бы столько стримов, сколько клиентов захотело получить информацию. Никакой хитрой транспортной оптимизации нет. На сервере и запросы, и стримы независимые.
HealthCheck gRPC-сервиса
Если вы пользуетесь Kubernetes, то знаете, что такое HealthChecks. Если коротко, это endpoints, через которые можно опросить сервис и приблизительно понять, что с ним происходит.
Есть так называемые Liveness/Readiness probes. Первая отвечает на вопрос, жив ли сервис, а вторая — готов ли он обрабатывать наши запросы. Даже если у вас нет Kubernetes, такие эндпойнты могут быть полезны для внешнего мониторинга и логирования состояния сервиса.
Для gRPC-сервисов есть стандарт. Он описан прямо в основном репозитории gRPC. Пакет, реализующий этот стандарт по .NET, называется gRPC HealthCheck. Он несложно устроен: чтобы иметь у себя хелсчеки, надо подключить пакет и реализовать интерфейс. Все, что нужно сделать, когда хотим поменять статус сервиса, — выставить статус специальному объекту healthGrpcService. Статусов всего четыре вида: serving, not_serving, unknown и service_unknown.
Первый параметр string.Empty — название сервиса для ситуации, когда в одном процессе находится несколько независимых gRPC-сервисов. Управлять их статусами можно независимо. Насколько это бьется с микросервисной архитектурой — вопрос. Но инструмент для такой ситуации есть. Вместо string.Empty можно передавать имя сервиса — в пробах будут пропагироваться сервисы, соответствующие своим статусам.
gRPC и KeepAlive
C KeepAlive все оказалось не так просто. Здесь тоже есть стандарт в виде таблицы с описанием:
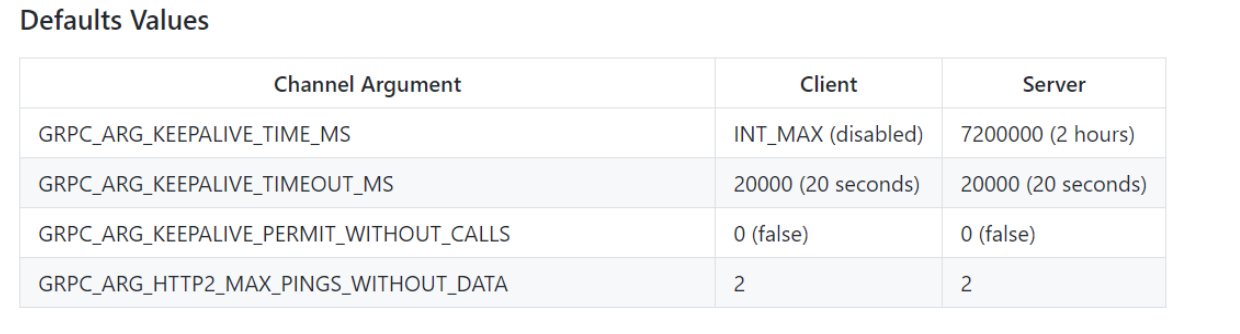
gRPC_ARG_KEEPALIVE_TIME_MS — время, которое проходит между KeepAlive-пингами. По дефолту клиент ждет бесконечно долго: он вообще ничего не шлет, а сервер шлет пинги раз в два часа. Очевидно, это сделано для того, чтобы убивать уснувших или отвалившихся клиентов.
gRPC_ARG_KEEPALIVE_TIMEOUT_MS — время, которое ожидается между тем, как был послан пинг и получен успешный ответ. 20 секунд — достаточно адекватный период.
gRPC_ARG_KEEPALIVE_PERMIT_WITHOUT_CALLS — по умолчанию 0. Это означает, что, если у вас не происходит отправок бизнес-сообщений, то и KeepAlive слаться не будут. Если указан 1, то KeepAlive слаться будут.
gRPC_ARG_HTTP2_MAX_PINGS_WITHOUT_DATA. Регламентирует максимальное количество KeepAlive-пингов, не перемежающихся бизнес-сообщениями.
Резюмируем: по дефолту ничего не шлется. Если сделаем time не бесконечным, а сколько-то секунд, например одну минуту, то раз в минуту у нас будут слаться пинги, но только если происходят постоянные бизнес-вызовы. Если стрим висит достаточно долго, то все равно ничего не будет посылаться. Если мы разрешим отправку, выставив третий параметр в единицу, то пошлется два пинга и после этого опять KeepAlive остановится.
Здесь достаточно неприятный момент: если мы хотим это изменить, то придется передеплоить все серверные gRPC-части. Если мы увеличим gRPC_ARG_HTTP2_MAX_PINGS_WITHOUT_DATA только у клиентов с 2 на 10 или на бесконечность, то после второго сообщения непереконфигурированный сервер будет прекращать обрабатывать стримы, посылать сообщение GOAWAY, и на этом все будет заканчиваться. С точки зрения менеджмента и деплоя, достаточно сложное изменение. Нужно задеплоить все сервера, потом всех клиентов. А если вы хотите что-то поменять или откатить, то придется делать все то же самое, только в обратном порядке.
Инструментарий
При разработке REST API многие пользуются Postman или аналогичными инструментами. Естественно, для gRPC хотелось бы иметь что-то похожее.
Есть BloomRPC. Мы пробовали искать что-то еще, потому что в сравнении с Postman он выглядит слишком примитивно для главного инструмента, решающего задачи отладки сервисов. Но другого инструмента не нашлось. Базовые потребности он закрывает. Так как gRPC работает с протоконтрактами, работа с BloomRPC достаточно простая и удобная. Загружаем протофайл — это сразу дает возможность вызвать конкретный сервер, выбрать endpoint. У нас все готово для того, чтобы вбить значение в пейлоад. Нужно только указать URL, куда мы будем коннектиться.
Немного о производительности
Я говорил о Protobuf, но это не все, что определяет протокол. Есть еще затраты в .NET-коде: распарсить, сериализовать, послать, получить и так далее. Я намеренно не хотел синтетики, числа будут из реального приложения, но достаточно легковесно обрабатывающего каждое конкретное сообщение.
Накладные расходы на gRPC даже на фоне легковесной обработки практически не измеримы. Это проценты от миллисекунд. С другой стороны, минимум сотни сообщений, обработанные на одном ядре в секунду. Помимо самого gRPC, происходит бизнес-обработка, мы что-то складываем в Mongo, продьюсим в Kafka, что-то считаем. С учетом накладных расходов на gRPC мы наблюдали сотни сообщений в секунду, что нас вполне устраивало.
Мы столкнулись с проблемами не самого gRPC, а LargeObjectsHeap: если посылать действительно большие сообщения, большие пейлоады, у вас будет фрагментироваться LOH и будут происходить частые сборки мусора во втором поколении. С этим ничего не сделать, только уменьшать размер сообщения до вменяемого, бить на чанки, делать рефакторинг, иногда что-то менять по бизнесу.
Еще в обновлении библиотеки появился extension class UnsafeByteOperations. Он позволяет хотя бы на клиенте не копировать большой пейлоад в большой пейлоад формата gRPC, который потом полетит по сети, а взять готовый массив с большим пейлоадом, легковесно обернуть его и передать. На мой взгляд, это все равно достаточно слабое решение, потому что для серверной части UnsafeByteOperationsвообще нет. Скорее всего, проблемы останутся.
Мы поднимали две ноды, клиентскую и серверную, большое количество стримов, эмулировали некоторую нагрузку. Удавалось параллельно выдержать несколько десятков тысяч gRPC-стримов, которые еще и посылают сообщения, а не просто висят мертвым грузом, но посылают их не слишком часто, раз в несколько секунд. Тем не менее десятки тысяч стримов между нодами работали хорошо. Ни по памяти, ни по CPU безумных чисел не было, речь шла о нескольких ядра и паре Гб в режиме работы, то есть когда нагрузка спадает, то и расход памяти существенно сокращается.
Подведем итоги
Если у вас .NET Core 3.1 и выше, микросервисы на бэкенде, они написаны на разных стеках и всё это причиняет боль, стоит рассмотреть gRPC, оценить его применимость для вашего проекта. Возможно, он будет вам полезен.
Следующая .NET-конференция DotNext пройдет онлайн 7 и 8 апреля.
ссылка на оригинал статьи https://habr.com/ru/company/mindbox/blog/597183/
Добавить комментарий