Подбираем эффективную конфигурацию под ваши нужды

Disclaimer. В статье рассмотрим конфигурацию, которую вы можете внедрить в свои проекты. При этом помните про несколько факторов:
• Результат может варьироваться, если используются разные серверные машины.
• Избыток ресурсов — это не всегда хорошо.
• Оптимизация железа должна идти бок о бок с оптимизацией тестов.
Всем привет! Меня зовут Иван Левиков, я старший инженер по тестированию.
ВКонтакте развиваю и ускоряю автотесты, анализирую и улучшаю инфраструктуру, создаю новые решения.
При проектировании инфраструктуры для автотестов на Android приходится искать ответы на вопросы о том, где можно их запускать и где лучше это делать.
Рассмотрим самые популярные места для запуска автотестов:
-
облачные решения;
-
решения на физических девайсах.
Облачные решения
В этой категории много предложений от разных компаний, например:
-
Amazon,
-
Firebase Test Lab,
-
Huawei DigiX Lab,
-
Remote Test Lab от Samsung,
-
и другие.
Говоря обобщённо, можно выделить такие преимущества и недостатки ферм из облачных решений ↓

В интернете много обзоров, так что не будем останавливаться на этом.
Если не хотите использовать внешние решения, а стремитесь построить что-то своё, можно обратиться к связке из OpenSTF и физического девайса или к эмуляторам андроид-устройств. Остановимся на каждом варианте чуть подробнее.
OpenSTF + физический девайс
В нашем опыте будет фигурировать Samsung Galaxy S20+ (6 ядер, 8 гигов). По характеристикам это достаточно мощный девайс (см. рейтинг производительности), и его ПО будет обновляться ещё долго. Берём в эксперимент.

Так выглядел один из первых прототипов нашей фермы. Собран из смартфонов Samsung, которые питаются через USB hub и подключены к ноутбуку с локально развёрнутой OpenSTF. Можно поиграть в «Отгадай модель устройства по фото».
Так мы и жили довольно долго, управляя физическими девайсами через OpenSTF. При очевидных преимуществах были и сложности — перечисляю их ниже.

Мы сталкивались с множеством проблем: это, например, очистка данных, закрытие всплывающих окон, падение производительности и непонятные флаки тестов. Если остальные недочёты мы рутинно побеждали, то дебаг и отладка флакующих тестов стали ресурсоёмкими задачами. В одних случаях это было связано с текущим состоянием устройства, а в других — казалось, что с фазой Луны и ретроградным Меркурием.

Ферма с виртуальными Android-девайсами
Мы решили провести разные эксперименты, чтобы повысить стабильность. В первую очередь — улучшить нашу ферму, но не за счёт покупки новых физических девайсов, как обычно, а создав параллельно ферму эмуляторов.

В итоге мы остановились на конфигурации с виртуальными андроид-девайсами. Начали с построения фермы из связки уже знакомой нам OpenSTF и эмуляторов QEMU. В стандартной комплектации из коробки у наших эмуляторов было по 2 виртуальных ядра и 4 гига оперативной памяти. В целом по производительности и жизнеспособности они нас устраивали. Но для некоторых ситуаций необходимо было создавать собственные решения: например, для превентивного прогнозирования возможной деградации эмулятора и падений тестов из-за этого. Винрейт (соотношение между упавшими и пройденными тестами) в исходном состоянии из коробки в среднем был около 65%, и автотесты при этом находили баги.

Ищем оптимальную конфигурацию железа для эмуляторов
Но положение дел меня по-прежнему не устраивало, так что я отправился в длинное приключение в поисках стабильности. Цель: найти оптимальную конфигурацию железа для эмуляторов. Обнаружил пару статей и readme в репозитории Google: там рекомендовали использовать конфиг на 4 виртуальных ядра и 12 гигов оперативной памяти. Мне стало интересно, почему так. А что будет, если дать больше или меньше?
Меня заинтриговали эти вопросы, так что я решил погрузиться в них. Казалось бы, чего здесь долгого — придумать способ для оценки производительности и сравнить между собой несколько конфигураций.

Но всё оказалось не так просто: в процессе работы пришлось делать много анализов производительности, искать причины появления ООМ (Out of memory). Поэтому простым это путешествие было не назвать. Оно стало тем самым «20-minute adventure» — на полгода ?

Я сравнивал производительность эмуляторов и физических девайсов, чтобы понять, куда мы движемся и не становится ли хуже. Выяснил, что в текущей конфигурации разница во времени прогона автотестов между эмулятором и физическим устройством составляет всего 12%. Может показаться, что это много, но у меня было чёткое ощущение, что мы можем выжать больше. Сейчас расскажу, как мы это сделали!
В начале экспериментов я тестировал много конфигураций серверных машин, которые используются ВКонтакте: начиная от старичков Xeon E5-2680 и заканчивая Xeon Gold 6283. Как это часто бывает, самое крутое железо не всегда было лучшим для наших задач. Так и получилось с Xeon Gold: классной частоты процессора можно было достичь только при срезании части ядер. Иначе под нагрузкой частота могла плавать даже до 0,8 GHz. Плюс существенную роль играет объём кеша уровня L3.

После первых подходов мы оценили результаты и решили остановиться на старом добром E5-2680. Так мы выбрали серверные машины для следующего этапа.
Собирая серверные машины для экспериментов, я сформулировал для себя следующие вопросы ↓

Представим, что все машины собраны, эмуляторы подготовлены. Что делать дальше? Правильно, собираем сьют автотестов для оценки производительности, связанных с разными разделами нашего приложения. Так за короткое время получим больше данных, максимально приближенных к реальным.

За эталон возьмём время прогона на хорошо известном нам физическом устройстве — S20+.

Эмуляторы собраны, конфигурации определены. Начинаем!
На первом этапе мы оценивали изменение времени прогона на каждой из этих конфигураций. В первом туре, в сравнении с S20+, получилась такая таблица.

На подведении недельных итогов спринта мы с командой обсудили показатели и сошлись во мнении, что результаты получаются интересными и надо продолжать эксперименты, расширяя тестируемые значения.
Казалось бы, давайте брать и внедрять самый мощный конфиг, чтобы гонять тесты на 30% быстрее. Но не всё так однозначно, потому что в нашем уравнении до сих пор несколько неизвестных. Копаем дальше!
На разных устройствах и эмуляторах я сталкивался с ситуацией, когда автотест падает, допустим, после шестого беспрерывного прогона. А где-то — после третьего. Или вообще не падает за первые десять прогонов. Это навело меня на мысль, что стабильность автотестов зависит ещё и от конфигурации железа. Эту гипотезу необходимо было проверить, прежде чем двигаться дальше. В результате экспериментов обнаружились такие закономерности падения тестов.
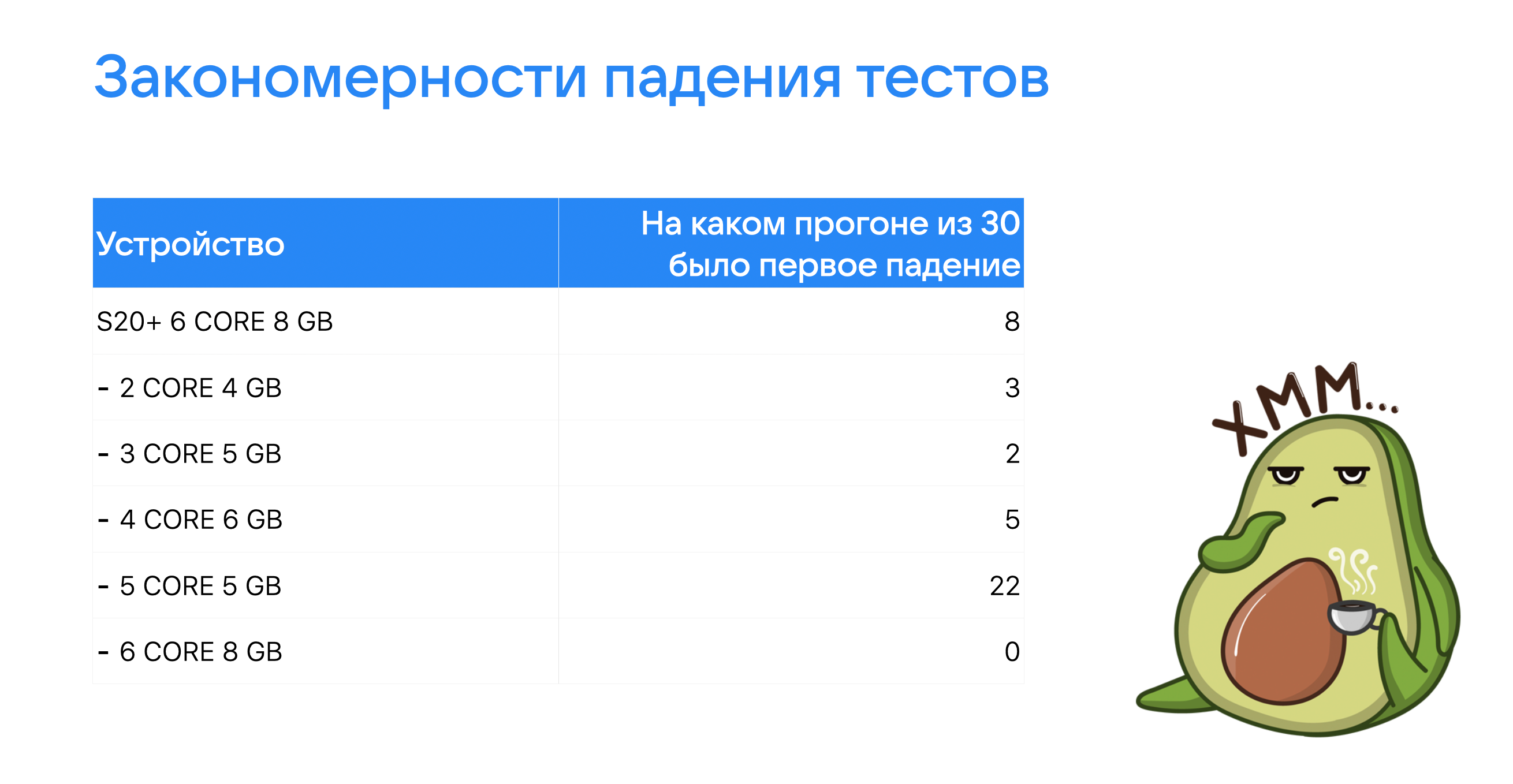
Это выглядит уже интереснее! В наш шорт-лист врываются три конфигурации: 6 ядер, 5 ядер и 4 ядра. Попробуем понять, какая из них может быть нам интересна и почему. Для этого расширим конфигурации в рамках 4 и 5 ядер, докинув эмуляторам оперативной памяти.

Неплохо, неплохо. Получается, что нашим минимальным номинантом точно будет конфигурация из 5 виртуальных ядер и 5 или 6 гигов оперативной памяти. Попробуем отталкиваться от этих значений.
Во время прогонов эмуляторы иногда самопроизвольно отключались — и мы ломали над этим голову. Детально изучили логи и графики из мониторинга и поняли, что это банальное ООМ. Значит, эмулятору недостаточно N гигов оперативной памяти, которое мы выделяем ему?
Да, всё так. Когда создаётся более мощный конфиг, потребляется больше ресурсов — так что для беспроблемной работы нужно резервировать ещё больше, чем мы выделяем. В процессе прогона автотестов наши эмуляторы разгонялись не сразу, а постепенно, при этом иногда уходя резко вверх. С помощью экспериментов мы поняли, что для спокойного существования эмуляторам желательно закладывать дополнительные ресурсы: минимум 1,5 гига оперативной памяти и 1 ядро vCPU плюсом к уже выделенным. Это пригодится для java heap и нужд пода. А в целом такое решение позволит сгладить скачки, увеличит жизнеспособность эмуляторов и обезопасит вас от нестабильности в тестах из-за железа.
Что внедряем в итоге (и что при этом учитываем)
Мы останавливаемся на базовом внедрении конфига эмулятора в 6 VCPUS / 6 GB и добавляем сверху минимум 1,5 гига оперативной памяти. По расчётам ожидаем, что в сравнении с нынешним конфигом эмулятора новый позволит нам ускориться на 20% и больше. А главное, он повысит стабильность прогонов автотестов — и мы будем увереннее в них.
Дальше коротко поделюсь выводами.
Вот о чём важно не забыть, когда внедряете конфиг в своём проекте ↓

А вот что стоит учесть, планируя эксперименты:
-
Можно отталкиваться от конфигурации с 5 или 6 виртуальными ядрами для мощного эмулятора и от 5,5 гигов RAM под эмулятор.
-
Разрыв между ядрами начал уменьшаться после 5 ядер (разница между 5 и 6 около 1,5 %).
-
Увеличение ОЗУ на 1 гигабайт даёт ускорение до + 0,5%.
-
Избыток ресурсов — это не всегда хорошо.
-
При изменении в железе эти значения тоже могут стать другими.
Какие конфигурации используете и во сколько потоков запускаете тесты? Поделитесь в комментариях.
А если хотите прокачивать автотесты в нашей команде — смотрите вакансии здесь.
Будем ВКонтакте!
ссылка на оригинал статьи https://habr.com/ru/company/vk/blog/645695/
Добавить комментарий