Привет! Меня зовут Андрей Якобчук, я ведущий фронтенд-разработчик в Muse Group. Мы постоянно работаем над ускорением клиентской части наших сайтов. К тому же Гугл с его метриками Core Web Vitals с каждым годом придаёт всё большее значение отзывчивости и стабильности интерфейса сайтов и понижает в ранжировании те, которые считает неудобными для пользователя. В статье я расскажу о том, какие подходы мы используем для измерения и мониторинга перфоманса сайтов, а также дам рекомендации, как можно улучшить ваш проект.
Зачем ускорять, если всё и так работает
Перфоманс сайта — это та область, где пересекаются интересы пользователя, бизнеса и Гугла. Это первое, что нужно понимать, прежде чем начинать работу над ускорением клиентской части сайта.
Удобство для пользователя
Важная характеристика интерфейса для пользователя — естественность изменений при взаимодействии с ним. Мы говорим об отзывчивости интерфейса, которая ограничена возможностями восприятия человека. Ещё в 1993 году UX-исследователь Якоб Нильсон в книге Usability Engineering описал, когда человек способен воспринимать конкретные внешние изменения как естественные.
0,1 секунды. Это время, в рамках которого изменение интерфейса воспринимается как мгновенное, а значит, обратная связь не нужна. Сюда можно отнести любые взаимодействия с интерфейсом, которые могут быть обработаны прямо в нём, без взаимодействий с внешними системами, например, без получения данных от сервера.

В примере на картинке могут возникнуть проблемы. Например, если основной поток занят другими задачами, задача по показу формы ответа может выйти за 0,1 секунды. Гугл рекомендует вписывать такие взаимодействия в 50 мс, чтобы оставить зазор на случай, если основной поток будет забит другими задачами.
1 секунда. Это предел для непрерывного потока мыслей пользователя. Даже если он заметит задержку, он не успеет отвлечься. Обычно обратная связь здесь тоже не требуется, но пользователь уже теряет ощущение непрерывной работы с данными и интерфейсом.
Сюда относятся все анимации и более глобальные изменения интерфейса, которые требуют взаимодействия с внешними источниками данных: нам требуется загрузить дополнительный код, чтобы отрисовать часть интерфейса, или обновить что-то в базе данных, чтобы мы могли что-то показать после этого.
Анимации можно делать 100 мс и меньше, конечно. Но при этом пользователю будет сложно воспринять изменения. Это лишь увеличит когнитивную нагрузку при взаимодействии с интерфейсом. Есть правило: чем больше часть интерфейса, которую мы анимируем, тем более длинная анимация нужна. Например, при hover на кнопку будет достаточно 150 мс, а для анимации показа модального окна уже потребуется 300–500 мс.
10 секунд. Это предел для удержания внимания пользователя. Он может захотеть переключиться на другую задачу. В этом случае важно дать обратную обратную связь: показать, что задача действительно длинная, и пользователь может вернуться к ней позже.
Сюда относятся все глобальные изменения на уровне переходов между экранами приложения или длинные операции, например, загрузка файла в удаленное хранилище.
16 мс — это важный промежуток времени для анимации и скролла интерфейса. Если каждый фрагмент анимации укладывается в промежуток 16 мс (60 fps), то пользователь воспринимает эту анимацию как плавную. Также важно учитывать, что часть времени уйдет на непосредственную отрисовку кадра, так что на все наши расчеты мы можем потратить до 10 мс. Нас могут сильно ограничивать другие задачи которые выполняются параллельно в нашем коде.
Что можно сделать, если мы не укладываемся в эти рамки
К сожалению, загрузка страницы за 1 секунду при холодном старте приложения — довольно сложная задача, так как общение с сервером вносит свои задержки. По реальным данным время ответа сервера (TTFB) составляет 500–600 мс на десктопе, а на мобильных устройствах, даже при хорошем соединении, может доходить до 1 секунды и более. К тому же оно не всегда одинаково, поэтому Гугл рекомендует укладываться в 2 секунды на хорошем соединении 4G и лучше, а при 3G не зазорным будет уложиться в 5 секунд.
Если изменение происходит в рамках текущей страницы, либо при загрузке страницы мы не укладываемся в 1–2 секунды, то можно показать лоадер в том месте, где появится интерфейс. Более современный способ — показать контентный плейсхолдер на месте UI, который должен подгрузиться. Такой вариант особенно хорош, если блоки интерфейса имеют стандартизированные размеры.

Если же задача выходит за рамки 10 секунд, то можно обыграть ситуацию через прогресс бар.

Хорошая практика — отправить письмо или пуш-уведомления, когда процесс закончится. В примере выше пользователь загружает скор. Он может закрыть страницу, потом вернуться на неё и увидеть состояние загрузки. После того, как его скор будет полностью обработан сервером, пользователь получит письмо, что загрузка завершена.

Интересы бизнеса и технические ограничения продукта
Если смотреть на ускорение работы сайта с точки зрения бизнеса, то наша задача — получить результат минимальными усилиями за минимальные вложения. Поэтому мы приняли решение отказаться от SSR. Вся отрисовка сейчас происходит на клиенте. Это позволяет нам:
-
Держать на 30% меньше серверных мощностей.
-
Не увеличивать штат разработки на поддержку серверной части отрисовки UI (это хотя и не большая задача, но все же мы должны быть уверены, что и бек и фронт отдают правильную верстку)
-
Уменьшить технологический зоопарк.
С другой стороны это увеличивает требования к клиентскому коду.
Требования Гугла

Гугл давно уже стоит на страже перфоманс, а после апдейта в августе мы все живем в рамках новых метрик — Core Web Vitals.
-
Теперь Гугл учитывает не только скорость загрузки сайта, но и то, насколько он отзывчивый и насколько интерфейс стабилен.
-
Все метрики Гугл собирает с реальных пользователей в реальном времени. Сайт теперь оценивается на основе средней скользящей за последние 28 дней.
-
Есть четкий performance budget — 70+% заходов по 75-му перцентилю на страницы домена должны быть в зеленой зоне по каждой из метрик (каждая метрика имеет красную, желтую и зеленую зону).
Пользователь, бизнес и Гугл — это три причины заняться ускорением работы клиентской части сайта. Но сначала нужно измерить текущую ситуацию.
Инструменты аналитики
Здесь я не буду рассказывать про такие стандартные браузерные инструменты, как performance panel в браузерах, об этом уже много писали в различных источниках. Для всех современных фреймворков типа Angular, Vue и UI-библиотек типа React есть свои инструменты разработчика, в которых также можно измерять производительность работы конкретного технического решения.

Вопрос performance — это, в первую очередь, вопрос баланса. Если не учитывать performance совсем, это негативно повлияет на бизнесовые метрики. Но в то же время — это бездонная бочка, в которую можно вложить бесконечное количество ресурсов. Соблюсти баланс в них нам помогает performance budget. В рамках performance budget мы устанавливаем приемлемые с точки зрения бизнеса SLO для наших перфоманс метрик. Здесь мы также придерживаемся Core Web Vitals, так как с одной стороны, эти метрики охватывают основные моменты отрисовки страницы, а с другой — позволяют нам хорошо индексироваться Гуглом, который является основным источником трафика.
Чтобы понимать, где мы находимся в рамках этого бюджета, необходим мониторинг. В данный момент у нас есть два типа аналитики:
-
Наша внутренняя аналитика (realtime).
-
Аналитика построенная на основе Google BigQuery
Realtime аналитика
После релиза наравне с Sentry смотрим дашборд перфоманса. Через 30 минут уже примерно видно, хорошо ли идет релиз. И если заметно, что метрики сильно выросли, то можно принимать решение об откате. Если нет видимого роста, то проверяем релиз через пару часов, чтобы быть уверенными, что все ок.
Данные собираются в ClickHouse, и на их основе мы строим графики в Superset. Данные агрегируем до 5 минут, но они на таком интервале очень шумные. Средствами Superset мы можем укрупнить агрегацию до часов или дней и построить смещение на день или неделю для удобного сравнения. Плюс возможность смотреть по релизам и сразу же определять, что что-то идёт не так. Можно сравнить день со днем или с прошлой неделей.

Дашборд, где показан общий тренд по дням, смотрим ежедневно.

Для удобства мы прямо на дашбордах установили верхние границы метрик, ниже которых мы считаем, что наш сайт хорошо работает с точки зрения перфоманс. Также видна ситуация относительно прошлых суток и недели, чтобы выявлять аномалии.
Ещё у нас есть свои кастомные метрики, которые помогают при локализации проблем.

Про то, что такое App Shell можно почитать здесь
Аналитика Google BigQuery
Этот дашборд достаточно проверять раз в неделю.
По этой аналитике мы смотрим, как нас воспринимает Гугл. Важное отличие — Гугл показывает не абсолютные данные, а скользящее среднее за последние 28 дней. Это значит, что если вы сломали или починили что-то, то абсолютные метрики будут примерно такими же как и в realtime аналитике только через 28 дней.

Следующий график на дашборде отражает распределение количества загрузок хороших страниц, страниц требующих доработки и плохих. Важно, чтобы загрузок в зелёной зоне (хорошие страницы) было больше 75%.
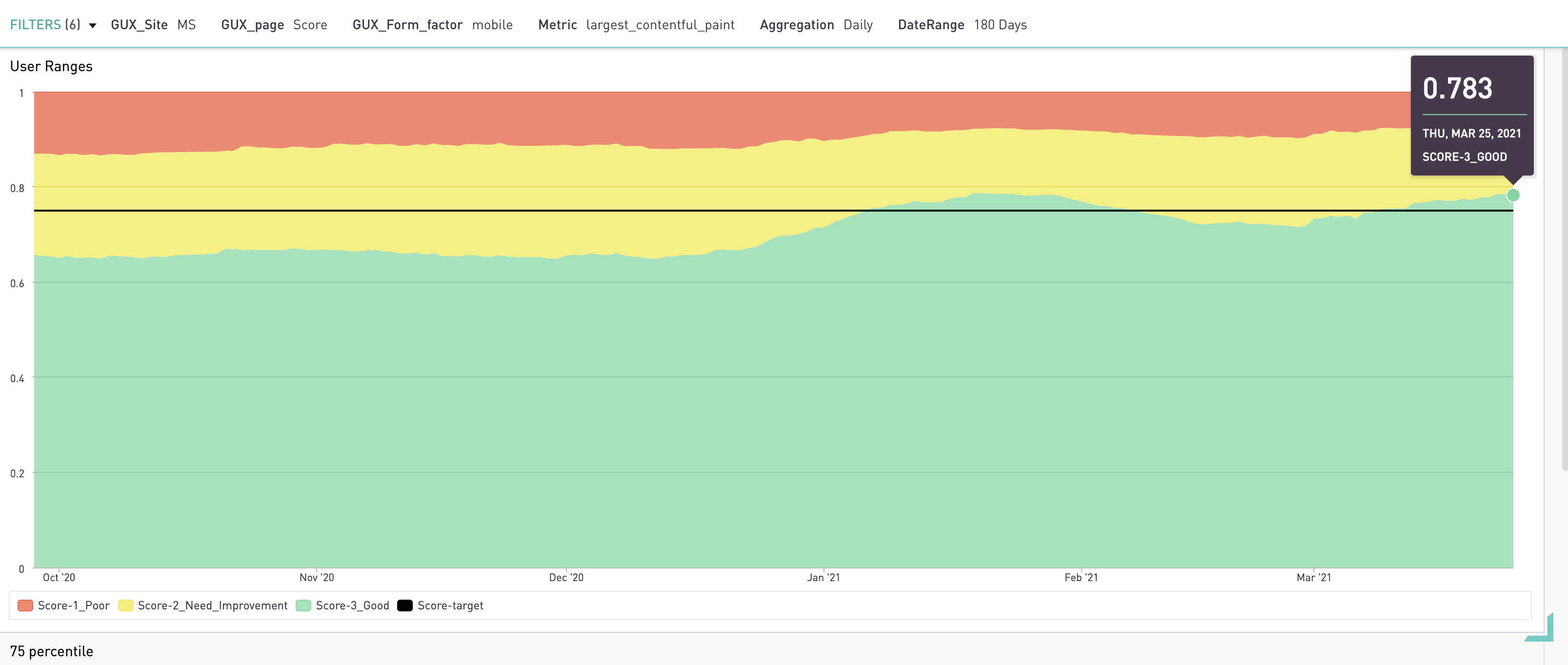
Google search consоle
C недавнего времени Гугл начал показывать в поисковой консоли качество сервиса с точки зрения перфоманса. Там можно посмотреть общую картину по домену (> 70% — это хорошо).

И указать на конкретные проблемы с сайта.
Провалившись в метрику, можно увидеть уже конкретные URL, которые Гугл считает требующими доработки.
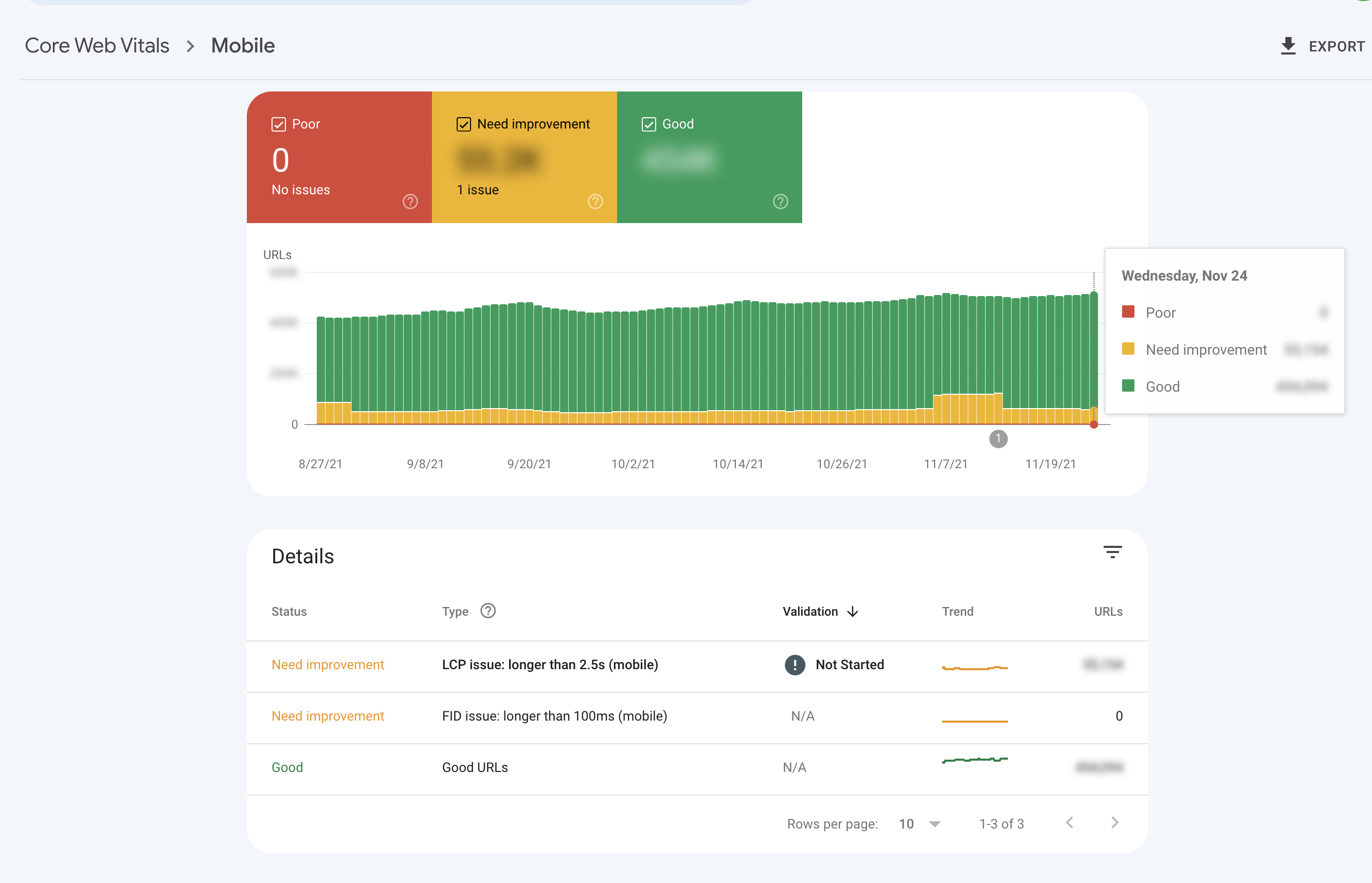

Алерты
У нас есть алерты для перфоманс метрик, которые помогут в случае, если что-то пошло не так, даже если релиза не было. Ну и человеческий фактор никто не отменял. Есть суточные алерты на каждую метрику, а есть алерты за три часа, чтобы отлавливать «жесткие» скачки метрик в негативную сторону и не ждать сутки, чтобы начать решать проблему.

Почему не Lighthouse и PageSpeed Insights
Мы сознательно перестали фокусироваться на использовании Lighthouse и PageSpeed Insights по двум причинам:
-
По тепличным метрикам невозможно понять, на сколько стало хуже у пользователей с опытом. Мы агрегируем тысячи значений от реальных пользователей, чтобы получить нормальное распределение в данных без шумов и с хорошей детекцией даже незначительных изменений.
-
Данные инструменты хороши именно в начале пути, когда только предстоит делать самые базовые оптимизации.
Наконец, настроив сбор данных для аналитики и алерты, можно приступить уже непосредственно к оптимизации.
Оптимизируй это
Здесь я составил небольшой набор рекомендаций, которые помогут поддерживать сайт всегда быстрым.
Фокус на главном
Определите, на какие страницы сайта приходит основной трафик, и сосредоточьте усилия на них. Нет смысла тратить ресурсы на страницы, на которые почти никто не заходит.
Ограничения
Подумайте, какие вещи можно автоматизировать или ограничить, чтобы сайт или приложение были быстрыми «из коробки». Например, для нас такими ограничениями являются:
-
Ограничения по размеру чанков. Чанк с контентом страницы должен быть всегда один. Также на чанки стоит ограничение по размеру. Превышен размер чанка — деплоя нет.
-
Ограничения по техническому стеку. Мы очень трепетно относимся к тому, сколько и какие внешние технологические решения мы привносим в продукт. Это важно, чтобы обходиться минимальным количеством решений, особенно это касается первого старта. Любое решение приносится в продукт открыто и только в результате исследования, в том числе сможем ли мы обойтись без этого решения. К слову, общий вес core libs у нас всего 27 КБ gzip.
Оптимизации
Мы фокусируемся на получении наилучшего значения Core Web Vitals как основных метрик производительности фронтенда.
Largest Contentful Paint (LCP) — скорость загрузки основного контента
Для того, чтобы грамотно оптимизировать LCP, необходимо определить, какой элемент интерфейса самый большой, и выстраивать загрузку страницы вокруг него. Чтобы определить какой это элемент или элементы, если их несколько, нужно измерить. Основные моменты по оптимизации хорошо описаны в этой статье, а от меня будет несколько дополнительных рекомендаций.
-
В месте, где вы управляете состоянием приложения, можно завести свойство, которое будет говорить, когда произошел LCP, и завязать на его изменение отрисовку не критичных с точки зрения первой отрисовки частей UI и non-UI функциональностей (например, аналитики).
-
Разделяйте код, который отвечает за отрисовку, и код, который отвечает за бизнес-логику. Весь код, который нужен для дальнейшей работы приложения, можно постепенно подгружать уже при взаимодействии пользователя с конкретными частями интерфейса.
-
Старайтесь не выполнять никакую бизнес-логику до LCP, так как это вызовет выделение лишних процессорных ресурсов.
-
Также важно понимать, что стабильность UI при его отрисовке также влияет на LCP. Если какие-либо другие элементы будут влиять на позицию вашего LCP-элемента на странице, то это отложит LCP.
-
Вся below the fold графика должна грузиться через lazy load.
Cumulative Layout Shift (CLS) — совокупное смещение макета
Данный раздел важен только для блоков страницы, которые находятся во viewport либо будут загружены во viewport после взаимодействия пользователя. Важно также понимать, что CLS — метрика кумулятивная, то есть учитываются все прыжки интерфейса, которые были в процессе взаимодействия со страницей. Основные оптимизации можно посмотреть здесь.
Первая отрисовка страницыЕсли есть динамические блоки, то под них обязательно нужно резервировать место под блок.
После взаимодействия пользователя
-
Вставка новых блоков должна быть в промежутке 500 мс после взаимодействия пользователя, тогда она считается естественной и любой layout shift не будет засчитываться в скор.
-
Если не получается вставить блок за это время, то необходимо как-то резервировать место под блок.
-
Если происходит трансформация элемента, например при скролле, то необходимо обязательно использовать CSS Transform для этой цели и анимировать именно через это свойство, так как в этом случае не будет происходить relayout.
Как можно резервировать место
-
Просто выделить место, возможно, с лоадером.
-
Делать контентные плейсхолдеры.
Общий совет — у всех медиа-блоков (embed/video/image) должны быть зафиксированы размеры.
First Input Delay (FID) — время ожидания до первого взаимодействия с контентом
Основные рекомендации по оптимизациям — в статье. Но, помимо указанного в статье, в негативную сторону на FID может повлиять большое количество одновременных запросов.
Итого
Мы оптимизировали наши основные сервисы, чтобы значения Core Web Vitals для их основных страниц всегда находились в зелёной зоне. Если значения Core Web Vitals ваших сервисов — в жёлтой или красной, вы знаете что делать. Помните, что метрики необходимо постоянно мониторить. К тому же Гугл обещает, что Core Web Vitals будут развиваться и дальше. Расскажите в комментариях, что вам помогает улучшать производительность сервисов.
ссылка на оригинал статьи https://habr.com/ru/post/647079/
Добавить комментарий