В этой статье я расскажу, как с помощью библиотек scikit-learn, opencv, numpy, imutilsс выявить новизну входных изображений. Многие программы требуют наличия возможности решить, принадлежит ли новый объект тому же распределению, что и существующие объекты (это промежуточный результат), или его следует рассматривать как новизну. Часто эта возможность используется для очистки реальных наборов данных.
Для начала установим необходимые библиотеки:
pip install numpy pip install opencv-contrib-python pip install imutils pip install scikit-learnВыявлять новинки будем методом «Обнаружения новинок», используя модуль Isolation Forests.

Одним из эффективных способов обнаружения новизны в наборе данных является использование случайных лесов. Алгоритм изолирует наблюдения, случайным образом выбирая признак, а затем случайным образом выбирая значение разделения между максимальным и минимальным значениями выбранного признака. Стратегия показана выше.
Рассмотрим работу алгоритма на конкретном примере. Пусть перед нами стоит задача – определить изображено ли картинке море.
Обучим модель на датасете фотографий моря.
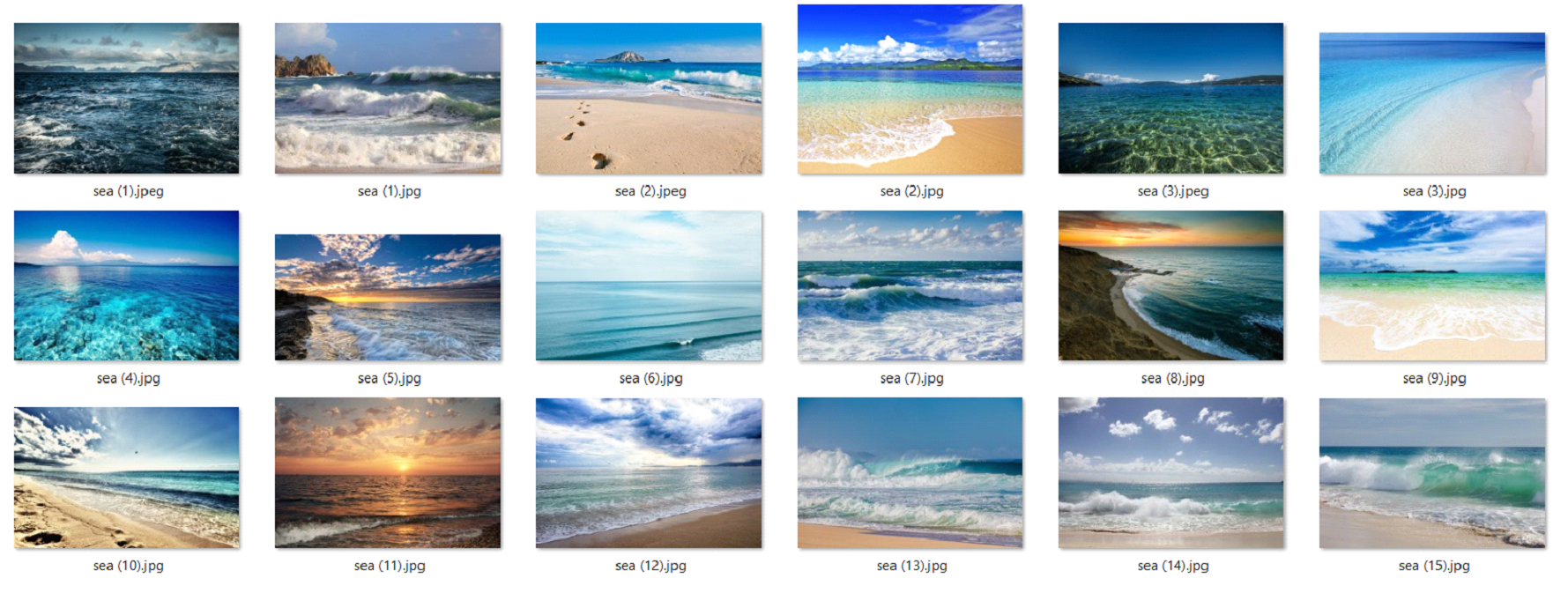
При представлении нового входного изображения наш алгоритм обнаружения новизны должен решить, вписывается ли новое изображение в «многообразие моря» или оно является новинкой, и вернуть либо 1, либо -1. Если возвращается 1, то делаем вывод «Да, это море», иначе «Нет, не похоже на море»
Для оценки нашего алгоритма обнаружения новинок используем 3 тестовых изображения:

Для начала реализуем модуль для извлечения цветовой гистограммы с помощью OpenCV, это необходимо для того, чтобы представить изображение в график пикселей:
from imutils import paths import numpy as np import cv2 def histogram_image(image, bins=(4, 6, 3)): # вычислияем 3D-цветовую гистограмму по изображению и нормализуем ее histogram = cv2.calcHist([image], [0, 1, 2], None, bins, [0, 180, 0, 256, 0, 256]) histogram = cv2.normalize(histogram, histogram).flatten() # Возращаем гистограмму return histogramЗатем загружаем датасет:
def loading_dataset(path_dataset, bins): # пути ко всем изображениям в нашем каталоге набора данных, затем # инициализируйте наши списки изображений path_s_image = list(paths.list_images(path_dataset)) data = [] # цикл по каждому патчу for path in path_s_image: image = cv2.imread(path) image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) features = quantify_image(image, bins) data.append(features) return np.array(data)Создаем файл Python для обучения модели на загруженном датасете и запускаем выполнение:
from function import loading_dataset from sklearn.ensemble import IsolationForest import pickle print("[ИНФО] подготовка набора данных") data = loading_dataset('sea/', bins=(3, 3, 3)) # обучаем модель print("[INFO] модель обнаружения") model = IsolationForest(n_estimators=100, contamination=0.01, random_state=42) model.fit(data) f = open('detect_anomaly.model', "wb") f.write(pickle.dumps(model)) f.close() Создаем файл test_anomaly для тестирования модели:
from function import histogram_image import pickle import cv2 print("[ИНФО] загрузка модели новизны") model = pickle.loads(open("detect_anomaly.model", "rb").read()) # Загрузка изображения,и конвертация в гистограмму image = cv2.imread('examples\cities.jpg') hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) features = histogram_image(hsv, bins=(3, 3, 3)) preds = model.predict([features])[0] label = "new" if preds == -1 else "normal" color = (0, 0, 255) if preds == -1 else (0, 255, 0) # рисуем фотографию cv2.putText(image, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, color, 2) # отображаем на экране cv2.imshow("Output", image) cv2.waitKey(0) Тестируем модель на трех фотографиях – город, море и шоссе.
Тест 1. В модель загружаем фото города.
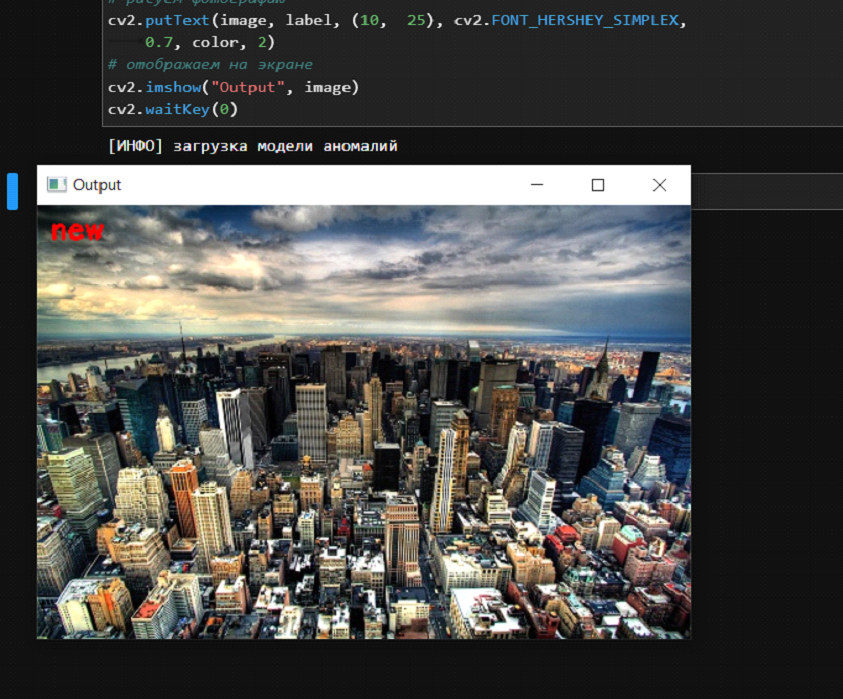
По результату отработки алгоритма видим, что фотографию города модель пометила как новинку.
Тест 2. В модель загружаем фото моря.

Фотографию моря модель пометила как нормальное. То есть на картинки изображено море.
Тест 3. В модель загружаем фото шоссе.
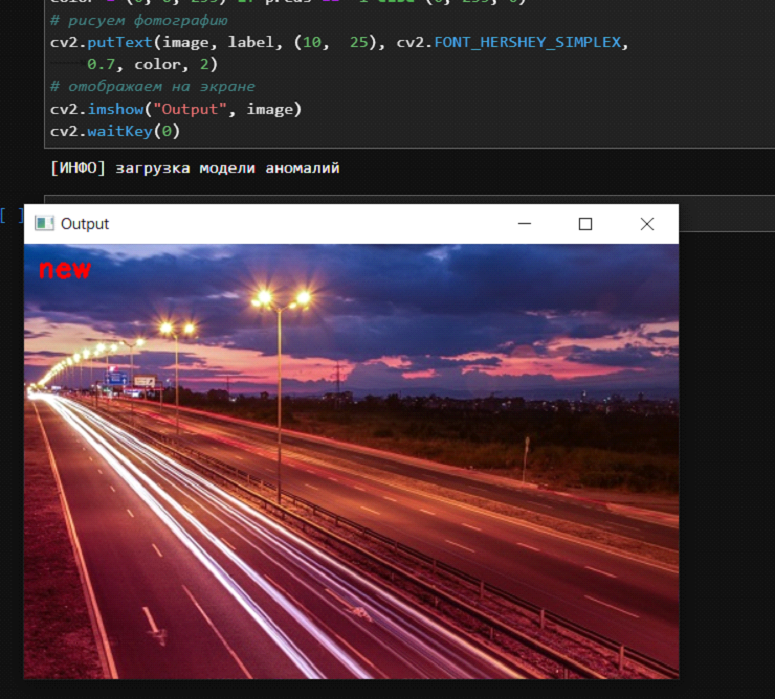
Фотографию шоссе модель пометила как новинку.
В результате, наша обученная модель прошла три из трех тестов, и определила все фотографии верно. Две из которых были новинками и одно фото не являлось новинкой.
ссылка на оригинал статьи https://habr.com/ru/post/652851/
Добавить комментарий