Вступление
У меня бывают ситуации на проектах, когда нужна база данных какой-то статической информации. Но увы, пошарив в интернетах, какого то публичного хранилища найти не удалось, но тем не менее, я вижу кучу ресурсов, которые это используют.
В моем случае мне понадобилась база данных пород кошек, но среди этих примеров может быть что угодно, от базы данных имен, названия городов, областей и т.д. Эта статья о базовых подходах и практиках парсинга данных с веб ресурсов.
Хочу подметить, что хоть в моих жилах течет дотнет, в этом примере я буду использовать Node JS, потому что так быстрее, и удобнее в плане парсинга. Чем именно удобней — я расскажу позже в статье.
Можем ли мы спарсить?
Да, к сожалению(или счастью) веб — он не однообразен, и каждый ресурс может быть уникален по своему, но в нашем деле, ключевым моментом будет то, есть ли на этом ресурсе Server-Side Rendering(SSR), или там Client-Side Rendering и важная для нас информация подтягивается позже с помощью JS.
К примеру, нативные апки на React или тот же Angular by default есть CSR. И что бы прикрутить там SSR нужно порой очень сильно попотеть. Тем не менее, большинство сайтов с топ серч результатов любой поисковой системы будут поддерживать именно SSR, потому что таков мир SEO оптимизаций.
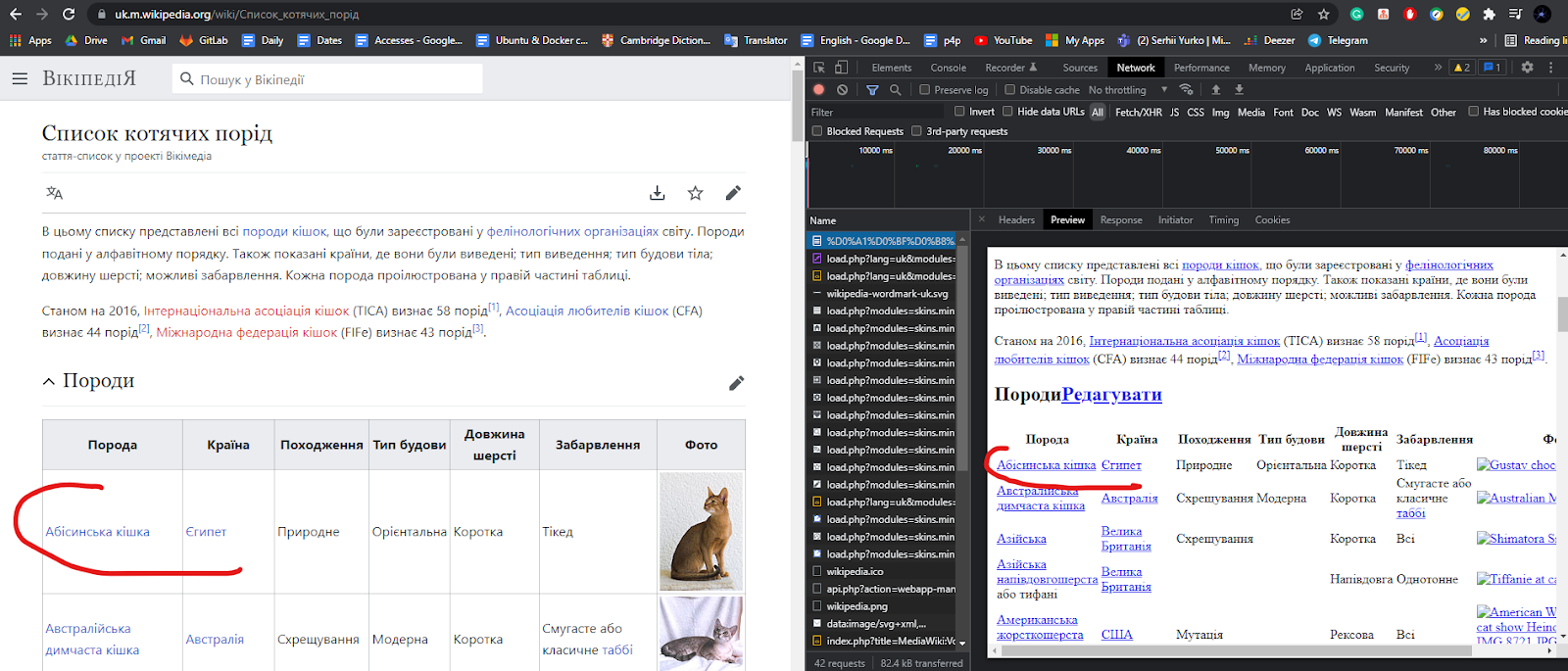
В моем примере, страница, которую будем парсить — это простая вики страница:
Мы можем видеть, что эта страница использует SSR, ибо в первом запросе, мы видим, что информация о породах уже есть в ответе от сервера.
Как будем парсить?
Перед тем, как начать парсить, давайте сначала определимся, что именно будем парсить. В моем примере — мне нужны были названия и фото пород. Названия я потом переводил на английский и русский, а фотки сохранял в директории с приложением. К слову, потом это все перегонялось в Postgres похожим скриптом.
Первое, что нужно сделать — это заинспектить нужные элементы страницы через тулзы браузера (в моем случае хром).


Кликаем на выбранный элемент и смотрим HTML в сайдбаре тулзов.

Как вы видите, мы имеем дело со стандартной таблицей, и для парсинга названия породы все, что нам нужно сделать — это спарсить необходимые нам <td> для каждого <tr>.

Фото также находится на одном из <td> тегов. Убеждаемся, что сорс фото валидный, и у нас есть доступ туда без никакой авторизации и прочих вещей.
Начнем парсить!
Создадим папку с проектом и в руте создадим main.js.
Потом с рута проекта открываем терминал и пишем:
npm init

Можете пропустить все, что спрашивается там, это неважно в нашем случае.
Для нашего апликейшена нам будут нужны axios для HTTP запросов, node-html-parser, чтобы парсить html, fs.promises для асинхронных колов файловой системы, google-translate-api, для перевода с украинского.
В терминале пишем следующую команду:
npm install axios node-html-parser @vitalets/google-translate-api —save
Дальше пишем такой код в нашем мейн файле:
Как вы видите, мы определили наши константы, библиотеки, которые собираемся использовать и асинхронный мейн, чтобы писать чистый и асинхронный код.
Теперь, чтобы спарсить контент с этой страницы, мы должны ее как-то получить. Мы просто сделаем GET запрос к ней и получим наш HTML.
Дальше, что мы можем сделать с нашим HTML? Есть несколько вариантов парсинга: XPath и нативные JS querySelector & getElementsBy. Я использовал querySelector ибо это упрощает написание парсера, потому что это легче тестировать(чуть ниже я покажу каким образом), лично мне больше понятен его синтаксис нежели синтаксис XPath.
Что же, давайте попробуем написать селектор для нашего имени. И вот тут и проявляется вся прелесть выбора querySelector, потому что мы просто идем в тулзы для девов в браузере, и там все это тестируем.
Тут я выпарсил все <tr>.

Как только “подобрали” правильный селектор, просто копипастим это в апку в какую-то константу.
Как мы видим, мы должны исключить первый и последний элемент.


Давайте теперь напишем ещё вспомогательный метод, который будет проверять, существует ли папка или файл по заданному пути, ну и добавим нашу константу.
Следом за этим — напишем логику, которая будет парсить все наши строки:
В коде выше — мы создали директорию для фото, взяли HTML через риквест на CAT_URL, и потом спарсили все <tr> теги. Теперь в Promise.all мы можем отдельно парсить каждую строку.
Теперь давайте поиграем с селекторами еще, чтобы взять имя породы:

Как вы видите, внутри <tr> тега мы должны следовать за <td> тегом и взять текст тега <a>.

Посмотрим, что мы можем использовать для парсинга фото:


Как же мы можем быть уверены, что можем это спарсить с нашей хтмл?
Мы можем скачать эту HTML любым удобным способом (cURL, Postman) и проверить, есть ли там фотка.
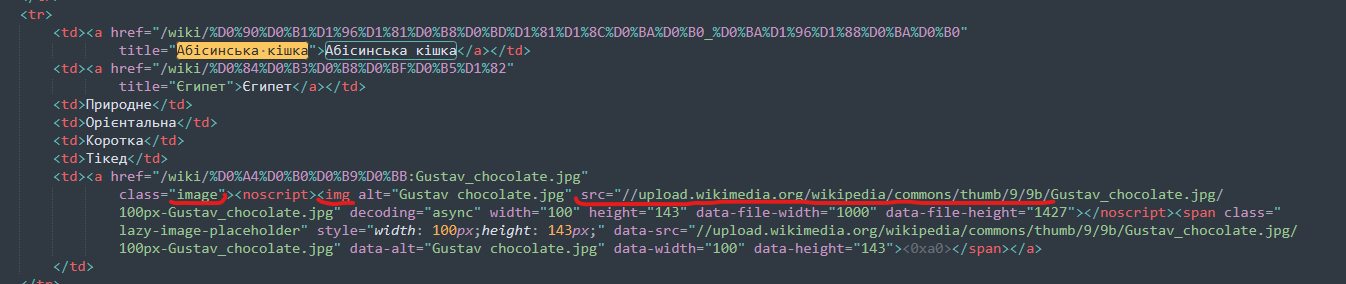
И конечно же, там нету элемента с классом ‘.image-lazy-loaded’. Но как решение, мы можем взять элемент с классом ‘.image’ потом взять тег <noscript> и из его дочернего элемента взять сорс фото.
Добавим нужные селекторы в код:
В коде, мы проверяем, есть ли уже у нас фото с названием породы (возможно апка будет запускаться множество раз, чтобы лишний раз не делать риквест на вики), и если нету мы скачиваем фото в локальную директорию.
Так же проверяем, есть ли фотка у породы вообще, потому что ее может не быть

Теперь создадим метод, который будет скачивать. Так же нам понадобиться юзерагент википедии, потому что после нескольких скачиваний, у меня начали падать ошибки, и они пофиксились добавлением этого хедера.
Последнее, что нужно сделать, после того, как мы скачали фото — это перевести название породы, сохранить это название в файлике.
Я также отделил создание новой строки в отдельный метод, потому что это платформ специфик штука.
Попробуем же это все запустить с командой:
node main.js
Весь код солюшна:
Результаты

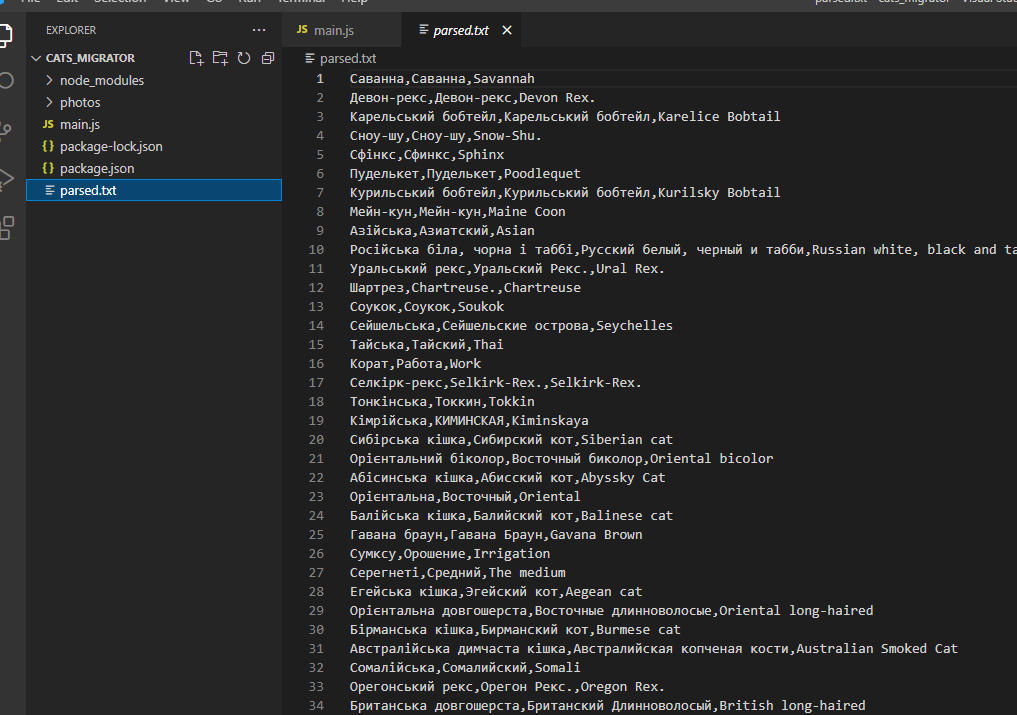
Перевод не такой классный, как мог бы быть, но это уже не проблема парсинга, а проблема процессинга.
Я еще сделал видео, демонстрирующее написанное в статьи, если хочеться увидеть процесс вживую — https://www.youtube.com/watch?v=HqJlRM-7osU&t=30s&ab_channel=andreyka26_programmer
ссылка на оригинал статьи https://habr.com/ru/post/646117/
Добавить комментарий